Disk-Based Interval Indexes Under the Increasing Ending Time Assumption
Pith reviewed 2026-06-26 06:47 UTC · model grok-4.3
The pith
Under the assumption that intervals arrive in increasing end-time order, two new disk-based indexes achieve smaller size, faster insertions, and quicker queries than prior methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By mapping intervals to 2D corner representations and enforcing the increasing ending time arrival order, the two-layer append-only B+-tree indexes CEB and TIDE deliver smaller index sizes, faster insertions, and faster query processing than existing competitors, with TIDE sometimes faster by orders of magnitude.
What carries the argument
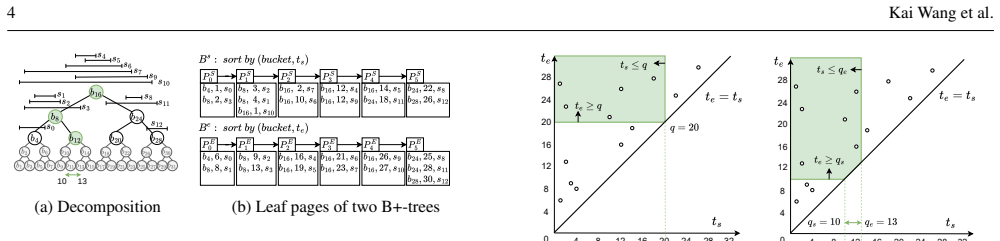
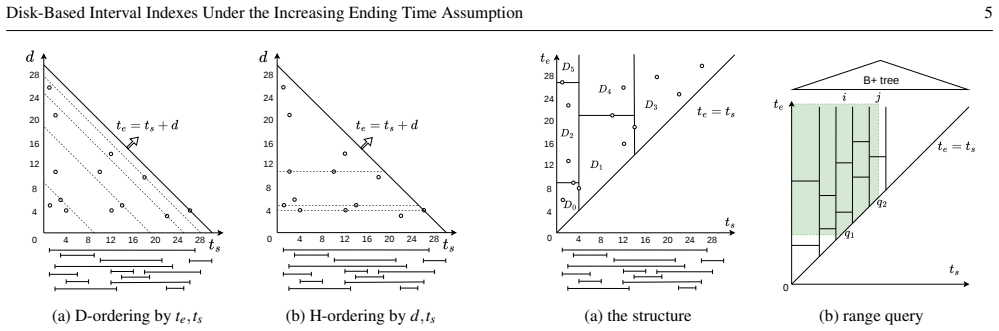
Two-layer append-only B+-tree architecture in which the leaf nodes of a top tree (ordering by center or duration) serve as roots of bottom trees (ordering by endpoint).
If this is right
- Temporal databases can store larger interval collections within the same disk budget.
- High-rate interval arrivals incur lower insertion latency.
- Range and point queries on lifespans complete with fewer disk accesses.
- The corner-space view lets query processors skip entire subtrees that cannot contain answers.
Where Pith is reading between the lines
- The same two-layer append-only design could apply to other monotonically ordered streams such as sensor readings or versioned records.
- Hybrid indexes might combine the IET assumption with additional ordering constraints to further reduce node fan-out.
- The corner representation offers a general template for turning any interval workload into a pair of 1D ordering problems.
- If the IET assumption holds only approximately, a small buffer or reordering layer could restore most of the reported gains.
Load-bearing premise
Intervals arrive in order of increasing ending time.
What would settle it
Run the same insertion and query workloads with intervals presented out of increasing-ending-time order and check whether CEB and TIDE lose their reported size and speed advantages over the prior indexes.
