LiveServe: Interaction-Aware Serving for Real-Time Omni-Modal LLMs
Pith reviewed 2026-06-26 07:24 UTC · model grok-4.3
The pith
LiveServe improves realtime omni-modal LLM serving by exposing playback progress, speech activity, and barge-in events to the scheduler and KV manager.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
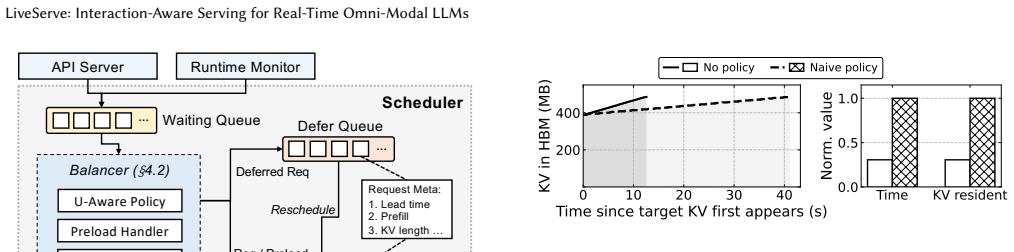
LiveServe is an interaction-aware serving system that exposes playback progress, speech activity, and barge-in events to the serving pipeline; the scheduler then prioritizes first-audio and near-underrun sessions while limiting generation beyond the playback frontier, and the KV manager applies next-use-aware eviction plus preloading of likely-needed state during user speech.
What carries the argument
Interaction-aware scheduler and next-use-aware KV manager that together use playback progress, speech activity, and barge-in events to guide prioritization and cache decisions.
If this is right
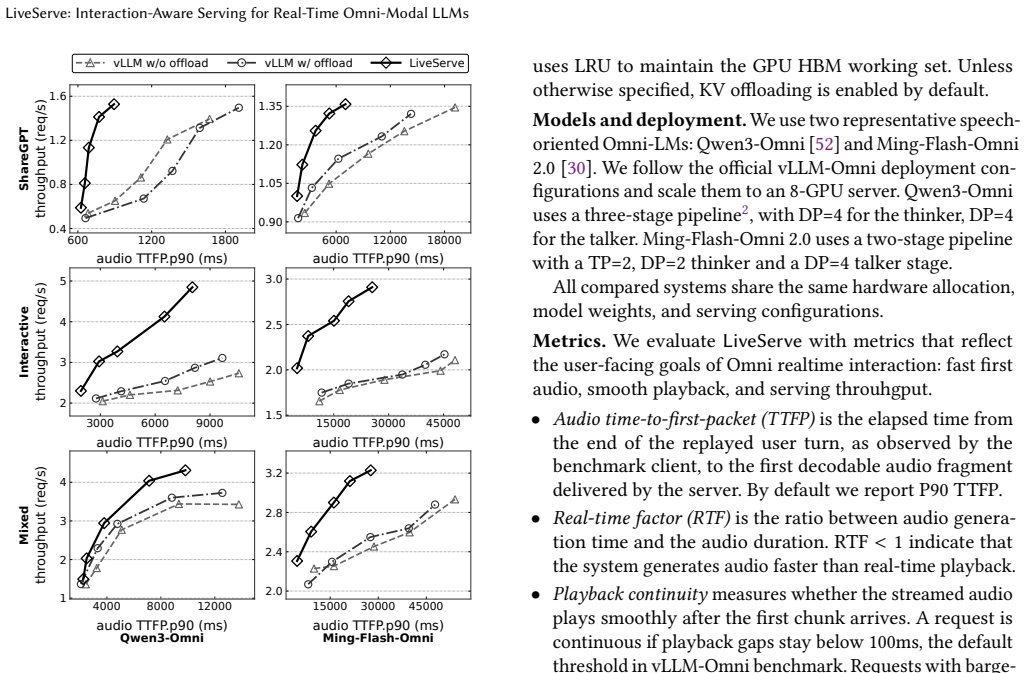
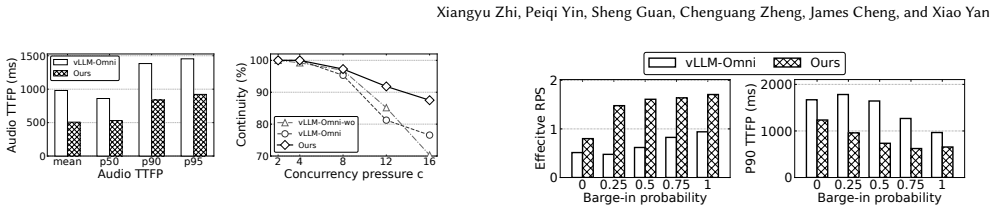
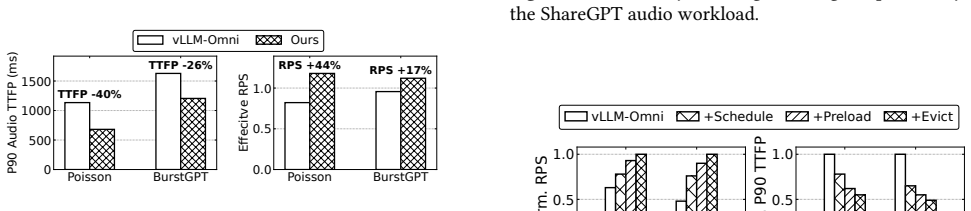
- P90 audio TTFP falls 1.55× on average and up to 2.21× across two omni-LMs and mixed workloads.
