From Pixels to Concepts: Growing Rich 3D Semantic Scene Graph Forests utilizing Foundation Models
Pith reviewed 2026-06-26 08:11 UTC · model grok-4.3
The pith
Foundation models identify instance concepts with VLMs then infer abstract ones with LLMs to assemble forests of hierarchical 3D scene graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
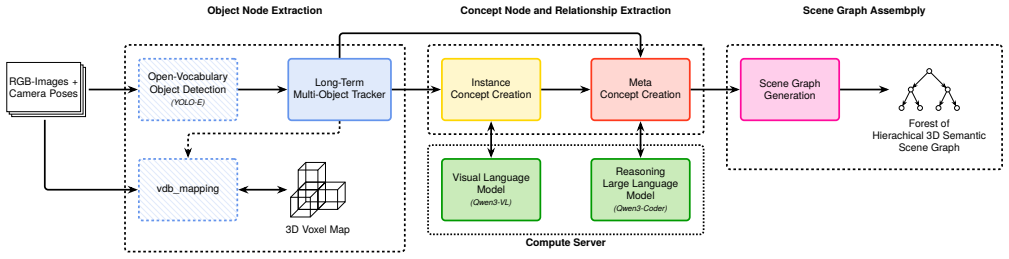
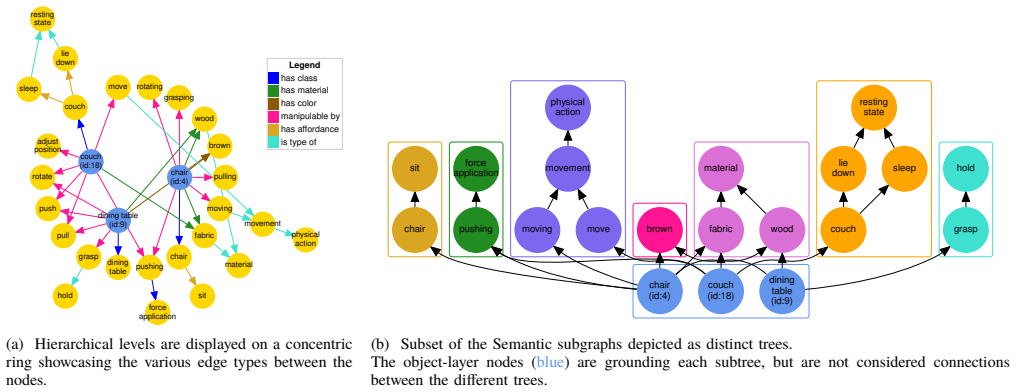
The central claim is that foundation models enable the construction of forests of hierarchical 3D scene graphs by first extracting instance-specific concept-nodes and relationships via a VLM and then extending them with abstract concept-nodes and relationships inferred through LLM reasoning, producing open semantic structures that integrate geometric, semantic, and relational data for improved scene understanding and robotic task execution, as shown through evaluations on uHumans2 and ScanNet plus a real-world object-retrieval demonstration on a Boston Dynamics Spot.
What carries the argument
The pipeline that uses a VLM to detect instance-specific concept-nodes and relationships from visual input, extends them via LLM reasoning to abstract concepts and open relations, and assembles the results into a forest of hierarchical 3D scene graphs enhanced with concept-nodes.
If this is right
- The generated relationships achieve measurable accuracy and relevance when evaluated on the uHumans2 and ScanNet indoor datasets.
- Scene-graph forests support open-vocabulary object-retrieval tasks both on ScanNet data and in a physical indoor deployment with a Boston Dynamics Spot robot.
- The resulting graphs capture more expressive semantic and environmental connections than approaches limited to fixed relationship classes.
- Robots obtain a multi-layer world model that integrates geometric, semantic, and relational information in a single spatial framework.
Where Pith is reading between the lines
- Such graphs could let robots plan actions that respect inferred causal or contextual links rather than treating objects in isolation.
- The same VLM-LLM assembly process might extend to dynamic or outdoor scenes if the underlying models generalize without additional fine-tuning.
- Downstream planners could query the abstract concept-nodes directly to generate higher-level task descriptions beyond simple retrieval.
Load-bearing premise
The vision-language and large language model outputs remain accurate and consistent enough that the assembled scene graphs stay useful for robotics tasks without accumulating errors from hallucinations or mis-inferences.
What would settle it
An object-retrieval or navigation task on ScanNet or real indoor data in which the generated scene-graph forest produces a wrong action traceable to a specific hallucinated or mis-inferred relationship that contradicts ground-truth human annotations.
