Benchmarking Vision-Language Models for Microscopic Plant Image Understanding
Pith reviewed 2026-06-26 10:40 UTC · model grok-4.3
The pith
Vision-language models achieve only modest accuracy on tasks requiring fine-grained understanding of microscopic plant images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that current vision-language models struggle with fine-grained recognition and biologically grounded reasoning when applied to microscopic plant imagery, as measured by their low performance across the tasks and question-answer pairs in the PlantMicro benchmark.
What carries the argument
The PlantMicro benchmark, which assembles diverse microscopic images and a suite of visual question answering tasks to test model capabilities in this domain.
If this is right
- Models must be improved specifically for perceiving fine cellular and subcellular structures in plant images.
- The benchmark supplies a standardized way to track whether new models close the observed performance gap.
- Better results on these tasks could enable more reliable automated support for plant pathology research.
- The same evaluation approach highlights where current systems fall short in connecting visual features to biological concepts.
Where Pith is reading between the lines
- Performance on PlantMicro could serve as an early indicator for whether a model is ready for practical use in high-throughput plant disease screening.
- Adding tasks that require cross-referencing multiple images or modalities might expose further limitations not captured in the current set.
- Pairing the benchmark with external biological databases could test whether models can combine visual input with domain knowledge.
Load-bearing premise
The images and tasks chosen for PlantMicro are representative of the full range of challenges in microscopic plant image understanding.
What would settle it
A vision-language model that reaches substantially higher accuracy, for example above 70 percent, on the pathogen classification task while maintaining strong results on the other PlantMicro tasks.
