Skin-Deep: A Geometric Diagnostic for Alignment Fragility in Large Language Model Representations
Pith reviewed 2026-06-26 10:20 UTC · model grok-4.3
The pith
A geometric score from aligned model activations predicts which models retain the most refusal after fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
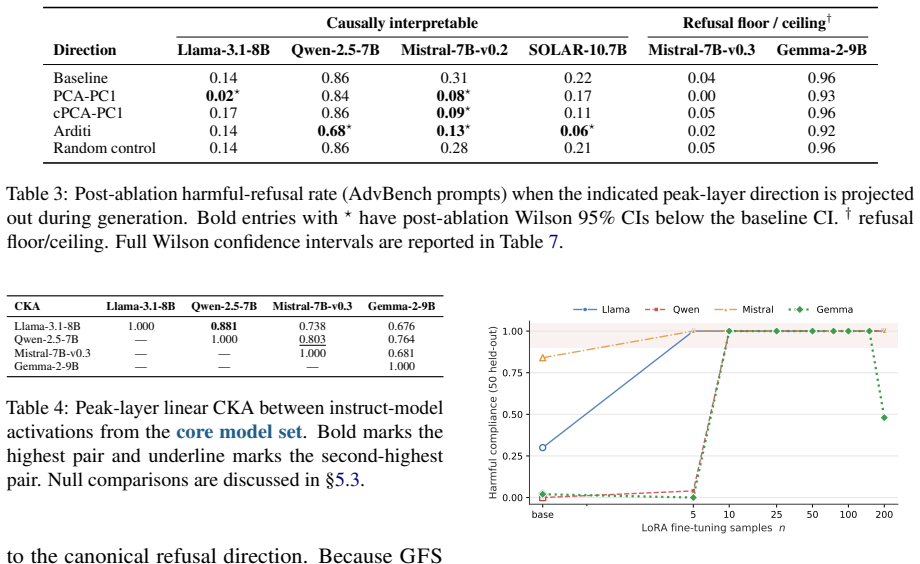
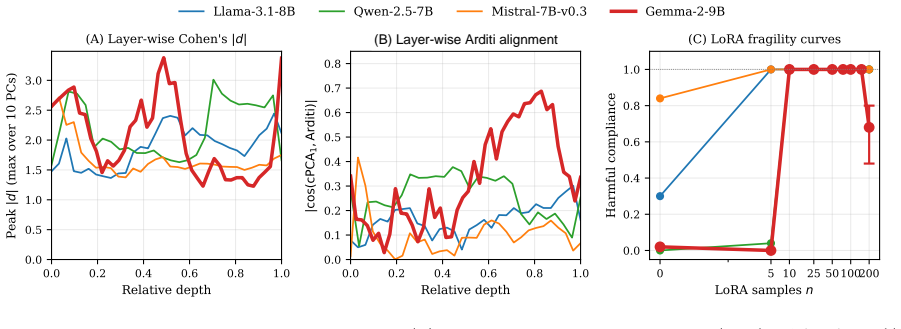
Skin-Deep identifies a recurring low-rank safety subspace in the activation space of aligned models. Direction ablations confirm that this subspace is causally linked to harmful-request refusal. The Geometric Fragility Score compresses the layer-wise geometry of this subspace into a scalar that, without any fine-tuning, correctly ranks models by how much refusal they will retain after small-scale LoRA fine-tuning on benign data.
What carries the argument
The low-rank safety subspace recovered from hidden-state activations, summarized by the Geometric Fragility Score (GFS) that measures alignment fragility.
If this is right
- Models showing a stronger or more stable safety subspace will lose less refusal capability under fine-tuning.
- The safety subspace is recoverable from activations alone and consistent across model families from 3B to 32B parameters.
- Removing directions from the subspace directly reduces refusal rates, confirming its role in the behavior.
- GFS provides a way to screen models for fragility prior to release or deployment without simulating attacks.
