Tmax: A simple recipe for terminal agents
Pith reviewed 2026-06-26 08:14 UTC · model grok-4.3
The pith
A simple data-generation taxonomy and outcome-only RL lets 9B models hit 27 percent on terminal benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
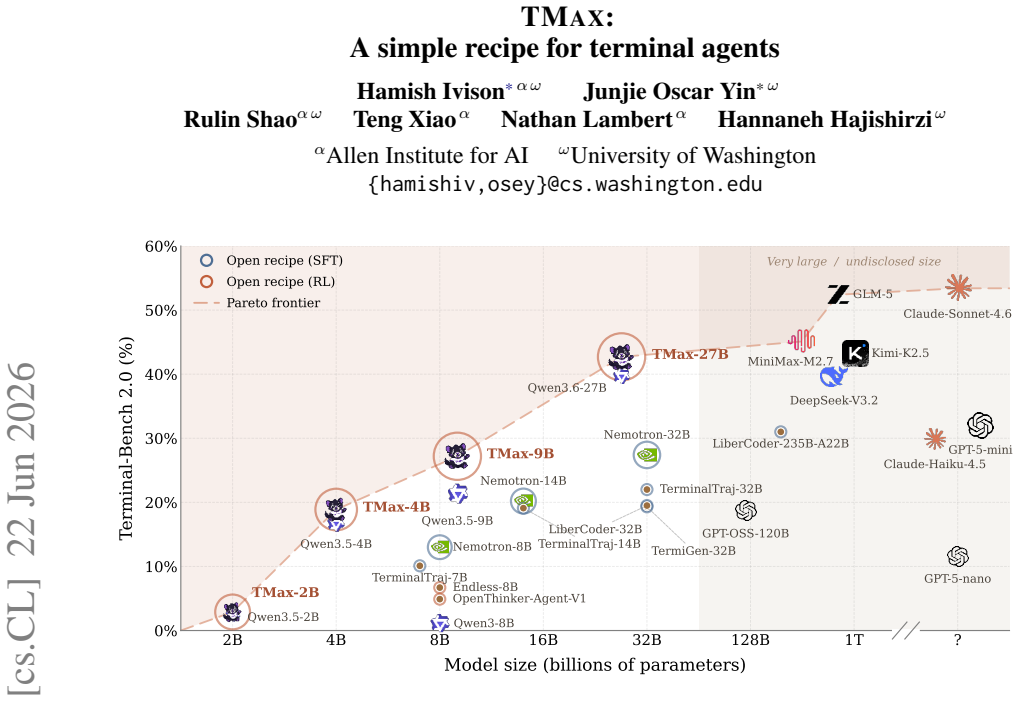
