Sat2City v2: Native 3D City Asset Generation from a Single Satellite Image
Pith reviewed 2026-06-26 01:42 UTC · model grok-4.3
The pith
Sat2City v2 generates reusable textured 3D city meshes from a single satellite image by adapting a pretrained structured-latent 3D foundation model to real data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By encoding each mesh into a pretrained native 3D latent space, fine-tuning a satellite-conditioned geometry flow, and using the decoded shape to anchor satellite-conditioned texturing, Sat2City v2 produces reusable textured mesh assets from weakly aligned satellite images on a real-world dataset, advancing satellite-to-city generation from rendering-oriented proxies to explicit assets.
What carries the argument
Encoding city meshes into a pretrained native structured-latent 3D foundation model and conditioning geometry flow plus texturing on satellite inputs.
If this is right
- Enables generation of metric-scale DSM reconstructions with improved geometry fidelity.
- Produces city assets whose appearance remains controllable from the satellite input.
- Yields explicit textured meshes suitable for downstream simulation and geospatial tasks.
- Supplies the first documented large satellite-mesh paired dataset collected from matched geographic crops.
Where Pith is reading between the lines
- The latent-space adaptation may allow similar 3D asset generation pipelines to incorporate new real-world imagery without full retraining.
- The paired dataset could support future work on multi-view consistency or temporal updates to city models.
- Controllability from satellite data might extend to editing generated assets when new imagery arrives.
Load-bearing premise
The pretrained native structured-latent 3D foundation model provides a latent space that can be effectively adapted to weakly aligned real-world satellite images and noisy city meshes without major domain gaps or loss of controllability.
What would settle it
Generated meshes from held-out real satellite images show large metric-scale misalignment with ground-truth DSM or produce inconsistent textures when rendered from novel viewpoints.
Figures


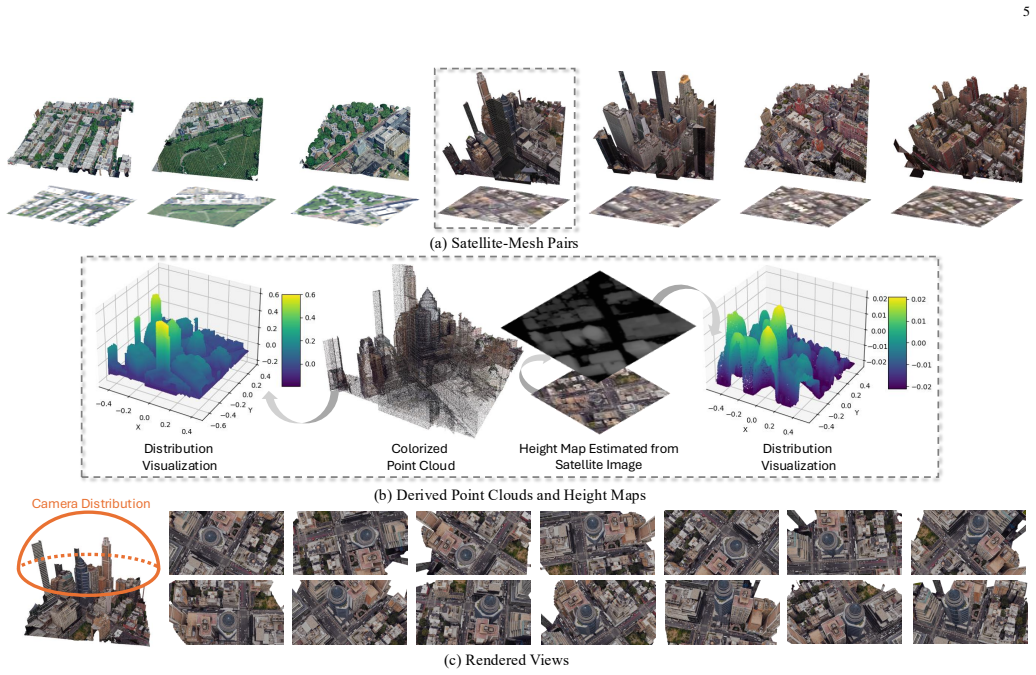
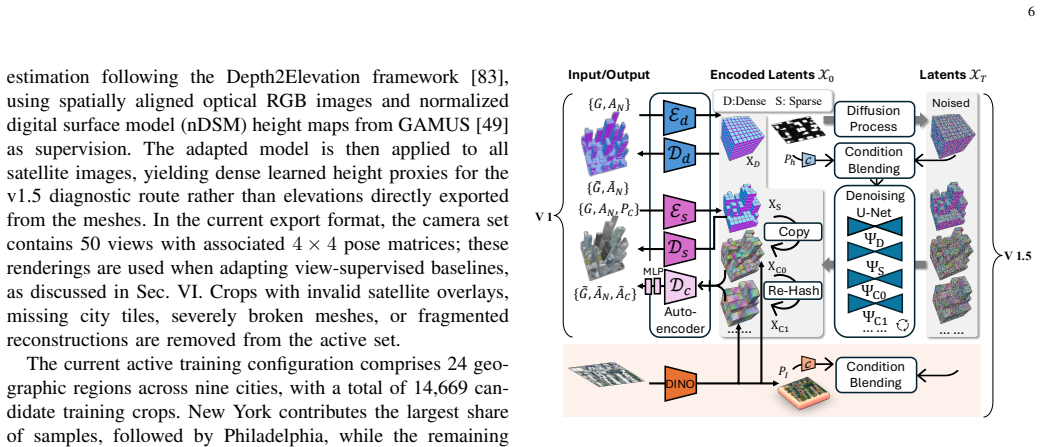





read the original abstract
Generating explicit 3D city assets from a single satellite image is important for digital twins, urban simulation, and geospatial intelligence. Unlike satellite-to-street-view synthesis, the task requires a reusable textured mesh with plausible geometry and controllable appearance rather than a 3D proxy optimized only for rendering a small set of images or videos. The ICCV Sat2City framework made a first step by conditioning cascaded sparse-voxel latent diffusion on satellite-derived height maps, but its appearance was random, its training data were synthetic, and its task-specific VAE did not scale well to noisy real-world reconstructions. We present Sat2City v2, a journal extension that adapts a pretrained native structured-latent 3D foundation model to weakly aligned satellite images and textured meshes. We build a real-world dataset with 16,241 satellite-mesh pairs across 24 regions