Active Inference as the Test-Time Scaling Law for Physical AI Agents
Pith reviewed 2026-06-26 08:52 UTC · model grok-4.3
The pith
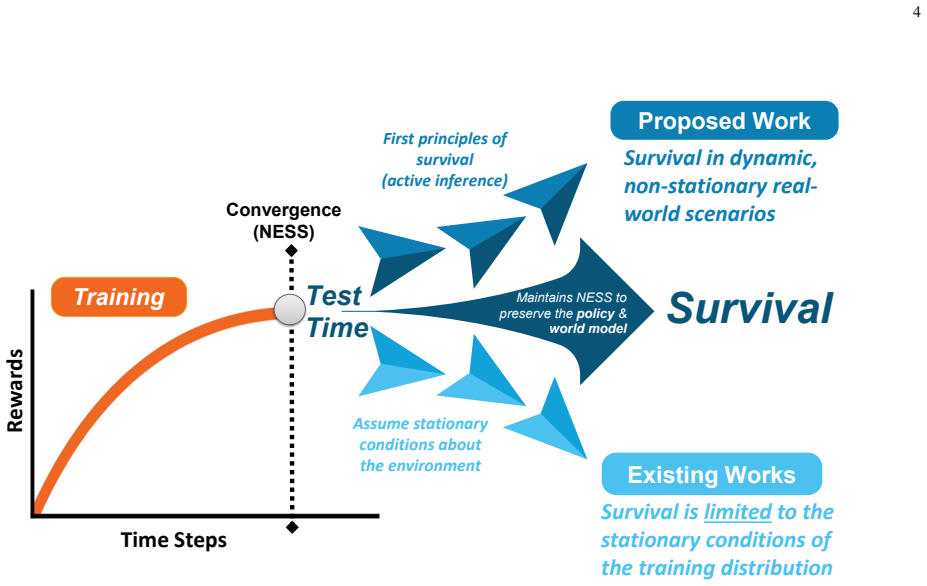
Active inference supplies a test-time scaling law for physical AI agents by updating policies through soft Bayesian inference on prediction errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
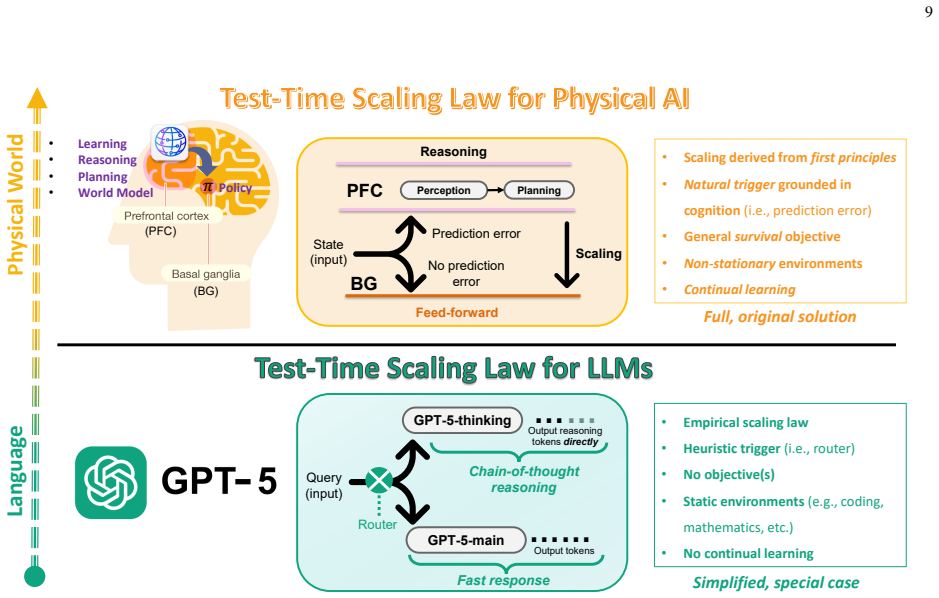
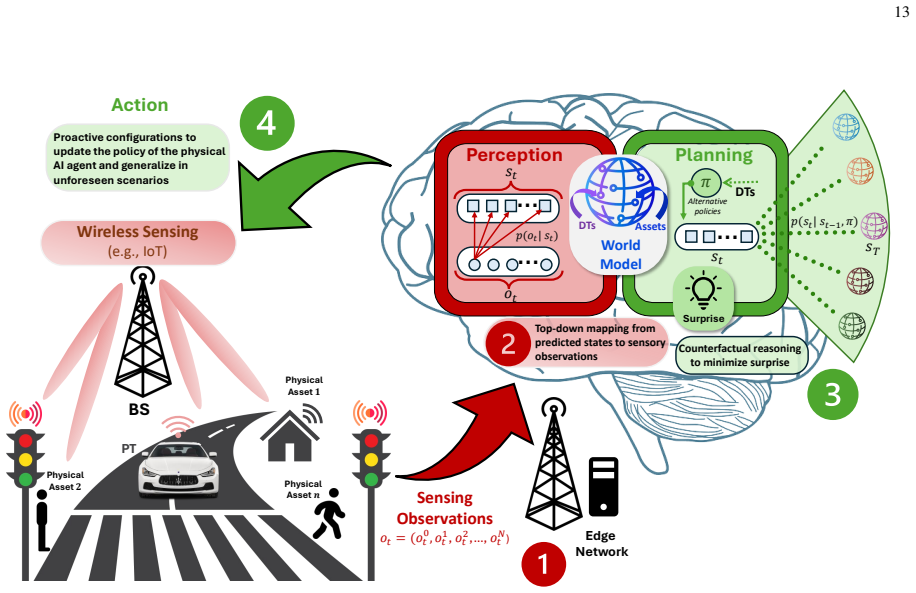
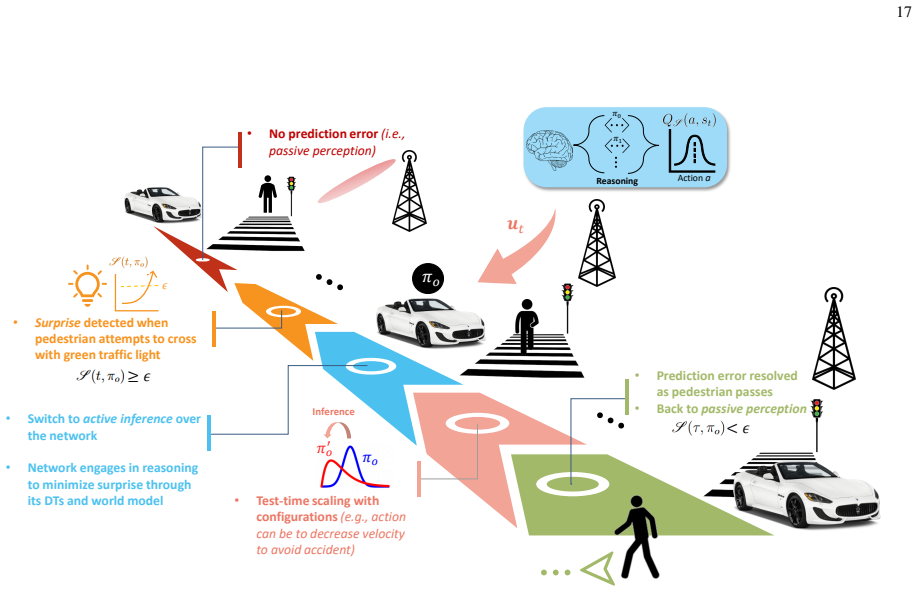
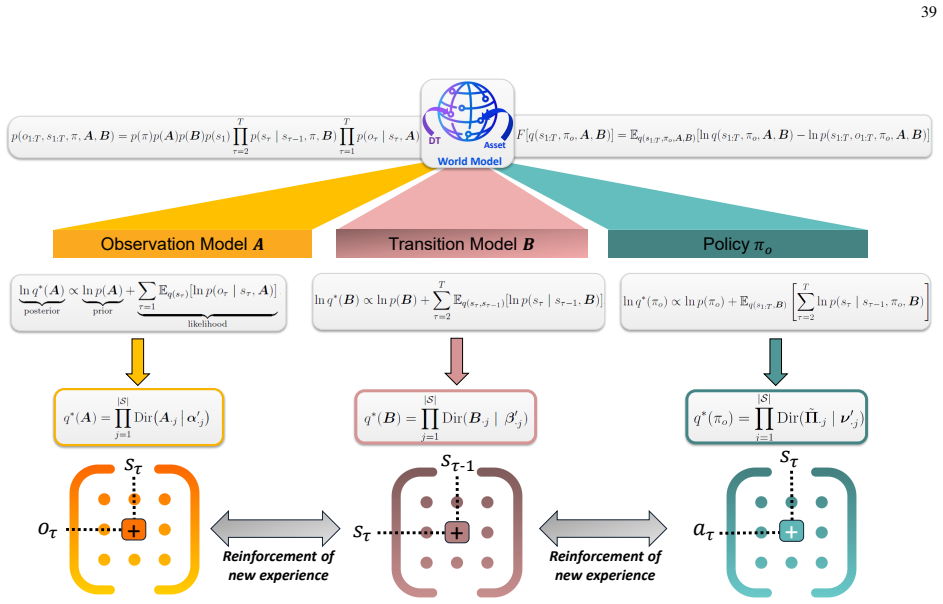
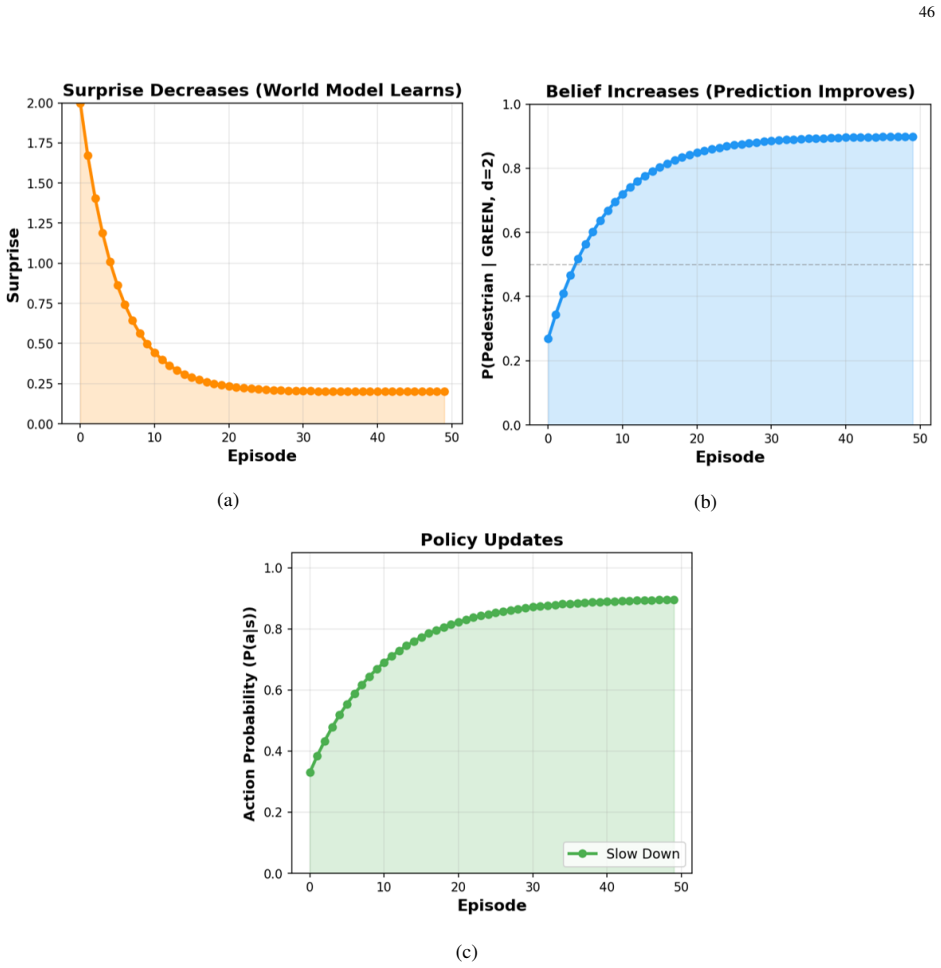
The paper states that the first principle of active inference equips physical AI agents with the general objective to survive, under which specific task objectives are subsumed, and that this principle supplies the reasoning to resolve prediction errors outside the training distribution. The scaling law captures the process by dynamically updating the agent's policy at test time through a soft Bayesian inference step whose likelihood is the reasoning that reduces expected prediction errors under allowable policies. The resulting posterior policy recovers a biological scaling mechanism that engages the basal ganglia and prefrontal cortex. An analytically tractable variational inference soluti
What carries the argument
Soft Bayesian inference process for policy update, in which beliefs about the policy are revised using reasoning that reduces expected prediction errors under allowable policies as the likelihood, solved via variational free-energy minimization.