Where Pith is reading between the lines
- If the subspace is low-rank, interventions targeting it could make alignment more robust to fine-tuning.
- This geometric approach might apply to measuring other model properties like factual consistency encoded in activations.
- Developers could use GFS to choose among alignment recipes the one producing the most stable safety geometry.
Load-bearing premise
The low-rank directions identified in activations directly cause the refusal behavior and their geometric properties determine how well refusal survives fine-tuning.
What would settle it
Running the fine-tuning experiments and finding that GFS does not correlate with or predict the post-fine-tuning refusal retention rates across the 21 models tested.
Figures

read the original abstract
Alignment tuning is meant to make harmful-request refusal robust, yet this safety behavior can be erased by a small set of benign fine-tuning examples. This is a deployment risk for open-weight models because a checkpoint can pass refusal tests at release time and later lose refusal under low-cost downstream fine-tuning. Prior work has established these refusal failures, but existing studies do not show how to detect this fragility in the aligned model itself before an attack or fine-tuning intervention is run. We introduce Skin-Deep, a geometric diagnostic that detects alignment fragility directly from the aligned model's hidden-state activations before such an intervention is run and compresses the layer-wise safety geometry into a single scalar, the Geometric Fragility Score (GFS). Applied to twenty-one instruction-tuned models spanning six alignment recipes and 3B--32B parameters, Skin-Deep reveals a recurring low-rank safety subspace across model families. Direction ablations show that removing directions in this subspace weakens harmful-request refusal, providing causal evidence that the recovered geometry underlies refusal behavior. Crucially, GFS identifies, before any fine-tuning, the initially safe model that retains the most refusal after small-scale LoRA fine-tuning. These results establish GFS as a practical pre-deployment diagnostic for flagging fragile refusal behavior without running an attack.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Skin-Deep, a geometric diagnostic that recovers a low-rank safety subspace from hidden-state activations of aligned LLMs and compresses it into the scalar Geometric Fragility Score (GFS). Applied to 21 instruction-tuned models (3B–32B parameters, six alignment recipes), it reports that direction ablations in this subspace weaken harmful-request refusal and that GFS, computed before any intervention, identifies the initially safe model that retains the highest refusal rate after small-scale benign LoRA fine-tuning.
Significance. If the central results hold, the work is significant for AI safety evaluation: it supplies a pre-deployment, attack-free diagnostic for refusal fragility that generalizes across model families and directly predicts downstream fine-tuning outcomes. The causal ablation evidence and the scale of the 21-model study are particular strengths; reproducible code or parameter-free derivations are not mentioned.
major comments (2)
- [§4.3] §4.3 (predictive evaluation): the claim that GFS 'identifies... the initially safe model that retains the most refusal' requires the full ranking or Spearman correlation across all 21 models; reporting only the single best model leaves open whether GFS outperforms simple baselines such as model size or initial refusal rate.
- [§3.2] §3.2 (subspace recovery): the low-rank safety subspace is recovered via a procedure whose exact rank-selection rule and layer-aggregation method are not shown to be robust; an ablation varying the rank hyperparameter is needed because the 'recurring low-rank' claim is load-bearing for both the causal and predictive results.
minor comments (2)
- [Figure 3] Figure 3 caption and axis labels should explicitly state the refusal metric (e.g., percentage of harmful prompts refused) and the exact fine-tuning dataset size.
- [Related Work] The manuscript cites prior refusal-erasure work but does not compare GFS against the refusal-score baselines used in those papers; adding this comparison would strengthen the novelty claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§4.3] §4.3 (predictive evaluation): the claim that GFS 'identifies... the initially safe model that retains the most refusal' requires the full ranking or Spearman correlation across all 21 models; reporting only the single best model leaves open whether GFS outperforms simple baselines such as model size or initial refusal rate.