Figures


















read the original abstract
Indexes for large collections of intervals are common in temporal databases, where each record has a lifespan, or validity interval. Despite their conceptual differences, we demonstrate that interval indexes can be captured by some corner structure in a 2D space. This representation facilitates the optimization of query processing by identifying nodes that must contain query results versus nodes that may contain results. In addition, we explore the assumption that intervals arrive in order of increasing ending time (IET) to develop disk-based indexes that have compact size, efficient insertions, and fast query processing. Specifically, we first develop CEB, an index in the corner space defined by the interval center and endpoint. Our second contribution is TIDE, which organizes intervals by their duration and endpoint. CEB and TIDE adopt a two-layer architecture, where the leaf nodes of a top tree (ordering intervals by their center or duration) correspond to the root nodes of bottom trees, ordering intervals by their endpoints. Both top and bottom trees are append-only B+-trees to facilitate fast insertions. CEB and TIDE outperform state-of-the-art competitors in terms of index size and insertion speed. In addition, TIDE is always faster in query processing, sometimes by orders of magnitude.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that under the Increasing Ending Time (IET) assumption, interval indexes can be represented via corner structures in 2D space. It introduces CEB (center-endpoint) and TIDE (duration-endpoint) as two-layer disk-based indexes using append-only B+-trees, achieving compact size and fast insertions; TIDE additionally provides faster query processing than competitors, sometimes by orders of magnitude.
Significance. If the IET assumption is realistic for target workloads, the two-layer append-only design and corner-based query optimization could yield practical gains in storage and performance for temporal databases. The explicit exploitation of arrival order for append-only structures is a clear technical contribution when the assumption holds.
major comments (1)
- [Abstract] Abstract: All claimed advantages (compact size via append-only B+-trees, fast insertions, TIDE query speed) are derived from the strictly increasing ending-time arrival order. The manuscript does not quantify how often real interval collections satisfy IET or test performance under mild violations, which is load-bearing for the practical significance of the results.
Simulated Author's Rebuttal
We thank the referee for highlighting the dependence of our results on the IET assumption. We address this point directly below and will revise the manuscript accordingly to better scope the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: All claimed advantages (compact size via append-only B+-trees, fast insertions, TIDE query speed) are derived from the strictly increasing ending-time arrival order. The manuscript does not quantify how often real interval collections satisfy IET or test performance under mild violations, which is load-bearing for the practical significance of the results.
Authors: We agree that the reported advantages of CEB and TIDE are predicated on the IET assumption, which is stated in the title, abstract, and throughout the paper. The work targets workloads (e.g., append-only temporal logs and event streams) where ending times are non-decreasing upon arrival; the two-layer append-only B+-tree design and corner-based pruning are direct consequences of this ordering. We will revise the abstract to foreground this scope more explicitly. On quantification, the manuscript does not contain a broad empirical survey of real interval collections, as our focus is the algorithmic exploitation of IET when it holds. We will add a dedicated discussion subsection on the assumption's prevalence in targeted domains and the expected behavior under mild violations (performance would fall back toward that of a standard B+-tree without the append-only optimizations). We did not evaluate non-IET workloads because the indexes are specialized for the IET case; such experiments would require a different design. revision: partial
Circularity Check
No circularity; constructions are conditional on external IET assumption
full rationale
The paper defines CEB and TIDE as two-layer append-only B+-tree indexes whose compactness and insertion efficiency are explicitly derived from the stated IET arrival assumption rather than from any self-referential equation, fitted parameter renamed as prediction, or self-citation chain. No equations appear in the abstract or description that reduce claimed performance metrics to the paper's own outputs by construction. The IET premise is presented as an input assumption whose real-world prevalence is outside the derivation; this is a modeling choice, not a circular reduction. The central claims therefore remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Intervals arrive in order of increasing ending time (IET)
invented entities (2)
-
CEB index
no independent evidence
-
TIDE index
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sketches-based join size estimation under local differential privacy
Amagata, D.: Independent range sampling on interval data. In: 2024 IEEE 40th International Conference on Data Engineering (ICDE), pp. 449–461 (2024). DOI 10.1109/ICDE60146.2024. 00041
-
[2]
In: Proceedings of 37th Conference on Foun- dations of Computer Science, pp
Arge, L., Vitter, J.: Optimal dynamic interval management in ex- ternal memory. In: Proceedings of 37th Conference on Foun- dations of Computer Science, pp. 560–569. IEEE Comput. Soc. Press (1996). DOI 10.1109/SFCS.1996.548515
-
[3]
SIGMOD Rec.19(2), 322–331 (1990)
Beckmann, N., Kriegel, H.P., Schneider, R., Seeger, B.: The r*- tree: an efficient and robust access method for points and rectan- gles. SIGMOD Rec.19(2), 322–331 (1990). DOI 10.1145/93605. 98741. URLhttps://doi.org/10.1145/93605.98741
-
[4]
In: Proceedings of the 16th Inter- national Symposium on Spatial and Temporal Databases, SSTD ’19, p
Behrend, A., Dign ¨os, A., Gamper, J., Schmiegelt, P., V oigt, H., Rottmann, M., Kahl, K.: Period index: A learned 2d hash index for range and duration queries. In: Proceedings of the 16th Inter- national Symposium on Spatial and Temporal Databases, SSTD ’19, p. 100–109. Association for Computing Machinery, New York, NY , USA (2019). DOI 10.1145/3340964.3...