in 9 cities. Instead of learning a 3D representation from noisy city meshes, Sat2City v2 encodes each mesh into a pretrained native 3D latent space, fine-tunes a satellite-conditioned geometry flow, and uses the decoded shape to anchor satellite-conditioned texturing. This retains Sat2City's geometry-to-appearance cascade while enabling appearance-controllable generation from the satellite input. Experiments on metric-scale DSM reconstruction and generative city-asset benchmarks for geometry and appearance show that Sat2City v2 achieves the best overall performance among evaluated baselines. Overall, Sat2City v2 advances satellite-to-city generation from rendering-oriented 3D proxies to explicit textured mesh assets, supported by, to the best of our knowledge, the first documented satellite-mesh paired dataset collected from matched geographic crops for this asset-level task. Project page: https://ai4city-hkust.github.io/Sat2City-v2/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Sat2City v2 as a journal extension of the prior ICCV Sat2City work for generating explicit, reusable textured 3D city meshes from a single satellite image. It adapts a pretrained native structured-latent 3D foundation model via fine-tuning of a satellite-conditioned geometry flow and anchored texturing, introduces a new real-world dataset of 16,241 satellite-mesh pairs across 24 regions in 9 cities, and claims superior performance over baselines on metric-scale DSM reconstruction and generative city-asset benchmarks for both geometry and appearance.
Significance. If the empirical claims hold, the work advances the field from rendering-oriented 3D proxies toward controllable explicit mesh assets suitable for digital twins and urban simulation. The explicit contribution of the first documented satellite-mesh paired dataset collected from matched geographic crops is a clear strength that can support future research. The incremental engineering approach of leveraging and adapting an external pretrained foundation model is appropriately scoped and avoids circularity.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: the central claim that Sat2City v2 'achieves the best overall performance among evaluated baselines' is unsupported by any quantitative metrics, baseline names, error analysis, or statistical tests in the manuscript, which is load-bearing for the empirical contribution.
- [Dataset] Dataset construction paragraph: no details are supplied on how the 16,241 satellite-mesh pairs were collected, geographically aligned, or quality-controlled, preventing assessment of whether the real-world data actually closes the domain gap assumed in the method.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance. We address each major comment below and will revise the manuscript to strengthen the empirical support and dataset description.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the central claim that Sat2City v2 'achieves the best overall performance among evaluated baselines' is unsupported by any quantitative metrics, baseline names, error analysis, or statistical tests in the manuscript, which is load-bearing for the empirical contribution.
