EgoSAT: A Comprehensive Benchmark of Egocentric Streaming Interaction Understanding
Pith reviewed 2026-06-26 00:24 UTC · model grok-4.3
The pith
EgoSAT benchmark shows vision-language models struggle with retrospective and prospective reasoning in streaming egocentric videos while exhibiting severe confidence miscalibration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
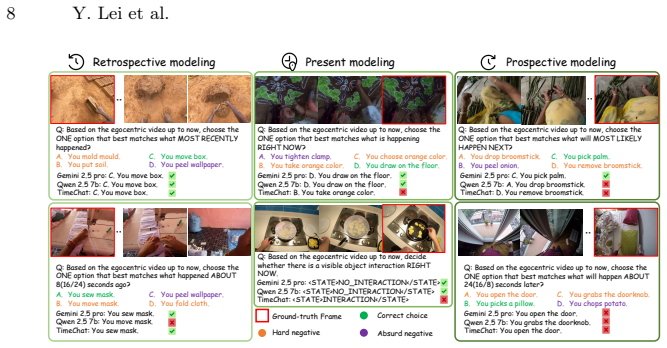
EgoSAT establishes a unified streaming framework for egocentric interaction understanding in which queries about past events test retrospective reasoning, queries about ongoing activities test online understanding, and queries about future actions test prospective anticipation, all under the constraint that only previously observed frames are available. Systematic assessment of diverse vision-language models reveals that they struggle with prospective and retrospective modeling and exhibit severe mis-calibration where confidence often fails to track inherent answerability.
What carries the argument
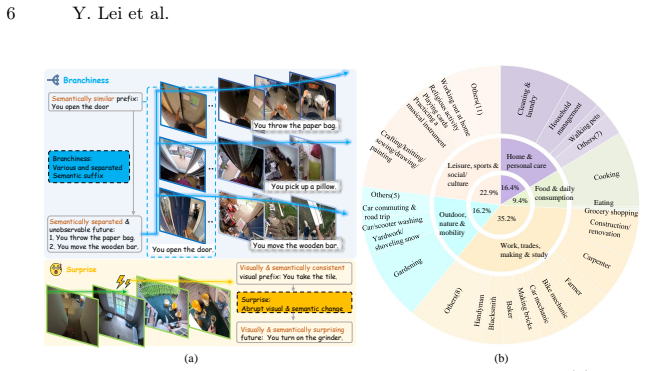
The EgoSAT benchmark of 1997 unique egocentric videos spanning 165 hours with around 4800 question-answer pairs that probe reasoning across retrospective, online, and prospective temporal contexts under a streaming constraint.
If this is right
- Vision-language models require targeted improvements to handle prospective anticipation and retrospective review when processing sequential egocentric video streams.
- Techniques for confidence calibration are necessary to reduce confidently incorrect outputs on unanswerable queries.
- Distinguishing answerability in benchmarks enables more precise diagnosis of specific failure modes in temporal reasoning.
- Unified streaming evaluations can direct development of models capable of integrated past-present-future reasoning in real-time settings.
Where Pith is reading between the lines
- The miscalibration findings imply that deployment in safety-critical streaming applications like wearable cameras could produce unreliable outputs without added uncertainty handling.
- The benchmark structure suggests potential extensions to test memory-efficient architectures that retain relevant past frames for long video streams.
- Results point toward the value of similar streaming benchmarks for non-egocentric domains such as surveillance or autonomous driving where temporal context varies.
Load-bearing premise
The 4800 question-answer pairs are high-quality unbiased probes that correctly isolate retrospective, online, and prospective reasoning under the streaming constraint without post-hoc selection effects or annotation artifacts.
What would settle it
A new vision-language model that achieves high accuracy on prospective and retrospective questions while producing confidence scores that reliably distinguish answerable from unanswerable queries would falsify the reported struggles and mis-calibration.
