Lightweight Transformer Models for On-Device Fault Detection: A Benchmark Study on Resource-Constrained Deployment
Pith reviewed 2026-06-26 00:36 UTC · model grok-4.3
The pith
Lightweight transformers match traditional ML at 87.8% F1 on turbofan fault data but at 100x model size and 9000x latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
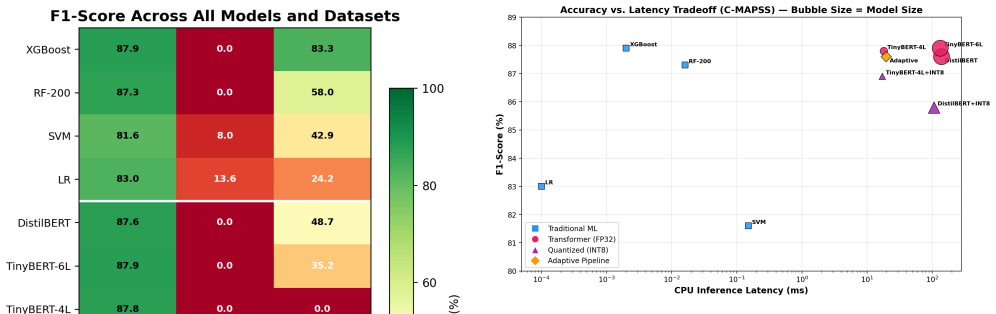
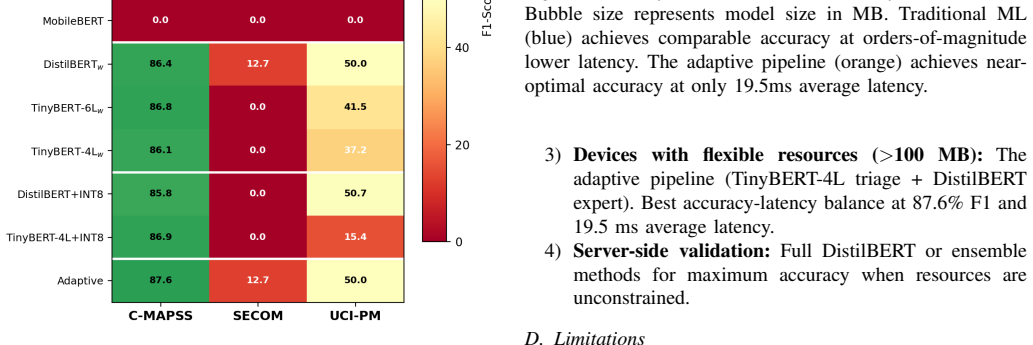
On the C-MAPSS dataset, lightweight transformers match traditional ML at 87.8% F1 but at 100x the model size and 9000x the latency. TinyBERT-4L is the most deployment-friendly transformer at 55 MB and 18 ms CPU latency. INT8 quantization reduces size by 25% while preserving 86.9% F1. The adaptive pipeline, routing 97.9% of predictions through a quantized triage model and only 2.1% to a larger expert, achieves 87.6% F1 at 19.5 ms average latency. On severely imbalanced datasets both traditional and transformer methods perform poorly.
What carries the argument
The two-stage adaptive inference pipeline that routes most cases through a small quantized triage model and reserves a larger expert model for the remaining cases.
If this is right
- INT8 dynamic quantization cuts model size by 25% with only a small drop in F1 on C-MAPSS.
- TinyBERT-4L delivers the best size-latency balance among the tested transformers at 55 MB and 18 ms.
- The adaptive pipeline keeps overall accuracy near the best single-model result while lowering average latency to 19.5 ms.
- Neither traditional ML nor lightweight transformers overcome extreme class imbalance on SECOM and UCI-PM.
Where Pith is reading between the lines
- Specialized techniques for class imbalance may be required before these models can be deployed on real manufacturing lines.
- Hybrid routing strategies could generalize to other sensor-based monitoring tasks where most samples are routine.
- Repeating the benchmark on mobile GPUs or dedicated edge accelerators would clarify whether CPU latency numbers translate to production hardware.
Load-bearing premise
The three public datasets adequately represent the distribution and challenges of real-world fault detection tasks on resource-constrained devices, and that the evaluation metrics are measured under consistent and fair conditions across all models.