If this is right
- Policy updates at test time enable generalization in non-stationary environments.
- The variational solution reinforces new instances in both the policy and the world model.
- The posterior policy recovers the scaling mechanism engaging the basal ganglia and prefrontal cortex.
- The method scales with continuous real-world experience rather than model size or training data.
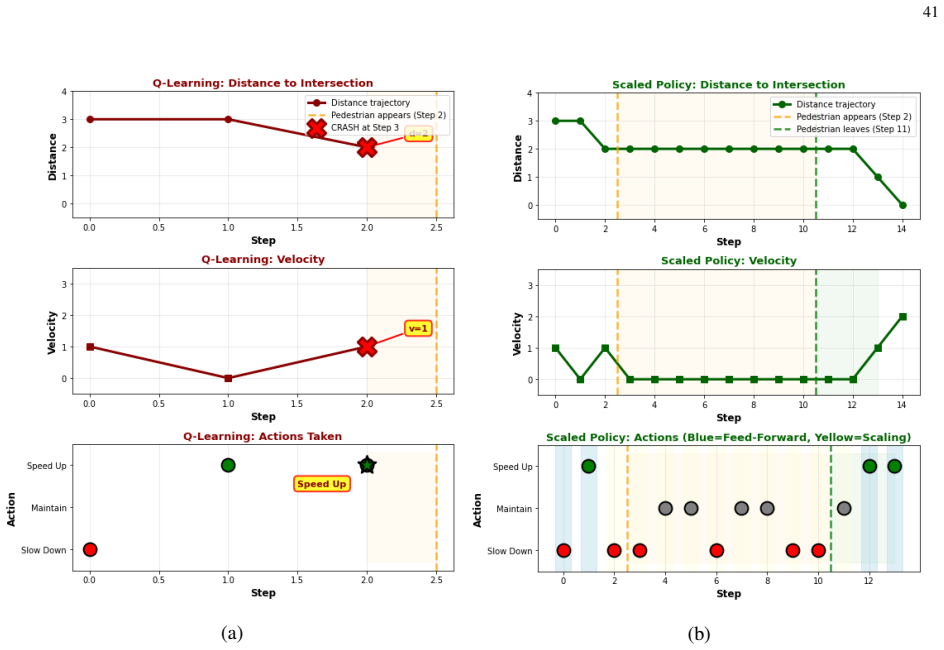
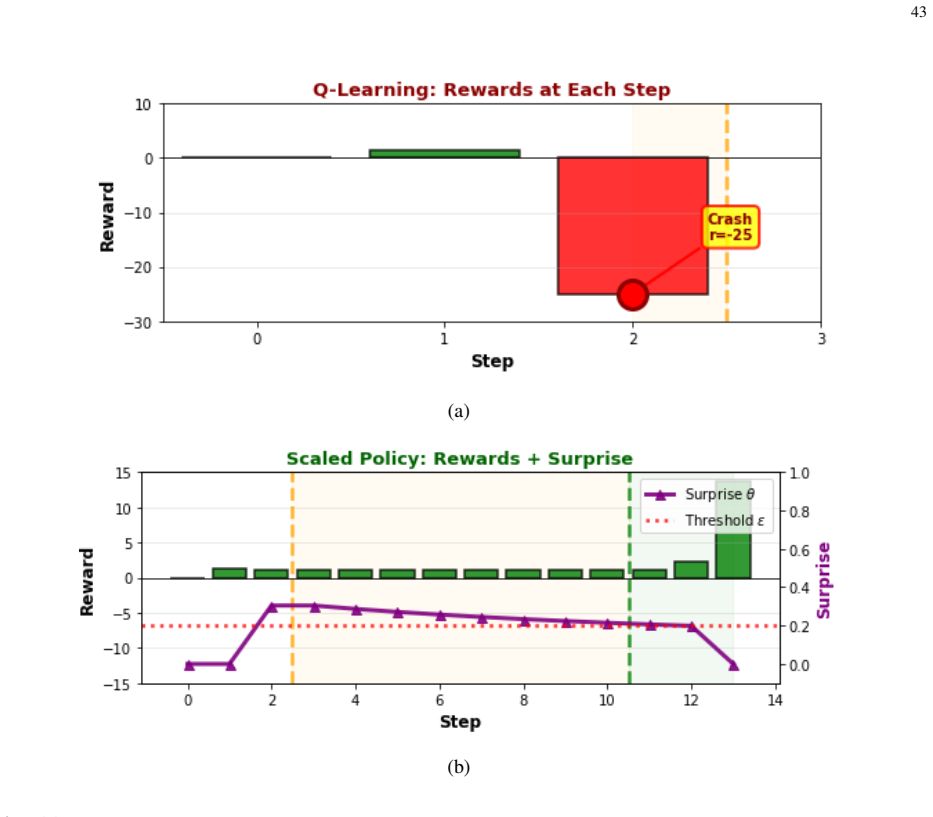
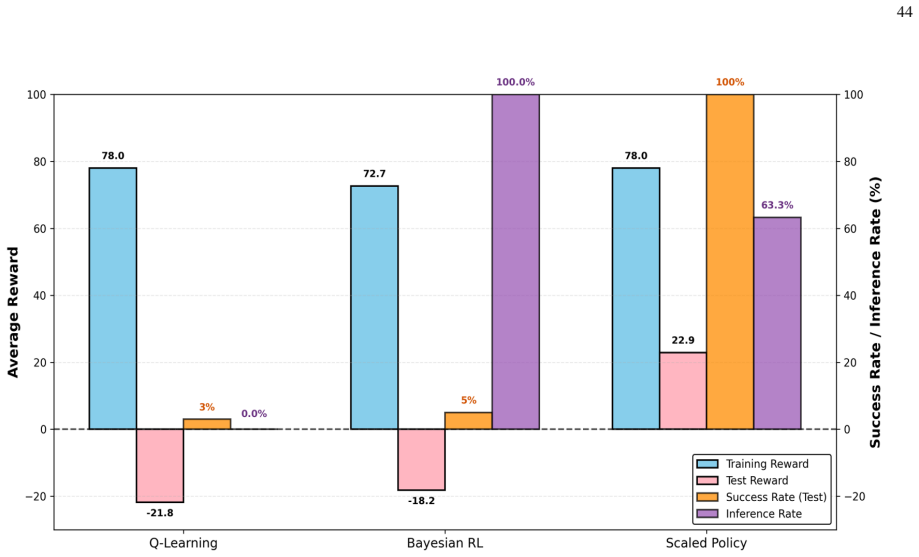
- Simulation results show robust generalization and over 36 percent improvement in inference efficiency on autonomous driving tasks.
