Navigating User Behavior toward Personalized Multimodal Generation
Pith reviewed 2026-06-26 00:25 UTC · model grok-4.3
The pith
Dual codes for items let models turn raw user history into instructions for personalized images and videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
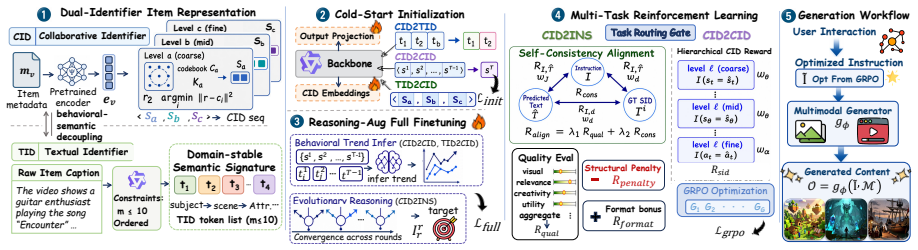
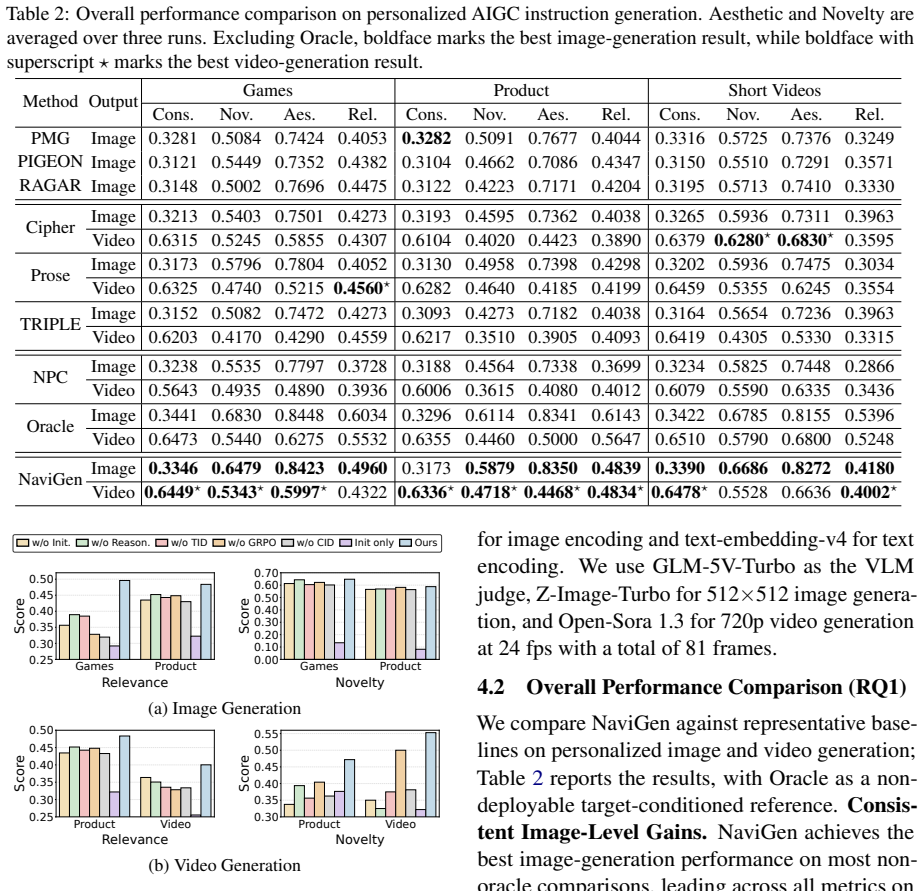
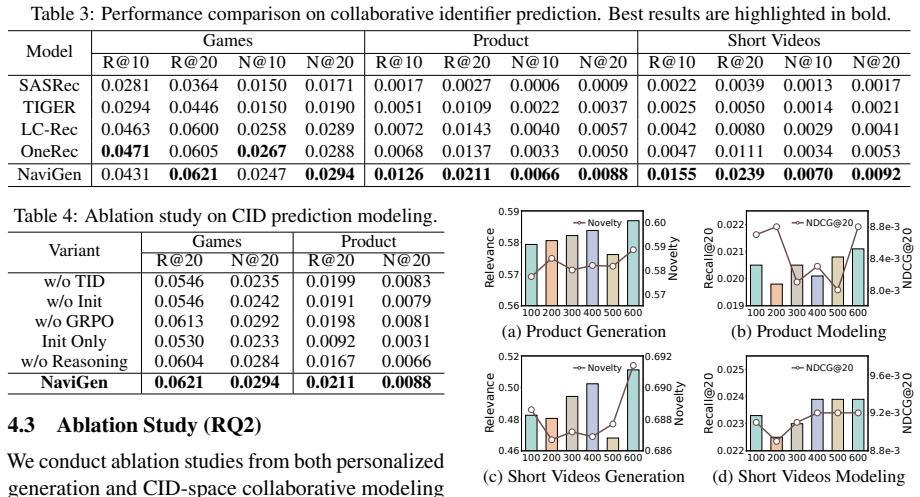
NaviGen demonstrates that representing each item with a dual identifier of collaborative code and textual code, then applying supervised fine-tuning on evolutionarily searched supervision followed by reinforcement learning with hierarchical and self-consistent rewards, produces instructions that better match user intent and improve both personalized multimodal generation and next-item prediction across domains.
What carries the argument
dual identifier coupling a collaborative code and a textual code as behavioral substrate and semantic bridge in one token stream
If this is right
- Personalized image and video generation improves across product, game, and short-video domains.
- Next-item prediction accuracy increases when the learned representations are used.
- The resulting instructions are more specific, relevant, and visually generatable than those from prior methods.
- The two-stage SFT-plus-RL pipeline successfully imparts skills absent from pretraining and raw logs.
Where Pith is reading between the lines
- The dual-code approach could be tested on additional generative tasks such as audio or 3D content where history must become creative instructions.
- Similar representations might improve user modeling in standard recommendation systems even without a generation step.