Figures




read the original abstract
Operating in complex real-world environments requires robots to understand their surroundings on a functional semantic level. This demands a detailed multi-layer world model capturing the complex relations of its surroundings. Hierarchical 3D scene graphs address this challenge by integrating geometric, semantic, and relational data within a unified spatial framework. However, current 3D scene graph approaches often restrict themselves to rigid structures of pre-determined relationship classes, mostly neglecting important semantic connections, like causal connections or environmental contexts. This paper explores the potential of foundation models to build forests of 3D scene graphs with open semantic relationships to improve scene understanding and robotic task execution. We propose a method where instance-specific concept-nodes and relationships are first identified by a VLM and extended upon by a LLM, inferring broader, more abstract concept-nodes and relationships through reasoning. These object-nodes, concept-nodes, and relationships are then assembled into a forest of hierarchical 3D scene graphs, enhanced with concept-nodes to represent abstract concepts. Evaluations were conducted on the uHumans2 and ScanNet indoor dataset, validating the accuracy and relevance of the generated relationships. Downstream suitability of scene-graph forests for robotics applications is demonstrated in an open-vocabulary object-retrieval task utilizing both ScanNet data and a real-world indoor deployment using a Boston Dynamics Spot. This paper leverages foundation models to create more expressive, semantically deep 3D hierarchical scene graphs and demonstrates their potential to advance semantic and environmental understanding in robotics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a pipeline leveraging vision-language models (VLMs) to detect instance-specific nodes and open relationships, followed by large language models (LLMs) to infer abstract concept-nodes via reasoning, can assemble these into forests of hierarchical 3D scene graphs. These graphs are said to improve semantic scene understanding beyond rigid predefined relations; the approach is evaluated for accuracy/relevance on uHumans2 and ScanNet and demonstrated in an open-vocabulary object-retrieval task on both ScanNet data and a real Boston Dynamics Spot deployment.
Significance. If the VLM/LLM-derived semantic layers prove accurate and the added abstract concepts measurably enhance task performance over geometric baselines, the work could enable more flexible, open-vocabulary world models for robotics that capture causal and contextual relations without hand-crafted taxonomies.
major comments (2)
- [Evaluation on uHumans2 and ScanNet] Evaluation section (uHumans2/ScanNet validation paragraph): the claim that accuracy and relevance of the generated open relationships were validated is unsupported by any reported quantitative metrics (precision, recall, F1, or inter-annotator agreement against human labels for the VLM/LLM outputs). This is load-bearing for the central claim that the semantic forest improves understanding and task execution.
- [Downstream object-retrieval task] Downstream suitability demonstration (object-retrieval task): no ablation isolating the contribution of the LLM-inferred abstract concept-nodes or VLM relationships versus the base geometric scene graph is presented, leaving open the possibility that observed gains derive from geometry alone rather than the added semantic layer. This directly affects the claim that the rich semantic forest advances robotic task execution.
minor comments (2)
- The abstract refers to 'forests' of scene graphs but provides no explicit description of how multiple graphs are constructed or merged from the per-scene pipeline.
- Notation for 'concept-nodes' versus 'object-nodes' is introduced without a clarifying diagram or formal definition in the method overview.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where the evaluation can be strengthened. We agree that quantitative support for the semantic components and an ablation for the downstream task are important. We will revise the manuscript to incorporate these elements.
read point-by-point responses
-
Referee: [Evaluation on uHumans2 and ScanNet] Evaluation section (uHumans2/ScanNet validation paragraph): the claim that accuracy and relevance of the generated open relationships were validated is unsupported by any reported quantitative metrics (precision, recall, F1, or inter-annotator agreement against human labels for the VLM/LLM outputs). This is load-bearing for the central claim that the semantic forest improves understanding and task execution.
Authors: We agree that the manuscript currently lacks quantitative metrics (precision, recall, F1) and inter-annotator agreement for the VLM/LLM-generated relationships; the validation described is qualitative via examples. In the revised manuscript we will add a human evaluation study on sampled outputs from uHumans2 and ScanNet, reporting the requested metrics together with agreement scores to substantiate the accuracy claims. revision: yes
-
Referee: [Downstream object-retrieval task] Downstream suitability demonstration (object-retrieval task): no ablation isolating the contribution of the LLM-inferred abstract concept-nodes or VLM relationships versus the base geometric scene graph is presented, leaving open the possibility that observed gains derive from geometry alone rather than the added semantic layer. This directly affects the claim that the rich semantic forest advances robotic task execution.