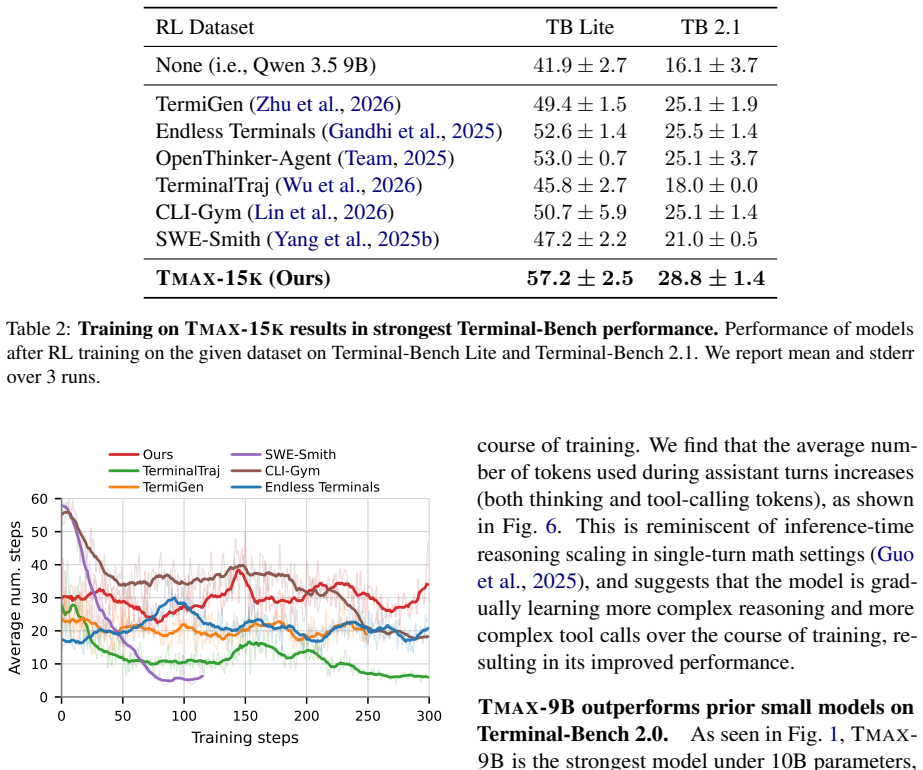
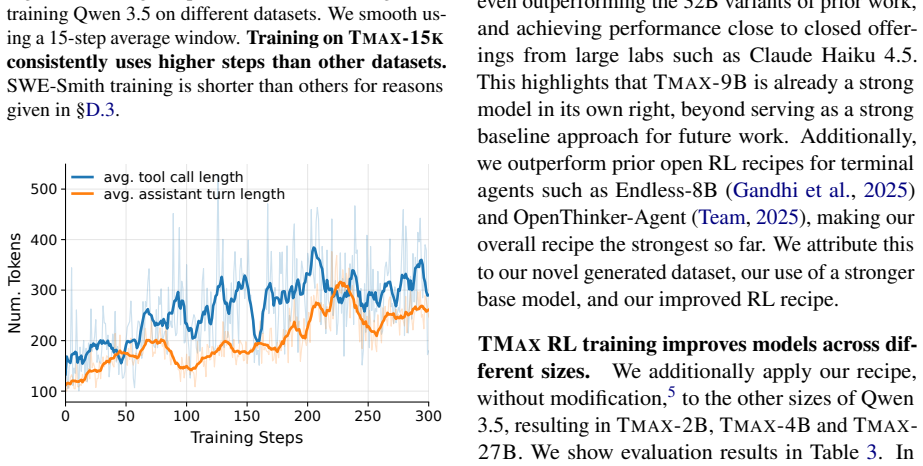
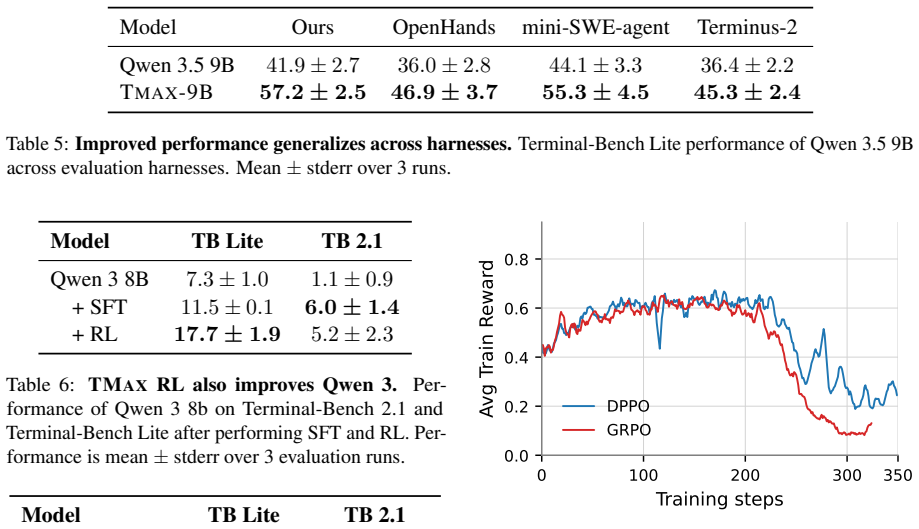
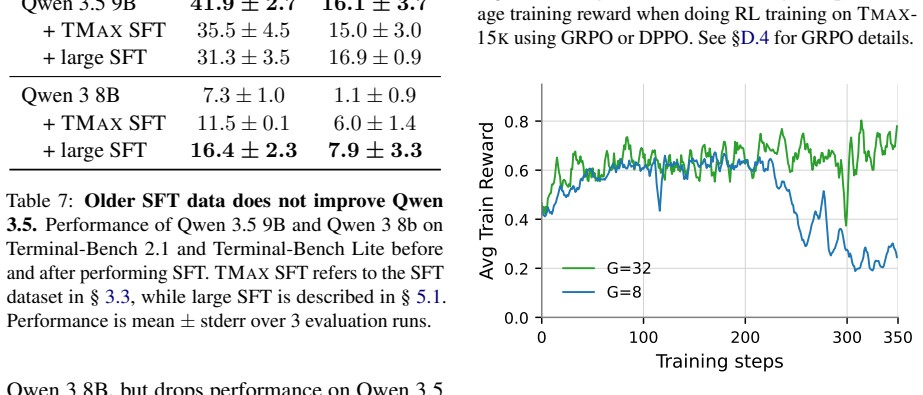
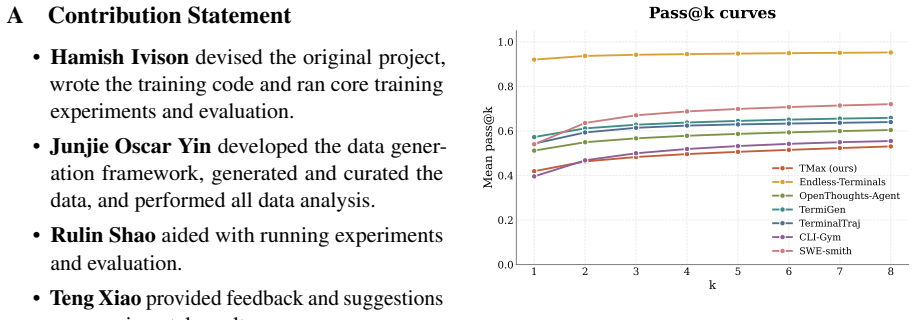
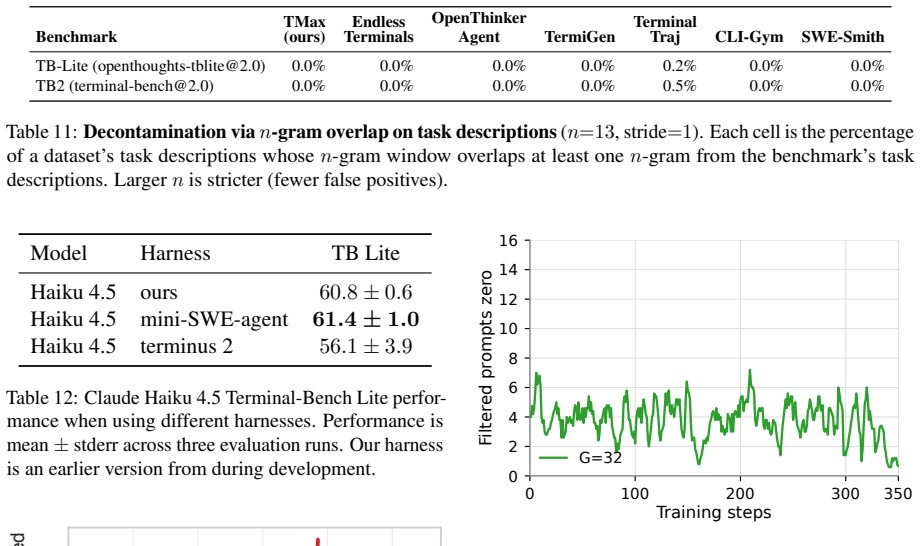
By generating terminal environments through a taxonomy that mixes difficulty control, personas, and verifier diversification, and then training with a simple outcome-only RL procedure on the resulting data, 9B parameter models reach 27 percent success on Terminal-Bench 2.0 and surpass larger models from earlier work.