Figures

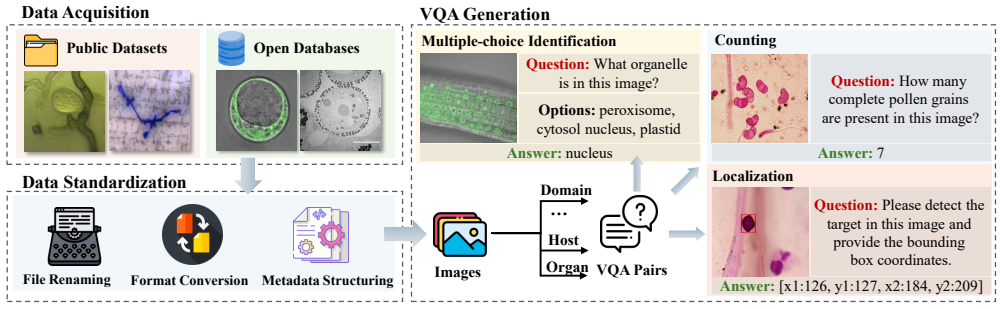
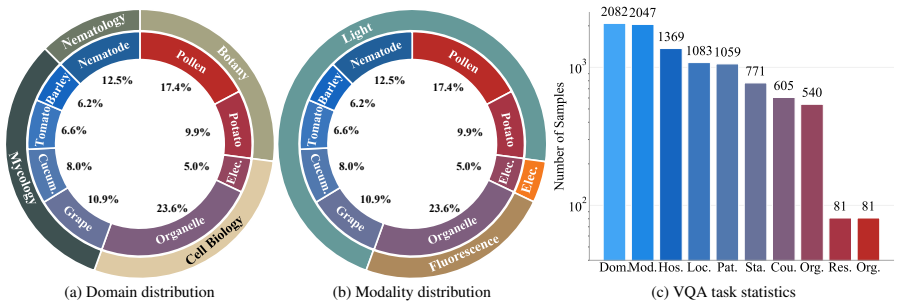
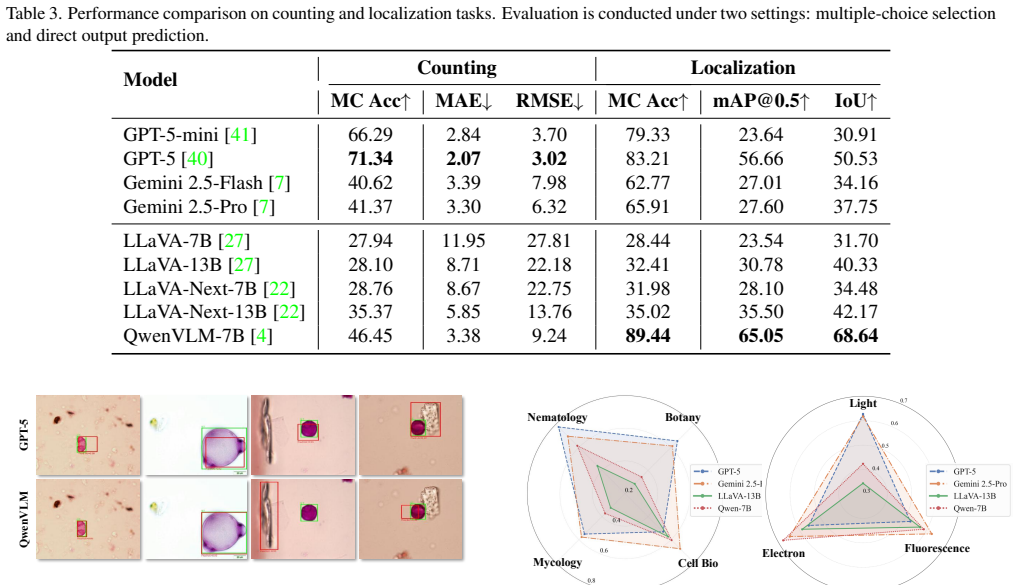
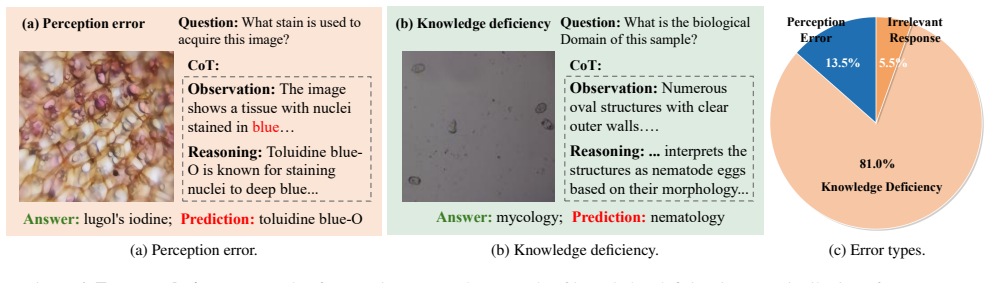
read the original abstract
Microscopic imaging provides essential visual evidence for studying plant biology and pathology at the cellular and subcellular levels. However, existing benchmarks on vision-language models primarily focus on macroscopic plant imagery, while the microscopic domain remains underexplored. To address this gap, we present PlantMicro, a comprehensive benchmark for evaluating vision-language models (VLMs) in microscopic plant imagery. PlantMicro integrates more than 5,000 images collected across diverse hosts, biological domains, and imaging modalities. Building on this diversity, we design a set of complementary tasks that capture different facets of microscopic image understanding. To support these tasks, we construct over 9,000 VQA pairs that systematically evaluate the capabilities of VLMs. Experiments on PlantMicro show that current VLMs struggle with fine-grained recognition and biologically grounded reasoning. For example, GPT-5 achieves 34.93% accuracy on the pathogen classification task, which is only modestly above the random-guessing baseline. The results highlight a significant gap in current VLMs' ability to comprehend plant microscopic images. PlantMicro provides a standardized foundation for advancing VLMs toward reliable and comprehensive microscopy-level plant understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PlantMicro, a benchmark with >5,000 microscopic plant images collected across diverse hosts, biological domains, and imaging modalities, plus >9,000 VQA pairs for complementary tasks. It reports that current VLMs struggle with fine-grained recognition and biologically grounded reasoning, citing GPT-5's 34.93% accuracy on pathogen classification (modestly above random baseline) as evidence of a significant gap in VLM capabilities for this domain.