Where Pith is reading between the lines
- The same variational update rule could be applied to other embodied tasks such as robotic manipulation without requiring task-specific retraining.
- The biological mapping suggests that hardware implementations might benefit from architectures that separate policy evaluation from world-model updating in the manner of basal ganglia and prefrontal circuits.
- Because the scaling is driven by real-time experience, the law predicts continued performance gains for agents that remain deployed for long periods rather than for agents that are periodically retrained offline.
Load-bearing premise
Active inference equips agents with the general objective to survive in the real world under which specific task objectives are subsumed, and the variational inference solution extends to enable learning beyond training by reinforcing new instances resolved at test time in both the policy and world model.
What would settle it
A controlled autonomous-driving simulation in which an agent equipped with the variational free-energy policy update shows no improvement in generalization to unforeseen scenarios or no gain in inference efficiency relative to model-free Q-learning or model-based Bayesian reinforcement learning would falsify the central claim.
Figures
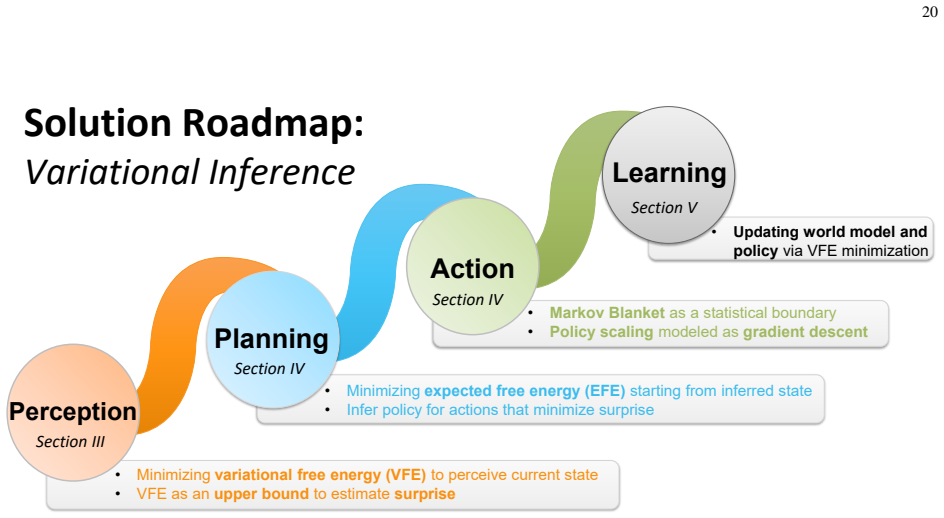
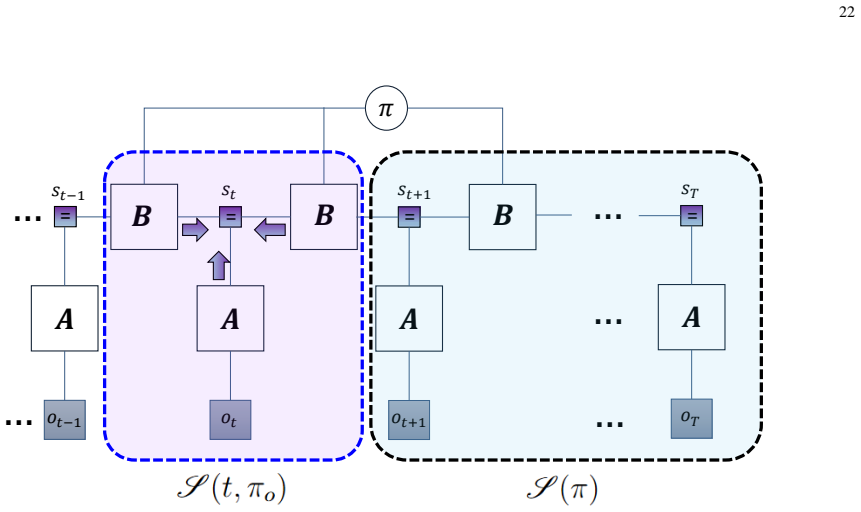
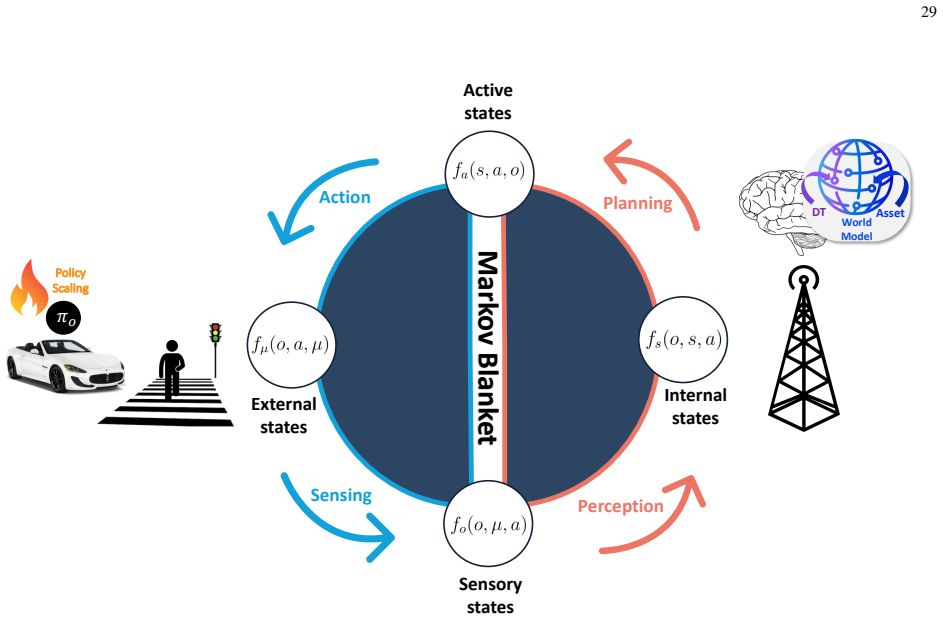
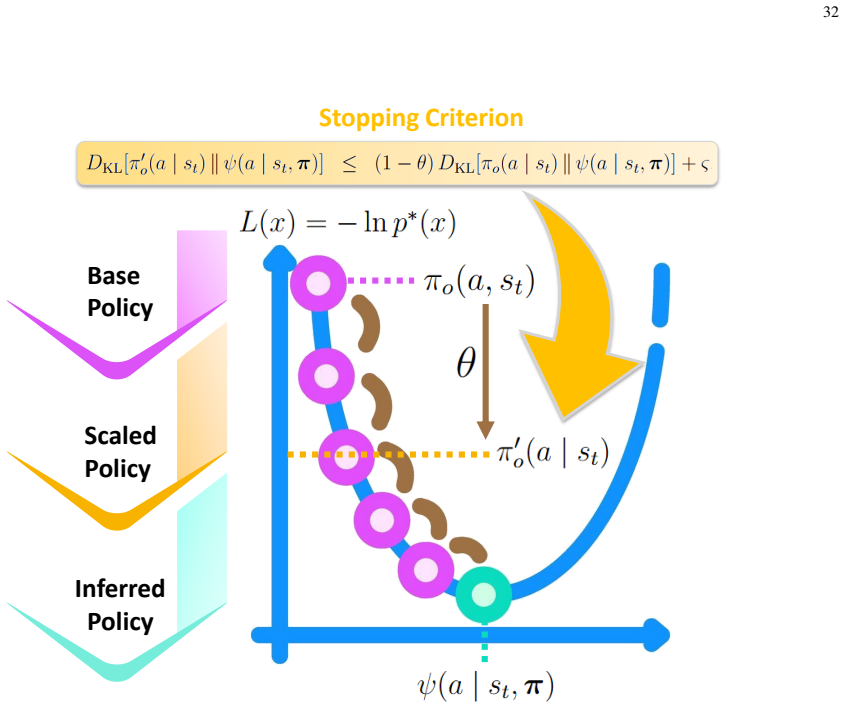
read the original abstract
In this paper, a novel test-time scaling law for physical artificial intelligence (AI) agents is introduced. This scaling law enables physical AI agents to reason with their world models to generalize in unforeseen scenarios at test time. The derived scaling law is grounded in the first principle of active inference, which equips agents with the general objective to survive in the real world, under which their specific task objectives are subsumed. Active inference achieves this by providing the reasoning to resolve prediction errors that arise when the agent encounters unforeseen situations outside its training distribution, enabling generalization in non-stationary environments. The proposed scaling law captures this by dynamically updating the agent's policy with this reasoning at test time. This policy update is modeled as a soft Bayesian inference process in which beliefs about the policy are updated using the reasoning that reduces expected prediction errors under allowable policies as a likelihood. The resulting posterior policy admits a biological interpretation, recovering the scaling mechanism that engages the brain's basal ganglia and prefrontal cortex at test time. To