What carries the argument
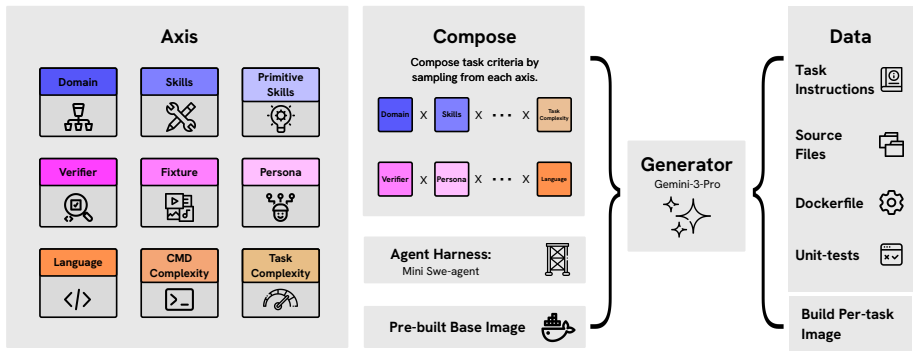
The novel taxonomy that combines difficulty control, personas, and verifier diversification to cheaply produce large volumes of terminal environments for training.
If this is right
- Open-weight 9B models trained this way achieve 27 percent on the benchmark.
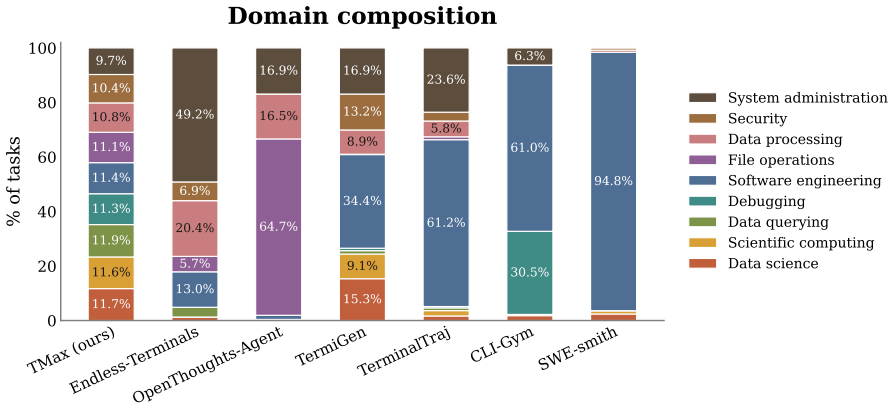
- The released dataset exceeds prior terminal-agent datasets by more than 2.5 times.
- Outcome-only RL on this data produces effective terminal agents without complex reward shaping.
- Releasing the data, models, and code establishes a reproducible baseline for further research.
Where Pith is reading between the lines
- Similar taxonomy-based data generation might improve training for other kinds of agents beyond terminals.
- Outcome-only signals could prove sufficient for many agent tasks if paired with diverse enough environments.
- Scaling up the number of generated environments might push performance higher without increasing model size.
Load-bearing premise
The generated environments from the taxonomy create training signals that transfer effectively to real terminal tasks when used with outcome-only RL.
What would settle it
Training a model with the described data and recipe and then measuring success below the performance of larger prior models on Terminal-Bench 2.0 would falsify the claim.
Figures
read the original abstract
Terminal-using agents have quickly become the most popular downstream application of language models (LMs). Despite their prevalence, relatively little academic work has examined RL-based training of these models, likely due to difficult benchmarks, a lack of data, and a lack of simple baseline recipes. We present Tmax, the strongest open RL recipe for terminal agents to date, bringing open data recipes closer to the frontier. While simple, our recipe achieves 27\% on Terminal-Bench 2.0 with only 9B parameters, outperforming much larger models from prior work. Concretely, we generate data using a novel taxonomy, combining difficulty control, personas, and verifier diversification, which allows us to cheaply generate large amounts of terminal environments for RL and SFT training. We open-source our terminal dataset, which is over 2.5x larger than previously released terminal-agent datasets. We then train open-weight models using RL with our data, using a simple, outcome-only recipe. We release our data, models, and code as a strong baseline for future open academic work on terminal agents at https://github.com/hamishivi/tmax.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Tmax, a simple RL-based recipe for training terminal agents. It proposes a novel taxonomy for generating terminal environments that combines difficulty control, personas, and verifier diversification to efficiently create large amounts of training data for SFT and RL. Using this data with outcome-only RL, the authors train a 9B parameter model that achieves 27% on Terminal-Bench 2.0, outperforming larger models from prior work. The dataset released is over 2.5x larger than previous ones, and the authors open-source the data, models, and code.