What would settle it
Running the same models on a fresh dataset collected from operating industrial equipment that exhibits known class imbalance and measuring end-to-end latency on actual edge hardware would show whether the reported accuracy-latency tradeoffs hold.
Figures

read the original abstract
On-device fault detection enables real-time diagnostics without cloud dependency, but deploying machine learning models on resource-constrained hardware demands careful tradeoffs between accuracy, latency, and model size. We present a benchmark comparing traditional ML methods (Random Forest, XGBoost, SVM, Logistic Regression) against lightweight transformer architectures (DistilBERT, TinyBERT-6L, TinyBERT-4L, MobileBERT) for binary fault detection across three public datasets: NASA C-MAPSS turbofan degradation, SECOM semiconductor manufacturing, and UCI AI4I 2020 predictive maintenance. We evaluate classification performance (F1-score, AUC), model size, and CPU inference latency, and further assess INT8 dynamic quantization and a two-stage adaptive inference pipeline. Our results reveal that on well-separated sensor data (C-MAPSS), lightweight transformers match traditional ML at 87.8% F1 but at 100x the model size and 9000x the latency. TinyBERT-4L emerges as the most deployment-friendly transformer at 55 MB and 18 ms CPU latency. INT8 quantization reduces size by 25% while preserving 86.9% F1. Our adaptive pipeline, routing 97.9% of predictions through a quantized triage model and only 2.1% to a larger expert, achieves 87.6% F1 at 19.5 ms average latency. On severely imbalanced datasets (SECOM, UCI-PM), both traditional and transformer methods struggle significantly, highlighting fundamental limitations of current approaches for extreme class imbalance in fault detection. All code is publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript benchmarks traditional ML methods (Random Forest, XGBoost, SVM, Logistic Regression) against lightweight transformer architectures (DistilBERT, TinyBERT-6L, TinyBERT-4L, MobileBERT) for binary fault detection on three public datasets (NASA C-MAPSS, SECOM, UCI AI4I 2020). It reports F1/AUC performance, model size, and CPU latency, including results for INT8 quantization and a two-stage adaptive inference pipeline that routes most samples through a triage model. Key results include matching 87.8% F1 on C-MAPSS with large efficiency gaps, 87.6% F1 at 19.5 ms via the adaptive pipeline, and poor performance on imbalanced datasets; all code is released publicly.
Significance. If the benchmark results hold under consistent conditions, the work supplies practical guidance on accuracy-efficiency tradeoffs for on-device fault detection, showing that traditional ML can be preferable to transformers for latency/size constraints while quantization and adaptive routing offer mitigation paths. Public code and explicit caveats on imbalance are strengths that support reproducibility and honest assessment.
minor comments (3)
- Abstract: the 9000x latency and 100x size claims should explicitly name the reference traditional ML model and the exact measurement conditions (e.g., batch size, hardware) to allow direct verification.
- The evaluation would benefit from reporting standard deviations or multiple random seeds for the F1/AUC numbers, especially given the acknowledged sensitivity to imbalance.
- Section describing the adaptive pipeline: clarify the exact routing threshold or confidence criterion used to decide when to invoke the expert model, as this directly affects the reported 2.1% routing rate.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript, the accurate summary of our contributions, and the recommendation for minor revision. We appreciate the recognition of the practical guidance on accuracy-efficiency tradeoffs, the value of public code, and the honest caveats regarding class imbalance.