Significance. If the benchmark construction is shown to be representative and free of selection/annotation bias, PlantMicro would fill a clear gap by providing the first standardized VQA resource for microscopic plant imagery, enabling targeted progress on VLM limitations in fine-grained biological reasoning that macroscopic benchmarks do not address.
major comments (2)
- [Abstract] Abstract: The central claim that VLMs struggle with microscopic plant understanding (e.g., GPT-5 at 34.93% on pathogen classification) depends on the >5,000 images spanning relevant biological/imaging variation and the >9,000 VQA pairs being correctly labeled without shortcut cues or bias. However, no sampling protocol, class distribution, inter-annotator agreement, or expert validation details are provided, leaving open the possibility that low scores reflect benchmark artifacts rather than model deficiencies.
- [Abstract (and methods, if present)] The paper provides no details on data collection methods, VQA construction process, baseline definitions, or statistical significance testing. These omissions are load-bearing because the abstract asserts that the tasks 'systematically evaluate' capabilities and that results 'highlight a significant gap,' yet the reported numbers cannot be independently verified or reproduced from the given information.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the need for greater transparency in benchmark construction. We will revise the manuscript to address these points by adding the requested methodological details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that VLMs struggle with microscopic plant understanding (e.g., GPT-5 at 34.93% on pathogen classification) depends on the >5,000 images spanning relevant biological/imaging variation and the >9,000 VQA pairs being correctly labeled without shortcut cues or bias. However, no sampling protocol, class distribution, inter-annotator agreement, or expert validation details are provided, leaving open the possibility that low scores reflect benchmark artifacts rather than model deficiencies.
Authors: We agree these details are necessary to substantiate the benchmark's validity. In the revised manuscript we will add a dedicated 'Benchmark Construction' subsection that specifies the sampling protocol for ensuring coverage across hosts, biological domains, and imaging modalities; reports class distributions; provides inter-annotator agreement statistics; and describes the expert validation steps used for image labels and VQA pairs. revision: yes
-
Referee: [Abstract (and methods, if present)] The paper provides no details on data collection methods, VQA construction process, baseline definitions, or statistical significance testing. These omissions are load-bearing because the abstract asserts that the tasks 'systematically evaluate' capabilities and that results 'highlight a significant gap,' yet the reported numbers cannot be independently verified or reproduced from the given information.
Authors: We acknowledge that the current manuscript lacks these methodological specifics. The revision will expand the Methods section to document data collection procedures, the full VQA pair generation process, explicit baseline definitions (including the random-guessing baseline), and the statistical tests applied to the reported accuracies. These additions will support independent verification and reproducibility of the experimental claims. revision: yes
Circularity Check
No circularity: empirical benchmark with direct measurements
full rationale
This is a dataset construction and model evaluation paper. It collects >5,000 images across hosts/domains/modalities, designs complementary tasks, builds >9,000 VQA pairs, and reports direct accuracy numbers (e.g., GPT-5 at 34.93% on pathogen classification). No equations, fitted parameters, predictions, or derivations are present that could reduce to inputs by construction. No self-citation chains or uniqueness theorems are invoked to support any result. The reported performance gaps are straightforward empirical observations on the new benchmark and do not rely on any self-referential step.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022
