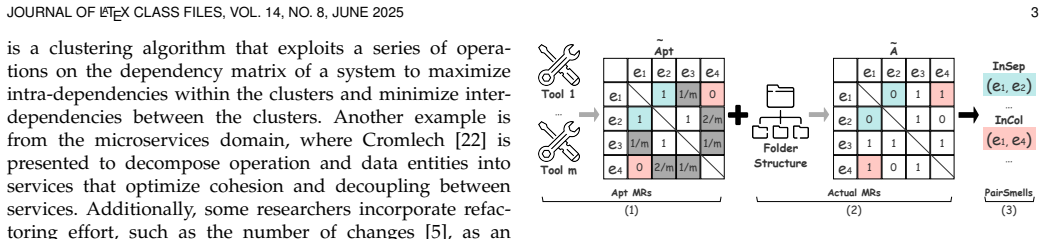
What Characterizes Pairwise Modular Smells?
Pith reviewed 2026-06-26 09:50 UTC · model grok-4.3
The pith
Pair characteristics like dependencies and shared terms predict pairwise modular smells, improving model performance by up to 58.6%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
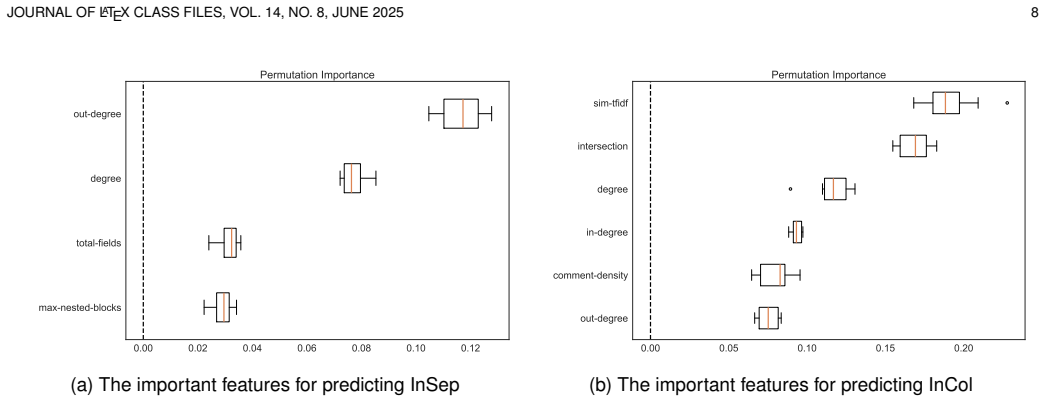
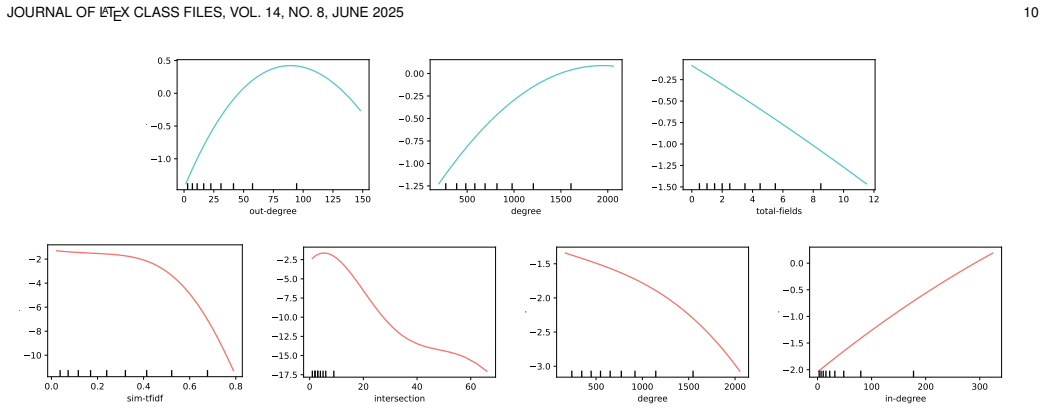
The central claim is that 19 pair characteristics suffice to train predictive models for PairSmells, with out-going dependencies, terms shared with others, and declared fields emerging as the strongest signals for inapt separated pairs while tf-idf semantic similarity, terms shared between the pair, terms shared with others, and in-going dependencies dominate for inapt collocated pairs.