Figures

read the original abstract
We introduce EgoSAT, the first comprehensive benchmark for egocentric video reasoning in streaming settings, designed to evaluate the capabilities of modern vision-language models (VLMs). The benchmark targets streaming interaction understanding, where video frames arrive sequentially and models must continuously interpret evolving visual context. EgoSAT unifies several previously distinct tasks within a single streaming framework. In this formulation, queries about completed events correspond to retrospective reasoning, queries about ongoing activities require online understanding, and queries about future actions involve prospective anticipation. This unified setting requires models to reason about the past, present, and future while operating under the constraint that only previously observed frames are available. EgoSAT contains 1,997 unique videos spanning 165 hours of egocentric footage and around 4,800 high-quality question-answer pairs, carefully designed to probe reasoning across varying temporal contexts. Using this benchmark, we evaluate a diverse set of both open-weight and closed-weight VLMs, providing a systematic assessment of their ability for streaming interaction understanding. By distinguishing answerability and conducting diagnostics on confidence of models, we find existing models not only struggle with prospective and retrospective modeling, but also exhibit severe mis-calibration: confidence often fails to track inherent answerability, leading to dangerous "confidently wrong" behaviors. Project page: https://leiyj23.github.io/EgoSAT/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EgoSAT, the first benchmark for egocentric streaming video reasoning with 1,997 videos (165 hours) and ~4,800 QA pairs. It unifies retrospective (past events), online (ongoing activities), and prospective (future actions) reasoning under true streaming constraints where only prior frames are available. Evaluation of open- and closed-weight VLMs reveals struggles with prospective and retrospective tasks plus severe confidence mis-calibration, where models are often 'confidently wrong' relative to inherent answerability.
Significance. If the QA construction and answerability labeling hold, EgoSAT would fill a clear gap by providing a unified streaming testbed for VLMs on egocentric data; the mis-calibration finding, if reproducible, would be practically relevant for deployment safety. The work ships a public project page and benchmark, which strengthens its utility.
major comments (2)
- [§3] §3 (Benchmark Construction, implied by abstract description of 'carefully designed' QA pairs): the process for determining answerability labels, enforcing streaming constraints, and avoiding post-hoc selection or annotation artifacts is not described with sufficient detail (e.g., inter-annotator agreement statistics, annotation guidelines, or verification that queries truly require only past frames) to confirm the probes isolate retrospective/online/prospective reasoning without bias.
- [§4] §4 (Evaluation and diagnostics): the quantitative definition and statistical test for 'severe mis-calibration' (confidence failing to track answerability) is not specified; without explicit metrics (e.g., expected calibration error stratified by answerability or Brier score), the claim that models exhibit dangerous 'confidently wrong' behavior cannot be verified or reproduced from the reported results.
minor comments (2)
- [Abstract] The abstract states 'around 4,800' pairs; the exact count and breakdown by temporal category (retrospective/online/prospective) should be reported in a table for precision.
- [Experiments] Model names, sizes, and exact prompting setup for the evaluated VLMs are not listed in the provided text; these details are needed for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive feedback on EgoSAT. We address each major comment below and will revise the manuscript to incorporate additional details as needed.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction, implied by abstract description of 'carefully designed' QA pairs): the process for determining answerability labels, enforcing streaming constraints, and avoiding post-hoc selection or annotation artifacts is not described with sufficient detail (e.g., inter-annotator agreement statistics, annotation guidelines, or verification that queries truly require only past frames) to confirm the probes isolate retrospective/online/prospective reasoning without bias.
Authors: We agree that Section 3 would benefit from expanded methodological detail. In the revised manuscript, we will add: annotation guidelines for QA pair creation and answerability labeling; inter-annotator agreement statistics; explicit procedures for enforcing that queries reference only past frames under streaming constraints; and steps taken to mitigate post-hoc selection or annotation artifacts. These additions will strengthen verification that the benchmark isolates retrospective, online, and prospective reasoning. revision: yes
-
Referee: [§4] §4 (Evaluation and diagnostics): the quantitative definition and statistical test for 'severe mis-calibration' (confidence failing to track answerability) is not specified; without explicit metrics (e.g., expected calibration error stratified by answerability or Brier score), the claim that models exhibit dangerous 'confidently wrong' behavior cannot be verified or reproduced from the reported results.