- Completed-request throughput rises 1.15× on average and up to 1.56×.
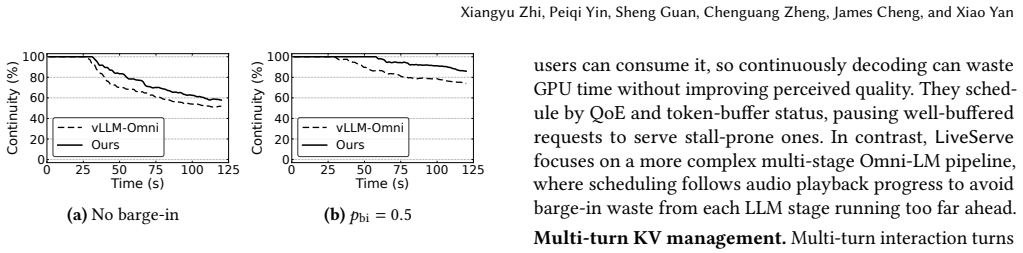
- Most KV reload work is moved off the next-turn critical path.
- Generation is limited to what users actually hear, reducing wasted tokens after barge-in.
Where Pith is reading between the lines
- The same signals could be used to decide when to stop speculative decoding or speculative audio generation.
- Energy use may drop because unnecessary tokens beyond the playback frontier are never produced.
- Design of future multimodal serving stacks could treat interaction events as first-class inputs rather than afterthoughts.
- The approach is testable on other frameworks by instrumenting the same three event sources and repeating the TTFP and throughput measurements.
Load-bearing premise
Playback progress, speech activity, and barge-in events can be exposed to the serving pipeline in a timely and low-overhead manner without changing the underlying model execution semantics.
What would settle it
Measure whether the added latency or overhead from exposing playback, speech, and barge-in signals equals or exceeds the reported 1.55× TTFP reduction; if it does, the net benefit disappears.