What carries the argument
Machine learning models trained on the 19 pair characteristics, with post-hoc interpretation to rank feature influence on InSep and InCol predictions.
If this is right
- Refactoring effort can be directed first at pairs exhibiting the identified high-influence characteristics.
- Architectural reviews gain concrete, measurable signals rather than relying solely on subjective judgment.
- The same feature set can be reused to flag candidate PairSmells automatically before manual inspection.
- Practical examples demonstrate direct links between specific characteristics and the occurrence of each smell type.
Where Pith is reading between the lines
- The same modeling pipeline could be applied to non-Java systems to test whether the influential features generalize across languages.
- Embedding the top features into static analysis tools would allow early detection during development rather than post-hoc review.
- Causal studies could check whether altering the influential characteristics actually reduces the incidence of PairSmells.
- The large dataset size implies the approach remains feasible for industrial-scale codebases.
Load-bearing premise
The rapid review captured all relevant pair characteristics and the dataset of 6,135,000 pairs accurately represents real PairSmells without labeling errors or selection bias.
What would settle it
Retraining and interpreting the models on a fresh set of projects where the listed top features no longer rank highest or where ROC-AUC gains fall below the reported threshold.
Figures






read the original abstract
Enhancing the modular structure of existing systems has attracted substantial research interest, primarily through (1) software modularization and (2) identifying design issues (e.g., smells) as refactoring opportunities; however, both approaches often prove impractical to guide effective improvement. Inspired by both aforementioned approaches, our previous study introduced a novel and practical architectural smell -- called Pairwise Modular Smell (or PairSmell) -- for identifying flawed architectural decisions that necessitate further examination. The objective of this study is to explain PairSmell from the perspective of pair characteristics. To this end, we first conduct a rapid review to collect and synthesize 19 pair characteristics that have been used in the literature to represent relationships between two entities. The collected characteristics are then used to train machine learning models for predicting two forms of PairSmell -- inapt separated pairs InSep and inapt collocated pairs InCol, based on a curated dataset of over 6,135,000 pairs of entities derived from 11 open-source Java projects. The trained models achieve up to a 58.6% improvement in ROC-AUC over the baselines. The interpretation of the models reveals that the most influential features for InSep are out-going dependencies, terms shared with others, and declared fields; while those for InCol include semantic similarity based on tf-idf, terms shared between the pair, terms shared with others, and in-going dependencies. We complement the work with a series of practical examples to illustrate how the influential pair characteristics impact the occurrence of PairSmell.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a rapid review yields 19 pair characteristics from the literature; these are used as features to train ML models that predict two forms of PairSmell (InSep and InCol) on a curated dataset of 6,135,000 entity pairs drawn from 11 Java projects. The models reportedly deliver up to a 58.6% ROC-AUC lift over baselines, and post-hoc interpretation identifies outgoing dependencies, shared terms, declared fields (for InSep) and tf-idf similarity, shared terms, incoming dependencies (for InCol) as most influential. Practical examples are supplied to illustrate the findings.
Significance. If the labeling procedure is shown to be independent of the 19 characteristics, the work supplies the first large-scale, interpretable empirical mapping from pair-level metrics to architectural smells. The scale of the dataset and the emphasis on model interpretation constitute a concrete advance over purely qualitative discussions of modularization.
major comments (2)
- [Abstract] Abstract and dataset-construction section: the paper states only that the 6.1 M-pair dataset was 'curated' from 11 projects and that labels for InSep and InCol were assigned. No description is given of the ground-truth labeling rule, its relation to the prior PairSmell paper, or any safeguard against overlap with the 19 characteristics later used as features (out-going dependencies, shared terms, tf-idf, declared fields, etc.). Because the central claims are a 58.6 % ROC-AUC gain and the ranking of exactly those features, any correlation between labeling and features renders both the performance numbers and the SHAP-style attributions circular.
