CoVStream: Edge-Cloud Collaboration for Understanding of Long Video Streams
Pith reviewed 2026-06-26 09:41 UTC · model grok-4.3
The pith
CoVStream splits long video streams between edge and cloud to cut bandwidth 87.6% while keeping 99.2% of full cloud accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
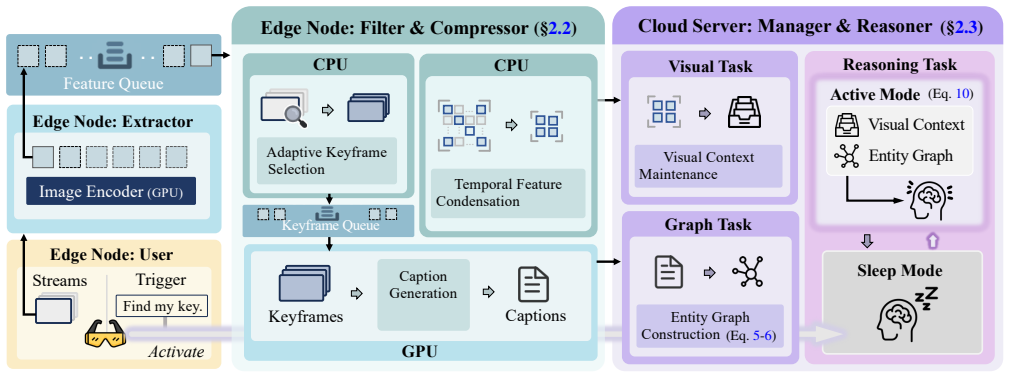
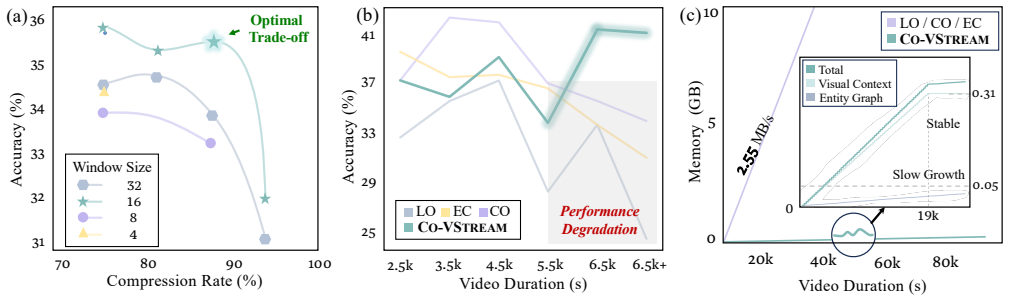
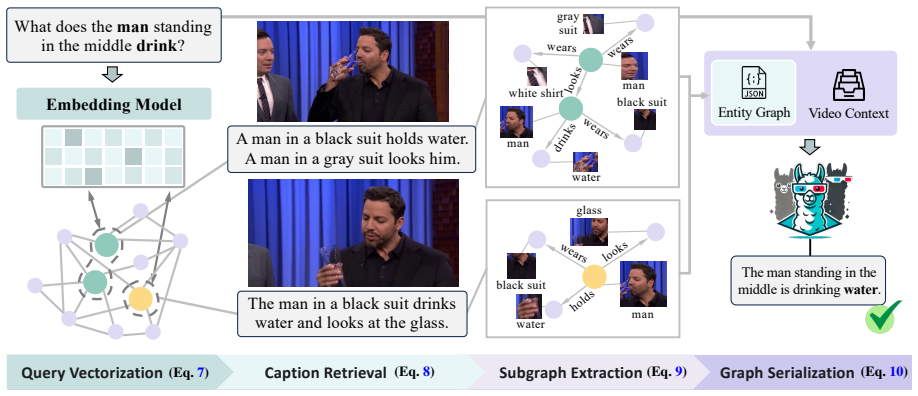
CoVStream is the first edge-cloud collaborative framework for long video stream understanding. The edge node distills raw video into compact visual features and semantic captions to minimize transmission, while the cloud integrates the received data into an entity graph and global visual context and activates its heavy reasoning model only upon user query arrival. On LVBench this yields an 87.6% bandwidth reduction while retaining 99.2% of the cloud baseline accuracy.