Authors: We acknowledge the absence of an ablation that isolates the LLM-inferred concept-nodes and VLM relationships from the geometric baseline. The current results show overall task performance but do not quantify the semantic contribution. In revision we will add an ablation on the retrieval task (both ScanNet and Spot data) comparing the full forest against a geometric-only graph, reporting the performance delta attributable to the semantic layer. revision: yes
Circularity Check
No circularity: pipeline relies on external foundation models without self-referential fitting or definitional loops
full rationale
The described method is a sequential pipeline (VLM for instance nodes/relations, LLM for abstract extensions, assembly into graphs) evaluated on external datasets (uHumans2, ScanNet) with a downstream robotics task. No equations, fitted parameters, or predictions appear; no self-citations are load-bearing for the core claim; the approach does not reduce any output to its inputs by construction. This is a standard non-circular application of off-the-shelf models.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SayPlan: Grounding large language models using 3d scene graphs for scalable robot task planning,
Rana, K., Haviland, J., Garg, S., Abou-Chakra, J., Reid, I., and Suenderhauf, N., “SayPlan: Grounding large language models using 3d scene graphs for scalable robot task planning,” in Proceedings of The 7th Conference on Robot Learning , PMLR, Dec. 2, 2023, pp. 23–72
2023
-
[2]
Hydra: A real-time spatial perception system for 3d scene graph construction and optimiza- tion,
Hughes, N., Chang, Y ., and Carlone, L., “Hydra: A real-time spatial perception system for 3d scene graph construction and optimiza- tion,” in Robotics: Science and Systems XVIII , Robotics: Science and Systems Foundation, Jun. 27, 2022, ISBN: 978-0-9923747-8-5. DOI: 10.15607/RSS.2022.XVIII.050
-
[3]
Maggio, D. et al., Clio: Real-time task-driven open-set 3d scene graphs, Apr. 2024. DOI: 10.1109/LRA.2024.3451395
-
[4]
Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification
Armeni, I. et al., “3d scene graph: A structure for unified semantics, 3d space, and camera,” in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea (South): IEEE, Oct. 2019, pp. 5663–5672, ISBN: 978-1-7281-4803-8. DOI: 10.1109/ICCV. 2019.00576
-
[5]
et al., Kimera: From SLAM to spatial perception with 3d dynamic scene graphs , Jan
Rosinol, A. et al., Kimera: From SLAM to spatial perception with 3d dynamic scene graphs , Jan. 2021. DOI: 10 . 1177 / 02783649211056674
2021
-
[6]
Scene Adaptive Sparse Transformer for Event-based Object Detection
Koch, S., Vaskevicius, N., Colosi, M., Hermosilla, P ., and Ropin- ski, T., “Open3dsg: Open-vocabulary 3d scene graphs from point clouds with queryable objects and open-set relationships,” in 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, W A, USA: IEEE, Jun. 16, 2024, pp. 14 183– 14 193, ISBN: 979-8-3503-5300-6. DOI:...
-
[7]
Chen, W., Hu, S., Talak, R., and Carlone, L., Leveraging large (visual) language models for robot 3d scene understanding , Nov. 8,
-
[8]
DOI: 10.48550/arXiv.2209.05629
-
[9]
Gu, Q. et al., “ConceptGraphs: Open-vocabulary 3d scene graphs for perception and planning,” in 2024 IEEE International Conference on Robotics and Automation (ICRA) , May 2024, pp. 5021–5028. DOI: 10.1109/ICRA57147.2024.10610243
-
[10]
A comprehensive survey of scene graphs: Generation and application,
Chang, X., Ren, P ., Xu, P ., Li, Z., Chen, X., and Hauptmann, A., “A comprehensive survey of scene graphs: Generation and application,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 45, no. 1, pp. 1–26, Jan. 2023, ISSN: 1939-3539. DOI: 10 . 1109/TPAMI.2021.3137605
arXiv 2023
-
[11]
Chen, L., Wang, X., Lu, J., Lin, S., Wang, C., and He, G., “Clip-driven open-vocabulary 3d scene graph generation via cross- modality contrastive learning,” in 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2024, pp. 27 863–27 873. DOI: 10.1109/CVPR52733.2024.02632
-
[12]
et al., Context-aware entity grounding with open- vocabulary 3d scene graphs , 2023