- [Evaluation] Model-training and evaluation section: the manuscript reports ROC-AUC improvements but supplies no information on training/validation splits, cross-validation strategy, hyper-parameter selection, baseline definitions, or class-imbalance handling. Without these details the 58.6 % figure cannot be reproduced or assessed for robustness, undermining the claim that the 19 characteristics 'explain' PairSmell.
minor comments (2)
- [Rapid Review] The rapid-review protocol (search strings, databases, inclusion/exclusion criteria, number of papers screened) is mentioned only in passing; a short table or paragraph would allow readers to judge coverage of the 19 characteristics.
- [Interpretation] Feature names in the interpretation tables should be aligned exactly with the definitions given in the rapid-review synthesis so that readers can map 'terms shared with others' back to the original characteristic.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify important omissions in the description of labeling and evaluation procedures. We will revise the manuscript to supply the requested details, which will strengthen reproducibility and address concerns about potential circularity.
read point-by-point responses
-
Referee: [Abstract] Abstract and dataset-construction section: the paper states only that the 6.1 M-pair dataset was 'curated' from 11 projects and that labels for InSep and InCol were assigned. No description is given of the ground-truth labeling rule, its relation to the prior PairSmell paper, or any safeguard against overlap with the 19 characteristics later used as features (out-going dependencies, shared terms, tf-idf, declared fields, etc.). Because the central claims are a 58.6 % ROC-AUC gain and the ranking of exactly those features, any correlation between labeling and features renders both the performance numbers and the SHAP-style attributions circular.
Authors: The ground-truth labels follow the definition of PairSmell (InSep and InCol) introduced in our prior work. The 19 characteristics were collected separately through a rapid review of the literature on entity-pair relationships and are not used in the labeling process. In the revision we will add an explicit subsection describing the labeling rule, its direct link to the previous paper, and safeguards (including manual verification examples) demonstrating independence from the 19 features. This will allow readers to confirm that the reported performance and feature attributions are not circular. revision: yes
-
Referee: [Evaluation] Model-training and evaluation section: the manuscript reports ROC-AUC improvements but supplies no information on training/validation splits, cross-validation strategy, hyper-parameter selection, baseline definitions, or class-imbalance handling. Without these details the 58.6 % figure cannot be reproduced or assessed for robustness, undermining the claim that the 19 characteristics 'explain' PairSmell.
Authors: We agree these details are required for reproducibility. The revision will expand the evaluation section with the exact train/validation split ratios, cross-validation procedure (including number of folds), hyper-parameter tuning method, precise definitions of all baselines, and the technique used to address class imbalance. Additional robustness checks (e.g., stratified splits) will also be reported. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper first performs an independent rapid review to synthesize 19 pair characteristics from the literature, then trains supervised models on a curated dataset of 6.1M pairs to predict PairSmell labels defined in a prior study. Model performance (ROC-AUC lift) and feature attributions are evaluated directly against held-out project data. No equation, definition, or self-citation reduces the central claims to the input features by construction; the labeling procedure is external to the 19 characteristics collected here, and the self-citation to the prior PairSmell paper supplies only the target labels rather than the explanatory variables or the uniqueness of the result.