Authors: We acknowledge the need for explicit support of this claim. The Experiments section includes quantitative results on metric-scale DSM reconstruction and generative city-asset benchmarks, with comparisons to baselines using metrics for both geometry and appearance. To address the concern directly, we will revise the abstract to reference key quantitative outcomes and expand the Experiments section to explicitly name all baselines, include detailed error analysis, and report any statistical tests performed. This revision will make the empirical contribution fully transparent. revision: yes
-
Referee: [Dataset] Dataset construction paragraph: no details are supplied on how the 16,241 satellite-mesh pairs were collected, geographically aligned, or quality-controlled, preventing assessment of whether the real-world data actually closes the domain gap assumed in the method.
Authors: We agree that additional details are required for reproducibility and to evaluate the domain gap. In the revised manuscript, we will expand the dataset description to specify the data sources (e.g., public satellite imagery providers and mesh reconstruction pipelines), the geographic alignment procedure using coordinate matching from matched crops, and the quality control steps including automated alignment verification and manual review for mesh fidelity and texture consistency. This will directly support assessment of the real-world data's role in the method. revision: yes
Circularity Check
No significant circularity; derivation relies on external pretrained model and new dataset
full rationale
The paper's method adapts an external pretrained structured-latent 3D foundation model via fine-tuning of a geometry flow and anchored texturing on a newly collected 16k-pair satellite-mesh dataset. No derivation step reduces a claimed prediction or result to a fitted parameter or self-citation by construction. The central claims are empirical benchmark comparisons on DSM reconstruction and generative city-asset tasks, which are supported by the external model and independent data collection rather than internal redefinitions or self-referential uniqueness theorems. This matches the default expectation of a non-circular engineering paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained native structured-latent 3D foundation models encode city geometry in a way that supports fine-tuning from weakly aligned satellite inputs.
Reference graph
Works this paper leans on
-
[1]
Sat2scene: 3d urban scene generation from satellite images with diffusion,
Z. Li, Z. Li, Z. Cui, M. Pollefeys, and M. R. Oswald, “Sat2scene: 3d urban scene generation from satellite images with diffusion,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 7141–7150
2024
-
[2]
Infinicity: Infinite-scale city synthesis,
C. H. Lin, H.-Y . Lee, W. Menapace, M. Chai, A. Siarohin, M.-H. Yang, and S. Tulyakov, “Infinicity: Infinite-scale city synthesis,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 22 808–22 818
2023
-
[3]
Citydreamer: Compositional generative model of unbounded 3d cities,
H. Xie, Z. Chen, F. Hong, and Z. Liu, “Citydreamer: Compositional generative model of unbounded 3d cities,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 9666–9675
2024
-
[4]
Gaussiancity: Generative gaussian splatting for unbounded 3d city generation,
H. Xie, Z. Chen, F. Hong, and Z. Liu, “Gaussiancity: Generative gaussian splatting for unbounded 3d city generation,”arXiv preprint arXiv:2406.06526, 2024
arXiv 2024
-
[5]
Generative gaussian splatting for unbounded 3d city generation,
H. Xie, Z. Chen, F. Hong, and Z. Liu, “Generative gaussian splatting for unbounded 3d city generation,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 6111–6120
2025
-
[6]
Sketch2scene: Automatic generation of interactive 3d game scenes from user’s casual sketches,
Y . Xu, Y . Ng, Y . Wang, I. Sa, Y . Duan, Y . Li, P. Ji, and H. Li, “Sketch2scene: Automatic generation of interactive 3d game scenes from user’s casual sketches,”arXiv preprint arXiv:2408.04567, 2024