2022
-
[2]
Deep learning- based detection of aphid colonies on plants from a re- constructed brassica image dataset.Computers and electronics in agriculture, 205:107587, 2023
Abderraouf Amrani, Ferdous Sohel, Dean Diepeveen, David Murray, and Michael GK Jones. Deep learning- based detection of aphid colonies on plants from a re- constructed brassica image dataset.Computers and electronics in agriculture, 205:107587, 2023
2023
-
[3]
Leveraging vision language models for specialized agricultural tasks
Muhammad Arbab Arshad, Talukder Zaki Jubery, Tirtho Roy, Rim Nassiri, Asheesh K Singh, Arti Singh, Chinmay Hegde, Baskar Ganapathysubrama- nian, Aditya Balu, Adarsh Krishnamurthy, et al. Leveraging vision language models for specialized agricultural tasks. In2025 IEEE/CVF Winter Con- ference on Applications of Computer Vision (WACV), pages 6320–6329. IEEE, 2025
2025
-
[4]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
A large-scale optical microscopy image dataset of potato tuber for deep learning based plant cell assessment.Scientific Data, 7(1):371, 2020
Sumona Biswas and Shovan Barma. A large-scale optical microscopy image dataset of potato tuber for deep learning based plant cell assessment.Scientific Data, 7(1):371, 2020
2020
-
[6]
Deep learning-based accu- rate detection of insects and damage in cruciferous crops using yolov5.Smart Agricultural Technology, 9:100663, 2024
Sourav Chakrabarty, Pathour Rajendra Shashank, Chandan Kumar Deb, Md Ashraful Haque, Pradyu- man Thakur, Deeba Kamil, Sudeep Marwaha, and Mukesh Kumar Dhillon. Deep learning-based accu- rate detection of insects and damage in cruciferous crops using yolov5.Smart Agricultural Technology, 9:100663, 2024
2024
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaek- ermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Developing a micro- scope image dataset for fungal spore classification in grapevine using deep learning.Journal of Agriculture and Food Research, 14:100805, 2023
Alexis Crespo-Michel, Miguel A Alonso-Ar´evalo, and Rufina Hern ´andez-Mart´ınez. Developing a micro- scope image dataset for fungal spore classification in grapevine using deep learning.Journal of Agriculture and Food Research, 14:100805, 2023
2023
-
[9]
Vardhan Dongre, Chi Gui, Shubham Garg, Hooshang Nayyeri, Gokhan Tur, Dilek Hakkani-T ¨ur, and Vikram S Adve. Mirage: A benchmark for mul- timodal information-seeking and reasoning in agri- cultural expert-guided conversations.arXiv preprint arXiv:2506.20100, 2025
-
[10]
Strategies of plants to overcome abiotic and biotic stresses.Biological Reviews, 99(4): 1524–1536, 2024
Baoguo Du, Robert Haensch, Saleh Alfarraj, and Heinz Rennenberg. Strategies of plants to overcome abiotic and biotic stresses.Biological Reviews, 99(4): 1524–1536, 2024
2024
-
[11]
Primary production of the biosphere: integrating terrestrial and oceanic components.science, 281(5374):237–240, 1998
Christopher B Field, Michael J Behrenfeld, James T Randerson, and Paul Falkowski. Primary production of the biosphere: integrating terrestrial and oceanic components.science, 281(5374):237–240, 1998
1998
-
[12]
Clip-adapter: Better vision-language models with feature adapters.International Journal of Com- puter Vision, 132(2):581–595, 2024
Peng Gao, Shijie Geng, Renrui Zhang, Teli Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li, and Yu Qiao. Clip-adapter: Better vision-language models with feature adapters.International Journal of Com- puter Vision, 132(2):581–595, 2024
2024
-
[13]
Aruna Gauba, Irene Pi, Yunze Man, Ziqi Pang, Vikram S. Adve, and Yu-Xiong Wang. Agmmu: A comprehensive agricultural multimodal understand- ing and reasoning benchmark. InarXiv preprint arXiv:2504.10568, 2025