Axiom & Free-Parameter Ledger
free parameters (1)
- ML model hyperparameters
axioms (1)
- domain assumption Pair characteristics from literature review are appropriate predictors for PairSmells
Reference graph
Works this paper leans on
-
[1]
C. Y. Baldwin and K. B. Clark,Design rules: The power of modularity. MIT press, 2000, vol. 1
2000
-
[2]
An empirical analysis of the costs of clone-and platform-oriented software reuse,
J. Kr ¨uger and T. Berger, “An empirical analysis of the costs of clone-and platform-oriented software reuse,” inProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2020, pp. 432–444
2020
-
[3]
Decomposition of monolith applications into microservices architectures: A sys- tematic review,
Y. Abgaz, A. McCarren, P . Elger, D. Solan, N. Lapuz, M. Bivol, G. Jackson, M. Yilmaz, J. Buckley, and P . Clarke, “Decomposition of monolith applications into microservices architectures: A sys- tematic review,”IEEE Transactions on Software Engineering, 2023
2023
-
[4]
Reposvul: A repository-level high-quality vulnerability dataset,
X. Wang, R. Hu, C. Gao, X.-C. Wen, Y. Chen, and Q. Liao, “Reposvul: A repository-level high-quality vulnerability dataset,” inProceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings, 2024, pp. 472–483. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, JUNE 2025 16
2024
-
[5]
Search-based software re-modularization: A case study at adyen,
C. Schr ¨oder, A. van der Feltz, A. Panichella, and M. Aniche, “Search-based software re-modularization: A case study at adyen,” inProceedings of the 43rd International Conference on Software Engineering: Software Engineering in Practice. IEEE, 2021, pp. 81–90
2021
-
[6]
A fast clustering algorithm for modularization of large-scale software systems,
N. Teymourian, H. Izadkhah, and A. Isazadeh, “A fast clustering algorithm for modularization of large-scale software systems,” IEEE Transactions on Software Engineering, vol. 48, no. 4, pp. 1451– 1462, 2022
2022
-
[7]
A graph- based clustering algorithm for software systems modularization,
B. Pourasghar, H. Izadkhah, A. Isazadeh, and S. Lotfi, “A graph- based clustering algorithm for software systems modularization,” Information and Software Technology, vol. 133, p. 106469, 2021
2021
-
[8]
Using cohesion and coupling for software remodularization: Is it enough?
I. Candela, G. Bavota, B. Russo, and R. Oliveto, “Using cohesion and coupling for software remodularization: Is it enough?”ACM Transactions on Software Engineering and Methodology, vol. 25, no. 3, pp. 1–28, 2016
2016
-
[9]
Detecting the locations and predicting the costs of compound architectural debts,
L. Xiao, Y. Cai, R. Kazman, R. Mo, and Q. Feng, “Detecting the locations and predicting the costs of compound architectural debts,”IEEE Transactions on Software Engineering, vol. 48, no. 9, pp. 3686–3715, 2022
2022
-
[10]
A systematic mapping study on architectural smells detection,
H. Mumtaz, P . Singh, and K. Blincoe, “A systematic mapping study on architectural smells detection,”Journal of Systems and Software, vol. 173, p. 110885, 2021
2021
-
[11]
Design pattern decay: The case for class grime,
I. Griffith and C. Izurieta, “Design pattern decay: The case for class grime,” inProceedings of the 8th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement. ACM, 2014, pp. 1–4
2014
-
[12]
Software design analysis and technical debt management based on design rule theory,
Y. Cai and R. Kazman, “Software design analysis and technical debt management based on design rule theory,”Information and Software Technology, vol. 164, p. 107322, 2023. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S0950584923001775
2023
-
[13]
Arcan: A tool for architectural smells detection,
F. A. Fontana, I. Pigazzini, R. Roveda, D. Tamburri, M. Zanoni, and E. Di Nitto, “Arcan: A tool for architectural smells detection,” inProceedings of the 2017 IEEE International Conference on Software Architecture Workshops. IEEE, 2017, pp. 282–285