- Longer user histories or different data types could be examined to check whether the same pipeline continues to scale.
Load-bearing premise
That evolutionarily searched supervision can teach preference reasoning and instruction-writing skills that are missing from both the base model and the raw user behavior data.
What would settle it
An experiment in which NaviGen-generated instructions produce image or video outputs rated no higher than those from simple history-to-prompt baselines, or in which next-item prediction accuracy fails to rise.
Figures


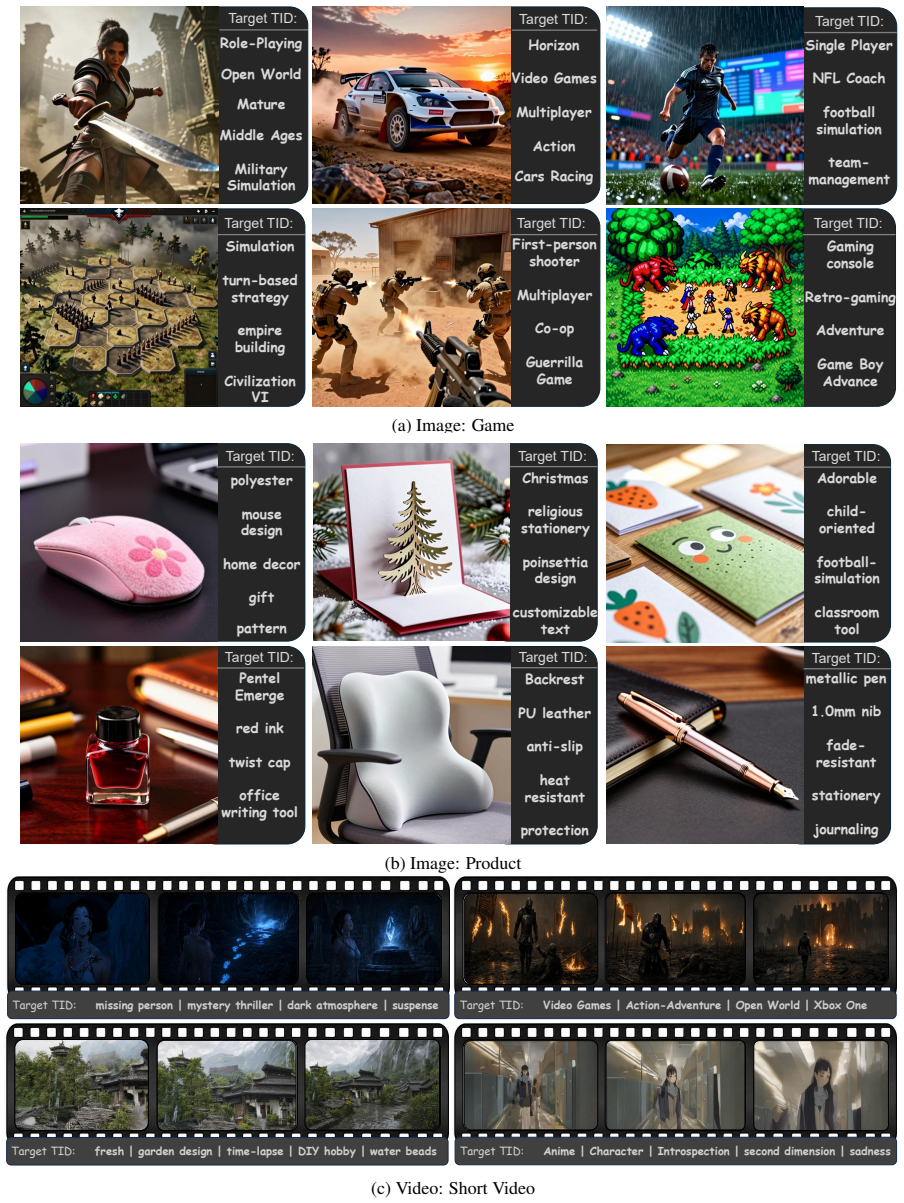







read the original abstract
Modern AIGC pipelines deliver high-fidelity images and videos but presuppose a well-formed creation instruction, while end users rarely articulate visual details, leaving generators misaligned with user demand. We study personalized content generation, which turns a user's interaction history into an executable instruction for downstream synthesis, and identify two obstacles: behavior must be encoded in a form legible to language reasoning, and the model must acquire instruction-writing skill absent from both pretraining and behavior data. We propose NaviGen, which represents each item with a dual identifier coupling a collaborative code and a textual code as a behavioral substrate and a semantic bridge in one token stream. On this representation, a two-stage SFT+RL pipeline first distills preference reasoning and instruction writing from evolutionarily searched supervision, then aligns generation with user intent through hierarchical and self-consistent rewards. Experiments across product, game, and short-video domains show that NaviGen improves personalized image and video generation, strengthens next-item prediction, and yields more specific, relevant, and visually generatable instructions. Our code is released at: https://github.com/iLearn-Lab/NaviGen.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NaviGen for personalized multimodal generation, representing each item via a dual identifier (collaborative code + textual code) as a behavioral substrate and semantic bridge. It employs a two-stage SFT+RL pipeline: the first stage distills preference reasoning and instruction-writing skill from evolutionarily searched supervision, while the second aligns outputs via hierarchical and self-consistent rewards. Experiments across product, game, and short-video domains report gains in personalized image/video generation, next-item prediction accuracy, and the specificity/relevance/generatability of produced instructions. Code is released at the provided GitHub link.
Significance. If the central claims hold, the work addresses a practical gap in AIGC pipelines by converting raw user histories into executable, visually grounded instructions without assuming well-formed prompts from users. The dual-identifier representation and evolutionary-supervision approach could generalize across recommendation and generation tasks. Releasing code supports reproducibility and is a clear strength.
major comments (2)
- [Abstract / method overview] Abstract and method sketch: the claim that the SFT stage distills 'preference reasoning and instruction writing' absent from pretraining and raw behavior data rests on evolutionary search producing transferable supervision. No ablation is described that isolates this contribution against standard SFT on behavior logs alone; without it, the subsequent RL stage's gains in specificity and next-item prediction cannot be attributed to the claimed mechanism.