solve this analytically intractable problem, a variational inference solution minimizing free energy bounds is developed. This solution extends to enable learning beyond training by reinforcing new instances, resolved at test time, in both the policy and world model. Unlike existing scaling laws constrained by model size and training data, the derived solution scales with the continuous real-world experience of a physical AI agent. Simulation results on an autonomous driving task demonstrate that the proposed solution outperforms model-free Q-learning and model-based Bayesian reinforcement learning, achieving robust generalization to unforeseen scenarios while improving inference efficiency by over 36%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to derive a test-time scaling law for physical AI agents from active inference as a first principle. Agents use variational free-energy minimization to perform soft Bayesian policy updates at test time, resolving prediction errors for generalization in non-stationary settings. The solution is asserted to extend beyond inference to reinforce resolved instances in both the policy and world model, enabling scaling with continuous experience rather than training data. A biological interpretation links the posterior policy to basal ganglia and prefrontal cortex mechanisms. Simulations on an autonomous driving task report outperformance over model-free Q-learning and model-based Bayesian RL, plus >36% inference efficiency gains.
Significance. If the variational extension to test-time world-model reinforcement holds with explicit, stable mechanisms, the work would supply a principled alternative to data- or parameter-size scaling laws for embodied agents, with direct relevance to robust physical AI in open environments. The grounding in active inference supplies a unified objective (survival under prediction-error minimization) that subsumes task-specific goals, and the simulation comparison provides an initial empirical anchor.
major comments (2)
- [Abstract] Abstract: The central claim that 'this solution extends to enable learning beyond training by reinforcing new instances, resolved at test time, in both the policy and world model' is load-bearing for the distinction from training-constrained scaling laws, yet no explicit update rule, gradient, or outer optimization loop for world-model parameters is supplied. Variational free-energy minimization is conventionally an inference procedure over latents or policies; parameter learning requires additional structure (e.g., EM-style alternation or online gradients on the bound) whose stability under non-stationary test-time data is not addressed.