What carries the argument
Edge distillation of video into compact visual features and semantic captions, which the cloud then assembles into an entity graph and global context for query-triggered reasoning.
If this is right
- Continuous video streams can run indefinitely without prohibitive bandwidth costs.
- Large reasoning models stay resident in the cloud yet are invoked only on demand.
- Accuracy remains close to full cloud processing across VideoMME-Long, LVBench, and RTV-Bench.
- Query-based understanding becomes feasible for real-time streams from constrained capture devices.
Where Pith is reading between the lines
- The same distillation step could lower privacy risk by avoiding raw video transmission to the cloud.
- The framework might extend to other continuous sensor streams such as audio or multi-camera feeds.
- Reduced data volume could shorten end-to-end latency in surveillance or monitoring applications.
Load-bearing premise
The distilled features and captions sent from the edge preserve enough information for the cloud's entity graph and context to support accurate reasoning on arriving queries.
What would settle it
Measure accuracy on a long video dataset where important events are deliberately omitted from the edge-generated captions and features; a drop well below 99% of baseline would falsify the claim.
Figures

read the original abstract
Long, continuous video streams are an increasingly critical driver of multimedia intelligence. Existing efforts often handle long videos with a sample-encode-reason approach using large models. However, they overlook a crucial deployment fact: the stream is often produced by computationally constrained devices. This forces an untenable compromise: cloud offloading unlocks strong reasoning but incurs prohibitive bandwidth overhead, while on-device processing remains limited by edge hardware capacity. Therefore, we propose CoVStream, the first edge-cloud collaborative framework for understanding long video streams. The edge node distills raw video streams into compact visual features and semantic captions for transmission to the cloud, minimizing bandwidth costs, while the cloud server integrates this data into an entity graph and global visual context, activating the heavy reasoning model only when a user query arrives. Experiments on VideoMME-Long, LVBench, and RTV-Bench show that CoVStream reduces bandwidth usage by 87.6% while retaining 99.2% of the cloud baseline accuracy on LVBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CoVStream, the first edge-cloud collaborative framework for long video stream understanding. The edge node distills raw video into compact visual features and semantic captions for low-bandwidth transmission; the cloud integrates the received data into an entity graph and global visual context and activates a heavy reasoning model only upon query arrival. Experiments on VideoMME-Long, LVBench, and RTV-Bench are reported to show an 87.6% bandwidth reduction while retaining 99.2% of the cloud baseline accuracy on LVBench.
Significance. If the reported numbers hold under rigorous validation, the work would address a practical deployment barrier for continuous video intelligence by trading modest edge computation for large bandwidth savings without substantial accuracy loss. The query-triggered reasoning activation is a sensible systems-level idea for long streams.
major comments (2)
- [Abstract] Abstract: the headline claims of 87.6% bandwidth reduction and 99.2% accuracy retention are presented without any experimental details, baselines, error bars, dataset splits, or ablation results. Because these numbers constitute the central empirical claim, their unsupported presentation undermines assessment of whether the data actually support the contribution.
- [Experiments] Experiments section: no intermediate metrics (graph node recall, caption coverage of ground-truth events, or ablation that removes the entity-graph component) are supplied to verify that the edge distillation step preserves the information needed for the cloud to construct an entity graph and global context that later supports near-baseline reasoning. This preservation assumption is load-bearing for the accuracy-retention result.
minor comments (1)
- The manuscript would benefit from explicit discussion of edge-compute constraints that could cause systematic loss of rare entities or long-range temporal relations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claims of 87.6% bandwidth reduction and 99.2% accuracy retention are presented without any experimental details, baselines, error bars, dataset splits, or ablation results. Because these numbers constitute the central empirical claim, their unsupported presentation undermines assessment of whether the data actually support the contribution.
Authors: We agree that the abstract would benefit from more context for the headline results. The current abstract already names the three evaluation datasets and specifies the 99.2% figure is measured on LVBench, but it omits explicit references to baselines and error bars. We will revise the abstract to add a short clause noting that results are obtained against a full-cloud baseline with comparisons reported in the Experiments section. This keeps the abstract concise while directing readers to the supporting details. revision: yes
-
Referee: [Experiments] Experiments section: no intermediate metrics (graph node recall, caption coverage of ground-truth events, or ablation that removes the entity-graph component) are supplied to verify that the edge distillation step preserves the information needed for the cloud to construct an entity graph and global context that later supports near-baseline reasoning. This preservation assumption is load-bearing for the accuracy-retention result.