Authors: We concur that the mis-calibration analysis requires explicit quantitative definitions for reproducibility. The revised Section 4 will specify the exact metrics employed (including any stratification by answerability and calibration measures such as expected calibration error), along with any statistical tests used to support claims of severe mis-calibration. This will allow independent verification of the reported confidence behaviors. revision: yes
Circularity Check
No significant circularity
full rationale
This is an empirical benchmark paper introducing EgoSAT with 1,997 videos and ~4,800 QA pairs to evaluate VLMs on retrospective, online, and prospective reasoning in streaming settings. No mathematical derivations, equations, fitted parameters presented as predictions, or load-bearing self-citations appear in the claims. Model evaluations and mis-calibration diagnostics are direct empirical measurements against the benchmark, with no reduction of results to inputs by construction. The work is self-contained as a dataset and evaluation study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
anthropic.com/transparency
Claude opus 4 and claude sonnet 4 summary table (2025),https : / / www . anthropic.com/transparency
2025
-
[2]
Gemini 2.5 pro model card (2025),https://storage.googleapis.com/deepmind- media/Model-Cards/Gemini-2-5-Pro-Model-Card.pdf
2025
-
[3]
An, X., Xie, Y., Yang, K., Zhang, W., Zhao, X., Cheng, Z., Wang, Y., Xu, S., Chen, C., Didi, Z., Wu, C., Tan, H., Li, C., Yang, J., Yu, J., Wang, X., Qin, B., Wang, Y., Yan, Z., Feng, Z., Liu, Z., Li, B., Deng, J.: Llava-onevision-1.5: Fully open framework for democratized multimodal training (2025)
2025
-
[4]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report (2025),https://arxiv.org/abs/2502.13923
Pith/arXiv arXiv 2025
-
[5]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR) Workshops
Bärmann, L., Waibel, A.: Where did i leave my keys? - episodic-memory-based question answering on egocentric videos. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR) Workshops. pp. 1560–1568 (June 2022)
2022
-
[6]
In: The Eleventh International Conference on Learning Representations
Bolya,D.,Fu,C.Y.,Dai,X.,Zhang,P.,Feichtenhofer,C.,Hoffman,J.:Tokenmerg- ing: Your vit but faster. In: The Eleventh International Conference on Learning Representations
-
[7]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, J., Lv, Z., Wu, S., Lin, K.Q., Song, C., Gao, D., Liu, J.W., Gao, Z., Mao, D., Shou, M.Z.: Videollm-online: Online video large language model for streaming video. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18407–18418 (2024)
2024
-
[8]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Chen, J., Zeng, Z., Lin, Y., Li, W., Ma, Z., Shou, M.Z.: Livecc: Learning video llm with streaming speech transcription at scale. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29083–29095 (2025)
2025
-
[9]
In: European Conference on Computer Vision
Chen, L., Zhao, H., Liu, T., Bai, S., Lin, J., Zhou, C., Chang, B.: An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision- language models. In: European Conference on Computer Vision. pp. 19–35 (2024)
2024
-
[10]
Chen, Y., Ge, Y., Ge, Y., Ding, M., Li, B., Wang, R., Xu, R., Shan, Y., Liu, X.: Egoplan-bench: Benchmarking multimodal large language models for human-level planning (2024),https://arxiv.org/abs/2312.06722
arXiv 2024
-
[11]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Cheng, S., Guo, Z., Wu, J., Fang, K., Li, P., Liu, H., Liu, Y.: Egothink: Evalu- ating first-person perspective thinking capability of vision-language models. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 14291–14302 (2023),https://api.semanticscholar.org/CorpusID:265456330
2024
-
[12]
International Journal of Computer Vision130(1), 33–55 (2022)
Damen, D., Doughty, H., Farinella, G.M., Furnari, A., Kazakos, E., Ma, J., Molti- santi, D., Munro, J., Perrett, T., Price, W., et al.: Rescaling egocentric vision: Collection, pipeline and challenges for epic-kitchens-100. International Journal of Computer Vision130(1), 33–55 (2022)
2022