- [Abstract] Abstract (simulation paragraph): The reported outperformance and 'improving inference efficiency by over 36%' are presented without error bars, number of independent runs, statistical tests, or precise definition of the efficiency metric. Because the scaling-law claim rests on these results demonstrating generalization beyond training, the absence of these details prevents assessment of whether gains arise from the proposed mechanism or from other implementation choices.
minor comments (2)
- [Abstract] The abstract states that an 'analytically intractable problem' is solved variationally but supplies neither the intractable objective nor the free-energy bound that is minimized, making it impossible for readers to verify the derivation steps.
- [Abstract] Notation for the soft Bayesian policy update (beliefs over policies updated by 'reasoning that reduces expected prediction errors under allowable policies as a likelihood') is introduced without an equation; a compact mathematical statement would clarify the mapping from active-inference quantities to the claimed posterior.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract claims and empirical reporting. We address each major comment below and will incorporate clarifications and additions in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'this solution extends to enable learning beyond training by reinforcing new instances, resolved at test time, in both the policy and world model' is load-bearing for the distinction from training-constrained scaling laws, yet no explicit update rule, gradient, or outer optimization loop for world-model parameters is supplied. Variational free-energy minimization is conventionally an inference procedure over latents or policies; parameter learning requires additional structure (e.g., EM-style alternation or online gradients on the bound) whose stability under non-stationary test-time data is not addressed.
Authors: We agree that the extension to world-model reinforcement requires explicit formalization to support the test-time scaling claim. The manuscript centers on variational free-energy minimization for policy inference, with the world-model extension stated at a high level in the abstract. In revision we will add a new subsection deriving the online gradient update on the variational bound for world-model parameters (following an EM-style alternation between policy and model optimization) and include a brief analysis of stability under non-stationary test-time data streams. This will make the mechanism concrete without altering the core active-inference derivation. revision: yes
-
Referee: [Abstract] Abstract (simulation paragraph): The reported outperformance and 'improving inference efficiency by over 36%' are presented without error bars, number of independent runs, statistical tests, or precise definition of the efficiency metric. Because the scaling-law claim rests on these results demonstrating generalization beyond training, the absence of these details prevents assessment of whether gains arise from the proposed mechanism or from other implementation choices.
Authors: We concur that the simulation results must be reported with full statistical detail to substantiate the generalization claims. The current version reports aggregate metrics only. In the revision we will (i) specify the inference-efficiency metric as average wall-clock time per policy update, (ii) report means and standard errors over 10 independent random seeds, and (iii) include paired t-tests against the Q-learning and Bayesian-RL baselines. These additions will be placed in both the abstract and the results section. revision: yes
Circularity Check
Active inference scaling law reduces to authors' own free-energy framework by construction via self-citation and asserted extension
specific steps
-
self citation load bearing
[Abstract]
"The derived scaling law is grounded in the first principle of active inference, which equips agents with the general objective to survive in the real world, under which their specific task objectives are subsumed. ... The resulting posterior policy admits a biological interpretation, recovering the scaling mechanism that engages the brain's basal ganglia and prefrontal cortex at test time."
Active inference and its free-energy principle originate in prior work by co-author Karl Friston; the paper invokes this as external first principle and recovers the biological mechanism from the same literature, so the scaling law's grounding reduces to the authors' own framework rather than independent justification.
-
self definitional
[Abstract]
"To solve this analytically intractable problem, a variational inference solution minimizing free energy bounds is developed. This solution extends to enable learning beyond training by reinforcing new instances, resolved at test time, in both the policy and world model. Unlike existing scaling laws constrained by model size and training data, the derived solution scales with the continuous real-world experience of a physical AI agent."
The scaling law is defined as the dynamic policy update via free-energy minimization; the asserted extension to test-time world-model reinforcement is presented as following from the same variational solution, rendering the 'new' scaling behavior equivalent to the input active-inference objective by construction.
full rationale
The paper's central derivation grounds the test-time scaling law directly in active inference as a 'first principle' (with co-author Friston as originator), models policy update as soft Bayesian inference under free-energy minimization, and asserts without separate mechanism that the variational solution 'extends to enable learning beyond training by reinforcing new instances... in both the policy and world model.' This makes the claimed departure from training-data scaling laws equivalent to re-applying the input framework at test time rather than deriving an independent result. One load-bearing self-citation chain and self-definitional extension are present; the simulation outperformance does not rescue the logical reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Active inference provides the general objective to survive in the real world under which specific task objectives are subsumed.
- domain assumption The variational inference solution minimizing free energy bounds solves the analytically intractable soft Bayesian policy update.