Authors: The referee correctly notes that intermediate metrics would provide stronger evidence for information preservation in the edge distillation step. The manuscript currently reports only end-to-end accuracy and bandwidth numbers across the three benchmarks. We will add the requested intermediate metrics (entity-graph node recall, caption coverage of ground-truth events) and an ablation removing the entity-graph component in a revised Experiments section, using the data already collected during our evaluation. revision: yes
Circularity Check
No circularity: empirical systems proposal with no derivations or self-referential fits
full rationale
The paper describes an edge-cloud framework and reports end-to-end experimental metrics (bandwidth reduction, accuracy retention) on VideoMME-Long, LVBench, and RTV-Bench. No equations, parameter-fitting steps, uniqueness theorems, or derivation chains appear in the provided text. Claims rest on measured outcomes rather than any quantity defined in terms of itself or predicted from a fitted subset. Self-citations, if present, are not load-bearing for any central result. This is a standard non-circular systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
CVPR , pages=
Ma-lmm: Memory-augmented large multimodal model for long-term video understanding , author=. CVPR , pages=
-
[2]
arXiv preprint arXiv:2606.07669 , year=
MemoVAD: Resource-Efficient Video Anomaly Detection via Dynamic Semantic Memory in Edge Computing Scenarios , author=. arXiv preprint arXiv:2606.07669 , year=
-
[3]
2025 , pages =
Wang, Hanling and Li, Qing and Chen, Li and Kang, Haidong and Ma, Fei and Jiang, Yong , title =. 2025 , pages =
2025
-
[4]
arXiv preprint arXiv:2601.04734 , year=
AIVD: Adaptive Edge-Cloud Collaboration for Accurate and Efficient Industrial Visual Detection , author=. arXiv preprint arXiv:2601.04734 , year=
-
[5]
ICCV , pages=
Videollamb: Long streaming video understanding with recurrent memory bridges , author=. ICCV , pages=
-
[6]
arXiv preprint arXiv:2406.11333 , year=
Hallucination mitigation prompts long-term video understanding , author=. arXiv preprint arXiv:2406.11333 , year=
-
[7]
arXiv preprint arXiv:2504.04471 , year=
VideoAgent2: Enhancing the LLM-Based Agent System for Long-Form Video Understanding by Uncertainty-Aware CoT , author=. arXiv preprint arXiv:2504.04471 , year=
-
[8]
arXiv preprint arXiv:2408.14023 , year=
Video-ccam: Enhancing video-language understanding with causal cross-attention masks for short and long videos , author=. arXiv preprint arXiv:2408.14023 , year=
-
[9]
arXiv preprint arXiv:2410.20252 , year=
Adaptive Video Understanding Agent: Enhancing efficiency with dynamic frame sampling and feedback-driven reasoning , author=. arXiv preprint arXiv:2410.20252 , year=
-
[10]
ECCV , pages=
Goldfish: Vision-language understanding of arbitrarily long videos , author=. ECCV , pages=
-
[11]
arXiv preprint arXiv:2312.05269 , year=
Lifelongmemory: Leveraging llms for answering queries in long-form egocentric videos , author=. arXiv preprint arXiv:2312.05269 , year=
-
[12]
StreamForest: efficient online video understanding with persistent event memory , year =
Zeng, Xiangyu and Qiu, Kefan and Zhang, Qingyu and Li, Xinhao and Wang, Jing and Li, Jiaxin and Yan, Ziang and Tian, Kun and Tian, Meng and Zhao, Xinhai and others , booktitle=. StreamForest: efficient online video understanding with persistent event memory , year =
-
[13]
NeurIPS , year=
Rtv-bench: Benchmarking mllm continuous perception, understanding and reasoning through real-time video , author=. NeurIPS , year=
-
[14]
NeurIPS , pages=
Streaming long video understanding with large language models , author=. NeurIPS , pages=
-
[15]
ICLR , year=
LongVILA: Scaling Long-Context Visual Language Models for Long Videos , author=. ICLR , year=
-
[16]
thinking with long videos
Longvt: Incentivizing" thinking with long videos" via native tool calling , author=. CVPR , pages=
-
[17]
CVPR , pages=
Building a Mind Palace: Structuring Environment-Grounded Semantic Graphs for Effective Long Video Analysis with LLMs , author=. CVPR , pages=