2017
-
[14]
A decision support system to refactor class cycles,
T. D. Oyetoyan, D. S. Cruzes, and C. Thurmann-Nielsen, “A decision support system to refactor class cycles,” inProceedings of the 31th IEEE International Conference on Software Maintenance and Evolution. IEEE, 2015, pp. 231–240
2015
-
[15]
Pairsmell: A novel perspective inspecting software modular structure,
C. Zhong, D. Feitosa, P . Avgeriou, H. Huang, Y. Li, and H. Zhang, “Pairsmell: A novel perspective inspecting software modular structure,” inProceedings of the 47th International Conference on Software Engineering. IEEE, 2025, pp. 1–12
2025
-
[16]
Identi- fying architectural bad smells,
J. Garcia, D. Popescu, G. Edwards, and N. Medvidovic, “Identi- fying architectural bad smells,” inProceedings of the 13th European Conference on Software Maintenance and Reengineering. IEEE, 2009, pp. 255–258
2009
-
[17]
Combining multiple clusterings using evidence accumulation,
A. L. Fred and A. K. Jain, “Combining multiple clusterings using evidence accumulation,”IEEE transactions on Pattern Analysis and Machine Intelligence, vol. 27, no. 6, pp. 835–850, 2005
2005
-
[18]
Weighted clustering ensemble: A review,
M. Zhang, “Weighted clustering ensemble: A review,”Pattern Recognition, vol. 124, p. 108428, 2022
2022
-
[19]
Software module clustering: An in-depth literature analysis,
Q. I. Sarhan, B. S. Ahmed, M. Bures, and K. Z. Zamli, “Software module clustering: An in-depth literature analysis,”IEEE Transac- tions on Software Engineering, vol. 48, no. 6, pp. 1905–1928, 2022
1905
-
[20]
Enhancing software modularization via semantic outliers filtration and label propagation,
K. Yang, J. Wang, Z. Fang, P . Wu, and Z. Song, “Enhancing software modularization via semantic outliers filtration and label propagation,”Information and Software Technology, vol. 145, p. 106818, 2022
2022
-
[21]
On the automatic modulariza- tion of software systems using the bunch tool,
B. S. Mitchell and S. Mancoridis, “On the automatic modulariza- tion of software systems using the bunch tool,”IEEE Transactions on Software Engineering, vol. 32, no. 3, pp. 193–208, 2006
2006
-
[22]
Cromlech: Semi-automated monolith decomposition into microservices,
G. Quattrocchi, D. Cocco, S. Staffa, A. Margara, and G. Cu- gola, “Cromlech: Semi-automated monolith decomposition into microservices,”IEEE Transactions on Services Computing, 2024
2024
-
[23]
A precise method-method interaction-based cohesion metric for object-oriented classes,
J. Al Dallal and L. C. Briand, “A precise method-method interaction-based cohesion metric for object-oriented classes,” ACM Transactions on Software Engineering and Methodology, vol. 21, no. 2, pp. 1–34, 2012
2012
-
[24]
Architecture anti-patterns: Automatically detectable violations of design prin- ciples,
R. Mo, Y. Cai, R. Kazman, L. Xiao, and Q. Feng, “Architecture anti-patterns: Automatically detectable violations of design prin- ciples,”IEEE Transactions on Software Engineering, vol. 47, no. 5, pp. 1008–1028, 2019
2019
-
[25]
Prevalence and severity of design anti-patterns in open source programs—a large-scale study,
A. Liu, J. Lefever, Y. Han, and Y. Cai, “Prevalence and severity of design anti-patterns in open source programs—a large-scale study,”Information and Software Technology, vol. 170, p. 107429, 2024
2024
-
[26]
Decoupling level: A new metric for architectural maintenance complexity,
R. Mo, Y. Cai, R. Kazman, L. Xiao, and Q. Feng, “Decoupling level: A new metric for architectural maintenance complexity,” inPro- ceedings of the 38th International Conference on Software Engineering. IEEE, 2016, pp. 499–510
2016
-
[27]
Using indirect coupling metrics to predict package maintainability and testability,