-
[13]
In: 2019 IEEE/CVF International Conference on Computer Vision Workshop (IC- CVW)
Fan, C.: Egovqa - an egocentric video question answering benchmark dataset. In: 2019 IEEE/CVF International Conference on Computer Vision Workshop (IC- CVW). pp. 4359–4366 (2019).https://doi.org/10.1109/ICCVW.2019.00536
-
[14]
In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition
Grauman, K., Westbury, A., Byrne, E., Chavis, Z., Furnari, A., Girdhar, R., Ham- burger, J., Jiang, H., Liu, M., Liu, X., et al.: Ego4d: Around the world in 3,000 hours of egocentric video. In: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition. pp. 18995–19012 (2022) 16 Y. Lei et al
2022
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Grauman, K., Westbury, A., Torresani, L., Kitani, K., Malik, J., Afouras, T., Ashutosh, K., Baiyya, V., Bansal, S., Boote, B., et al.: Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19383–19400 (2024)
2024
-
[16]
arXiv preprint arXiv:2412.21080 (2024)
Huang, Y., Xu, J., Pei, B., He, Y., Chen, G., Yang, L., Chen, X., Wang, Y., Nie, Z., Liu, J., et al.: Vinci: A real-time embodied smart assistant based on egocentric vision-language model. arXiv preprint arXiv:2412.21080 (2024)
arXiv 2024
-
[17]
Huang, Z., Ji, Y., Wang, X., Mehta, N., Xiao, T., Lee, D., Vanvalkenburgh, S., Zha, S., Lai, B., Yu, L., Zhang, N., Lee, Y.J., Liu, M.: Building a mind palace: Structuringenvironment-grounded semanticgraphsforeffectivelongvideoanalysis with llms (2025),https://arxiv.org/abs/2501.04336
arXiv 2025
-
[18]
Jia, B., Lei, T., Zhu, S.C., Huang, S.: Egotaskqa: Understanding human tasks in egocentric videos (2022),https://arxiv.org/abs/2210.03929
arXiv 2022
-
[19]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, J., Chen, Y., Piao, D., Pan, P., Yu, Y., Wang, D., Yan, H., Yue, L., Wang, S., Chen, Y., et al.: Egoprox: Evaluating mllms on egocentric 3d proximity reasoning across a cognitive hierarchy. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 23751–23762 (2026)
2026
-
[20]
arXiv preprint arXiv:2605.27074 (2026)
Li, J., Chen, Y., Song, W., Lei, Y., Zhang, Y., Yan, H., Pan, P., Liu, M.: Ipibench: Evaluating interactive proactive intelligence of mllms under continuous streams. arXiv preprint arXiv:2605.27074 (2026)
Pith/arXiv arXiv 2026
-
[21]
arXiv e-prints pp
Li, X., Wang, Y., Yu, J., Zeng, X., Zhu, Y., Huang, H., Gao, J., Li, K., He, Y., Wang, C., et al.: Videochat-flash: Hierarchical compression for long-context video modeling. arXiv e-prints pp. arXiv–2501 (2024)
2024
-
[22]
Lin, B., Ye, Y., Zhu, B., Cui, J., Ning, M., Jin, P., Yuan, L.: Video-llava: Learn- ing united visual representation by alignment before projection (2024),https: //arxiv.org/abs/2311.10122
Pith/arXiv arXiv 2024
-
[23]
arXiv preprint arXiv:2411.03628 (2024)
Lin, J., Fang, Z., Chen, C., Wan, Z., Luo, F., Li, P., Liu, Y., Sun, M.: Stream- ingbench: Assessing the gap for mllms to achieve streaming video understanding. arXiv preprint arXiv:2411.03628 (2024)
arXiv 2024
-
[24]
ArXivabs/2308.09126(2023), https://api.semanticscholar.org/CorpusID:261031047
Mangalam, K., Akshulakov, R., Malik, J.: Egoschema: A diagnostic benchmark for very long-form video language understanding. ArXivabs/2308.09126(2023), https://api.semanticscholar.org/CorpusID:261031047
arXiv 2023
-
[25]
Niu, J., Li, Y., Miao, Z., Ge, C., Zhou, Y., He, Q., Dong, X., Duan, H., Ding, S., Qian, R., et al.: Ovo-bench: How far is your video-llms from real-world online video understanding? In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18902–18913 (2025)
2025
-
[26]
In: Advances in Neural Information Processing Systems (2025)
Peng, T., Hua, J., Liu, M., Lu, F.: In the eye of mllm: Benchmarking egocentric video intent understanding with gaze-guided prompting. In: Advances in Neural Information Processing Systems (2025)
2025
-
[27]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Qian, R., Ding, S., Dong, X., Zhang, P., Zang, Y., Cao, Y., Lin, D., Wang, J.: Dispider: Enabling video llms with active real-time interaction via disentangled perception, decision, and reaction. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24045–24055 (2025)