-
[18]
ICML , year=
LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding , author=. ICML , year=
-
[19]
CVPR , pages=
Video-xl: Extra-long vision language model for hour-scale video understanding , author=. CVPR , pages=
-
[20]
Yongdong Luo and Xiawu Zheng and Guilin Li and Shukang Yin and Haojia Lin and Chaoyou Fu and Jinfa Huang and Jiayi Ji and Fei Chao and Jiebo Luo and Rongrong Ji , booktitle=. Video-
-
[21]
arXiv preprint arXiv:2510.18866 , year=
Lightmem: Lightweight and efficient memory-augmented generation , author=. arXiv preprint arXiv:2510.18866 , year=
-
[22]
ECCV , pages=
Longvlm: Efficient long video understanding via large language models , author=. ECCV , pages=
-
[23]
ECCV , pages=
Llama-vid: An image is worth 2 tokens in large language models , author=. ECCV , pages=
-
[24]
ACM MM , pages=
Vitcot: Video-text interleaved chain-of-thought for boosting video understanding in large language models , author=. ACM MM , pages=
-
[25]
arXiv preprint arXiv:2406.16852 , year=
Long context transfer from language to vision , author=. arXiv preprint arXiv:2406.16852 , year=
-
[26]
ECCV , pages=
Videoagent: Long-form video understanding with large language model as agent , author=. ECCV , pages=
-
[27]
CVPR , pages=
SEAL: Semantic Attention Learning for Long Video Representation , author=. CVPR , pages=
-
[28]
CVPR , pages=
Moviechat: From dense token to sparse memory for long video understanding , author=. CVPR , pages=
-
[29]
TPAMI , year=
Moviechat+: Question-aware sparse memory for long video question answering , author=. TPAMI , year=
-
[30]
arXiv preprint arXiv:2409.02889 , year=
Longllava: Scaling multi-modal llms to 1000 images efficiently via a hybrid architecture , author=. arXiv preprint arXiv:2409.02889 , year=
-
[31]
ACM MM , pages =
Chu, Meng and Li, Yicong and Chua, Tat-Seng , title =. ACM MM , pages =
-
[32]
ICCV , year =
Zhang, Haoji and Wang, Yiqin and Tang, Yansong and Liu, Yong and Feng, Jiashi and Jin, Xiaojie , title =. ICCV , year =
-
[33]
ICLR , year=
World Model on Million-Length Video And Language With Blockwise RingAttention , author=. ICLR , year=
-
[34]
ICWS , pages=
Ce-collm: Efficient and adaptive large language models through cloud-edge collaboration , author=. ICWS , pages=
-
[35]
ACL , year =
Token Level Routing Inference System for Edge Devices , author =. ACL , year =
-
[36]
SpecEdge: Scalable Edge-Assisted Serving Framework for Interactive
Jinwoo Park and Seunggeun Cho and Dongsu Han , booktitle=. SpecEdge: Scalable Edge-Assisted Serving Framework for Interactive
-
[37]
IEEE Communications Magazine , volume=
Large language models empowered autonomous edge AI for connected intelligence , author=. IEEE Communications Magazine , volume=
-
[38]
EMNLP , pages=
Hybrid-RACA: hybrid retrieval-augmented composition assistance for real-time text prediction , author=. EMNLP , pages=
-
[39]
arXiv preprint arXiv:2311.14030 , year=
Privatelora for efficient privacy preserving llm , author=. arXiv preprint arXiv:2311.14030 , year=
-
[40]
IEEE Internet of Things Journal , year=
Edgeshard: Efficient llm inference via collaborative edge computing , author=. IEEE Internet of Things Journal , year=
-
[41]
arXiv preprint arXiv:2405.14636 , year=
Perllm: Personalized inference scheduling with edge-cloud collaboration for diverse llm services , author=. arXiv preprint arXiv:2405.14636 , year=
-
[42]
arXiv preprint arXiv:2512.20012 , year=
Reliable LLM-Based Edge-Cloud-Expert Cascades for Telecom Knowledge Systems , author=. arXiv preprint arXiv:2512.20012 , year=
-
[43]
Proceedings of the 25th International Workshop on Mobile Computing Systems and Applications , pages=
Creating edge ai from cloud-based llms , author=. Proceedings of the 25th International Workshop on Mobile Computing Systems and Applications , pages=
-
[44]
IEEE Transactions on Broadcasting , year=
VaVLM: Toward Efficient Edge-Cloud Video Analytics With Vision-Language Models , author=. IEEE Transactions on Broadcasting , year=
-
[45]
Journal of Industrial Information Integration , pages=
