Ocean4D: Generative Underwater 4D Reconstruction via Medium-Aware Video Diffusion
Pith reviewed 2026-06-26 09:22 UTC · model grok-4.3
The pith
A generative video diffusion model produces consistent 4D underwater reconstructions from monocular input by building geometric conditions and handling medium effects implicitly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
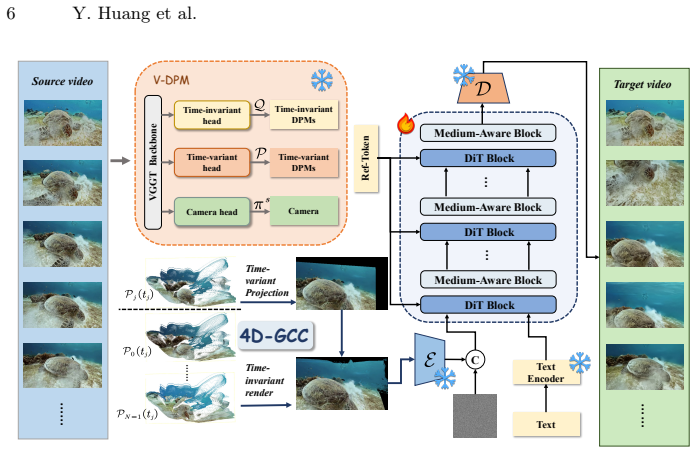
Ocean4D builds 4D geometrically consistent conditioning with improved cross-frame coverage through 4D-GCC and performs implicit medium-aware denoising via the Medium-Aware Block inside the latent diffusion process, allowing generation of videos along target camera trajectories that preserve global structure and cross-view consistency despite absorption, backscatter, and dynamic water variations.
What carries the argument
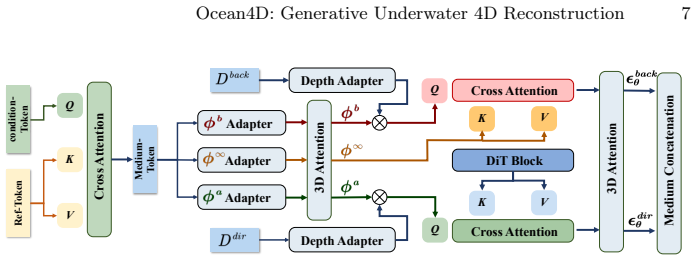
The Medium-Aware Block, which performs implicit medium-aware denoising during latent diffusion to stabilize appearance under absorption and scattering.
If this is right
- The method generates videos along target trajectories while preserving global structure and cross-view consistency.
- It achieves state-of-the-art results on both dynamic and static underwater benchmarks.
- It avoids sensitivity to drifting particles and dynamic distractors by dropping near-static assumptions.
- No explicit physical modeling or additional medium inputs are required.
Where Pith is reading between the lines
- The same implicit denoising strategy could extend to reconstruction in other participating media such as fog without redesigning the model.
- Underwater robot mapping tasks might rely on this method using only forward-facing video rather than calibrated multi-camera rigs.
- Longer sequences or higher turbidity levels could be tested to check whether the geometric conditioning remains stable over extended time.
Load-bearing premise
The Medium-Aware Block can implicitly handle absorption and scattering effects in denoising without needing explicit physical models or extra inputs.
What would settle it
Generated output videos that exhibit mismatched colors, structures, or drifting particles when rendered from different target camera paths under strong scattering conditions would falsify the consistency claim.
Figures






read the original abstract
Underwater 4D reconstruction remains challenging due to the coupling between degraded light transport in participating media and dynamic water variations. Most existing Methods are developed under in-air assumptions and do not explicitly account for underwater absorption and backscatter. Additionally, near-static assumptions make these approaches sensitive to drifting particles and dynamic distractors , leading to unstable geometry and inconsistent cross-view results. To address these issues, we propose a generative framework for underwater 4D reconstruction, named Ocean4D, which is built on two complementary components. Specifically, 4D-GCC constructs 4D geometrically consistent conditioning with improved cross-frame coverage, while the Medium-Aware Block performs implicit medium-aware denoising in the latent diffusion process to stabilize underwater appearance under absorption and scattering. Given a monocular video and target cameras, our method generates videos along the target trajectories while preserving global structure and cross-view consistency. Extensive experiments on both dynamic and static underwater benchmarks demonstrate state-of-the-art performance on underwater reconstruction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Ocean4D, a generative framework for underwater 4D reconstruction from monocular video. It consists of two main components: 4D-GCC, which constructs 4D geometrically consistent conditioning with improved cross-frame coverage, and the Medium-Aware Block, which performs implicit medium-aware denoising in the latent diffusion process to stabilize underwater appearance under absorption and scattering. Given a monocular video and target cameras, the method generates videos along target trajectories while preserving global structure and cross-view consistency, and claims state-of-the-art performance on both dynamic and static underwater benchmarks.