-
[5]
Berg, M.d., Cheong, O., Kreveld, M.v., Overmars, M.: Compu- tational Geometry: Algorithms and Applications, 3rd ed. edn. Springer-Verlag TELOS, Santa Clara, CA, USA (2008)
2008
-
[6]
IEEE Transactions on Knowledge and Data Engineering (2025)
Bouros, P., Christodoulou, G., Rauch, C., Titkov, A., Mamoulis, N.: Querying interval data on steroids. IEEE Transactions on Knowledge and Data Engineering (2025)
2025
-
[7]
The VLDB Journal30(4), 667–691 (2021)
Bouros, P., Mamoulis, N., Tsitsigkos, D., Terrovitis, M.: In- memory interval joins. The VLDB Journal30(4), 667–691 (2021). DOI 10.1007/s00778-020-00639-0. URLhttps://doi.org/ 10.1007/s00778-020-00639-0
-
[8]
In: Proceedings of the 55th An- nual ACM Symposium on Theory of Computing, STOC 2023, p
Brodal, G.S., Rysgaard, C.M., Svenning, R.: External memory fully persistent search trees. In: Proceedings of the 55th An- nual ACM Symposium on Theory of Computing, STOC 2023, p. 1410–1423. Association for Computing Machinery, New York, NY , USA (2023). DOI 10.1145/3564246.3585140. URLhttps: //doi.org/10.1145/3564246.3585140
-
[9]
Ceccarello, M., Dign ¨os, A., Gamper, J., Khnaisser, C.: Index- ing temporal relations for range-duration queries. In: Pro- ceedings of the 35th International Conference on Scientific and Statistical Database Management, SSDBM ’23. Association for Computing Machinery, New York, NY , USA (2023). DOI 10.1145/3603719.3603732. URLhttps://doi.org/10.1145/ 3603...
-
[10]
In: Proceedings of the 2022 International Conference on Management of Data, SIGMOD ’22, p
Christodoulou, G., Bouros, P., Mamoulis, N.: Hint: A hierarchical index for intervals in main memory. In: Proceedings of the 2022 International Conference on Management of Data, SIGMOD ’22, p. 1257–1270. Association for Computing Machinery, New York, NY , USA (2022). DOI 10.1145/3514221.3517873. URLhttps: //doi.org/10.1145/3514221.3517873
-
[11]
Christodoulou, G., Bouros, P., Mamoulis, N.: Lit: Lightning-fast in-memory temporal indexing. Proc. ACM Manag. Data2(1) Disk-Based Interval Indexes Under the Increasing Ending Time Assumption 17 (2024). DOI 10.1145/3639275. URLhttps://doi.org/10. 1145/3639275
-
[12]
Data in Brief51, 109,749 (2023)
Costa, D., La Cava, L., Tagarelli, A.: Unraveling the nft econ- omy: A comprehensive collection of non-fungible token transac- tions and metadata. Data in Brief51, 109,749 (2023)
2023
-
[13]
In: 2010 IEEE 26th International Conference on Data Engineering (ICDE 2010), pp
Cudre-Mauroux, P., Wu, E., Madden, S.: Trajstore: An adaptive storage system for very large trajectory data sets. In: 2010 IEEE 26th International Conference on Data Engineering (ICDE 2010), pp. 109–120. IEEE (2010)
2010
-
[14]
GeoInformatica9(1), 33–60 (2005)
De Almeida, V .T., G¨uting, R.H.: Indexing the trajectories of mov- ing objects in networks. GeoInformatica9(1), 33–60 (2005)
2005
-
[15]