S. Almugrin, W. Albattah, and A. Melton, “Using indirect coupling metrics to predict package maintainability and testability,”Journal of Systems and Software, vol. 121, pp. 298–310, 2016
2016
-
[28]
Cohesion-driven decomposition of service inter- faces without access to source code,
D. Athanasopoulos, A. V . Zarras, G. Miskos, V . Issarny, and P . Vassiliadis, “Cohesion-driven decomposition of service inter- faces without access to source code,”IEEE Transactions on Services Computing, vol. 8, no. 4, pp. 550–562, 2014
2014
-
[29]
On measuring coupling between microservices,
C. Zhong, H. Zhang, C. Li, H. Huang, and D. Feitosa, “On measuring coupling between microservices,”Journal of Systems and Software, p. 111670, 2023
2023
-
[30]
Detecting software mod- ularity violations,
S. Wong, Y. Cai, M. Kim, and M. Dalton, “Detecting software mod- ularity violations,” inProceedings of the 33rd International Conference on Software Engineering, 2011, pp. 411–420
2011
-
[31]
An empirical study of architectural decay in open-source software,
D. M. Le, D. Link, A. Shahbazian, and N. Medvidovic, “An empirical study of architectural decay in open-source software,” inProceedings of the 15th International Conference on Software Archi- tecture. IEEE, 2018, pp. 176–17 609
2018
-
[32]
Hotspot patterns: The formal definition and automatic detection of architecture smells,
R. Mo, Y. Cai, R. Kazman, and L. Xiao, “Hotspot patterns: The formal definition and automatic detection of architecture smells,” inProceedings of the 12th Working IEEE/IFIP Conference on Software Architecture. IEEE, 2015, pp. 51–60
2015
-
[33]
Shull, J
F. Shull, J. Singer, and D. I. Sjøberg,Guide to advanced empirical software engineering. Springer, 2008, vol. 93
2008
-
[34]
A scoping review of rapid review methods,
A. C. Tricco, J. Antony, W. Zarin, L. Strifler, M. Ghassemi, J. Ivory, L. Perrier, B. Hutton, D. Moher, and S. E. Straus, “A scoping review of rapid review methods,”BMC Medicine, vol. 13, pp. 1–15, 2015
2015
-
[35]
Recommended steps for thematic synthesis in software engineering,
D. S. Cruzes and T. Dyba, “Recommended steps for thematic synthesis in software engineering,” inProceedings of the 5th Inter- national Symposium on Empirical Software Engineering and Measure- ment. IEEE, 2011, pp. 275–284
2011
-
[36]
Kitchenham and S
B. Kitchenham and S. Charters,Guidelines for performing systematic literature reviews in software engineering. Keele, UK, 2007
2007
-
[37]
Splitting a large software repository for easing future software evolu- tion—an industrial experience report,
M. Glorie, A. Zaidman, A. van Deursen, and L. Hofland, “Splitting a large software repository for easing future software evolu- tion—an industrial experience report,”Journal of Software Mainte- nance and Evolution: Research and Practice, vol. 21, no. 2, pp. 113–141, 2009
2009
-
[38]
Automatic software refactoring via weighted clustering in method-level net- works,
Y. Wang, H. Yu, Z. Zhu, W. Zhang, and Y. Zhao, “Automatic software refactoring via weighted clustering in method-level net- works,”IEEE Transactions on Software Engineering, vol. 44, no. 3, pp. 202–236, 2017
2017
-
[39]
Depends,
“Depends,” https://github.com/multilang-depends/depends, 2022
2022
-
[40]
“Ctags,” https://github.com/universal-ctags/ctags, 2022
2022
-
[41]
“Nltk,” https://www.nltk.org/, 2023
2023
-
[42]
Scikit-learn,
“Scikit-learn,” https://scikit-learn.org/stable/whats new/v1.4. html#version-1-4-1, 2024
2024
-
[43]
“Ck,” https://github.com/mauricioaniche/ck/releases/tag/ ck-0.7.0, 2022
2022
-
[44]
“Cloc,” https://github.com/AlDanial/cloc/commits/v2.00, 2024
2024
-
[45]
Introducing a ripple effect measure: A theoretical and empirical validation,
E.-M. Arvanitou, A. Ampatzoglou, A. Chatzigeorgiou, and P . Avgeriou, “Introducing a ripple effect measure: A theoretical and empirical validation,” inProceedings of the 9th International Symposium on Empirical Software Engineering and Measurement. IEEE, 2015, pp. 1–10