Reference graph
Works this paper leans on
-
[1]
Artificial general intelligence (AGI)-native wireless systems: A journey beyond 6G,
W. Saad, O. Hashash, C. K. Thomas, C. Chaccour, M. Debbah, N. Mandayam, and Z. Han, “Artificial general intelligence (AGI)-native wireless systems: A journey beyond 6G,”Proceedings of the IEEE, vol. 113, no. 9, pp. 849–887, 2025
2025
-
[2]
Waymos blocked roads and caused chaos during San Francisco power outage,
J. Ding and M. Liedtke, “Waymos blocked roads and caused chaos during San Francisco power outage,” https://fortune.com/ 2025/12/22/waymo-ai-san-francisco-power-outage-operational-management-failure-software/, December 2025, associated Press, December 22, 2025
2025
-
[3]
D. Ha and J. Schmidhuber, “World models,”arXiv preprint arXiv:1803.10122, vol. 2, no. 3, p. 440, 2018
Pith/arXiv arXiv 2018
-
[4]
Kahneman,Thinking, fast and slow
D. Kahneman,Thinking, fast and slow. macmillan, 2011
2011
-
[5]
A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27,
Y . LeCun, “A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27,”Open Review, vol. 62, 2022
2022
-
[6]
Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects,
R. P. Rao and D. H. Ballard, “Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects,”Nature neuroscience, vol. 2, no. 1, pp. 79–87, 1999
1999
-
[7]
Active inference: a process theory,
K. Friston, T. FitzGerald, F. Rigoli, P. Schwartenbeck, and G. Pezzulo, “Active inference: a process theory,”Neural computation, vol. 29, no. 1, pp. 1–49, 2017
2017
-
[8]
Dissipative structures in biological systems: bistability, oscillations, spatial patterns and waves,
A. Goldbeter, “Dissipative structures in biological systems: bistability, oscillations, spatial patterns and waves,”Philosoph- ical transactions. Series A, Mathematical, physical, and engineering sciences, vol. 376, no. 2124, p. 20170376, 2018
2018
-
[9]
Active inference for physical AI agents–an engineering perspective,
B. de Vries, “Active inference for physical AI agents–an engineering perspective,”arXiv preprint arXiv:2603.20927, 2026
arXiv 2026
-
[10]
Life as we know it,
K. Friston, “Life as we know it,”Journal of the royal society interface, vol. 10, no. 86, p. 20130475, 2013. 52
2013
-
[11]
Challenges of real-world reinforcement learning: definitions, benchmarks and analysis,
G. Dulac-Arnold, N. Levine, D. J. Mankowitz, J. Li, C. Paduraru, S. Gowal, and T. Hester, “Challenges of real-world reinforcement learning: definitions, benchmarks and analysis,”Machine Learning, vol. 110, no. 9, pp. 2419–2468, 2021
2021
-
[12]
OpenAI, “GPT-5,” https://openai.com/, 2025
2025
-
[13]
V- JEPA 2: Self-supervised video models enable understanding, prediction and planning,
M. Assran, A. Bardes, D. Fan, Q. Garrido, R. Howes, M. Muckley, A. Rizvi, C. Roberts, K. Sinha, A. Zholuset al., “V- JEPA 2: Self-supervised video models enable understanding, prediction and planning,”arXiv preprint arXiv:2506.09985, 2025
Pith/arXiv arXiv 2025
-
[14]
Mindjourney: Test-time scaling with world models for spatial reasoning,
Y . Yang, J. Liu, Z. Zhang, S. Zhou, R. Tan, J. Yang, Y . Du, and C. Gan, “Mindjourney: Test-time scaling with world models for spatial reasoning,”Advances in Neural Information Processing Systems, vol. 38, pp. 109 855–109 885, 2026
2026
-
[15]
π 0.7: a steerable generalist robotic foundation model with emergent capabilities,
Physical Intelligence, “π 0.7: a steerable generalist robotic foundation model with emergent capabilities,” Physical Intelligence, Tech. Rep., 2026. [Online]. Available: https://pi.website/pi07
2026
-
[16]
V-JEPA 2.1: Unlocking dense features in video self-supervised learning,
L. Mur-Labadia, M. Muckley, A. Bar, M. Assran, K. Sinha, M. Rabbat, Y . LeCun, N. Ballas, and A. Bardes, “V-JEPA 2.1: Unlocking dense features in video self-supervised learning,”arXiv preprint arXiv:2603.14482, 2026
Pith/arXiv arXiv 2026
-
[17]
The markov blankets of life: autonomy, active inference and the free energy principle,
M. Kirchhoff, T. Parr, E. Palacios, K. Friston, and J. Kiverstein, “The markov blankets of life: autonomy, active inference and the free energy principle,”Journal of The royal society interface, vol. 15, no. 138, p. 20170792, 2018
2018
-
[18]
A neural substrate of prediction and reward,
W. Schultz, P. Dayan, and P. R. Montague, “A neural substrate of prediction and reward,”Science, vol. 275, no. 5306, pp. 1593–1599, 1997
1997
-
[19]
Training compute-optimal large language models,
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. Casas, L. A. Hendricks, J. Welbl, A. Clark et al., “Training compute-optimal large language models,”arXiv preprint arXiv:2203.15556, vol. 10, 2022
Pith/arXiv arXiv 2022
-
[20]
Scaling laws for neural language models,
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,”arXiv preprint arXiv:2001.08361, 2020
Pith/arXiv arXiv 2001
-
[21]
Scaling LLM test-time compute optimally can be more effective than scaling model parameters,
C. Snell, J. Lee, K. Xu, and A. Kumar, “Scaling LLM test-time compute optimally can be more effective than scaling model parameters,”arXiv preprint arXiv:2408.03314, 2024
Pith/arXiv arXiv 2024
-
[22]
Toward causal representation learning,
B. Sch ¨olkopf, F. Locatello, S. Bauer, N. R. Ke, N. Kalchbrenner, A. Goyal, and Y . Bengio, “Toward causal representation learning,”Proceedings of the IEEE, vol. 109, no. 5, pp. 612–634, 2021
2021
-
[23]
From passive mirrors to active agents: Holonic digital twins for physical artificial intelligence over networks,
C. K. Thomas, O. Hashash, and W. Saad, “From passive mirrors to active agents: Holonic digital twins for physical artificial intelligence over networks,”IEEE Vehicular Technology Magazine, 2026
2026
-
[24]
Robust agents learn causal world models,
J. Richens and T. Everitt, “Robust agents learn causal world models,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[25]
Bayesian surprise attracts human attention,
L. Itti and P. Baldi, “Bayesian surprise attracts human attention,”Vision research, vol. 49, no. 10, pp. 1295–1306, 2009
2009
-
[26]
The free-energy principle: a unified brain theory?