Figures





read the original abstract
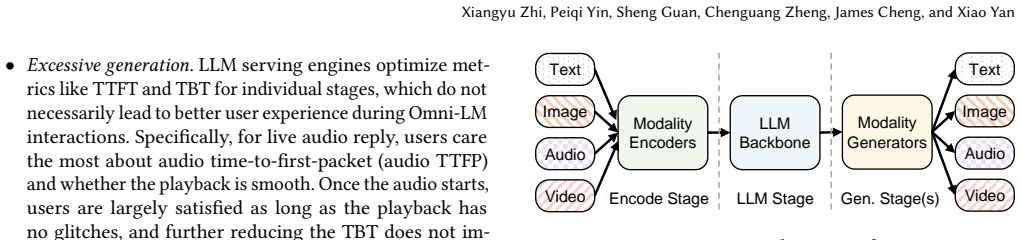
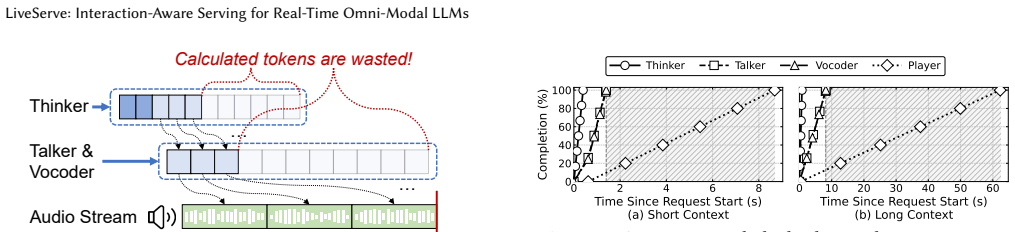
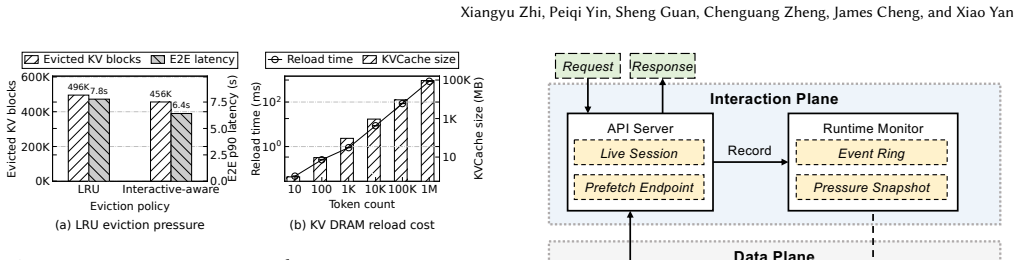
Realtime omni-modal LMs support speech-centric conversations where users stream inputs, hear generated audio, and interrupt freely. Existing Omni-LM serving systems still rely on throughput-oriented LLM scheduling and LRU KV offloading. These policies ignore audio playback and multi-turn reuse: they may generate tokens far beyond what users hear, wasting work after barge-in, and evict KV state needed in the next turn. LiveServe is an interaction-aware serving system for realtime Omni-LM interaction. It exposes playback progress, speech activity, and barge-in events to the serving pipeline. The scheduler prioritizes first-audio and near-underrun sessions while limiting generation beyond the playback frontier. The KV manager uses next-use-aware eviction and preloads likely-needed KV during user speech to hide reload latency. On vLLM-Omni, LiveServe improves realtime serving across two Omni-LMs and mixed workloads. It lowers P90 audio TTFP by $1.55\times$ on average and up to $2.21\times$, while improving completed-request throughput by $1.15\times$ on average and up to $1.56\times$, and moves most KV reload work off the next-turn critical path.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LiveServe, an interaction-aware serving system for real-time omni-modal LLMs. It exposes playback progress, speech activity, and barge-in events to the scheduler and KV manager. The scheduler prioritizes first-audio and near-underrun sessions while limiting generation beyond the playback frontier; the KV manager uses next-use-aware eviction and preloads KV during user speech. On vLLM-Omni with two Omni-LMs and mixed workloads, it reports 1.55× average (up to 2.21×) reduction in P90 audio TTFP, 1.15× average (up to 1.56×) improvement in completed-request throughput, and moving most KV reload work off the next-turn critical path.
Significance. If the empirical results hold after verification of integration costs, LiveServe would demonstrate a practical way to reduce wasted generation and hide reload latency in realtime omni-modal serving, which is relevant for interactive speech-centric applications.
major comments (1)
- [Abstract] The central performance claims (1.55× P90 TTFP and 1.15× throughput) rest on the assumption that playback progress, speech activity, and barge-in events can be exposed to the serving pipeline in a timely, low-overhead manner without altering model execution semantics or adding latency to the critical path. The provided text states that the events are exposed but supplies no isolated measurement or ablation of the client-server integration cost, polling overhead, or semantic equivalence of aborts, which is load-bearing for whether the reported gains would materialize.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the constructive major comment. We agree that the integration overhead of exposing playback, speech activity, and barge-in events must be quantified to support the reported gains. We address this below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] The central performance claims (1.55× P90 TTFP and 1.15× throughput) rest on the assumption that playback progress, speech activity, and barge-in events can be exposed to the serving pipeline in a timely, low-overhead manner without altering model execution semantics or adding latency to the critical path. The provided text states that the events are exposed but supplies no isolated measurement or ablation of the client-server integration cost, polling overhead, or semantic equivalence of aborts, which is load-bearing for whether the reported gains would materialize.