Significance. If the central claims hold, the work could meaningfully advance underwater computer vision by demonstrating that video diffusion models can implicitly handle participating media effects and dynamic distractors without explicit physical modeling or additional inputs. This implicit stabilization approach, if effective, would be a useful design pattern for other challenging environments where light transport is degraded.
minor comments (2)
- The abstract contains a capitalization inconsistency: 'Most existing Methods' should read 'methods'.
- The abstract contains a typographical error with an extraneous space before the comma: 'distractors , leading'.
Simulated Author's Rebuttal
We thank the referee for their summary of Ocean4D and for noting its potential to advance underwater computer vision through implicit handling of participating media. The recommendation is uncertain, yet the report contains no enumerated major comments. We therefore provide a general response below and stand ready to address any specific concerns the referee may wish to raise.
Circularity Check
No significant circularity in claimed derivation chain
full rationale
The abstract and description present Ocean4D as a proposed generative framework whose two components (4D-GCC and Medium-Aware Block) are introduced as architectural design choices to handle underwater media effects and consistency. No equations, fitted parameters, predictions, uniqueness theorems, or self-citations appear that would reduce any result to its own inputs by construction. The method is described at the level of high-level components and empirical performance claims rather than a derivation chain that collapses into self-definition or renamed fits. This is the common case of a self-contained engineering proposal without load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proc
Akkaynak, D., Treibitz, T.: A revised underwater image formation model. In: Proc. CVPR. pp. 6723–6732 (2018) 2, 4
2018
-
[2]
In: Proc
Akkaynak, D., Treibitz, T.: Sea-thru: A method for removing water from under- water images. In: Proc. CVPR. pp. 1682–1691 (2019) 2
2019
-
[3]
arXiv preprint arXiv:2001.00330 (2020) 1
Arain, B., Dayoub, F., Rigby, P., Dunbabin, M.: Close-proximity underwater terrain mapping using learning-based coarse range estimation. arXiv preprint arXiv:2001.00330 (2020) 1
arXiv 2001
-
[4]
In: Proc
Bai, J., Xia, M., Fu, X.,Wang, X.,Mu, L., Cao, J.,Liu, Z., Hu, H.,Bai, X., Wan, P., et al.: Recammaster: Camera-controlled generative rendering from a single video. In: Proc. ICCV. pp. 14834–14844 (2025) 2, 4, 9, 10, 12
2025
-
[5]
In: Proc
Barron, J.T., Mildenhall, B., Tancik, M., Hedman, P., Martin-Brualla, R., Srini- vasan, P.P.: Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In: Proc. ICCV. pp. 5855–5864 (2021) 2, 3
2021
-
[6]
In: Proc
Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In: Proc. CVPR. pp. 5470–5479 (2022) 2, 3
2022
-
[7]
In: Proc
Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Zip-nerf: Anti-aliased grid-based neural radiance fields. In: Proc. ICCV. pp. 19697–19705 (2023) 2, 3
2023
-
[8]
arXiv preprint arXiv:2311.15127 (2023) 2, 4, 5
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023) 2, 4, 5
Pith/arXiv arXiv 2023
-
[9]
In: Proc