K. Friston, “The free-energy principle: a unified brain theory?”Nature reviews neuroscience, vol. 11, no. 2, pp. 127–138, 2010
2010
-
[27]
T. Parr, G. Pezzulo, and K. J. Friston,Active inference: the free energy principle in mind, brain, and behavior. MIT Press, 2022
2022
-
[28]
Path integrals, particular kinds, and strange things,
K. Friston, L. Da Costa, D. A. Sakthivadivel, C. Heins, G. A. Pavliotis, M. Ramstead, and T. Parr, “Path integrals, particular kinds, and strange things,”Physics of Life Reviews, vol. 47, pp. 35–62, 2023
2023
-
[29]
Evidence for surprise minimization over value maximization in choice behavior,
P. Schwartenbeck, T. H. FitzGerald, C. Mathys, R. Dolan, M. Kronbichler, and K. Friston, “Evidence for surprise minimization over value maximization in choice behavior,”Scientific reports, vol. 5, no. 1, p. 16575, 2015
2015
-
[30]
Pearl,Probabilistic reasoning in intelligent systems: networks of plausible inference
J. Pearl,Probabilistic reasoning in intelligent systems: networks of plausible inference. Elsevier, 2014
2014
-
[31]
The mathematics of changing one’s mind, via jeffrey’s or via pearl’s update rule,
B. Jacobs, “The mathematics of changing one’s mind, via jeffrey’s or via pearl’s update rule,”Journal of Artificial Intelligence Research, vol. 65, pp. 783–806, 2019
2019
-
[32]
R. S. Sutton and A. G. Barto,Reinforcement Learning: An Introduction. Cambridge, MA: MIT Press, 2018. 53
2018
-
[33]
Human-level control through deep reinforcement learning,
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovskiet al., “Human-level control through deep reinforcement learning,”nature, vol. 518, no. 7540, pp. 529–533, 2015
2015
-
[34]
Optimizing for the future in non- stationary mdps,
Y . Chandak, G. Theocharous, S. Shankar, M. White, S. Mahadevan, and P. Thomas, “Optimizing for the future in non- stationary mdps,” inInternational Conference on Machine Learning. PMLR, 2020, pp. 1414–1425
2020
-
[35]
A tutorial on energy-based learning,
Y . LeCun, S. Chopra, R. Hadsell, M. Ranzato, F. Huanget al., “A tutorial on energy-based learning,”Predicting structured data, vol. 1, no. 0, 2006
2006
-
[36]
An introduction to variational methods for graphical models,
M. I. Jordan, Z. Ghahramani, T. S. Jaakkola, and L. K. Saul, “An introduction to variational methods for graphical models,” Machine learning, vol. 37, no. 2, pp. 183–233, 1999
1999
-
[37]
Graphical models, exponential families, and variational inference,
M. J. Wainwright and M. I. Jordan, “Graphical models, exponential families, and variational inference,”Foundations and Trends® in Machine Learning, vol. 1, no. 1-2, pp. 1–305, 2008
2008
-
[38]
Variational message passing
J. Winn, C. M. Bishop, and T. Jaakkola, “Variational message passing.”Journal of Machine Learning Research, vol. 6, no. 4, 2005
2005
-
[39]
Auto-encoding variational bayes,
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,”arXiv preprint arXiv:1312.6114, 2013
Pith/arXiv arXiv 2013
-
[40]
A step-by-step tutorial on active inference and its application to empirical data,
R. Smith, K. J. Friston, and C. J. Whyte, “A step-by-step tutorial on active inference and its application to empirical data,” Journal of mathematical psychology, vol. 107, p. 102632, 2022
2022
-
[41]
Codes on graphs: Normal realizations,
G. D. Forney, “Codes on graphs: Normal realizations,”IEEE Transactions on Information Theory, vol. 47, no. 2, pp. 520–548, 2001
2001
-
[42]
C. M. Bishop and N. M. Nasrabadi,Pattern recognition and machine learning. Springer, 2006, vol. 4, no. 4
2006
-
[43]
Whence the expected free energy?
B. Millidge, A. Tschantz, and C. L. Buckley, “Whence the expected free energy?”Neural Computation, vol. 33, no. 2, pp. 447–482, 2021
2021
-
[44]
Koller and N
D. Koller and N. Friedman,Probabilistic graphical models: principles and techniques. MIT press, 2009
2009
-
[45]
Bayesian mechanics for stationary processes,
L. Da Costa, K. Friston, C. Heins, and G. A. Pavliotis, “Bayesian mechanics for stationary processes,”Proceedings. Mathematical, Physical, and Engineering Sciences, vol. 477, no. 2256, p. 20210518, 2021
2021
-
[46]
On markov blankets and hierarchical self-organisation,
E. R. Palacios, A. Razi, T. Parr, M. Kirchhoff, and K. Friston, “On markov blankets and hierarchical self-organisation,” Journal of theoretical biology, vol. 486, p. 110089, 2020
2020
-
[47]
Nonlinear kinetics on lattices based on the kinetic interaction principle,
G. Kaniadakis and D. T. Hristopulos, “Nonlinear kinetics on lattices based on the kinetic interaction principle,”Entropy, vol. 20, no. 6, p. 426, 2018
2018
-
[48]
Cognitive dynamics: From attractors to active inference,
K. Friston, B. Sengupta, and G. Auletta, “Cognitive dynamics: From attractors to active inference,”Proceedings of the IEEE, vol. 102, no. 4, pp. 427–445, 2014
2014
-
[49]
Welcome to the era of experience,
D. Silver and R. S. Sutton, “Welcome to the era of experience,”Google AI, vol. 1, p. 11, 2025
2025
-
[50]
Active inference on discrete state-spaces: A synthesis,
L. Da Costa, T. Parr, N. Sajid, S. Veselic, V . Neacsu, and K. Friston, “Active inference on discrete state-spaces: A synthesis,” Journal of Mathematical Psychology, vol. 99, p. 102447, 2020
2020
-
[51]
E. Dupoux, Y . LeCun, and J. Malik, “Why AI systems don’t learn and what to do about it: Lessons on autonomous learning from cognitive science,”arXiv preprint arXiv:2603.15381, 2026
arXiv 2026
-
[52]
Edge continual learning for dynamic digital twins over wireless networks,
O. Hashash, C. Chaccour, and W. Saad, “Edge continual learning for dynamic digital twins over wireless networks,” in Proc. of the IEEE 23rd International Workshop on Signal Processing Advances in Wireless Communication (SPAWC), Oulu, Finland, Jul. 2022, pp. 1–5
2022
-
[53]
The neural basis of the speed–accuracy tradeoff,
R. Bogacz, E.-J. Wagenmakers, B. U. Forstmann, and S. Nieuwenhuis, “The neural basis of the speed–accuracy tradeoff,” Trends in neurosciences, vol. 33, no. 1, pp. 10–16, 2010
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.