Authors: We acknowledge that the manuscript does not provide isolated microbenchmarks or ablations for the client-server integration cost, polling overhead, or the semantic equivalence of barge-in aborts. The current evaluation reports only end-to-end results. In the revised manuscript we will add a new subsection (and corresponding appendix) containing: (1) microbenchmarks isolating the latency and CPU overhead of event exposure and polling under varying load; (2) confirmation that abort semantics preserve model execution correctness with no additional critical-path latency; and (3) an ablation showing the contribution of these mechanisms to the reported TTFP and throughput improvements. These additions will directly address the load-bearing assumption. revision: yes
Circularity Check
No circularity; empirical systems claims with no derivations or fitted predictions
full rationale
The paper describes an interaction-aware scheduler and KV manager that use exposed playback, speech, and barge-in signals to prioritize sessions and preload state. All load-bearing claims are measured speedups (1.55× P90 TTFP, 1.15× throughput) obtained by running the implemented system on vLLM-Omni under mixed workloads. No equations, parameter fits, uniqueness theorems, or self-citations appear as the basis for any result; the contribution is a concrete engineering artifact whose correctness is established by external benchmarking rather than by construction from its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al . 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774(2023)
Pith/arXiv arXiv 2023
-
[2]
Amey Agrawal, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhar- gav S Gulavani, and Ramachandran Ramjee. 2023. Sarathi: Efficient llm inference by piggybacking decodes with chunked prefills.arXiv preprint arXiv:2308.16369(2023)
Pith/arXiv arXiv 2023
-
[3]
Aleksandr Algazinov, Matt Laing, and Paul Laban. 2025. MATE: LLM- Powered Multi-Agent Translation Environment for Accessibility Ap- plications.arXiv preprint arXiv:2506.19502(2025)
arXiv 2025
-
[4]
Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. 2023. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805(2023)
Pith/arXiv arXiv 2023
-
[5]
Fan Bai, Pai Peng, Zhengzhi Tang, Zhe Wang, Gong Chen, Xiang Lu, Yinuo Li, Huan Lin, Weizhe Lin, Yaoyuan Wang, et al. 2026. EPD-Serve: A Flexible Multimodal EPD Disaggregation Inference Serving System On Ascend.arXiv preprint arXiv:2601.11590(2026)
arXiv 2026
-
[6]
Siyu Cao, Hangting Chen, Peng Chen, Yiji Cheng, Yutao Cui, Xinchi Deng, Ying Dong, Kipper Gong, Tianpeng Gu, Xiusen Gu, et al. 2025. HunyuanImage 3.0 Technical Report.arXiv preprint arXiv:2509.23951 (2025)
Pith/arXiv arXiv 2025
-
[7]
Junyi Chen, Chuheng Du, Renyuan Liu, Shuochao Yao, Dingtian Yan, Jiang Liao, Shengzhong Liu, Fan Wu, and Guihai Chen. 2026. Token- Flow: Responsive LLM Text Streaming Serving under Request Burst via Preemptive Scheduling. InProceedings of the 21st European Conference on Computer Systems. 497–513
2026
-
[8]
Jae-Won Chung, Jeff J Ma, Jisang Ahn, Yizhuo Liang, Akshay Jajoo, Myungjin Lee, and Mosharaf Chowdhury. 2026. Cornserve: A dis- tributed serving system for any-to-any multimodal models.arXiv preprint arXiv:2603.12118(2026)
Pith/arXiv arXiv 2026
-
[9]
Google Deepmind. 2026. Gemini Omni: Speak it. See it. Share it. https://gemini.google/overview/video-generation/
2026
-
[10]
Matendo Didas. 2026. A multi-agent artificial intelligence-powered ar- chitecture for customer experience management.International Journal of Advanced Computer Research16 (2026), 76
2026
-
[11]
Xianzhe Dong, Tongxuan Liu, Yuting Zeng, Liangyu Liu, Yang Liu, Siyu Wu, Yu Wu, Hailong Yang, Ke Zhang, and Jing Li. 2025. Hydrainfer: Hybrid disaggregated scheduling for multimodal large language model serving.arXiv preprint arXiv:2505.12658(2025)
arXiv 2025
-
[12]
Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, and Pengfei Zuo. 2024. {Cost- Efficient} large language model serving for multi-turn conversations with {CachedAttention}. In2024 USENIX annual technical conference (USENIX ATC 24). 111–126
2024
-
[13]
Shiwei Gao, Youmin Chen, and Jiwu Shu. 2025. Fast state restoration in llm serving with hcache. InProceedings of the Twentieth European Conference on Computer Systems. 128–143