-
[14]
Segmenta- tion and coverage measurement of maize canopy im- ages for variable-rate fertilization using the mcac-unet model.Agronomy, 14(7):1565, 2024
Hailiang Gong, Litong Xiao, and Xi Wang. Segmenta- tion and coverage measurement of maize canopy im- ages for variable-rate fertilization using the mcac-unet model.Agronomy, 14(7):1565, 2024
2024
-
[15]
A visual– language foundation model for pathology image anal- ysis using medical twitter.Nature medicine, 29(9): 2307–2316, 2023
Zhi Huang, Federico Bianchi, Mert Yuksekgonul, Thomas J Montine, and James Zou. A visual– language foundation model for pathology image anal- ysis using medical twitter.Nature medicine, 29(9): 2307–2316, 2023
2023
-
[16]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Os- trow, Akila Welihinda, Alan Hayes, Alec Rad- ford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Microscopic image dataset of plant-parasitic nematode.Data in Brief, page 111687, 2025
Siwi Indarti, Nabila Husna Shabrina, and Rina Ma- harani. Microscopic image dataset of plant-parasitic nematode.Data in Brief, page 111687, 2025
2025
-
[18]
Plant defense responses to biotic stress and its interplay with fluctuating dark/light conditions.Fron- tiers in Plant Science, 12:631810, 2021
Zahra Iqbal, Mohammed Shariq Iqbal, Abeer Hashem, Elsayed Fathi Abd Allah, and Mohammad Israil Ansari. Plant defense responses to biotic stress and its interplay with fluctuating dark/light conditions.Fron- tiers in Plant Science, 12:631810, 2021
2021
-
[19]
Diagnosing the spores of tomato fungal diseases using microscopic image processing and ma- chine learning.Multimedia Tools and Applications, 83 (26):67283–67301, 2024
Seyed Mohamad Javidan, Ahmad Banakar, Key- van Asefpour Vakilian, Yiannis Ampatzidis, and Kam- ran Rahnama. Diagnosing the spores of tomato fungal diseases using microscopic image processing and ma- chine learning.Multimedia Tools and Applications, 83 (26):67283–67301, 2024
2024
-
[20]
Large language models are zero-shot reasoners.Advances in neu- ral information processing systems, 35:22199–22213, 2022
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.Advances in neu- ral information processing systems, 35:22199–22213, 2022
2022
-
[21]
Epigenetic and chromatin-based mechanisms in environmental stress adaptation and stress memory in plants.Genome biol- ogy, 18(1):124, 2017
J ¨orn L ¨amke and Isabel B ¨aurle. Epigenetic and chromatin-based mechanisms in environmental stress adaptation and stress memory in plants.Genome biol- ogy, 18(1):124, 2017
2017
-
[22]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava- next-interleave: Tackling multi-image, video, and 3d in large multimodal models.arXiv preprint arXiv:2407.07895, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large lan- guage models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large lan- guage models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[24]
Wheat growth stage identification method based on multimodal data.European Journal of Agronomy, 162:127423, 2025
Yong Li, Yinchao Che, Handan Zhang, Shiyu Zhang, Liang Zheng, Xinming Ma, Lei Xi, and Shuping Xiong. Wheat growth stage identification method based on multimodal data.European Journal of Agronomy, 162:127423, 2025
2025
-
[25]
Track any peppers: Weakly supervised sweet pepper tracking using vlms
Jia Syuen Lim, Yadan Luo, Zhi Chen, Tianqi Wei, Scott Chapman, and Zi Huang. Track any peppers: Weakly supervised sweet pepper tracking using vlms. arXiv preprint arXiv:2411.06702, 2024
-
[26]
Pmc- clip: Contrastive language-image pre-training using biomedical documents
Weixiong Lin, Ziheng Zhao, Xiaoman Zhang, Chaoyi Wu, Ya Zhang, Yanfeng Wang, and Weidi Xie. Pmc- clip: Contrastive language-image pre-training using biomedical documents. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 525–536. Springer, 2023
2023