Significance. This work provides a strong, reproducible baseline for open research on terminal agents by demonstrating competitive performance with a relatively small model through careful data generation and simple training. The release of extensive artifacts (dataset, models, code) is a notable strength that facilitates verification and further development in the field.
minor comments (2)
- [Abstract] Abstract: the claim of outperforming 'much larger models from prior work' would be strengthened by naming the specific models, their parameter counts, and citations for direct comparison.
- [Abstract] Abstract: no evaluation details (baselines, number of runs, error bars, or verification of comparisons) are supplied, which limits immediate assessment of the 27% result even if these appear in later sections.
Simulated Author's Rebuttal
We thank the referee for their positive summary, significance assessment, and recommendation of minor revision. No major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
The paper presents an empirical recipe: a data-generation taxonomy (difficulty control + personas + verifier diversification) used to create a large terminal-agent dataset, followed by outcome-only RL/SFT training of 9B models that reach 27% on Terminal-Bench 2.0. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the derivation chain. The central claim is a reproducible performance number backed by released artifacts, making the work externally falsifiable rather than internally circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces , author=. arXiv preprint arXiv:2601.11868 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Team, OpenThoughts-Agent , month = Dec, title =
-
[3]
Endless terminals: Scaling rl environments for terminal agents.arXiv preprint arXiv:2601.16443,
Endless Terminals: Scaling RL Environments for Terminal Agents , author=. arXiv preprint arXiv:2601.16443 , year=
-
[4]
NL 2 B ash: A Corpus and Semantic Parser for Natural Language Interface to the Linux Operating System
Lin, Xi Victoria and Wang, Chenglong and Zettlemoyer, Luke and Ernst, Michael D. NL 2 B ash: A Corpus and Semantic Parser for Natural Language Interface to the Linux Operating System. Proceedings of the Eleventh International Conference on Language Resources and Evaluation ( LREC 2018). 2018
2018
-
[5]
DeepSWE: Training a State-of-the-Art Coding Agent from Scratch by Scaling RL , author=
-
[6]
2025 , howpublished =
Anthropic , title =. 2025 , howpublished =
2025
-
[7]
2026 , eprint=
Composer 2 Technical Report , author=. 2026 , eprint=
2026
-
[8]
2026 , eprint=
Computer Environments Elicit General Agentic Intelligence in LLMs , author=. 2026 , eprint=
2026
-
[9]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[10]
2025 , month = nov, howpublished =
Interleaved Thinking Unlocks Reliable. 2025 , month = nov, howpublished =
2025
-
[11]
2025 , eprint=
SWE-smith: Scaling Data for Software Engineering Agents , author=. 2025 , eprint=
2025
-
[12]
2025 , eprint=
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models , author=. 2025 , eprint=
2025
-
[13]
Wang, Junli and Cheng, Zhoujun and Zhang, Yuxuan and Hao, Shibo and Tang, Yao and Hu, Zhiting and Ammanabrolu, Prithviraj and Zhang, Hao , year =
-
[14]
OpenThoughts-Agent team, Snorkel AI, Bespoke Labs , month = Feb, title =
-
[15]
2026 , eprint=
CLI-Gym: Scalable CLI Task Generation via Agentic Environment Inversion , author=. 2026 , eprint=
2026
-
[16]
2025 , eprint=
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention , author=. 2025 , eprint=
2025
-
[17]
2026 , eprint=
Olmo 3 , author=. 2026 , eprint=
2026
-
[18]
2025 , eprint=
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. 2025 , eprint=
2025
-
[19]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[20]
2025 , eprint=
Scaling Synthetic Data Creation with 1,000,000,000 Personas , author=. 2025 , eprint=
2025
-
[21]
2026 , eprint=
Rethinking the Trust Region in LLM Reinforcement Learning , author=. 2026 , eprint=
2026
-
[22]
2025 , eprint=
Tulu 3: Pushing Frontiers in Open Language Model Post-Training , author=. 2025 , eprint=
2025
-
[23]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[24]