Authors: We agree that reporting only the single best model is insufficient to fully substantiate the predictive claim. In the revised manuscript we will add the complete ranking of all 21 models by GFS together with the Spearman correlation between GFS and post-fine-tuning refusal retention; we will also include direct comparisons against the baselines of model size and initial refusal rate to demonstrate whether GFS supplies additional predictive information. revision: yes
-
Referee: [§3.2] §3.2 (subspace recovery): the low-rank safety subspace is recovered via a procedure whose exact rank-selection rule and layer-aggregation method are not shown to be robust; an ablation varying the rank hyperparameter is needed because the 'recurring low-rank' claim is load-bearing for both the causal and predictive results.
Authors: We acknowledge that an explicit robustness check on rank choice is warranted. We will add an ablation that varies the rank hyperparameter over a small integer range and report that the key causal ablation results and the GFS predictive correlations remain stable for the low ranks consistent with our recurring low-rank observation. We will also clarify the precise rank-selection rule and layer-aggregation procedure in the revised §3.2. revision: yes
Circularity Check
No significant circularity
full rationale
The paper recovers a low-rank safety subspace from activations, performs direction ablations to demonstrate causal impact on refusal (an independent intervention test), and then computes GFS to rank models by their post-LoRA refusal retention across 21 models from multiple families. This predictive step is an empirical correlation on held-out fine-tuning outcomes rather than a quantity fitted or defined from the same data. No equations, self-citations, or ansatzes are shown that reduce the central claim to its inputs by construction. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Refusal in language models is mediated by a single direction , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
Representation Engineering: A Top-Down Approach to
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and others , journal=. Representation Engineering: A Top-Down Approach to
-
[3]
arXiv preprint arXiv:2307.15043 , year=
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
-
[4]
Jailbroken: How Does
Wei, Alexander and Haghtalab, Nika and Steinhardt, Jacob , booktitle=. Jailbroken: How Does
-
[5]
International Conference on Learning Representations (ICLR) , year=
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To! , author=. International Conference on Learning Representations (ICLR) , year=
-
[6]
Mazeika, Mantas and Phan, Long and Yin, Xuwang and Zou, Andy and Wang, Zifan and Mu, Norman and Sakhaee, Elham and Li, Nathaniel and Basart, Steven and Li, Bo and others , booktitle=
-
[7]
Advances in Neural Information Processing Systems , volume=
Beavertails: Towards improved safety alignment of llm via a human-preference dataset , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Training Language Models to Follow Instructions with Human Feedback , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[9]
arXiv preprint arXiv:2204.05862 , year=
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback , author=. arXiv preprint arXiv:2204.05862 , year=
-
[10]
Harrison Lee and Samrat Phatale and Hassan Mansoor and Thomas Mesnard and Johan Ferret and Kellie Lu and Colton Bishop and Ethan Hall and Victor Carbune and Abhinav Rastogi and Sushant Prakash , year =. 2309.00267 , archivePrefix =
-
[11]
Manning and Chelsea Finn , year =
Rafael Rafailov and Archit Sharma and Eric Mitchell and Stefano Ermon and Christopher D. Manning and Chelsea Finn , year =. 2305.18290 , archivePrefix =
-
[12]
Jiwoo Hong and Noah Lee and James Thorne , year =. 2403.07691 , archivePrefix =
-
[13]
Guan Wang and Sijie Cheng and Xianyuan Zhan and Xiangang Li and Sen Song and Yang Liu , year =. 2309.11235 , archivePrefix =
-
[14]