-
[27]
Improved baselines with visual instruction tun- ing
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tun- ing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024
2024
-
[29]
Plant species classification based on hyperspectral imaging via a lightweight con- volutional neural network model.Frontiers in Plant Science, 13:855660, 2022
Keng-Hao Liu, Meng-Hsien Yang, Sheng-Ting Huang, and Chinsu Lin. Plant species classification based on hyperspectral imaging via a lightweight con- volutional neural network model.Frontiers in Plant Science, 13:855660, 2022
2022
-
[30]
A multi- modal benchmark dataset and model for crop disease diagnosis
Xiang Liu, Zhaoxiang Liu, Huan Hu, Zezhou Chen, Kohou Wang, Kai Wang, and Shiguo Lian. A multi- modal benchmark dataset and model for crop disease diagnosis. InEuropean Conference on Computer Vi- sion, pages 157–170. Springer, 2024
2024
-
[31]
Micro-bench: A microscopy benchmark for vision-language understanding
Alejandro Lozano, Jeffrey J Nirschl, James Burgess, Sanket Rajan Gupte, Yuhui Zhang, Alyssa Unell, and Serena Yeung-Levy. Micro-bench: A microscopy benchmark for vision-language understanding. InThe Thirty-eight Conference on Neural Information Pro- cessing Systems Datasets and Benchmarks Track
-
[32]
Odl net: Object detection and location network for small pears around the thinning period.Computers and Electronics in Agriculture, 212:108115, 2023
Yuqi Lu, Shuang Du, Ze Ji, Xiang Yin, and Weikuan Jia. Odl net: Object detection and location network for small pears around the thinning period.Computers and Electronics in Agriculture, 212:108115, 2023
2023
-
[33]
Deep phenotyping platform for microscopic plant- pathogen interactions.Frontiers in Plant Science, 16: 1462694, 2025
Stefanie L ¨uck, Salim Bourras, and Dimitar Douchkov. Deep phenotyping platform for microscopic plant- pathogen interactions.Frontiers in Plant Science, 16: 1462694, 2025
2025
-
[34]
Shoji Mano, Tomoki Miwa, Shuh-ichi Nishikawa, Tet- suro Mimura, and Mikio Nishimura. The plant or- ganelles database (podb): a collection of visualized plant organelles and protocols for plant organelle re- search.Nucleic acids research, 36(suppl 1):D929– D937, 2007
2007
-
[35]
The plant or- ganelles database 3 (podb3) update 2014: integrating electron micrographs and new options for plant or- ganelle research.Plant and Cell Physiology, 55(1): e1–e1, 2014
Shoji Mano, Takanori Nakamura, Maki Kondo, Tomoki Miwa, Shuh-ichi Nishikawa, Tetsuro Mimura, Akira Nagatani, and Mikio Nishimura. The plant or- ganelles database 3 (podb3) update 2014: integrating electron micrographs and new options for plant or- ganelle research.Plant and Cell Physiology, 55(1): e1–e1, 2014
2014
-
[36]
Genetic control of cell division patterns in developing plants.Cell, 88(3):299–308, 1997
Elliot M Meyerowitz. Genetic control of cell division patterns in developing plants.Cell, 88(3):299–308, 1997
1997
-
[37]
Using deep learning for image-based plant disease detection.Frontiers in plant science, 7: 215232, 2016
Sharada P Mohanty, David P Hughes, and Marcel Salath´e. Using deep learning for image-based plant disease detection.Frontiers in plant science, 7: 215232, 2016
2016
-
[38]
A cnn-and self-attention-based maize growth stage recognition method and platform from uav orthophoto images.Re- mote Sensing, 16(14):2672, 2024
Xindong Ni, Faming Wang, Hao Huang, Ling Wang, Changkai Wen, and Du Chen. A cnn-and self-attention-based maize growth stage recognition method and platform from uav orthophoto images.Re- mote Sensing, 16(14):2672, 2024
2024
-
[39]
Gpt-4o mini, 2024
OpenAI. Gpt-4o mini, 2024. Accessed: 2025-11-11
2024
-
[40]
Introducing gpt-5, 2025
OpenAI. Introducing gpt-5, 2025
2025
-
[41]
Gpt-5 mini, 2025
OpenAI. Gpt-5 mini, 2025. Accessed: 2025-11-11
2025
-
[42]
Multiscale imaging of plant development by light-sheet fluorescence microscopy.Nature plants, 4 (9):639–650, 2018