Blattmann, A., Rombach, R., Ling, H., Dockhorn, T., Kim, S.W., Fidler, S., Kreis, K.: Align your latents: High-resolution video synthesis with latent diffusion models. In: Proc. CVPR. pp. 22563–22575 (2023) 2, 5
2023
-
[10]
In: Proc
Chen, A., Xu, Z., Zhao, F., Zhang, X., Xiang, F., Yu, J., Su, H.: Mvsnerf: Fast generalizable radiance field reconstruction from multi-view stereo. In: Proc. ICCV. pp. 14124–14133 (2021) 2, 3
2021
-
[11]
arXiv preprint arXiv:2310.19512 (2023) 4, 5
Chen, H., Xia, M., He, Y., Zhang, Y., Cun, X., Yang, S., Xing, J., Liu, Y., Chen, Q., Wang, X., et al.: Videocrafter1: Open diffusion models for high-quality video generation. arXiv preprint arXiv:2310.19512 (2023) 4, 5
Pith/arXiv arXiv 2023
-
[12]
Computers & Graphics 123, 104025 (2024) 4
Chen, L., Xiong, Y., Zhang, Y., Yu, R., Fang, L., Liu, D.: Sp-seanerf: Underwater neural radiance fields with strong scattering perception. Computers & Graphics 123, 104025 (2024) 4
2024
-
[13]
In: Proc
Chen, Y., Xu, H., Zheng, C., Zhuang, B., Pollefeys, M., Geiger, A., Cham, T.J., Cai, J.: Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. In: Proc. ECCV. pp. 370–386. Springer (2024) 2, 3
2024
-
[14]
Symmetry16(8), 1010 (2024) 2, 4 16 Y
Du, Y., Zhang, Z., Zhang, P., Sun, F., Lv, X.: Udr-gs: Enhancing underwater dynamic scene reconstruction with depth regularization. Symmetry16(8), 1010 (2024) 2, 4 16 Y. Huang et al
2024
-
[15]
In: proc
Duan, Y., Wei, F., Dai, Q., He, Y., Chen, W., Chen, B.: 4d-rotor gaussian splat- ting: towards efficient novel view synthesis for dynamic scenes. In: proc. ACM SIGGRAPH. pp. 1–11 (2024) 3
2024
-
[16]
arXiv preprint arXiv:2403.20309 (2024) 2, 3
Fan, Z., Cong, W., Wen, K., Wang, K., Zhang, J., Ding, X., Xu, D., Ivanovic, B., Pavone, M., Pavlakos, G., et al.: Instantsplat: Sparse-view gaussian splatting in seconds. arXiv preprint arXiv:2403.20309 (2024) 2, 3
arXiv 2024
-
[17]
In: Proc
Feng, C., Yu, W., Cheng, X., Tang, Z., Zhang, J., Yuan, L., Tian, Y.: Ae-nerf: Augmenting event-based neural radiance fields for non-ideal conditions and larger scenes. In: Proc. AAAI. vol. 39, pp. 2924–2932 (2025) 3
2025
-
[18]
In: Proc
Fu, X., Zhuang, P., Huang, Y., Liao, Y., Zhang, X.P., Ding, X.: A retinex-based enhancing approach for single underwater image. In: Proc. ICIP. pp. 4572–4576. IEEE (2014) 3
2014
-
[19]
Advances in Neural Information Processing Systems (2024) 4
Gao*, R., Holynski*, A., Henzler, P., Brussee, A., Martin-Brualla, R., Srinivasan, P.P., Barron, J.T., Poole*, B.: Cat3d: Create anything in 3d with multi-view dif- fusion models. Advances in Neural Information Processing Systems (2024) 4
2024
-
[20]
International Journal of Naval Ar- chitecture and Ocean Engineering6(4), 840–866 (2014) 3
Ghani, A.S.A., Isa, N.A.M.: Underwater image quality enhancement through rayleigh-stretching and averaging image planes. International Journal of Naval Ar- chitecture and Ocean Engineering6(4), 840–866 (2014) 3
2014
-
[21]
Sensors16(8), 1174 (2016) 1
Hernández, J.D., Istenič, K., Gracias, N., Palomeras, N., Campos, R., Vidal, E., Garcia, R., Carreras, M.: Autonomous underwater navigation and optical mapping in unknown natural environments. Sensors16(8), 1174 (2016) 1
2016
-
[22]
PloS one15(3), e0230671 (2020) 1
Hopkinson, B.M., King, A.C., Owen, D.P., Johnson-Roberson, M., Long, M.H., Bhandarkar, S.M.: Automated classification of three-dimensional reconstructions of coral reefs using convolutional neural networks. PloS one15(3), e0230671 (2020) 1