LiteCoder: Advancing Small and Medium-sized Code Agents , author=
-
[25]
2026 , month = jan, url =
Qijia Shen and Jay Rainton and Aznaur Aliev and Ahmed Awelkair and Boyuan Ma and Zhiqi (Julie) Huang and Yuzhen Mao and Wendong Fan and Philip Torr and Bernard Ghanem and Changran Hu and Urmish Thakker and Guohao Li , title =. 2026 , month = jan, url =
2026
-
[26]
2026 , eprint=
SERA: Soft-Verified Efficient Repository Agents , author=. 2026 , eprint=
2026
-
[27]
2026 , eprint=
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem , author=. 2026 , eprint=
2026
-
[28]
2024 , eprint=
Training Software Engineering Agents and Verifiers with SWE-Gym , author=. 2024 , eprint=
2024
-
[29]
Advances in Neural Information Processing Systems , volume=
Language Models are Few-Shot Learners , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
2023 , eprint=
Hugo Touvron and Thibaut Lavril and Gautier Izacard and Xavier Martinet and Marie-Anne Lachaux and Timoth. 2023 , eprint=
2023
-
[31]
2025 , eprint=
SWE-rebench: An Automated Pipeline for Task Collection and Decontaminated Evaluation of Software Engineering Agents , author=. 2025 , eprint=
2025
-
[32]
arXiv preprint arXiv:2602.21193 , year=
On Data Engineering for Scaling LLM Terminal Capabilities , author=. arXiv preprint arXiv:2602.21193 , year=
-
[33]
TermiGen: High-Fidelity Environment and Robust Trajectory Synthesis for Terminal Agents , author=. arXiv preprint arXiv:2602.07274 , year=
-
[34]
arXiv preprint arXiv:2602.01244 , year=
Large-Scale Terminal Agentic Trajectory Generation from Dockerized Environments , author=. arXiv preprint arXiv:2602.01244 , year=
-
[35]
Mountain View, CA: Google)
A new era of intelligence with Gemini 3 , author=. Mountain View, CA: Google). Available online at: https://blog. google/products-andplatforms/products/gemini/gemini-3/(Accessed February 1, 2026) , year=
2026
-
[36]
2026 , eprint=
SWE-Universe: Scale Real-World Verifiable Environments to Millions , author=. 2026 , eprint=
2026
-
[37]
2024 , url=
Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan , booktitle=. 2024 , url=
2024
-
[38]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms , author=. arXiv preprint arXiv:2501.12599 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Advances in Neural Information Processing Systems , volume=
Swe-agent: Agent-computer interfaces enable automated software engineering , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
A Report on the First Native Language Identification Shared Task
Tetreault, Joel and Blanchard, Daniel and Cahill, Aoife. A Report on the First Native Language Identification Shared Task. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[41]
Applying Unsupervised Learning To Support Vector Space Model Based Speaking Assessment
Chen, Lei. Applying Unsupervised Learning To Support Vector Space Model Based Speaking Assessment. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[42]
Role of Morpho-Syntactic Features in E stonian Proficiency Classification
Vajjala, Sowmya and L \ o o, Kaidi. Role of Morpho-Syntactic Features in E stonian Proficiency Classification. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[43]
Automated Content Scoring of Spoken Responses in an Assessment for Teachers of E nglish
Zechner, Klaus and Wang, Xinhao. Automated Content Scoring of Spoken Responses in an Assessment for Teachers of E nglish. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[44]
Experimental Results on the Native Language Identification Shared Task
Abu-Jbara, Amjad and Jha, Rahul and Morley, Eric and Radev, Dragomir. Experimental Results on the Native Language Identification Shared Task. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[45]
VTEX System Description for the NLI 2013 Shared Task
Daudaravi c ius, Vidas. VTEX System Description for the NLI 2013 Shared Task. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[46]
Feature Space Selection and Combination for Native Language Identification
Goutte, Cyril and L \'e ger, Serge and Carpuat, Marine. Feature Space Selection and Combination for Native Language Identification. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[47]
Discriminating Non-Native E nglish with 350 Words