Miroslav Ove ˇcka, Daniel von Wangenheim, Pavel Tomanˇc´ak, Olga ˇSamajov´a, George Komis, and Jozef ˇSamaj. Multiscale imaging of plant development by light-sheet fluorescence microscopy.Nature plants, 4 (9):639–650, 2018
2018
-
[43]
Karolina Pawlak and Małgorzata Kołodziejczak. The role of agriculture in ensuring food security in devel- oping countries: Considerations in the context of the problem of sustainable food production.Sustainabil- ity, 12(13):5488, 2020
2020
-
[44]
Imaging flow- ers: a guide to current microscopy and tomography techniques to study flower development.Journal of experimental botany, 71(10):2898–2909, 2020
Nathana ¨el Prunet and Keith Duncan. Imaging flow- ers: a guide to current microscopy and tomography techniques to study flower development.Journal of experimental botany, 71(10):2898–2909, 2020
2020
-
[45]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sas- try, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[46]
You only look once: Unified, real-time object detection
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 779–788, 2016
2016
-
[47]
Faster r-cnn: Towards real-time object detection with region proposal networks.Advances in neural information processing systems, 28, 2015
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks.Advances in neural information processing systems, 28, 2015
2015
-
[48]
Jos ´e S Rufi ´an, Alberto P Macho, David S Corry, John W Mansfield, Javier Ruiz-Albert, Dawn L Arnold, and Carmen R Beuz ´on. Confocal mi- croscopy reveals in planta dynamic interactions be- tween pathogenic, avirulent and non-pathogenic pseu- domonas syringae strains.Molecular plant pathology, 19(3):537–551, 2018
2018
-
[49]
Agrobench: Vision-language model benchmark in agriculture
Risa Shinoda, Nakamasa Inoue, Hirokatsu Kataoka, Masaki Onishi, and Yoshitaka Ushiku. Agrobench: Vision-language model benchmark in agriculture. In Proceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 7634–7644, 2025
2025
-
[50]
Plant- doc: A dataset for visual plant disease detection
Davinder Singh, Naman Jain, Pranjali Jain, Pratik Kayal, Sudhakar Kumawat, and Nipun Batra. Plant- doc: A dataset for visual plant disease detection. In Proceedings of the 7th ACM IKDD CoDS and 25th COMAD, pages 249–253. 2020
2020
-
[51]
Imaging dataset of fresh hydrous plants obtained by field-emission scan- ning electron microscopy conducted using a protective nanosuit.PloS one, 15(5):e0232992, 2020
Sayuri Takehara, Yasuharu Takaku, Masatsugu Shi- momura, and Takahiko Hariyama. Imaging dataset of fresh hydrous plants obtained by field-emission scan- ning electron microscopy conducted using a protective nanosuit.PloS one, 15(5):e0232992, 2020
2020
-
[52]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
A re- view on weed detection using ground-based machine vision and image processing techniques.Computers and electronics in agriculture, 158:226–240, 2019
Aichen Wang, Wen Zhang, and Xinhua Wei. A re- view on weed detection using ground-based machine vision and image processing techniques.Computers and electronics in agriculture, 158:226–240, 2019
2019
-
[54]
T-cnn: Trilinear convolutional neural networks model for visual detection of plant diseases.Comput- ers and Electronics in Agriculture, 190:106468, 2021
Dongfang Wang, Jun Wang, Wenrui Li, and Ping Guan. T-cnn: Trilinear convolutional neural networks model for visual detection of plant diseases.Comput- ers and Electronics in Agriculture, 190:106468, 2021
2021
-
[55]
Agri-cm3: A chinese massive multi-modal, multi-level benchmark for agricultural understanding and reasoning
Haotian Wang, Yi Guan, Fanshu Meng, Chao Zhao, Lian Yan, Yang Yang, and Jingchi Jiang. Agri-cm3: A chinese massive multi-modal, multi-level benchmark for agricultural understanding and reasoning. InPro- ceedings of the 63rd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 11729–11754, 2025
2025
-
[56]
The global wheat full semantic organ segmentation (gwfss) dataset.bioRxiv, pages 2025–03, 2025