2015
-
[46]
R. C. Martin,Clean code: A craftsman’s guide to software structure and design. Pearson Education, 2018
2018
-
[47]
Newman,Building microservices
S. Newman,Building microservices. O’Reilly Media, 2021
2021
-
[48]
Sample-based non-uniform random variate gener- ation,
L. Devroye, “Sample-based non-uniform random variate gener- ation,” inProceedings of the 18th Conference on Winter Simulation, 1986, pp. 260–265
1986
-
[49]
Are fix-inducing changes a moving target? a longitudinal case study of just-in-time defect prediction,
S. McIntosh and Y. Kamei, “Are fix-inducing changes a moving target? a longitudinal case study of just-in-time defect prediction,” inProceedings of the 40th International Conference on Software Engi- neering, 2018, pp. 560–560
2018
-
[50]
Spearman,The proof and measurement of association between two things.Appleton-Century-Crofts, 1961
C. Spearman,The proof and measurement of association between two things.Appleton-Century-Crofts, 1961
1961
-
[51]
A first look at good first issues on github,
X. Tan, M. Zhou, and Z. Sun, “A first look at good first issues on github,” inProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2020, pp. 398–409. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, JUNE 2025 17
2020
-
[52]
Characterizing timeout builds in continuous integration,
N. Weeraddana, M. Alfadel, and S. McIntosh, “Characterizing timeout builds in continuous integration,”IEEE Transactions on Software Engineering, 2024
2024
-
[53]
The meaning and use of the area under a receiver operating characteristic (roc) curve,
J. A. Hanley and B. J. McNeil, “The meaning and use of the area under a receiver operating characteristic (roc) curve,”Radiology, vol. 143, no. 1, pp. 29–36, 1982
1982
-
[54]
Area under the precision- recall curve: Point estimates and confidence intervals,
K. Boyd, K. H. Eng, and C. D. Page, “Area under the precision- recall curve: Point estimates and confidence intervals,” inPro- ceedings of the 2013 European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 2013, pp. 451–466
2013
-
[55]
D. W. Hosmer Jr, S. Lemeshow, and R. X. Sturdivant,Applied logistic regression. John Wiley & Sons, 2013
2013
-
[56]
Support vector machines,
M. Awad and L. Khan, “Support vector machines,” inIntelligent Information Technologies: Concepts, Methodologies, Tools, and Applica- tions. IGI Global, 2008, pp. 1138–1146
2008
-
[57]
A random forest guided tour,
G. Biau and E. Scornet, “A random forest guided tour,”Test, vol. 25, no. 2, pp. 197–227, 2016
2016
-
[58]
The precision-recall plot is more informative than the roc plot when evaluating binary classifiers on imbalanced datasets,
T. Saito and M. Rehmsmeier, “The precision-recall plot is more informative than the roc plot when evaluating binary classifiers on imbalanced datasets,”PloS one, vol. 10, no. 3, p. e0118432, 2015
2015
-
[59]
Molnar,Interpretable machine learning
C. Molnar,Interpretable machine learning. Lulu. com, 2020
2020
-
[60]
On a test of whether one of two random variables is stochastically larger than the other,
H. B. Mann and D. R. Whitney, “On a test of whether one of two random variables is stochastically larger than the other,”The Annals of Mathematical Statistics, pp. 50–60, 1947
1947
-
[61]
Fowler,Refactoring
M. Fowler,Refactoring. Addison-Wesley Professional, 2018
2018
-
[62]
Code smell,
——, “Code smell,” 2006. [Online]. Available: https: //martinfowler.com/bliki/CodeSmell.html
2006
-
[63]
Quantifying the effect of code smells on maintenance effort,
D. I. Sjøberg, A. Yamashita, B. C. Anda, A. Mockus, and T. Dyb ˚a, “Quantifying the effect of code smells on maintenance effort,” IEEE Transactions on Software Engineering, vol. 39, no. 8, pp. 1144– 1156, 2012
2012
-
[64]
Do code smells reflect important maintainability aspects?