International Conference on Machine Learning (ICML) , year=
Similarity of Neural Network Representations Revisited , author=. International Conference on Machine Learning (ICML) , year=
-
[15]
Nature Communications , volume=
Exploring Patterns Enriched in a Dataset with Contrastive Principal Component Analysis , author=. Nature Communications , volume=
-
[16]
Austral Ecology , volume=
A New Method for Non-parametric Multivariate Analysis of Variance , author=. Austral Ecology , volume=
-
[17]
Journal of Machine Learning Research , volume=
A Kernel Two-Sample Test , author=. Journal of Machine Learning Research , volume=
-
[18]
Journal of the Royal Statistical Society: Series B , volume=
Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing , author=. Journal of the Royal Statistical Society: Series B , volume=
-
[19]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=
-
[20]
Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and others , journal=. The
-
[21]
arXiv preprint arXiv:2412.15115 , year=
-
[22]
Jiang, Albert Q. and Sablayrolles, Alexandre and Mensch, Arthur and Bamford, Chris and Chaplot, Devendra Singh and de las Casas, Diego and Bressand, Florian and Lengyel, Gianna and Lample, Guillaume and Saulnier, Lucile and others , journal=
-
[23]
arXiv preprint arXiv:2408.00118 , year=
-
[24]
ICLR Workshop , year=
Understanding Intermediate Layers Using Linear Classifier Probes , author=. ICLR Workshop , year=
-
[25]
arXiv preprint arXiv:2303.08112 , year=
Eliciting Latent Predictions from Transformers with the Tuned Lens , author=. arXiv preprint arXiv:2303.08112 , year=
-
[26]
arXiv preprint arXiv:2312.06681 , year=
Steering llama 2 via contrastive activation addition , author=. arXiv preprint arXiv:2312.06681 , year=
-
[27]
International Conference on Machine Learning (ICML) , year=
Assessing the Brittleness of Safety Alignment via Pruning and Low-Rank Modifications , author=. International Conference on Machine Learning (ICML) , year=
-
[28]
and Mihalcea, Rada , booktitle=
Lee, Andrew and Bai, Xiaoyan and Pres, Itamar and Wattenberg, Martin and Kummerfeld, Jonathan K. and Mihalcea, Rada , booktitle=. A Mechanistic Understanding of Alignment Algorithms: A Case Study on
-
[29]
2024 , publisher=
Scaling monosemanticity: Extracting interpretable features from claude 3 sonnet , author=. 2024 , publisher=
2024
-
[30]
Cui, Justin and Chiang, Wei-Lin and Stoica, Ion and Hsieh, Cho-Jui , journal=
-
[31]
arXiv preprint arXiv:2310.02949 , year=
Shadow Alignment: The Ease of Subverting Safely-Aligned Language Models , author=. arXiv preprint arXiv:2310.02949 , year=
-
[32]
Lermen, Simon and Rogers-Smith, Charlie and Ladish, Jeffrey , booktitle=
-
[33]
Zhou, Chunting and Liu, Pengfei and Xu, Puxin and Iyer, Srinivasan and Sun, Jiao and Mao, Yuning and Ma, Xuezhe and Efrat, Avia and Yu, Ping and Yu, Lili and others , booktitle=
-
[34]
Latent Adversarial Training Improves Robustness to Persistent Harmful Behaviors in
Sheshadri, Abhay and Ewart, Aidan and Guo, Phillip and Lynch, Aengus and Wu, Cindy and Hebbar, Vivek and Sleight, Henry and Stickland, Asa Cooper and Perez, Ethan and Hadfield-Menell, Dylan and Casper, Stephen , journal=. Latent Adversarial Training Improves Robustness to Persistent Harmful Behaviors in
-
[35]
International Conference on Machine Learning (ICML) , year=
On Prompt-Driven Safeguarding for Large Language Models , author=. International Conference on Machine Learning (ICML) , year=
-
[36]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Grounding Representation Similarity Through Statistical Testing , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[37]
arXiv preprint arXiv:2312.06674 , year=
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations , author=. arXiv preprint arXiv:2312.06674 , year=
-
[38]
2024 , eprint =
The Llama 3 Herd of Models , author =. 2024 , eprint =
2024
-
[39]
2013 , publisher=
Statistical power analysis for the behavioral sciences , author=. 2013 , publisher=
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.