Circularity Check
No significant circularity
full rationale
The paper is an empirical benchmark study reporting direct experimental measurements of F1, AUC, model size, and latency on public datasets using standard models and pipelines. No mathematical derivations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or described claims. All reported numbers (e.g., 87.8% F1, 19.5 ms latency) are presented as outcomes of benchmark runs rather than reductions to prior inputs by construction. The central claims rest on reproducible experimental results with public code noted, satisfying the criteria for a self-contained non-circular evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A survey of predic- tive maintenance: Systems, purposes and approaches,
Y . Ran, X. Zhou, P. Lin, Y . Wen, and R. Deng, “A survey of predic- tive maintenance: Systems, purposes and approaches,”arXiv preprint arXiv:1911.10539, 2019
arXiv 1911
-
[2]
A survey of on-device machine learning,
S. Dhar, J. Guo, J. Liu, S. Tripathi, U. Kurup, and M. Shah, “A survey of on-device machine learning,”ACM Trans. Internet of Things, vol. 2, no. 3, pp. 1–49, 2021
2021
-
[3]
Learning graph structures with transformer for multivariate time-series anomaly detection,
Z. Chen, D. Chen, X. Zhang, Z. Yuan, and X. Cheng, “Learning graph structures with transformer for multivariate time-series anomaly detection,”IEEE Internet of Things J., 2022
2022
-
[4]
Efficient transformers: A survey,
Y . Tay, M. Dehghani, D. Bahri, and D. Metzler, “Efficient transformers: A survey,”ACM Computing Surveys, vol. 55, no. 6, pp. 1–28, 2022
2022
-
[5]
Distilling the knowledge in a neural network,
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv:1503.02531, 2015
Pith/arXiv arXiv 2015
-
[6]
Quantization and training of neural networks for efficient integer-arithmetic-only inference,
B. Jacob et al., “Quantization and training of neural networks for efficient integer-arithmetic-only inference,” inProc. CVPR, 2018, pp. 2704–2713
2018
-
[7]
Deep compression,
S. Han, H. Mao, and W. J. Dally, “Deep compression,” inProc. ICLR, 2016
2016
-
[8]
DistilBERT, a distilled version of BERT,
V . Sanh, L. Debut, J. Chaumond, and T. Wolf, “DistilBERT, a distilled version of BERT,”arXiv:1910.01108, 2019
Pith/arXiv arXiv 1910
-
[9]
TinyBERT: Distilling BERT for natural language under- standing,
X. Jiao et al., “TinyBERT: Distilling BERT for natural language under- standing,” inFindings of EMNLP, 2020, pp. 4163–4174
2020
-
[10]
MobileBERT: a compact task-agnostic BERT for resource- limited devices,
Z. Sun et al., “MobileBERT: a compact task-agnostic BERT for resource- limited devices,” inProc. ACL, 2020, pp. 2158–2170
2020
-
[11]
TensorFlow Lite Micro: Embedded ML for TinyML systems,
R. David et al., “TensorFlow Lite Micro: Embedded ML for TinyML systems,” inProc. MLSys, 2021
2021
-
[12]
Damage propagation modeling for aircraft engine run-to-failure simulation,
A. Saxena, K. Goebel, D. Simon, and N. Eklund, “Damage propagation modeling for aircraft engine run-to-failure simulation,” inProc. PHM, 2008
2008
-
[13]
SECOM dataset,
M. McCann and A. Johnston, “SECOM dataset,” UCI ML Repository, 2008
2008
-
[14]
AI4I 2020 predictive maintenance dataset,
S. Matzka, “AI4I 2020 predictive maintenance dataset,” UCI ML Repos- itory, 2020
2020
-
[15]
Data-driven methods for predictive maintenance,
W. Zhang, D. Yang, and H. Wang, “Data-driven methods for predictive maintenance,”IEEE Systems J., vol. 13, no. 3, pp. 2213–2227, 2019
2019
-
[16]
Support vector machine in machine condition monitoring,
A. Widodo and B. S. Yang, “Support vector machine in machine condition monitoring,”Mech. Syst. Signal Process., vol. 21, no. 6, pp. 2560–2574, 2007
2007
-
[17]
XGBoost: A scalable tree boosting system,
T. Chen and C. Guestrin, “XGBoost: A scalable tree boosting system,” inProc. KDD, 2016, pp. 785–794
2016
-
[18]
Remaining useful life estimation using deep CNNs,
X. Li, Q. Ding, and J. Q. Sun, “Remaining useful life estimation using deep CNNs,”Rel. Eng. Syst. Safety, vol. 172, pp. 1–11, 2018
2018
-
[19]
LSTM for remaining useful life estimation,
S. Zheng, K. Ristovski, A. Farahat, and C. Gupta, “LSTM for remaining useful life estimation,” inProc. ICPHM, 2017, pp. 88–95
2017
-
[20]
Autoformer: Decomposition transformers with auto-correlation,
H. Wu, J. Xu, J. Wang, and M. Long, “Autoformer: Decomposition transformers with auto-correlation,” inProc. NeurIPS, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.