Henderson, John and Zarrella, Guido and Pfeifer, Craig and Burger, John D. Discriminating Non-Native E nglish with 350 Words. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[48]
Maximizing Classification Accuracy in Native Language Identification
Jarvis, Scott and Bestgen, Yves and Pepper, Steve. Maximizing Classification Accuracy in Native Language Identification. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[49]
Recognizing E nglish Learners' Native Language from Their Writings
Li, Baoli. Recognizing E nglish Learners' Native Language from Their Writings. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[50]
NLI Shared Task 2013: MQ Submission
Malmasi, Shervin and Wong, Sze-Meng Jojo and Dras, Mark. NLI Shared Task 2013: MQ Submission. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[51]
NAIST at the NLI 2013 Shared Task
Mizumoto, Tomoya and Hayashibe, Yuta and Sakaguchi, Keisuke and Komachi, Mamoru and Matsumoto, Yuji. NAIST at the NLI 2013 Shared Task. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[52]
Cognate and Misspelling Features for Natural Language Identification
Nicolai, Garrett and Hauer, Bradley and Salameh, Mohammad and Yao, Lei and Kondrak, Grzegorz. Cognate and Misspelling Features for Natural Language Identification. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[53]
Exploring Syntactic Representations for Native Language Identification
Swanson, Ben. Exploring Syntactic Representations for Native Language Identification. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[54]
Simple Yet Powerful Native Language Identification on TOEFL 11
Wu, Ching-Yi and Lai, Po-Hsiang and Liu, Yang and Ng, Vincent. Simple Yet Powerful Native Language Identification on TOEFL 11. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[55]
Prompt-based Content Scoring for Automated Spoken Language Assessment
Evanini, Keelan and Xie, Shasha and Zechner, Klaus. Prompt-based Content Scoring for Automated Spoken Language Assessment. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[56]
Automated Scoring of a Summary-Writing Task Designed to Measure Reading Comprehension
Madnani, Nitin and Burstein, Jill and Sabatini, John and O ' Reilly, Tenaha. Automated Scoring of a Summary-Writing Task Designed to Measure Reading Comprehension. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[57]
Inter-annotator Agreement for Dependency Annotation of Learner Language
Ragheb, Marwa and Dickinson, Markus. Inter-annotator Agreement for Dependency Annotation of Learner Language. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[58]
Native Language Identification with PPM
Bobicev, Victoria. Native Language Identification with PPM. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[59]
Using Other Learner Corpora in the 2013 NLI Shared Task
Brooke, Julian and Hirst, Graeme. Using Other Learner Corpora in the 2013 NLI Shared Task. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[60]
Combining Shallow and Linguistically Motivated Features in Native Language Identification
Bykh, Serhiy and Vajjala, Sowmya and Krivanek, Julia and Meurers, Detmar. Combining Shallow and Linguistically Motivated Features in Native Language Identification. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[61]
Linguistic Profiling based on General -- purpose Features and Native Language Identification
Cimino, Andrea and Dell ' Orletta, Felice and Venturi, Giulia and Montemagni, Simonetta. Linguistic Profiling based on General -- purpose Features and Native Language Identification. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[62]
Improving Native Language Identification with TF - IDF Weighting
Gebre, Binyam Gebrekidan and Zampieri, Marcos and Wittenburg, Peter and Heskes, Tom. Improving Native Language Identification with TF - IDF Weighting. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[63]
Native Language Identification: a Simple n-gram Based Approach
Gyawali, Binod and Ramirez, Gabriela and Solorio, Thamar. Native Language Identification: a Simple n-gram Based Approach. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[64]
Feature Engineering in the NLI Shared Task 2013: C harles U niversity Submission Report