arXiv 2024
-
[7]
Urban architect: Steerable 3d urban scene generation with layout prior,
F. Lu, K.-Y . Lin, Y . Xu, H. Li, G. Chen, and C. Jiang, “Urban architect: Steerable 3d urban scene generation with layout prior,”arXiv preprint arXiv:2404.06780, 2024
arXiv 2024
-
[8]
Procedural generation of 3d scenes for urban landscape based on remote sensing images,
S. Yang, H. Yuan, T. Wang, R. Zhong, C. Song, Y . Fu, W. Ge, and X. Yuan, “Procedural generation of 3d scenes for urban landscape based on remote sensing images,” in2024 IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS). IEEE, 2024, pp. 1–7
2024
-
[9]
Y . Lu, X. Ren, J. Yang, T. Shen, Z. Wu, J. Gao, Y . Wang, S. Chen, M. Chen, S. Fidleret al., “Infinicube: Unbounded and controllable dynamic 3d driving scene generation with world-guided video models,” arXiv preprint arXiv:2412.03934, 2024
arXiv 2024
-
[10]
Capturing, reconstructing, and simulating: The urbanscene3d dataset,
L. Lin, Y . Liu, Y . Hu, X. Yan, K. Xie, and H. Huang, “Capturing, reconstructing, and simulating: The urbanscene3d dataset,” inEuropean Conference on Computer Vision, 2022
2022
-
[11]
Urban- world: An urban world model for 3d city generation,
Y . Shang, J. Chen, H. Fan, J. Ding, J. Feng, and Y . Li, “Urban- world: An urban world model for 3d city generation,”arXiv preprint arXiv:2407.11965, 2024. 14
arXiv 2024
-
[12]
Cityx: Controllable procedural content generation for unbounded 3d cities,
S. Zhang, M. Zhou, Y . Wang, C. Luo, R. Wang, Y . Li, X. Yin, Z. Zhang, and J. Peng, “Cityx: Controllable procedural content generation for unbounded 3d cities,”arXiv preprint arXiv:2407.17572, 2024
arXiv 2024
-
[13]
Sat2vid: Street-view panoramic video synthesis from a single satellite image,
Z. Li, Z. Li, Z. Cui, R. Qin, M. Pollefeys, and M. R. Oswald, “Sat2vid: Street-view panoramic video synthesis from a single satellite image,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 12 436–12 445
2021
-
[14]
Geometry-aware satellite-to-ground image synthesis for urban areas,
X. Lu, Z. Li, Z. Cui, M. R. Oswald, M. Pollefeys, and R. Qin, “Geometry-aware satellite-to-ground image synthesis for urban areas,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 859–867
2020
-
[16]
Geometry-guided street- view panorama synthesis from satellite imagery,
Y . Shi, D. Campbell, X. Yu, and H. Li, “Geometry-guided street- view panorama synthesis from satellite imagery,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 12, pp. 10 009–10 022, 2022
2022
-
[17]
Geospecific view generation – geometry-context aware high-resolution ground view inference from satellite views,
N. Xu and R. Qin, “Geospecific view generation – geometry-context aware high-resolution ground view inference from satellite views,”
-
[18]
Available: https://arxiv.org/abs/2407.08061
[Online]. Available: https://arxiv.org/abs/2407.08061
-
[19]
Crossviewdiff: A cross-view diffusion model for satellite-to- street view synthesis,
W. Li, J. He, J. Ye, H. Zhong, Z. Zheng, Z. Huang, D. Lin, and C. He, “Crossviewdiff: A cross-view diffusion model for satellite-to- street view synthesis,”arXiv preprint arXiv:2408.14765, 2024
arXiv 2024
-
[20]
Streetscapes: Large-scale consistent street view generation using au- toregressive video diffusion,
B. Deng, R. Tucker, Z. Li, L. Guibas, N. Snavely, and G. Wetzstein, “Streetscapes: Large-scale consistent street view generation using au- toregressive video diffusion,” inACM SIGGRAPH 2024 Conference Papers, 2024, pp. 1–11
2024
-
[21]
Ur- bangiraffe: Representing urban scenes as compositional generative neural feature fields,
Y . Yang, Y . Yang, H. Guo, R. Xiong, Y . Wang, and Y . Liao, “Ur- bangiraffe: Representing urban scenes as compositional generative neural feature fields,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 9199–9210
2023
-
[22]
Syn- theocc: Synthesize geometric-controlled street view images through 3d semantic mpis,