In: Proceedings of the Eighteenth An- nual ACM Symposium on Theory of Computing, STOC ’86, p
Driscoll, J.R., Sarnak, N., Sleator, D.D., Tarjan, R.E.: Making data structures persistent. In: Proceedings of the Eighteenth An- nual ACM Symposium on Theory of Computing, STOC ’86, p. 109–121. Association for Computing Machinery, New York, NY , USA (1986). DOI 10.1145/12130.12142. URLhttps://doi. org/10.1145/12130.12142
-
[16]
Technical Report p
Edelsbrunner, H.: Dynamic rectangle intersection searching. Technical Report p. 47 (1980)
1980
-
[17]
In: Proceedings of the Sixteenth In- ternational Conference on Very Large Databases, p
Elmasri, R., Wuu, G.T.J., Kim, Y .J.: The time index—an access structure for temporal data. In: Proceedings of the Sixteenth In- ternational Conference on Very Large Databases, p. 1–12. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA (1990)
1990
-
[18]
In: 22nd International Conference on Data Engineering (ICDE’06), p
Eltabakh, M., Eltarras, R., Aref, W.: Space-partitioning trees in postgresql: Realization and performance. In: 22nd International Conference on Data Engineering (ICDE’06), p. 100–100. IEEE (2006). DOI 10.1109/icde.2006.146. URLhttp://dx.doi. org/10.1109/ICDE.2006.146
-
[19]
In: Proceedings of the Seventh International Conference on Data Engineering, p
Faloutsos, C., Rong, Y .: Dot: A spatial access method using frac- tals. In: Proceedings of the Seventh International Conference on Data Engineering, p. 152–159. IEEE Computer Society, USA (1991)
1991
-
[20]
Gaede, V ., G¨unther, O.: Multidimensional access methods. ACM Comput. Surv.30(2), 170–231 (1998). DOI 10.1145/280277. 280279. URLhttps://doi.org/10.1145/280277.280279
-
[21]
Goh, C.H., Lu, H., Ooi, B.C., Tan, K.L.: Indexing temporal data using existing b+-trees. Data Knowl. Eng.18(2), 147–165 (1996). DOI 10.1016/0169-023X(95)00034-P. URLhttps: //doi.org/10.1016/0169-023X(95)00034-P
-
[22]
arXiv preprint arXiv:2403.03952 (2024)
Hou, Y ., Li, J., He, Z., Yan, A., Chen, X., McAuley, J.: Bridg- ing language and items for retrieval and recommendation. arXiv preprint arXiv:2403.03952 (2024)
Pith/arXiv arXiv 2024
-
[23]
In: Proceedings of the 2022 International Conference on Management of Data, SIGMOD ’22, p
Hu, X., Sintos, S., Gao, J., Agarwal, P.K., Yang, J.: Computing complex temporal join queries efficiently. In: Proceedings of the 2022 International Conference on Management of Data, SIGMOD ’22, p. 2076–2090. Association for Computing Machinery, New York, NY , USA (2022). DOI 10.1145/3514221.3517893. URL https://doi.org/10.1145/3514221.3517893
-
[24]
Kanellakis, P.C., Ramaswamy, S., Vengroff, D.E., Vitter, J.S.: In- dexing for data models with constraints and classes (extended ab- stract). In: Proceedings of the Twelfth ACM SIGACT-SIGMOD- SIGART Symposium on Principles of Database Systems, PODS ’93, p. 233–243. Association for Computing Machinery, New York, NY , USA (1993). DOI 10.1145/153850.153884. ...