2020
-
[23]
Journal of Marine Science and Engineering11(5), 949 (2023) 2
Hu, K., Wang, T., Shen, C., Weng, C., Zhou, F., Xia, M., Weng, L.: Overview of underwater 3d reconstruction technology based on optical images. Journal of Marine Science and Engineering11(5), 949 (2023) 2
2023
-
[24]
In: Proc
Hu, W., Gao, X., Li, X., Zhao, S., Cun, X., Zhang, Y., Quan, L., Shan, Y.: Depthcrafter: Generating consistent long depth sequences for open-world videos. In: Proc. CVPR. pp. 2005–2015 (2025) 5, 10
2005
-
[25]
In: Proc
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video genera- tive models. In: Proc. CVPR. pp. 21807–21818 (2024) 10, 11
2024
-
[26]
In: 2010 IEEE international conference on systems, man and cybernetics
Iqbal, K., Odetayo, M., James, A., Salam, R.A., Talib, A.Z.H.: Enhancing the low quality images using unsupervised colour correction method. In: 2010 IEEE international conference on systems, man and cybernetics. pp. 1703–1709. IEEE (2010) 3
2010
-
[27]
ACM Transactions on Graphics44(6), 1–16 (2025) 3, 9, 11, 12, 13
Jiang, L., Mao, Y., Xu, L., Lu, T., Ren, K., Jin, Y., Xu, X., Yu, M., Pang, J., Zhao, F., et al.: Anysplat: Feed-forward 3d gaussian splatting from unconstrained views. ACM Transactions on Graphics44(6), 1–16 (2025) 3, 9, 11, 12, 13
2025
-
[28]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G., et al.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023) 2, 3, 9, 11, 12
2023
-
[29]
In: Proc
Levy, D., Peleg, A., Pearl, N., Rosenbaum, D., Akkaynak, D., Korman, S., Treibitz, T.: Seathru-nerf: Neural radiance fields in scattering media. In: Proc. CVPR. pp. 56–65 (2023) 3
2023
-
[30]
In: Proc
Li, H., Song, W., Xu, T., Elsig, A., Kulhanek, J.: Watersplatting: Fast underwater 3d scene reconstruction using gaussian splatting. In: Proc. 3DV. pp. 969–978. IEEE (2025) 2, 4, 9, 11, 12, 13 Ocean4D: Generative Underwater 4D Reconstruction 17
2025
-
[31]
In: Proc
Li, J., Li, D., Xiong, C., Hoi, S.: Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In: Proc. ICML. pp. 12888–12900. PMLR (2022) 7
2022
-
[32]
Springer (2024) 2, 3
Liang, Z., Zhang, Q., Hu, W., Zhu, L., Feng, Y., Jia, K.: Analytic-splatting: Anti- aliased3dgaussiansplattingviaanalyticintegration.In:Proc.ECCV.pp.281–297. Springer (2024) 2, 3
2024
-
[33]
arXiv preprint arXiv:2412.00131 (2024) 4
Lin, B., Ge, Y., Cheng, X., Li, Z., Zhu, B., Wang, S., He, X., Ye, Y., Yuan, S., Chen, L., et al.: Open-sora plan: Open-source large video generation model. arXiv preprint arXiv:2412.00131 (2024) 4
Pith/arXiv arXiv 2024
-
[34]
In: Proc
Lin, C.H., Ma, W.C., Torralba, A., Lucey, S.: Barf: Bundle-adjusting neural radi- ance fields. In: Proc. ICCV. pp. 5741–5751 (2021) 3
2021
-
[35]
In: Proc
Liu, R., Wu, R., Van Hoorick, B., Tokmakov, P., Zakharov, S., Vondrick, C.: Zero- 1-to-3: Zero-shot one image to 3d object. In: Proc. ICCV. pp. 9298–9309 (2023) 4
2023
-
[36]
arXiv preprint arXiv:2411.00239 (2024) 2, 4
Liu, S., Lu, J., Gu, Z., Li, J., Deng, Y.: Aquatic-gs: A hybrid 3d representation for underwater scenes. arXiv preprint arXiv:2411.00239 (2024) 2, 4
arXiv 2024
-
[37]
Commu- nications of the ACM65(1), 99–106 (2021) 2
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM65(1), 99–106 (2021) 2
2021
-
[38]
In: Proc