2025
-
[14]
Google Gemini. 2025. Gemini Live – Ask AI a question in any mode you choose.https://gemini.google/overview/gemini-live/
2025
-
[15]
Biao Gong, Cheng Zou, Chuanyang Zheng, Chunluan Zhou, Canxiang Yan, Chunxiang Jin, Chunjie Shen, Dandan Zheng, Fudong Wang, et al
-
[16]
Ming-Omni: A Unified Multimodal Model for Perception and Generation.arXiv preprint arXiv:2506.09344(2025)
arXiv 2025
-
[17]
Connor Holmes, Masahiro Tanaka, Michael Wyatt, Ammar Ah- mad Awan, Jeff Rasley, Samyam Rajbhandari, Reza Yazdani Am- inabadi, Heyang Qin, Arash Bakhtiari, Lev Kurilenko, et al . 2024. Deepspeed-fastgen: High-throughput text generation for llms via mii and deepspeed-inference.arXiv preprint arXiv:2401.08671(2024)
arXiv 2024
-
[18]
Shipeng Hu, Guangyan Zhang, Yuqi Zhou, Yaya Wei, Ziyan Zhong, and Jike Chen. 2026. Bidaw: Enhancing Key-Value Caching for Interactive LLM Serving via Bidirectional Computation–Storage Awareness. In 24th USENIX Conference on File and Storage Technologies (FAST 26). USENIX Association, Santa Clara, CA, 101–116.https://www.usenix. org/conference/fast26/prese...
2026
-
[19]
Jinwoo Jeong and Jeongseob Ahn. 2025. Accelerating llm serving for multi-turn dialogues with efficient resource management. InProceed- ings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 1–15
2025
-
[20]
Keisuke Kamahori, Wei-Tzu Lee, Atindra Jha, Rohan Kadekodi, Stephanie Wang, Arvind Krishnamurthy, and Baris Kasikci. 2026. VoxServe: Streaming-Centric Serving System for Speech Language Models.arXiv preprint arXiv:2602.00269(2026)
arXiv 2026
-
[21]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[22]
InProceedings of the 29th symposium on operating systems principles
Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles. 611–626
-
[23]
Xiaoxi Li, Wenxiang Jiao, Jiarui Jin, Shijian Wang, Guanting Dong, Jiajie Jin, Hao Wang, Yinuo Wang, Ji-Rong Wen, Yuan Lu, et al. 2026. Omnigaia: Towards native omni-modal ai agents.arXiv preprint arXiv:2602.22897(2026)
arXiv 2026
-
[24]
Yadong Li, Jun Liu, Tao Zhang, Song Chen, Tianpeng Li, Zehuan Li, Lijun Liu, Lingfeng Ming, Guosheng Dong, Da Pan, et al . 2025. Baichuan-Omni-1.5 Technical Report.arXiv preprint arXiv:2501.15368 (2025)
arXiv 2025
-
[25]
Zhicheng Li, Shuoming Zhang, Jiacheng Zhao, Siqi Li, Xiyu Shi, Yangyu Zhang, Shuaijiang Li, Donglin Yu, Zheming Yang, Yuan Wen, et al
-
[26]
SpaceServe: Spatial Multiplexing of Complementary Encoders and Decoders for Multimodal LLMs.Advances in Neural Information Processing Systems38 (2026), 79272–79296
2026
-
[27]
Junming Lin, Zheng Fang, Chi Chen, Zihao Wan, Fuwen Luo, Peng Li, Yang Liu, and Maosong Sun. 2024. StreamingBench: Assessing the Gap for MLLMs to Achieve Streaming Video Understanding. arXiv:2411.03628 [cs.CV] doi:10.48550/arXiv.2411.03628
-
[28]
Jiachen Liu, Jae-Won Chung, Zhiyu Wu, Fan Lai, Myungjin Lee, and Mosharaf Chowdhury. 2024. Andes: Defining and enhancing quality- of-experience in llm-based text streaming services.arXiv preprint arXiv:2404.16283(2024)
arXiv 2024
-
[29]
Yuhan Liu, Yihua Cheng, Jiayi Yao, Yuwei An, Xiaokun Chen, Shaot- ing Feng, Yuyang Huang, Samuel Shen, Rui Zhang, Kuntai Du, et al
-
[30]
Lmcache: An efficient KV cache layer for enterprise-scale LLM inference.arXiv preprint arXiv:2510.09665(2025)
arXiv 2025
-
[31]
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Anantha- narayanan, et al. 2024. Cachegen: Kv cache compression and streaming for fast large language model serving. InProceedings of the ACM SIG- COMM 2024 Conference. 38–56
2024
-
[32]
Zedong Liu, Shenggan Cheng, Guangming Tan, Yang You, and Ding- wen Tao. 2026. Elasticmm: Efficient multimodal llms serving with elastic multimodal parallelism.Advances in Neural Information Pro- cessing Systems38 (2026), 94264–94289
2026
-
[33]
Run Luo, Ting-En Lin, Haonan Zhang, Yuchuan Wu, Xiong Liu, Yong- bin Li, Longze Chen, Jiaming Li, Lei Zhang, Xiaobo Xia, et al . 2026. Openomni: Advancing open-source omnimodal large language mod- els with progressive multimodal alignment and real-time emotional speech synthesis.Advances in Neural Information Processing Systems 38 (2026), 158925–158953. X...