2025
-
[28]
Advances in Neural Information Processing Systems37, 119336–119360 (2024)
Qian, R.,Dong,X.,Zhang,P., Zang,Y.,Ding,S.,Lin,D., Wang,J.:Streaminglong video understanding with large language models. Advances in Neural Information Processing Systems37, 119336–119360 (2024)
2024
-
[29]
In: Findings of the Association for Computational Linguistics: EMNLP 2023
Ren, S., Chen, S., Li, S., Sun, X., Hou, L.: Testa: Temporal-spatial token aggrega- tion for long-form video-language understanding. In: Findings of the Association for Computational Linguistics: EMNLP 2023. pp. 932–947 (2023) EgoSAT: Egocentric Streaming Interaction Benchmark 17
2023
-
[30]
Ryoo, M.S., Piergiovanni, A., Arnab, A., Dehghani, M., Angelova, A.: Token- learner: What can 8 learned tokens do for images and videos? arXiv preprint arXiv:2106.11297 (2021)
arXiv 2021
-
[31]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems
Shao, K., Keda, T., Qin, C., You, H., Sui, Y., Wang, H.: Holitom: Holistic to- ken merging for fast video large language models. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[32]
In: 42nd International Conference on Machine Learning, ICML 2025
Shen, X., Xiong, Y., Zhao, C., Wu, L., Chen, J., Zhu, C., Liu, Z., Xiao, F., Varadarajan, B., Bordes, F., et al.: Longvu: Spatiotemporal adaptive compres- sion for long video-language understanding. In: 42nd International Conference on Machine Learning, ICML 2025. ML Research Press (2025)
2025
-
[33]
Advances in neural information processing systems36, 38863–38886 (2023)
Song, Y., Byrne, E., Nagarajan, T., Wang, H., Martin, M., Torresani, L.: Ego4d goal-step: Toward hierarchical understanding of procedural activities. Advances in neural information processing systems36, 38863–38886 (2023)
2023
-
[34]
arXiv preprint arXiv:2403.00998 (2024)
Tsvilodub, P., Wang, H., Grosch, S., Franke, M.: Predictions from language models for multiple-choice tasks are not robust under variation of scoring methods. arXiv preprint arXiv:2403.00998 (2024)
arXiv 2024
-
[35]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wang,W.,He,Z.,Hong,W.,Cheng,Y.,Zhang,X.,Qi,J.,Ding,M.,Gu,X.,Huang, S., Xu, B., et al.: Lvbench: An extreme long video understanding benchmark. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 22958–22967 (2025)
2025
-
[36]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition
Wang, Y., Wang, Y., Chen, B., Wu, T., Zhao, D., Zheng, Z.: Omnimmi: A com- prehensive multi-modal interaction benchmark in streaming video contexts. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 18925–18935 (2025)
2025
-
[37]
important tokens
Wen, Z., Gao, Y., Wang, S., Zhang, J., Zhang, Q., Li, W., He, C., Zhang, L.: Stop looking for “important tokens” in multimodal language models: Duplication matters more. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 9972–9991 (2025)
2025
-
[38]
(eds.) Computer Vi- sion – ECCV 2022
Wong, B., Chen, J., Wu, Y., Lei, S.W., Mao, D., Gao, D., Shou, M.Z.: Assistq: Affordance-centricquestion-driventaskcompletionforegocentricassistant.In:Avi- dan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) Computer Vi- sion – ECCV 2022. pp. 485–501. Springer Nature Switzerland, Cham (2022)
2022
-
[39]
Advances in Neural Information Pro- cessing Systems37, 28828–28857 (2024)
Wu, H., Li, D., Chen, B., Li, J.: Longvideobench: A benchmark for long-context interleaved video-language understanding. Advances in Neural Information Pro- cessing Systems37, 28828–28857 (2024)
2024
-
[40]
In: The Thirteenth International Conference on Learning Representations
Xiong, H., Yang, Z., Yu, J., Zhuge, Y., Zhang, L., Zhu, J., Lu, H.: Streaming video understanding and multi-round interaction with memory-enhanced knowledge. In: The Thirteenth International Conference on Learning Representations
-
[41]
arXiv preprint arXiv:2510.09608 (2025)
Xu, R., Xiao, G., Chen, Y., He, L., Peng, K., Lu, Y., Han, S.: Streamingvlm: Real- time understanding for infinite video streams. arXiv preprint arXiv:2510.09608 (2025)
Pith/arXiv arXiv 2025
-
[42]