L. Li, W. Qiu, Y . Cai, X. Yan, Q. Lian, B. Liu, and Y .-C. Chen, “Syn- theocc: Synthesize geometric-controlled street view images through 3d semantic mpis,”arXiv preprint arXiv:2410.00337, 2024
arXiv 2024
-
[23]
Sat2density: Faithful density learning from satellite-ground image pairs,
M. Qian, J. Xiong, G.-S. Xia, and N. Xue, “Sat2density: Faithful density learning from satellite-ground image pairs,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3683–3692
2023
-
[24]
Seeing through satellite images at street views,
M. Qian, B. Tan, Q. Wang, X. Zheng, H. Xiong, G.-S. Xia, Y . Shen, and N. Xue, “Seeing through satellite images at street views,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[25]
Sat3dgen: Comprehensive street-level 3d scene gen- eration from single satellite image,
M. Qian, Z. Xia, C. Liu, S. Ma, W. Wang, Z. Ke, B. Tan, H. Zhang, and G.-S. Xia, “Sat3dgen: Comprehensive street-level 3d scene gen- eration from single satellite image,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[26]
Sat2city: 3d city gener- ation from a single satellite image with cascaded latent diffusion,
T. Hua, L. Jiang, Y .-C. Chen, and W. Zhao, “Sat2city: 3d city gener- ation from a single satellite image with cascaded latent diffusion,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2025, pp. 27 978–27 988
2025
-
[27]
Wide-area image geolo- calization with aerial reference imagery,
S. Workman, R. Souvenir, and N. Jacobs, “Wide-area image geolo- calization with aerial reference imagery,” inProceedings of the IEEE International Conference on Computer Vision, 2015, pp. 3961–3969
2015
-
[28]
Lending orientation to neural networks for cross- view geo-localization,
L. Liu and H. Li, “Lending orientation to neural networks for cross- view geo-localization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 5624–5633
2019
-
[29]
Vigor: Cross-view image geo- localization beyond one-to-one retrieval,
S. Zhu, T. Yang, and C. Chen, “Vigor: Cross-view image geo- localization beyond one-to-one retrieval,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2021, pp. 3640–3649
2021
-
[30]
Google earth,
Google, “Google earth,” 2026, accessed: 2026-05-28. [Online]. Available: https://earth.google.com/
2026
-
[31]
Xcube: Large-scale 3d generative modeling using sparse voxel hier- archies,
X. Ren, J. Huang, X. Zeng, K. Museth, S. Fidler, and F. Williams, “Xcube: Large-scale 3d generative modeling using sparse voxel hier- archies,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 4209–4219
2024
-
[32]
Scube: Instant large-scale scene recon- struction using voxsplats,
X. Ren, Y . Lu, H. Liang, Z. Wu, H. Ling, M. Chen, S. Fidler, F. Williams, and J. Huang, “Scube: Instant large-scale scene recon- struction using voxsplats,”arXiv preprint arXiv:2410.20030, 2024
arXiv 2024
-
[33]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, F. Massa, D. Haziza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sen- tana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Couprie, J. Mairal, H. J ´egou, P. Labatut, and P. Bojanowski, “DINOv3,”arXiv preprint arXiv:2508.1...
Pith/arXiv arXiv 2025
-
[34]
Native and compact structured latents for 3d generation,
J. Xiang, X. Chen, S. Xu, R. Wang, Z. Lv, Y . Deng, H. Zhu, Y . Dong, H. Zhao, N. J. Yuan, and J. Yang, “Native and compact structured latents for 3d generation,”arXiv preprint arXiv:2512.14692, 2025
Pith/arXiv arXiv 2025
-
[35]
3d gaussian splatting for real-time radiance field rendering
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering.”ACM Trans. Graph., vol. 42, no. 4, pp. 139–1, 2023
2023
-
[36]
Earthcrafter: Scalable 3d earth generation via dual-sparse latent diffusion,
S. Liu, C. Cao, C. Yu, W. Qian, J. Wang, and F. Wang, “Earthcrafter: Scalable 3d earth generation via dual-sparse latent diffusion,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 9, 2026, pp. 7260–7268
2026
-
[37]
ABot-Earth 0.5: Generative 3d earth model,