LAECIPS: Large vision model assisted adaptive edge-cloud collaboration for iot-based embodied intelligence system , author=. Journal of Industrial Information Integration , pages=
-
[46]
IEEE Network , volume=
NetGPT: An AI-native network architecture for provisioning beyond personalized generative services , author=. IEEE Network , volume=
-
[47]
MobiHoc , pages=
Local-cloud inference offloading for LLMs in multi-modal, multi-task, multi-dialogue settings , author=. MobiHoc , pages=
-
[48]
arXiv preprint arXiv:2508.12638 , year=
edgeVLM: Cloud-edge Collaborative Real-time VLM based on Context Transfer , author=. arXiv preprint arXiv:2508.12638 , year=
-
[49]
Science China Information Sciences , volume=
Adaptive joint configuration optimization for collaborative inference in edge-cloud systems , author=. Science China Information Sciences , volume=
-
[50]
TMC , year=
Large language models (LLMs) inference offloading and resource allocation in cloud-edge computing: An active inference approach , author=. TMC , year=
-
[51]
IEEE Internet of Things Journal , year=
A cloud-edge collaborative architecture for multimodal llms-based advanced driver assistance systems in iot networks , author=. IEEE Internet of Things Journal , year=
-
[52]
CVPR , pages=
Cloud-device collaborative adaptation to continual changing environments in the real-world , author=. CVPR , pages=
-
[53]
MobiCom , pages=
EdgeCloudAI: Edge-Cloud Distributed Video Analytics , author=. MobiCom , pages=
-
[54]
ICLR , year=
Sample then identify: A general framework for risk control and assessment in multimodal large language models , author=. ICLR , year=
-
[55]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[56]
arXiv preprint arXiv:2501.13106 , year=
Videollama 3: Frontier multimodal foundation models for image and video understanding , author=. arXiv preprint arXiv:2501.13106 , year=
-
[57]
ICCV , pages=
Lvbench: An extreme long video understanding benchmark , author=. ICCV , pages=
-
[58]
CVPR , pages=
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis , author=. CVPR , pages=
-
[59]
arXiv preprint arXiv:2006.03654 , year=
Deberta: Decoding-enhanced bert with disentangled attention , author=. arXiv preprint arXiv:2006.03654 , year=
Pith/arXiv arXiv 2006
-
[60]
CVPR , pages=
Ego4d: Around the world in 3,000 hours of egocentric video , author=. CVPR , pages=
-
[61]
arXiv preprint arXiv:2308.13561 , year=
Project aria: A new tool for egocentric multi-modal ai research , author=. arXiv preprint arXiv:2308.13561 , year=
-
[62]
CVPR , pages=
Where is my wallet? modeling object proposal sets for egocentric visual query localization , author=. CVPR , pages=
-
[63]
CVPR , pages=
Naq: Leveraging narrations as queries to supervise episodic memory , author=. CVPR , pages=
-
[64]
CVPR , pages=
Egolife: Towards egocentric life assistant , author=. CVPR , pages=
-
[65]
CVPR , pages=
Fine-grained spatiotemporal grounding on egocentric videos , author=. CVPR , pages=
-
[66]
CVPR , pages=
Timechat: A time-sensitive multimodal large language model for long video understanding , author=. CVPR , pages=
-
[67]
TCSVT , year=
Video understanding with large language models: A survey , author=. TCSVT , year=
-
[68]
NeurIPS , pages=
Hourvideo: 1-hour video-language understanding , author=. NeurIPS , pages=
-
[69]
NeurIPS , pages=
Egoschema: A diagnostic benchmark for very long-form video language understanding , author=. NeurIPS , pages=
-
[70]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[71]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[72]
, title =
Robinson, Arthur L. , title =. 1980 , doi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[73]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[74]
Clancey and Glenn Rennels , abstract =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
-
[75]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[76]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[77]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[78]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[79]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[80]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.