A. Yamashita and L. Moonen, “Do code smells reflect important maintainability aspects?” inProceedings of the 28th IEEE Interna- tional Conference on Software Maintenance. IEEE, 2012, pp. 306–315
2012
-
[65]
Dependency facade: The coupling and conflicts between android framework and its customization,
W. Jin, Y. Dai, J. Zheng, Y. Qu, M. Fan, Z. Huang, D. Huang, and T. Liu, “Dependency facade: The coupling and conflicts between android framework and its customization,” inProceedings of the IEEE/ACM 45th International Conference on Software Engineering. IEEE, 2023, pp. 1674–1686
2023
-
[66]
An automatic extraction approach: Tran- sition to microservices architecture from monolithic application,
S. Eski and F. Buzluca, “An automatic extraction approach: Tran- sition to microservices architecture from monolithic application,” inProceedings of the 19th International Conference on Agile Software Development: Companion, 2018, pp. 1–6
2018
-
[67]
A novel com- munity detection based genetic algorithm for feature selection,
M. Rostami, K. Berahmand, and S. Forouzandeh, “A novel com- munity detection based genetic algorithm for feature selection,” Journal of Big Data, vol. 8, no. 1, p. 2, 2021
2021
-
[68]
Service candidate identification from monolithic systems based on exe- cution traces,
W. Jin, T. Liu, Y. Cai, R. Kazman, R. Mo, and Q. Zheng, “Service candidate identification from monolithic systems based on exe- cution traces,”IEEE Transactions on Software Engineering, vol. 47, no. 5, pp. 987–1007, 2019
2019
-
[69]
Mono2micro: A practical and effective tool for decomposing monolithic java applications to microservices,
A. K. Kalia, J. Xiao, R. Krishna, S. Sinha, M. Vukovic, and D. Baner- jee, “Mono2micro: A practical and effective tool for decomposing monolithic java applications to microservices,” inProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2021, pp. 1214–1224
2021
-
[70]
Eism: An interactive and collab- orative approach for software modularization,
C. Zhong, C. Li, and H. Zhang, “Eism: An interactive and collab- orative approach for software modularization,”Journal of Systems and Software, p. 112726, 2025
2025
-
[71]
Refac- toring microservices to microservices in support of evolutionary design,
C. Zhong, S. Li, H. Zhang, H. Huang, L. Yang, and Y. Cai, “Refac- toring microservices to microservices in support of evolutionary design,”IEEE transactions on software engineering, 2024
2024
-
[72]
Using automatic clustering to produce high-level system organi- zations of source code,
S. Mancoridis, B. S. Mitchell, C. Rorres, Y. Chen, and E. R. Gansner, “Using automatic clustering to produce high-level system organi- zations of source code,” inProceedings of 6th International Workshop on Program Comprehension. IEEE, 1998, pp. 45–52
1998
-
[73]
An architectural technical debt index based on machine learning and architectural smells,
D. Sas and P . Avgeriou, “An architectural technical debt index based on machine learning and architectural smells,”IEEE Trans- actions on Software Engineering, vol. 49, no. 8, pp. 4169–4195, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.