M. Qian, T. Ouyang, M. Sun, Z. Wang, J. Xiong, J. Han, Y . Zhang, J. Zhang, X. Wang, Y . Liu, L. Tang, F. Yu, Z. Ge, M. Du, Y . Liu, N. Fan, S. Wang, Y . Peng, C. Jia, Y . Liu, S. Zeng, H. Shi, J. Lai, H. Pan, Z. Wu, N. Guo, M. Xu, and H. Zhang, “ABot-Earth 0.5: Generative 3d earth model,”arXiv preprint arXiv:2606.09967, 2026
Pith/arXiv arXiv 2026
-
[38]
Y . Kang, X. Wang, Z. Wu, Y . Shi, and H. Zhu, “Sat2realcity: Geometry- aware and appearance-controllable 3d urban generation from satellite imagery,”arXiv preprint arXiv:2511.11470, 2025
arXiv 2025
-
[39]
Persistent nature: A generative model of unbounded 3d worlds,
L. Chai, R. Tucker, Z. Li, P. Isola, and N. Snavely, “Persistent nature: A generative model of unbounded 3d worlds,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 20 863–20 874
2023
-
[40]
Scenedreamer: Unbounded 3d scene generation from 2d image collections,
Z. Chen, G. Wang, and Z. Liu, “Scenedreamer: Unbounded 3d scene generation from 2d image collections,”IEEE transactions on pattern analysis and machine intelligence, 2023
2023
-
[41]
Scenescape: Text- driven consistent scene generation,
R. Fridman, A. Abecasis, Y . Kasten, and T. Dekel, “Scenescape: Text- driven consistent scene generation,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[42]
Gancraft: Unsuper- vised 3d neural rendering of minecraft worlds,
Z. Hao, A. Mallya, S. Belongie, and M.-Y . Liu, “Gancraft: Unsuper- vised 3d neural rendering of minecraft worlds,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 14 072–14 082
2021
-
[43]
Scene123: One prompt to 3d scene generation via video-assisted and consistency- enhanced mae,
Y . Yang, F. Yin, J. Fan, X. Chen, W. Li, and G. Yu, “Scene123: One prompt to 3d scene generation via video-assisted and consistency- enhanced mae,”arXiv preprint arXiv:2408.05477, 2024
arXiv 2024
-
[44]
3d-scenedreamer: Text-driven 3d-consistent scene generation,
S. Zhang, Y . Zhang, Q. Zheng, R. Ma, W. Hua, H. Bao, W. Xu, and C. Zou, “3d-scenedreamer: Text-driven 3d-consistent scene generation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 10 170–10 180
2024
-
[45]
Extend3d: Town-scale 3d generation,
S. Yoon, J. Kim, and J. Park, “Extend3d: Town-scale 3d generation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026, pp. 5892–5901
2026
-
[46]
2019 ieee grss data fusion contest: Large-scale semantic 3d reconstruction,
B. Le Saux, N. Yokoya, R. H ¨ansch, and M. Brown, “2019 ieee grss data fusion contest: Large-scale semantic 3d reconstruction,”IEEE Geoscience and Remote Sensing Magazine, 2019
2019
-
[47]
Urbanbis: A large-scale benchmark for fine-grained urban building instance segmentation,
G. Yang, F. Xue, Q. Zhang, K. Xie, C.-W. Fu, and H. Huang, “Urbanbis: A large-scale benchmark for fine-grained urban building instance segmentation,”ACM Transactions on Graphics, vol. 42, no. 4, 2023
2023
-
[48]
Holicity: A city-scale data platform for learning holistic 3d structures,
Y . Zhou, J. Huang, X. Dai, L. Luo, Z. Chen, and Y . Ma, “Holicity: A city-scale data platform for learning holistic 3d structures,”arXiv preprint arXiv:2008.03286, 2020
arXiv 2008
-
[49]
Omnicity: Omnipotent city understanding with multi-level and multi-view images,
W. Li, Y . Lai, L. Xu, Y . Xiangli, J. Yu, C. He, G.-S. Xia, and D. Lin, “Omnicity: Omnipotent city understanding with multi-level and multi-view images,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 17 397–17 407
2023
-
[50]
Gamus: A geometry-aware multi-modal semantic segmentation benchmark for remote sensing data,
Z. Xiong, S. Chen, Y . Wang, L. Mou, and X. X. Zhu, “Gamus: A geometry-aware multi-modal semantic segmentation benchmark for remote sensing data,”arXiv preprint arXiv:2305.14914, 2023
arXiv 2023
-
[51]
Nuiscene: Exploring efficient generation of unbounded outdoor scenes,
H.-H. Lee, Q. Han, and A. X. Chang, “Nuiscene: Exploring efficient generation of unbounded outdoor scenes,”arXiv:2503.16375, 2025
arXiv 2025
-
[52]
Syncity: Training-free generation of 3d worlds,