Chang, H. et al., Context-aware entity grounding with open- vocabulary 3d scene graphs , 2023. DOI: 10 . 48550 / arXiv . 2309.15940
arXiv 2023
-
[13]
Learning transferable visual models from natural language supervision,
Radford, A. et al., “Learning transferable visual models from natural language supervision,” in Proceedings of the 38th International Conference on Machine Learning , PMLR, Jul. 1, 2021, pp. 8748– 8763
2021
-
[14]
et al., Open-vocabulary functional 3d scene graphs for real-world indoor spaces , Mar
Zhang, C. et al., Open-vocabulary functional 3d scene graphs for real-world indoor spaces , Mar. 24, 2025. DOI: 10 . 48550 / arXiv.2503.19199
arXiv 2025
-
[15]
SceneGraphFusion: Incremental 3d scene graph prediction from RGB-d sequences,
Wu, S.-C., Wald, J., Tateno, K., Navab, N., and Tombari, F., “SceneGraphFusion: Incremental 3d scene graph prediction from RGB-d sequences,” in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA: IEEE, Jun. 2021, pp. 7511–7521, ISBN: 978-1-6654-4509-2. DOI: 10 . 1109/CVPR46437.2021.00743
arXiv 2021
-
[16]
Lang3dsg: Language-based contrastive pre-training for 3d scene graph prediction,
Koch, S., Hermosilla, P ., Vaskevicius, N., Colosi, M., and Ropinski, T., “Lang3dsg: Language-based contrastive pre-training for 3d scene graph prediction,” in 2024 International Conference on 3D Vision (3DV), Mar. 2024, pp. 1037–1047. DOI: 10.1109/3DV62453. 2024.00076
-
[17]
Learning 3d semantic scene graphs from 3d indoor reconstructions,
Wald, J., Dhamo, H., Navab, N., and Tombari, F., “Learning 3d semantic scene graphs from 3d indoor reconstructions,” presented at the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 3961–3970. DOI: 10.1109/ CVPR42600.2020.00402
arXiv 2020
-
[18]
Hierarchical open-vocabulary 3d scene graphs for language- grounded robot navigation,
Werby, A., Huang, C., Büchner, M., Valada, A., and Burgard, W., “Hierarchical open-vocabulary 3d scene graphs for language- grounded robot navigation,” Robotics: Science and Systems , 2024. DOI: 10.15607/RSS.2024.XX.077
-
[19]
Devarakonda, V . N. et al., OrionNav: Online planning for robot autonomy with context-aware LLM and open-vocabulary semantic scene graphs , Oct. 8, 2024. DOI: 10 . 48550 / arXiv . 2410 . 06239
2024
-
[20]
et al., Segment anything , Apr
Kirillov, A. et al., Segment anything , Apr. 5, 2023. DOI: 10 . 48550/arXiv.2304.02643
Pith/arXiv arXiv 2023
-
[21]
Available: https://doi.org/10.48550/arXiv.2503
Wang, A., Liu, L., Chen, H., Lin, Z., Han, J., and Ding, G., Yoloe: Real-time seeing anything, 2025. DOI: 10.48550/arXiv.2503. 07465
-
[22]
Besselmann, M. G., Puck, L., Steffen, L., Roennau, A., and Dillmann, R., “VDB-mapping: A high resolution and real-time capable 3d mapping framework for versatile mobile robots,” in 2021 IEEE 17th International Conference on Automation Science and Engineering (CASE) , Aug. 2021, pp. 448–454. DOI: 10 . 1109 / CASE49439.2021.9551430
arXiv 2021
-
[23]
Team, Q., Qwen3 technical report, 2025. DOI: 10.48550/arXiv. 2505.09388
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2025
-
[24]
10, 2023
Jocher, G., Qiu, J., and Chaurasia, A., Ultralytics YOLO , ver- sion 11.0.0, Jan. 10, 2023. [Online]. Available: https : / / github.com/ultralytics/ultralytics
2023
-
[25]
URL https://doi.org/10.1109/CVPR.2017.261
Dai, A., Chang, A. X., Savva, M., Halber, M., Funkhouser, T., and Nießner, M., “ScanNet: Richly-annotated 3d reconstructions of indoor scenes,” in Proc. Computer vision and pattern recognition (CVPR), IEEE , 2017. DOI: 10.1109/CVPR.2017.261
-
[26]
Roucher, A., Moral, A. V . del, Wolf, T., Werra, L. von, and Kau- nismäki, E., ‘smolagents‘: A smol library to build great agentic sys- tems. https://github.com/huggingface/smolagents , 2025
2025
-
[27]
ReAct: Synergizing Reasoning and Acting in Language Models
Y ao, S. et al., React: Synergizing reasoning and acting in language models, 2023. DOI: 10.48550/arXiv.2210.03629
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.03629 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.