Müller, N., Schwarz, K., Rössle, B., Porzi, L., Bulo, S.R., Nießner, M., Kontschieder, P.: Multidiff: Consistent novel view synthesis from a single image. In: Proc. CVPR. pp. 10258–10268 (2024) 4
2024
-
[39]
Frontiers in Environmental Science10, 1044706 (2022) 1
de Oliveira, L.M.C., Lim, A., Conti, L.A., Wheeler, A.J.: High-resolution 3d map- ping of cold-water coral reefs using machine learning. Frontiers in Environmental Science10, 1044706 (2022) 1
2022
-
[40]
In: Proc
Park, K., Sinha, U., Barron, J.T., Bouaziz, S., Goldman, D.B., Seitz, S.M., Martin- Brualla, R.: Nerfies: Deformable neural radiance fields. In: Proc. ICCV. pp. 5865– 5874 (2021) 3
2021
-
[41]
In: Proc
Pumarola, A., Corona, E., Pons-Moll, G., Moreno-Noguer, F.: D-nerf: Neural ra- diance fields for dynamic scenes. In: Proc. CVPR. pp. 10318–10327 (2021) 3
2021
-
[42]
Journal of Machine Learning Research21(140), 1–67 (2020) 7
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.J.: Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research21(140), 1–67 (2020) 7
2020
-
[43]
In: Proc
Ren,X.,Shen,T.,Huang,J.,Ling,H.,Lu,Y.,Nimier-David,M.,Müller,T.,Keller, A., Fidler, S., Gao, J.: Gen3c: 3d-informed world-consistent video generation with precise camera control. In: Proc. CVPR. pp. 6121–6132 (2025) 2, 4
2025
-
[44]
In: Proc
Sargent, K., Li, Z., Shah, T., Herrmann, C., Yu, H.X., Zhang, Y., Chan, E.R., Lagun, D., Fei-Fei, L., Sun, D., et al.: Zeronvs: Zero-shot 360-degree view synthesis from a single image. In: Proc. CVPR. pp. 9420–9429 (2024) 4
2024
-
[45]
In: OCEANS 2023-MTS/IEEE US Gulf Coast
Sethuraman, A.V., Ramanagopal, M.S., Skinner, K.A.: Waternerf: Neural radiance fields for underwater scenes. In: OCEANS 2023-MTS/IEEE US Gulf Coast. pp. 1–
2023
-
[46]
In: Proc
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. In: Proc. ICLR (2020) 4
2020
-
[47]
IEEE Transactions on Visualization and Computer Graphics29(5), 2732–2742 (2023) 3
Song, L., Chen, A., Li, Z., Chen, Z., Chen, L., Yuan, J., Xu, Y., Geiger, A.: Nerf- player: A streamable dynamic scene representation with decomposed neural radi- ance fields. IEEE Transactions on Visualization and Computer Graphics29(5), 2732–2742 (2023) 3
2023
-
[48]
arXiv preprint arXiv:2601.09499 (2026) 6, 9 18 Y
Sucar, E., Insafutdinov, E., Lai, Z., Vedaldi, A.: V-dpm: 4d video reconstruction with dynamic point maps. arXiv preprint arXiv:2601.09499 (2026) 6, 9 18 Y. Huang et al
arXiv 2026
-
[49]
In: Proc
Tang, Y., Zhu, C., Wan, R., Xu, C., Shi, B.: Neural underwater scene representa- tion. In: Proc. CVPR. pp. 11780–11789 (2024) 3, 9, 12, 13
2024
-
[50]
In: Proc
Van Hoorick, B., Wu, R., Ozguroglu, E., Sargent, K., Liu, R., Tokmakov, P., Dave, A., Zheng, C., Vondrick, C.: Generative camera dolly: Extreme monocular dynamic novel view synthesis. In: Proc. ECCV. pp. 313–331. Springer (2024) 2, 4, 5
2024
-
[51]
In: Proc
Varghese, N., Kumar, A., Rajagopalan, A.: Self-supervised monocular underwater depth recovery, image restoration, and a real-sea video dataset. In: Proc. ICCV. pp. 12248–12258 (2023) 9, 12, 13
2023
-
[52]
IEEE Transactions on Pattern Analysis and Machine Intelligence47(11), 9426–9437 (2024) 3
Verbin, D., Hedman, P., Mildenhall, B., Zickler, T., Barron, J.T., Srinivasan, P.P.: Ref-nerf: Structured view-dependent appearance for neural radiance fields. IEEE Transactions on Pattern Analysis and Machine Intelligence47(11), 9426–9437 (2024) 3
2024
-
[53]