- [Experiments] Experiments section: the reported improvements in 'more specific, relevant, and visually generatable instructions' and cross-domain gains are presented without error bars, statistical tests, or controls for post-hoc prompt engineering. This leaves open whether the dual-identifier coupling or the hierarchical rewards are the load-bearing factors.
minor comments (1)
- [Method] Notation for the dual identifier (collaborative code + textual code) is introduced without an explicit equation or tokenization diagram, making the 'one token stream' claim hard to verify mechanically.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline revisions to strengthen the attribution of the SFT stage and the rigor of the experimental analysis.
read point-by-point responses
-
Referee: [Abstract / method overview] Abstract and method sketch: the claim that the SFT stage distills 'preference reasoning and instruction writing' absent from pretraining and raw behavior data rests on evolutionary search producing transferable supervision. No ablation is described that isolates this contribution against standard SFT on behavior logs alone; without it, the subsequent RL stage's gains in specificity and next-item prediction cannot be attributed to the claimed mechanism.
Authors: We agree that an explicit ablation isolating evolutionary-search supervision from standard SFT on raw behavior logs would strengthen attribution. The manuscript positions evolutionary search as necessary because raw logs lack explicit preference reasoning and instruction structure, yet we will add this ablation in revision: a direct comparison of the SFT stage with versus without evolutionary supervision, measuring effects on instruction quality metrics and next-item prediction. revision: yes
-
Referee: [Experiments] Experiments section: the reported improvements in 'more specific, relevant, and visually generatable instructions' and cross-domain gains are presented without error bars, statistical tests, or controls for post-hoc prompt engineering. This leaves open whether the dual-identifier coupling or the hierarchical rewards are the load-bearing factors.
Authors: We acknowledge the absence of error bars, statistical tests, and prompt-engineering controls. In the revised version we will report standard deviations over multiple runs, include paired statistical significance tests on all metrics, and add controls that apply post-hoc prompt engineering to the dual-identifier and hierarchical-reward components, thereby clarifying their individual contributions across domains. revision: yes
Circularity Check
No circularity: derivation relies on external experiments rather than definitional reduction
full rationale
The provided abstract and method sketch describe a dual-identifier representation, evolutionary supervision, and two-stage SFT+RL pipeline whose outputs are assessed via cross-domain experiments on image/video generation and next-item prediction. No equations, fitted parameters, or self-citations are shown that would make any claimed prediction equivalent to its inputs by construction. The central claims rest on empirical results outside the fitted quantities, satisfying the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User behavior must be encoded in a form legible to language reasoning and the model must acquire instruction-writing skill absent from pretraining and behavior data
invented entities (1)
-
dual identifier coupling a collaborative code and a textual code
no independent evidence
Reference graph
Works this paper leans on
-
[1]
OneRec: Unifying retrieve and rank with gen- erative recommender and iterative preference align- ment.arXiv preprint arXiv:2502.18965. Junchen Fu, Xuri Ge, Xin Xin, Alexandros Karatzoglou, Ioannis Arapakis, Kaiwen Zheng, Yongxin Ni, and Joemon M Jose Joemon. 2025. Efficient and effec- tive adaptation of multimodal foundation models in sequential recommend...
Pith/arXiv arXiv 2025
-
[2]
Representation learning with large language models for recommendation. InWWW, pages 3464– 3475. Team Seedance, De Chen, Liyang Chen, Xin Chen, Ying Chen, Zhuo Chen, Zhuowei Chen, Feng Cheng, Tianheng Cheng, Yufeng Cheng, and 1 others. 2026. Seedance 2.0: Advancing video generation for world complexity.arXiv preprint arXiv:2604.14148. Team Seedream, Yunpen...