2026
-
[34]
Bowen Ma, Cheng Zou, Canxiang Yan, Chunxiang Jin, Chunjie Shen, Chenyu Lian, Dandan Zheng, Fudong Wang, Furong Xu, et al. 2025. Ming-Flash-Omni: A Sparse, Unified Architecture for Multimodal Per- ception and Generation.arXiv preprint arXiv:2510.24821(2025)
arXiv 2025
-
[35]
OpenAI. 2025. Introducing gpt-realtime and Realtime API updates for production voice agents.https://openai.com/index/introducing-gpt- realtime/
2025
-
[36]
Danny Harnik Or Ozeri. 2026. Inside vLLM’s New KV Offloading Con- nector: Smarter Memory Transfer for Maximizing Inference Through- put.https://vllm.ai/blog/2026-01-08-kv-offloading-connector
2026
-
[37]
Konstantinos Papaioannou and Thaleia Dimitra Doudali. 2026. TCM- Serve: Modality-aware Scheduling for Multimodal Large Language Model Inference.arXiv preprint arXiv:2603.26498(2026)
Pith/arXiv arXiv 2026
-
[38]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 118–132
2024
-
[39]
William Peebles and Saining Xie. 2023. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision. 4195–4205
2023
-
[40]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. 2025. Mooncake: Trading more storage for less computation—a {KVCache-centric} architecture for serving {LLM} chatbot. In23rd USENIX Conference on File and Storage Technologies (FAST 25). 155–170
2025
-
[41]
Haoran Qiu, Anish Biswas, Zihan Zhao, Jayashree Mohan, Alind Khare, Esha Choukse, Íñigo Goiri, Zeyu Zhang, Haiying Shen, Chetan Bansal, et al. 2025. Modserve: Modality-and stage-aware resource disaggrega- tion for scalable multimodal model serving. InProceedings of the 2025 ACM Symposium on Cloud Computing. 817–830
2025
-
[42]
ByteDance Seed. 2026. Doubao Realtime Voice Model.https://seed. bytedance.com/en/special/realtime_voice
2026
-
[43]
shareAI. 2023. ShareGPT Chinese-English 90K.https://huggingface. co/datasets/shareAI/ShareGPT-Chinese-English-90k
2023
-
[44]
Ying Sheng, Shiyi Cao, Dacheng Li, Banghua Zhu, Zhuohan Li, Danyang Zhuo, Joseph E Gonzalez, and Ion Stoica. 2024. Fairness in serving large language models. In18th USENIX Symposium on Op- erating Systems Design and Implementation (OSDI 24). 965–988
2024
-
[45]
Gursimran Singh, Xinglu Wang, Yifan Hu, Timothy Tin Long Yu, Linzi Xing, Wei Jiang, Zhefeng Wang, Bai Xiaolong, Yi Li, Ying Xiong, et al. [n. d.]. Efficiently Serving Large Multimodal Models Using EPD Disaggregation. InForty-second International Conference on Machine Learning
-
[46]
Biao Sun, Ziming Huang, Hanyu Zhao, Wencong Xiao, Xinyi Zhang, Yong Li, and Wei Lin. 2024. Llumnix: Dynamic scheduling for large lan- guage model serving. In18th USENIX symposium on operating systems design and implementation (OSDI 24). 173–191
2024
-
[47]
Nvidia Nemotron Team. 2026. Nemotron Voicechat Model.https: //build.nvidia.com/nvidia/nemotron-voicechat
2026
-
[48]
Qwen Team. 2026. Qwen3. 5-omni technical report.arXiv preprint arXiv:2604.15804(2026)
Pith/arXiv arXiv 2026
-
[49]
SGLang Team. 2026. SGLang Omni: High-Performance Multi-Stage Pipeline Framework for Omni Models.https://github.com/sgl-project/ sglang-omni