P. Engstler, A. Shtedritski, I. Laina, C. Rupprecht, and A. Vedaldi, “Syncity: Training-free generation of 3d worlds,”arXiv:2503.16420, 2025
arXiv 2025
-
[53]
Dreamfusion: Text- to-3d using 2d diffusion,
B. Poole, A. Jain, J. T. Barron, and B. Mildenhall, “Dreamfusion: Text- to-3d using 2d diffusion,”arXiv preprint arXiv:2209.14988, 2022
Pith/arXiv arXiv 2022
-
[54]
Componerf: Text-guided multi-object compositional nerf with editable 3d scene layout,
H. Bai, Y . Lyu, L. Jiang, S. Li, H. Lu, X. Lin, and L. Wang, “Componerf: Text-guided multi-object compositional nerf with editable 3d scene layout,”arXiv preprint arXiv:2303.13843, 2023
arXiv 2023
-
[55]
X. Zhou, X. Ran, Y . Xiong, J. He, Z. Lin, Y . Wang, D. Sun, and M.-H. Yang, “Gala3d: Towards text-to-3d complex scene genera- tion via layout-guided generative gaussian splatting,”arXiv preprint arXiv:2402.07207, 2024
arXiv 2024
-
[56]
Set-the-scene: Global-local training for generating controllable nerf scenes,
D. Cohen-Bar, E. Richardson, G. Metzer, R. Giryes, and D. Cohen-Or, “Set-the-scene: Global-local training for generating controllable nerf scenes,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 2920–2929. 15
2023
-
[57]
Dreamscape: 3d scene cre- ation via gaussian splatting joint correlation modeling,
X. Yuan, H. Yang, Y . Zhao, and D. Huang, “Dreamscape: 3d scene cre- ation via gaussian splatting joint correlation modeling,”arXiv preprint arXiv:2404.09227, 2024
arXiv 2024
-
[58]
A general framework to boost 3d gs initialization for text-to-3d generation by lexical richness,
L. Jiang, H. Li, and L. Wang, “A general framework to boost 3d gs initialization for text-to-3d generation by lexical richness,” inProceed- ings of the 32nd ACM International Conference on Multimedia, 2024, pp. 6803–6812
2024
-
[59]
Disentangled 3d scene generation with layout learning,
D. Epstein, B. Poole, B. Mildenhall, A. A. Efros, and A. Holynski, “Disentangled 3d scene generation with layout learning,”arXiv preprint arXiv:2402.16936, 2024
arXiv 2024
-
[60]
X. Cheng, T. Yang, J. Wang, Y . Li, L. Zhang, J. Zhang, and L. Yuan, “Progressive3d: Progressively local editing for text-to-3d content creation with complex semantic prompts,”arXiv preprint arXiv:2310.11784, 2023
arXiv 2023
-
[61]
Lrm: Large reconstruction model for single image to 3d,
Y . Hong, K. Zhang, J. Gu, S. Bi, Y . Zhou, D. Liu, F. Liu, K. Sunkavalli, T. Bui, and H. Tan, “Lrm: Large reconstruction model for single image to 3d,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[62]
Triposr: Fast 3d object reconstruction from a single image,
D. Tochilkin, D. Pankratz, Z. Liu, Z. Huang, A. Letts, Y . Li, D. Liang, C. Laforte, V . Jampani, and Y .-P. Cao, “Triposr: Fast 3d object reconstruction from a single image,”arXiv preprint arXiv:2403.02151, 2024
Pith/arXiv arXiv 2024
-
[64]
Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation,
Z. Zhao, Z. Lai, Q. Lin, Y . Zhao, H. Liu, S. Yang, Y . Feng, M. Yang, S. Zhang, X. Yanget al., “Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation,”arXiv preprint arXiv:2501.12202, 2025
Pith/arXiv arXiv 2025
-
[65]
Meshgen: Generating pbr textured mesh with render-enhanced auto-encoder and generative data augmentation,
Z. Chen, Y . Wang, W. Sun, F. Wang, Y . Chen, and H. Liu, “Meshgen: Generating pbr textured mesh with render-enhanced auto-encoder and generative data augmentation,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 5835–5848
2025
-
[66]
Sf3d: Stable fast 3d mesh reconstruction with uv-unwrapping and illumination disentanglement,
M. Boss, Z. Huang, A. Vasishta, and V . Jampani, “Sf3d: Stable fast 3d mesh reconstruction with uv-unwrapping and illumination disentanglement,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 16 240–16 250
2025
-
[67]
Lrm: Large reconstruction model for single image to 3d,
Y . Hong, K. Zhang, J. Gu, S. Bi, Y . Zhou, D. Liu, F. Liu, K. Sunkavalli, T. Bui, and H. Tan, “Lrm: Large reconstruction model for single image to 3d,”arXiv preprint arXiv:2311.04400, 2023
Pith/arXiv arXiv 2023
-
[68]