Hladk \'a , Barbora and Holub, Martin and Kr \'i z , Vincent. Feature Engineering in the NLI Shared Task 2013: C harles U niversity Submission Report. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[65]
Native Language Identification: A Key N-gram Category Approach
Kyle, Kristopher and Crossley, Scott and Dai, Jianmin and McNamara, Danielle S. Native Language Identification: A Key N-gram Category Approach. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[66]
Using N-gram and Word Network Features for Native Language Identification
Lahiri, Shibamouli and Mihalcea, Rada. Using N-gram and Word Network Features for Native Language Identification. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[67]
LIMSI ' s participation to the 2013 shared task on Native Language Identification
Lavergne, Thomas and Illouz, Gabriel and Max, Aur \'e lien and Nagata, Ryo. LIMSI ' s participation to the 2013 shared task on Native Language Identification. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[68]
Native Language Identification using large scale lexical features
Lynum, Andr \'e. Native Language Identification using large scale lexical features. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[69]
The Story of the Characters, the DNA and the Native Language
Popescu, Marius and Ionescu, Radu Tudor. The Story of the Characters, the DNA and the Native Language. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[70]
Identifying the L 1 of non-native writers: the CMU -Haifa system
Tsvetkov, Yulia and Twitto, Naama and Schneider, Nathan and Ordan, Noam and Faruqui, Manaal and Chahuneau, Victor and Wintner, Shuly and Dyer, Chris. Identifying the L 1 of non-native writers: the CMU -Haifa system. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[71]
Evaluating Unsupervised Language Model Adaptation Methods for Speaking Assessment
Xie, Shasha and Chen, Lei. Evaluating Unsupervised Language Model Adaptation Methods for Speaking Assessment. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[72]
Improving interpretation robustness in a tutorial dialogue system
Dzikovska, Myroslava and Farrow, Elaine and Moore, Johanna. Improving interpretation robustness in a tutorial dialogue system. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[73]
Detecting Missing Hyphens in Learner Text
Cahill, Aoife and Chodorow, Martin and Wolff, Susanne and Madnani, Nitin. Detecting Missing Hyphens in Learner Text. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[74]
Applying Machine Translation Metrics to Student-Written Translations
Michaud, Lisa and McCoy, Patricia Ann. Applying Machine Translation Metrics to Student-Written Translations. Proceedings of the Eighth Workshop on Innovative Use of NLP for Building Educational Applications. 2013
2013
-
[75]
Proceedings of the 4th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis. 2013
2013
-
[76]
Recent adventures with emotion-reading technology
Picard, Rosalind. Recent adventures with emotion-reading technology. Proceedings of the 4th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis. 2013
2013
-
[77]
Bootstrapped Learning of Emotion Hashtags \# hashtags4you
Qadir, Ashequl and Riloff, Ellen. Bootstrapped Learning of Emotion Hashtags \# hashtags4you. Proceedings of the 4th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis. 2013
2013
-
[78]
Fine-Grained Emotion Recognition in Olympic Tweets Based on Human Computation
Sintsova, Valentina and Musat, Claudiu and Pu, Pearl. Fine-Grained Emotion Recognition in Olympic Tweets Based on Human Computation. Proceedings of the 4th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis. 2013
2013
-
[79]
S panish DAL : A S panish Dictionary of Affect in Language
Dell ' Amerlina R \'i os, Mat \'i as and Gravano, Agust \'i n. S panish DAL : A S panish Dictionary of Affect in Language. Proceedings of the 4th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis. 2013
2013
-
[80]
The perfect solution for detecting sarcasm in tweets \# not
Liebrecht, Christine and Kunneman, Florian and van den Bosch, Antal. The perfect solution for detecting sarcasm in tweets \# not. Proceedings of the 4th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis. 2013
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.