Pith/arXiv arXiv 2026
-
[3]
Content-rich aigc video quality assessment via intricate text alignment and motion-aware consis- tency.arXiv preprint arXiv:2502.04076. Weiwei Sun, Lingyong Yan, Xinyu Ma, Shuaiqiang Wang, Pengjie Ren, Zhumin Chen, Dawei Yin, and Zhaochun Ren. 2023. Is chatgpt good at search? investigating large language models as re-ranking agents.arXiv preprint arXiv:23...
arXiv 2023
-
[4]
InInternational Con- ference on Learning Representations, volume 2025, pages 83048–83077
Cogvideox: Text-to-video diffusion models with an expert transformer. InInternational Con- ference on Learning Representations, volume 2025, pages 83048–83077. Yuyang Ye, Zhi Zheng, Yishan Shen, Tianshu Wang, Hengruo Zhang, Peijun Zhu, Runlong Yu, Kai Zhang, and Hui Xiong. 2025. Harnessing multimodal large language models for multimodal sequential recom- ...
arXiv 2025
-
[5]
In 2024 IEEE 40th International Conference on Data Engineering, pages 1435–1448
Adapting large language models by integrat- ing collaborative semantics for recommendation. In 2024 IEEE 40th International Conference on Data Engineering, pages 1435–1448. IEEE. Guorui Zhou, Honghui Bao, Jiaming Huang, Ji- axin Deng, Jinghao Zhang, Junda She, Kuo Cai, Lejian Ren, Lu Ren, Qiang Luo, and 1 others
2024
-
[6]
Openonerec technical report.arXiv preprint arXiv:2512.24762. 10 A Appendix A.1 Baseline Methods To ensure a comprehensive study, we compare NaviGen against a broad set of baselines cover- ing personalized generation, collaborative filtering and broader behavioral preference modeling, and prompting-based references. Personalized Generation Methods • PMG(Sh...
arXiv 2024
-
[7]
Historical TIDs are only auxiliary clues
The target item is the primary objective. Historical TIDs are only auxiliary clues
-
[8]
Each candidate must implicitly point to the target item, but the creative instruction must not explicitly mention, copy, or quote the target item text or tokens
-
[9]
Each candidate must also output a concise reasoning explaining why the prompt is suitable and what information it used
-
[10]
Use multiple rounds of selection, crossover, and mutation to refine the candidate set
-
[11]
prompt" and
Output only one JSON object with fields "prompt" and "reasoning".""" SCORER_SYSTEM_PROMPT = """You are a strict AIGC prompt evaluation model. Given the user's historical TIDs, the target TID, and a candidate prompt, score the candidate independently on the following four dimensions:
-
[12]
consistency: whether it is centered on the target item semantics, uses history only as supporting context, and avoids drifting or explicitly naming the target
-
[13]
novelty: whether it introduces reasonable innovation without losing the intended direction
-
[14]
aesthetic: whether it shows clear and layered visual composition ability, including subject, scene, style, camera language, lighting, mood, and key details
-
[15]
Scoring requirements:
executability: whether it is specific, clear, contradiction-free, and directly usable for AIGC generation. Scoring requirements:
-
[16]
Output a floating-point score from 0 to 10 for each dimension
-
[17]
The four dimensions must be judged independently; do not give all high scores just because you like the candidate overall
-
[18]
The reasoning should briefly explain the main strengths and weaknesses and stay within 200 characters
-
[19]
If the prompt explicitly mentions the target item, lower consistency and executability
-
[20]
consistency
Output only one JSON object. Do not output Markdown and do not output any extra explanation. Output format: { "consistency": 0.0, "novelty": 0.0, "aesthetic": 0.0, "executability": 0.0, "reasoning": "..." }""" Figure 8: Generation prompts create target-aligned AIGC candidates, while scoring prompts evaluate and select the best final prompt. Tid Generation...