In: Proc
Wang, H., Agapito, L.: 3d reconstruction with spatial memory. In: Proc. 3DV. pp. 78–89. IEEE (2025) 3
2025
-
[54]
In: Proc
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proc. CVPR. pp. 5294–5306 (2025) 3, 9
2025
-
[55]
In: Proc
Wang, Q., Zhang, Y., Holynski, A., Efros, A.A., Kanazawa, A.: Continuous 3d perception model with persistent state. In: Proc. CVPR. pp. 10510–10522 (2025) 3
2025
-
[56]
In: Proc
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: Dust3r: Geometric 3d vision made easy. In: Proc. CVPR. pp. 20697–20709 (2024) 3
2024
-
[57]
In: Proc
Wu, G., Yi, T., Fang, J., Xie, L., Zhang, X., Wei, W., Liu, W., Tian, Q., Wang, X.: 4d gaussian splatting for real-time dynamic scene rendering. In: Proc. CVPR. pp. 20310–20320 (2024) 3
2024
-
[58]
In: Proc
Wu, R., Gao, R., Poole, B., Trevithick, A., Zheng, C., Barron, J.T., Holynski, A.: Cat4d: Create anything in 4d with multi-view video diffusion models. In: Proc. CVPR. pp. 26057–26068 (2025) 4
2025
-
[59]
In: Proc
Wu, R., Mildenhall, B., Henzler, P., Park, K., Gao, R., Watson, D., Srinivasan, P.P., Verbin, D., Barron, J.T., Poole, B., et al.: Reconfusion: 3d reconstruction with diffusion priors. In: Proc. CVPR. pp. 21551–21561 (2024) 4
2024
-
[60]
In: Proc
Xie, Y., Kong, L., Chen, K., Zheng, Z., Yu, X., Yu, Z., Zheng, B.: Uveb: A large- scale benchmark and baseline towards real-world underwater video enhancement. In: Proc. CVPR. pp. 22358–22367 (2024) 9, 10
2024
-
[61]
In: Proc
Yang, D., Leonard, J.J., Girdhar, Y.: Seasplat: Representing underwater scenes with 3d gaussian splatting and a physically grounded image formation model. In: Proc. ICRA. pp. 7632–7638. IEEE (2025) 2, 4
2025
-
[62]
In: Proc
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. In: Proc. ICLR (2024) 4, 5, 7
2024
-
[63]
Advancesin Neural Information ProcessingSystems34,4805–4815(2021) 2
Yariv, L., Gu, J., Kasten, Y., Lipman, Y.: Volume rendering of neural implicit surfaces. Advancesin Neural Information ProcessingSystems34,4805–4815(2021) 2
2021
-
[64]
In: Proc
Yu, M., Hu, W., Xing, J., Shan, Y.: Trajectorycrafter: Redirecting camera trajec- tory for monocular videos via diffusion models. In: Proc. ICCV. pp. 100–111 (2025) 2, 4, 5, 6, 7, 9, 10, 11, 12, 13
2025
-
[65]
In: Proc
Yu, W., Fan, Y., Zhang, Y., Wang, X., Yin, F., Bai, Y., Cao, Y.P., Shan, Y., Wu, Y., Sun, Z., et al.: Nofa: Nerf-based one-shot facial avatar reconstruction. In: Proc. ACM SIGGRAPH. pp. 1–12 (2023) 3 Ocean4D: Generative Underwater 4D Reconstruction 19
2023
-
[66]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025) 4
Yu, W., Xing, J., Yuan, L., Hu, W., Li, X., Huang, Z., Gao, X., Wong, T.T., Shan, Y., Tian, Y.: Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025) 4
2025
-
[67]
In: Proc
Zhang, J., Herrmann, C., Hur, J., Jampani, V., Darrell, T., Cole, F., Sun, D., Yang, M.H.: Monst3r: A simple approach for estimating geometry in the presence of motion. In: Proc. ICLR (2024) 3
2024
-
[68]
Neurocomputing245, 1–9 (2017) 3
Zhang, S., Wang, T., Dong, J., Yu, H.: Underwater image enhancement via ex- tended multi-scale retinex. Neurocomputing245, 1–9 (2017) 3
2017
-
[69]
In: Proc
Zhu, Z., Fan, Z., Jiang, Y., Wang, Z.: Fsgs: Real-time few-shot view synthesis using gaussian splatting. In: Proc. ECCV. pp. 145–163. Springer (2024) 3
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.