Zijian Wang, Radek Zenkl, Latifa Greche, Benoit De Solan, Lucas Bernigaud Samatan, Safaa Ouahid, Andrea Visioni, Carlos A Robles-Zazueta, Francisco Pinto, Ivan Perez-Olivera, et al. The global wheat full semantic organ segmentation (gwfss) dataset.bioRxiv, pages 2025–03, 2025
2025
-
[57]
Chain-of-thought prompting elicits reasoning in large language models.Advances in neural informa- tion processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural informa- tion processing systems, 35:24824–24837, 2022
2022
-
[58]
Bench- marking in-the-wild multimodal disease recognition and a versatile baseline
Tianqi Wei, Zhi Chen, Zi Huang, and Xin Yu. Bench- marking in-the-wild multimodal disease recognition and a versatile baseline. InProceedings of the 32nd ACM International Conference on Multimedia, pages 1593–1601, 2024
2024
-
[59]
Snap and diagnose: An advanced multimodal retrieval system for identify- ing plant diseases in the wild
Tianqi Wei, Zhi Chen, and Xin Yu. Snap and diagnose: An advanced multimodal retrieval system for identify- ing plant diseases in the wild. InProceedings of the 6th ACM International Conference on Multimedia in Asia, pages 1–3, 2024
2024
-
[60]
Tianqi Wei, Zhi Chen, Xin Yu, Scott Chapman, Paul Melloy, and Zi Huang. Plantseg: A large-scale in- the-wild dataset for plant disease segmentation.arXiv preprint arXiv:2409.04038, 2024
-
[61]
Tianqi Wei, Xin Yu, Zhi Chen, Scott Chapman, and Zi Huang. Augment to segment: Tackling pixel-level im- balance in wheat disease and pest segmentation.arXiv preprint arXiv:2509.09961, 2025
-
[62]
Crop identification using deep learning on lucas crop cover photos.Sen- sors, 23(14):6298, 2023
Momchil Yordanov, Rapha ¨el d’Andrimont, Laura Martinez-Sanchez, Guido Lemoine, Dominique Fas- bender, and Marijn Van der Velde. Crop identification using deep learning on lucas crop cover photos.Sen- sors, 23(14):6298, 2023
2023
-
[63]
Lit: Zero-shot transfer with locked- image text tuning
Xiaohua Zhai, Xiao Wang, Basil Mustafa, Andreas Steiner, Daniel Keysers, Alexander Kolesnikov, and Lucas Beyer. Lit: Zero-shot transfer with locked- image text tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, pages 18123–18133, 2022
2022
-
[64]
Wheat-net: An automatic dense wheat spike segmentation method based on an opti- mized hybrid task cascade model.Frontiers in Plant Science, 13:834938, 2022
Jiajing Zhang, An Min, Brian J Steffenson, Wen-Hao Su, Cory D Hirsch, James Anderson, Jian Wei, Qin Ma, and Ce Yang. Wheat-net: An automatic dense wheat spike segmentation method based on an opti- mized hybrid task cascade model.Frontiers in Plant Science, 13:834938, 2022
2022
-
[65]
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hanwen Xu, Jaspreet Bagga, Robert Tinn, Sam Preston, Ra- jesh Rao, Mu Wei, Naveen Valluri, et al. Biomedclip: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs.arXiv preprint arXiv:2303.00915, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[66]
Deep learn- ing based multi-temporal crop classification.Remote sensing of environment, 221:430–443, 2019
Liheng Zhong, Lina Hu, and Hang Zhou. Deep learn- ing based multi-temporal crop classification.Remote sensing of environment, 221:430–443, 2019
2019
-
[67]
Cucum- ber pathogenic spores’ detection using the gcs-yolov8 network with microscopic images in natural scenes
Xinyi Zhu, Feifei Chen, Chen Qiao, Yiding Zhang, Lingxian Zhang, Wei Gao, and Yong Wang. Cucum- ber pathogenic spores’ detection using the gcs-yolov8 network with microscopic images in natural scenes. Plant Methods, 20(1):131, 2024
2024
-
[68]
Baokai Zu, Tong Cao, Yafang Li, Jianqiang Li, Fu- jiao Ju, and Hongyuan Wang. Swint-srnet: Swin transformer with image super-resolution reconstruc- tion network for pollen images classification.En- gineering Applications of Artificial Intelligence, 133: 108041, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.