-
[21]
The terms should cover the core semantics of the item
-
[22]
Preserve key information while staying concise and avoiding redundant modifiers
-
[23]
Prefer stable cross-domain signals such as: - subject or category - core scene or use case - key attributes or selling points - style, atmosphere, or audience only when truly important
-
[24]
Avoid synonym stacking and avoid sentence-style expressions
Use standard, general, reusable wording. Avoid synonym stacking and avoid sentence-style expressions
-
[25]
You decide how many terms are needed, but the result must be expressive enough and must not exceed {MAX_TERMS} terms
-
[26]
Each term may be a single word or a very short phrase, but the overall result must stay compact
-
[27]
Strict output requirements:
Order the terms by importance, with the most essential term first. Strict output requirements:
-
[28]
terms": [
The format must be {{"terms": ["term1", "term2"]}}
-
[29]
Do not output explanations, reasoning process, Markdown, or extra text
-
[30]
All terms must be in English
-
[31]
"" Figure 9: Convert item captions into structured Term IDs. Oneshot Distillation SYSTEM_PROMPT =
Do not use Chinese or any other non-English language in the terms.""" Figure 9: Convert item captions into structured Term IDs. Oneshot Distillation SYSTEM_PROMPT = """You are an AIGC creative planning teacher model. Your task is to distill a final reasoning paragraph from the user's historical TIDs, the step1 reasoning, the target TID, and the step2 evol...
-
[32]
The output must be one coherent paragraph of natural-language reasoning written as first-person internal thinking, with "I" as the subject
-
[33]
I should first infer, from the history and the step1 reasoning, what kind of next item the user is likely to engage with, without naming the final target too early
-
[34]
Then I should summarize how the prompt-writing route gradually moved closer to the right answer by comparing early drafts, keeping stronger parts, rewriting weaker parts, and refining the wording
-
[35]
Use plain language instead
Do not use biological evolution terms such as selection, crossover, mutation, founder, or similar jargon. Use plain language instead
-
[36]
Near the end of the paragraph, I may explicitly mention the final target TID and explain why the route converges there
-
[37]
The paragraph should explain how the inferred target direction, the history clues, and the prompt revision route together support the final prompt-writing idea
-
[38]
Do not output XML/HTML tags, Markdown code blocks, bullet points, titles, or template fields
-
[39]
"" USER_PROMPT_TEMPLATE =
Do not write as a teacher note, analysis report, or explanation addressed to someone else. The paragraph must read like the student model's own think content.""" USER_PROMPT_TEMPLATE = """User historical TIDs: {history_tids} Step1 reasoning from history to the next target: {step1_reasoning} Target TID: {target_tid} Step2 prompt revision summary: {evolutio...
-
[40]
Write in first person, using "I" as the subject throughout
-
[41]
You may condense the step1 reasoning, but keep its core judgment about the likely next-item direction
-
[42]
Use the step2 summary to explain in plain language how the drafts moved closer to the right final prompt
-
[43]
Do not use technical or biological evolution wording such as selection, crossover, mutation, founder, elite, mate, or similar labels
-
[44]
Near the end, explicitly mention the target TID and explain why the route finally points there
-
[45]
End by summarizing how I would write the final prompt around that target direction, using history as support rather than as the main objective
-
[46]
"" Figure 10: Distills user history, target reasoning, and prompt refinement into final first-person reasoning. 13 SFT Task
Output one complete paragraph only.""" Figure 10: Distills user history, target reasoning, and prompt refinement into final first-person reasoning. 13 SFT Task "cid2tid": ( "You are an ID mapping assistant. " "Your task is to map the input cid to the corresponding tid (tid is the item's metadata). " "The final answer must be a JSON object only, with the f...
-
[47]
The output must be one complete, natural paragraph of reasoning text
-
[48]
I should
The reasoning must be written from the perspective of a student model (use first-person thinking style such as "I should...", "I need to...")
-
[49]
The first part of the paragraph should explain how to extract semantic clues from history and narrow down candidates toward the correct target_tid
-
[50]
The final part of the paragraph should explicitly conclude with the provided target_tid as the final decision
-
[51]
novelty_score
Do not output any extra explanation, list, or metadata; output only the single reasoning paragraph.""" Figure 14: Reason from hist TIDs to target TID. Judging: Image You are AIM-judge for AIGC image generation evaluation. Evaluate the generated media conditioned on the creative text instruction (ins). Return JSON only with fields: "novelty_score", "aesthe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.