In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference
Yang, C., Sui, Y., Xiao, J., Huang, L., Gong, Y., Li, C., Yan, J., Bai, Y., Sa- dayappan, P., Hu, X., et al.: Topv: Compatible token pruning with inference time optimization for fast and low-memory multimodal vision language model. In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference. pp. 19803– 19813 (2025)
2025
-
[43]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yang, C., Dong, X., Zhu, X., Su, W., Wang, J., Tian, H., Chen, Z., Wang, W., Lu, L., Dai, J.: Pvc: Progressive visual token compression for unified image and video processing in large vision-language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24939–24949 (2025) 18 Y. Lei et al
2025
-
[44]
Yang, J., Liu, S., Guo, H., Dong, Y., Zhang, X., Zhang, S., Wang, P., Zhou, Z., Xie, B., Wang, Z., Ouyang, B., Lin, Z., Cominelli, M., Cai, Z., Zhang, Y., Zhang, P., Hong, F., Widmer, J., Gringoli, F., Yang, L., Li, B., Liu, Z.: Egolife: Towards egocentric life assistant (2025),https://arxiv.org/abs/2503.03803
arXiv 2025
-
[45]
In: The Thirteenth International Conference on Learning Repre- sentations
Yang, Z., Hu, Y., Du, Z., Xue, D., Qian, S., Wu, J., Yang, F., Dong, W., Xu, C.: Svbench: A benchmark with temporal multi-turn dialogues for streaming video understanding. In: The Thirteenth International Conference on Learning Repre- sentations
-
[46]
arXiv preprint arXiv:2405.20985 (2024)
Yao, L., Li, L., Ren, S., Wang, L., Liu, Y., Sun, X., Hou, L.: Deco: Decoupling token compression from semantic abstraction in multimodal large language models. arXiv preprint arXiv:2405.20985 (2024)
arXiv 2024
-
[47]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Yao, L., Li, Y., Wei, Y., Li, L., Ren, S., Liu, Y., Ouyang, K., Wang, L., Li, S., Li, S., et al.: Timechat-online: 80% visual tokens are naturally redundant in streaming videos. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 10807–10816 (2025)
2025
-
[48]
In: Yue, Y., Garg, A., Peng, N., Sha, F., Yu, R
Ye, H., Zhang, H., Daxberger, E., Chen, L., Lin, Z., Li, Y., Zhang, B., You, H., Xu, D., Gan, Z., Lu, J., Yang, Y.: Mmego: Towards building egocentric mul- timodal llms for video qa. In: Yue, Y., Garg, A., Peng, N., Sha, F., Yu, R. (eds.) International Conference on Representation Learning. vol. 2025, pp. 71705– 71723 (2025),https://proceedings.iclr.cc/pa...
2025
-
[49]
Yuan, Y., Dang, R., Li, L., Li, W., Jiao, D., Li, X., Zhao, D., Wang, F., Zhang, W., Xiao, J., et al.: Eoc-bench: Can mllms identify, recall, and forecast objects in an egocentric world? arXiv preprint arXiv:2506.05287 (2025)
arXiv 2025
-
[50]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems
Zhang, H., Fu, Y.: Vqtoken: Neural discrete token representation learning for ex- treme token reduction in video large language models. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[51]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang, H., Wang, Y., Tang, Y., Liu, Y., Feng, J., Jin, X.: Flash-vstream: Efficient real-time understanding for long video streams. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 21059–21069 (2025)
2025
-
[52]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems
Zhang, Y., Shi, C., Wang, Y., Yang, S.: Eyes wide open: Ego proactive video-llm for streaming video. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[53]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhou, J., Shu, Y., Zhao, B., Wu, B., Liang, Z., Xiao, S., Qin, M., Yang, X., Xiong, Y., Zhang, B., et al.: Mlvu: Benchmarking multi-task long video understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13691–13701 (2025)
2025
-
[54]
EgoSAT: A Comprehensive Benchmark of Egocentric Streaming Interaction Understanding
Zhou, S., Xiao, J., Li, Q., Li, Y., Yang, X., Guo, D., Wang, M., Chua, T.S., Yao, A.: Egotextvqa: Towards egocentric scene-text aware video question answering. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 3363–3373 (2025),https://api.semanticscholar.org/CorpusID:276258564 EgoSAT: Egocentric Streaming Interaction Benchmark...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.