-
[25]
SIGMOD Rec.20(2), 138–147 (1991)
Kolovson, C.P., Stonebraker, M.: Segment indexes: dynamic in- dexing techniques for multi-dimensional interval data. SIGMOD Rec.20(2), 138–147 (1991). DOI 10.1145/119995.115807. URL https://doi.org/10.1145/119995.115807
-
[26]
In: Proceedings of the 26th Inter- national Conference on Very Large Data Bases, VLDB ’00, p
Kriegel, H.P., P ¨otke, M., Seidl, T.: Managing intervals efficiently in object-relational databases. In: Proceedings of the 26th Inter- national Conference on Very Large Data Bases, VLDB ’00, p. 407–418. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA (2000)
2000
-
[27]
ACM SIGMOD Record20(2), 426–435 (1991)
Lanka, S., Mays, E.: Fully persistent b+-trees. ACM SIGMOD Record20(2), 426–435 (1991)
1991
-
[28]
Lu, W., Zhao, Z., Wang, X., Li, H., Zhang, Z., Shui, Z., Ye, S., Pan, A., Du, X.: A lightweight and efficient temporal database man- agement system in tdsql. Proc. VLDB Endow.12(12), 2035–2046 (2019). DOI 10.14778/3352063.3352122. URLhttps://doi. org/10.14778/3352063.3352122
-
[29]
In: Foundations of Data Organization, pp
Nievergelt, J., Hinrichs, K.: Storage and access structures for geo- metric data bases. In: Foundations of Data Organization, pp. 441–
-
[30]
In: Proceedings of the 2004 ACM SIG- MOD international conference on Management of data, pp
Patel, J.M., Chen, Y ., Chakka, V .P.: Stripes: an efficient index for predicted trajectories. In: Proceedings of the 2004 ACM SIG- MOD international conference on Management of data, pp. 635– 646 (2004)
2004
-
[31]
Salzberg, B., Tsotras, V .J.: Comparison of access methods for time-evolving data. ACM Comput. Surv.31(2), 158–221 (1999). DOI 10.1145/319806.319816. URLhttps://doi.org/10. 1145/319806.319816
-
[32]
In: Proceedings of the 14th International Conference on Very Large Data Bases, VLDB ’88, p
Seeger, B., Kriegel, H.P.: Techniques for design and implementa- tion of efficient spatial access methods. In: Proceedings of the 14th International Conference on Very Large Data Bases, VLDB ’88, p. 360–371. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA (1988)
1988
-
[33]
Segev, A., Gunadhi, H.: Efficient indexing methods for temporal relations. IEEE Trans. on Knowl. and Data Eng.5(3), 496–509 (1993). DOI 10.1109/69.224200. URLhttps://doi.org/10. 1109/69.224200
-
[34]
In: Proceedings of the 13th International Conference on Very Large Data Bases, VLDB ’87, p
Sellis, T.K., Roussopoulos, N., Faloutsos, C.: The r+-tree: A dy- namic index for multi-dimensional objects. In: Proceedings of the 13th International Conference on Very Large Data Bases, VLDB ’87, p. 507–518. Morgan Kaufmann Publishers Inc., San Fran- cisco, CA, USA (1987)
1987
-
[35]
In: Proceedings of the 4th International Conference on Mobile Data Management, MDM ’03, p
Song, Z., Roussopoulos, N.: Seb-tree: An approach to index con- tinuously moving objects. In: Proceedings of the 4th International Conference on Mobile Data Management, MDM ’03, p. 340–344. Springer-Verlag, Berlin, Heidelberg (2003)
2003
-
[36]
U, L.H., Mamoulis, N., Berberich, K., Bedathur, S.: Durable top-k search in document archives. In: Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data, SIG- MOD ’10, p. 555–566. Association for Computing Machinery, New York, NY , USA (2010). DOI 10.1145/1807167.1807228. URLhttps://doi.org/10.1145/1807167.1807228
-
[37]
Vitter, J.S.: External memory algorithms and data structures: deal- ing with massive data. ACM Comput. Surv.33(2), 209–271 (2001). DOI 10.1145/384192.384193. URLhttps://doi.org/ 10.1145/384192.384193
-
[38]
In: Proceed- ings of the The Ninth International Conference on Mobile Data Management, MDM ’08, p
Wang, L., Zheng, Y ., Xie, X., Ma, W.Y .: A flexible spatio-temporal indexing scheme for large-scale gps track retrieval. In: Proceed- ings of the The Ninth International Conference on Mobile Data Management, MDM ’08, p. 1–8. IEEE Computer Society, USA (2008). DOI 10.1109/MDM.2008.24. URLhttps://doi.org/ 10.1109/MDM.2008.24
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.