2026
-
[50]
Xiaomi Mimo Team. 2026. Xiaomi MiMo-V2-Omni.https://mimo. xiaomi.com/mimo-v2-omni
2026
-
[51]
Bairui Wang, Bin Xiao, Bo Zhang, Bolin Rong, Borun Chen, Chang Wan, Chao Zhang, Chen Huang, Chen Chen, et al . 2025. LongCat- Flash-Omni Technical Report.arXiv preprint arXiv:2511.00279(2025)
arXiv 2025
-
[52]
Yuxin Wang, Yuhan Chen, Zeyu Li, Xueze Kang, Yuchu Fang, Yeju Zhou, Yang Zheng, Zhenheng Tang, Xin He, Rui Guo, Xin Wang, Qiang Wang, Amelie Chi Zhou, and Xiaowen Chu. 2025. BurstGPT: A Real-World Workload Dataset to Optimize LLM Serving Systems. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Dis- covery and Data Mining V.2. ACM, New York, N...
-
[53]
Zichen Wen, Boxue Yang, Junlong Ke, Jiajie Huang, Chenfei Liao, Junxi Wang, Xuyang Liu, and Linfeng Zhang. 2026. EvoStreaming: Your Offline Video Model Is a Natively Streaming Assistant.arXiv preprint arXiv:2605.10343(2026)
Pith/arXiv arXiv 2026
-
[54]
Bingyang Wu, Yinmin Zhong, Zili Zhang, Shengyu Liu, Fangyue Liu, Yuanhang Sun, Gang Huang, Xuanzhe Liu, and Xin Jin. 2026. {FastServe}:{Iteration-Level} Preemptive Scheduling for Large Lan- guage Model Inference. In23rd USENIX Symposium on Networked Systems Design and Implementation (NSDI 26). 57–74
2026
-
[55]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, et al. 2025. Qwen2.5- omni technical report.arXiv preprint arXiv:2503.20215(2025)
Pith/arXiv arXiv 2025
-
[56]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, Yuanjun Lv, Yongqi Wang, Dake Guo, He Wang, Linhan Ma, Pei Zhang, Xinyu Zhang, Hongkun Hao, Zishan Guo, Baosong Yang, Bin Zhang, Ziyang Ma, Xipin Wei, Shuai Bai, Keqin Chen, Xuejing Liu, Peng Wang, Mingkun Yang, Dayiheng Liu, Xingzhang Ren, Bo ...
Pith/arXiv arXiv 2025
-
[57]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
Pith/arXiv arXiv 2025
-
[58]
Peiqi Yin, Jiangyun Zhu, Han Gao, Chenguang Zheng, Yongxiang Huang, Taichang Zhou, Ruirui Yang, Weizhi Liu, Weiqing Chen, Canlin Guo, et al. 2026. vLLM-Omni: Fully Disaggregated Serving for Any- to-Any Multimodal Models.arXiv preprint arXiv:2602.02204(2026)
arXiv 2026
-
[59]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A distributed serving system for {Transformer-Based} generative models. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). 521–538
2022
-
[60]
Lingfan Yu, Jinkun Lin, and Jinyang Li. 2025. Stateful large language model serving with pensieve. InProceedings of the Twentieth European Conference on Computer Systems. 144–158
2025
-
[61]
Z.AI. 2026. GLM-Image: Auto-regressive for Dense-knowledge and High-fidelity Image Generation.https://z.ai/blog/glm-image
2026
-
[62]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Livia Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. 2024. Sglang: Efficient execution of structured language model programs.Advances in neural information processing systems37 (2024), 62557–62583
2024
-
[63]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. {DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 193–210
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.