J. Xu, W. Cheng, Y . Gao, X. Wang, S. Gao, and Y . Shan, “Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models,”arXiv preprint arXiv:2404.07191, 2024
Pith/arXiv arXiv 2024
-
[69]
Clay: A controllable large-scale generative model for creating high-quality 3d assets,
L. Zhang, Z. Wang, Q. Zhang, Q. Qiu, A. Pang, H. Jiang, W. Yang, L. Xu, and J. Yu, “Clay: A controllable large-scale generative model for creating high-quality 3d assets,”ACM Transactions on Graphics (TOG), vol. 43, no. 4, pp. 1–20, 2024
2024
-
[70]
3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models,
B. Zhang, J. Tang, M. Niessner, and P. Wonka, “3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models,” ACM Transactions on Graphics (TOG), vol. 42, no. 4, pp. 1–16, 2023
2023
-
[71]
Lagem: A large geometry model for 3d rep- resentation learning and diffusion,
B. Zhang and P. Wonka, “Lagem: A large geometry model for 3d rep- resentation learning and diffusion,”arXiv preprint arXiv:2410.01295, 2024
arXiv 2024
-
[72]
Meshgpt: Generating trian- gle meshes with decoder-only transformers,
Y . Siddiqui, A. Alliegro, A. Artemov, T. Tommasi, D. Sirigatti, V . Rosov, A. Dai, and M. Nießner, “Meshgpt: Generating trian- gle meshes with decoder-only transformers,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 19 615–19 625
2024
-
[73]
Meshanything: Artist-created mesh generation with autoregressive transformers,
Y . Chen, T. He, D. Huang, W. Ye, S. Chen, J. Tang, X. Chen, Z. Cai, L. Yang, G. Yuet al., “Meshanything: Artist-created mesh generation with autoregressive transformers,”arXiv preprint arXiv:2406.10163, 2024
arXiv 2024
-
[74]
Meshanything v2: Artist-created mesh generation with adjacent mesh tokenization,
Y . Chen, Y . Wang, Y . Luo, Z. Wang, Z. Chen, J. Zhu, C. Zhang, and G. Lin, “Meshanything v2: Artist-created mesh generation with adjacent mesh tokenization,”arXiv preprint arXiv:2408.02555, 2024
arXiv 2024
-
[75]
Meshxl: Neural coordinate field for generative 3d foundation models,
S. Chen, X. Chen, A. Pang, X. Zeng, W. Cheng, Y . Fu, F. Yin, Y . Wang, Z. Wang, C. Zhanget al., “Meshxl: Neural coordinate field for generative 3d foundation models,”arXiv preprint arXiv:2405.20853, 2024
arXiv 2024
-
[76]
Edgerunner: Auto-regressive auto-encoder for artistic mesh genera- tion,
J. Tang, Z. Li, Z. Hao, X. Liu, G. Zeng, M.-Y . Liu, and Q. Zhang, “Edgerunner: Auto-regressive auto-encoder for artistic mesh genera- tion,”arXiv preprint arXiv:2409.18114, 2024
arXiv 2024
-
[77]
Pivotmesh: Generic 3d mesh generation via pivot vertices guidance,
H. Weng, Y . Wang, T. Zhang, C. Chen, and J. Zhu, “Pivotmesh: Generic 3d mesh generation via pivot vertices guidance,”arXiv preprint arXiv:2405.16890, 2024
arXiv 2024
-
[78]
Llama-mesh: Unifying 3d mesh generation with language models,
Z. Wang, J. Lorraine, Y . Wang, H. Su, J. Zhu, S. Fidler, and X. Zeng, “Llama-mesh: Unifying 3d mesh generation with language models,” arXiv preprint arXiv:2411.09595, 2024
arXiv 2024
-
[79]
Structured 3d latents for scalable and versatile 3d generation,
J. Xiang, Z. Lv, S. Xu, Y . Deng, R. Wang, B. Zhang, D. Chen, X. Tong, and J. Yang, “Structured 3d latents for scalable and versatile 3d generation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2025, pp. 21 469–21 480
2025
-
[80]
Blender - a 3d modeling and animation software,
B. Foundation, “Blender - a 3d modeling and animation software,” 2025, version 4.2, accessed: 2025-02-19. [Online]. Available: https://www.blender.org
2025
-
[81]
Cloudcompare (version 2.12.4) [gpl software],
C. D. Team, “Cloudcompare (version 2.12.4) [gpl software],” 2025, retrieved on 2025-02-19. [Online]. Available: http://www. cloudcompare.org/
2025
-
[82]
Depth anything: Unleashing the power of large-scale unlabeled data,
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao, “Depth anything: Unleashing the power of large-scale unlabeled data,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 10 371–10 381
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.