DDStereo: Efficient Dual Decoder Transformers for Stereo 3D Road Anomaly Detection
Pith reviewed 2026-06-26 00:31 UTC · model grok-4.3
The pith
Dual lightweight decoders sharing queries let stereo 3D detection run in real time while supporting open-set cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
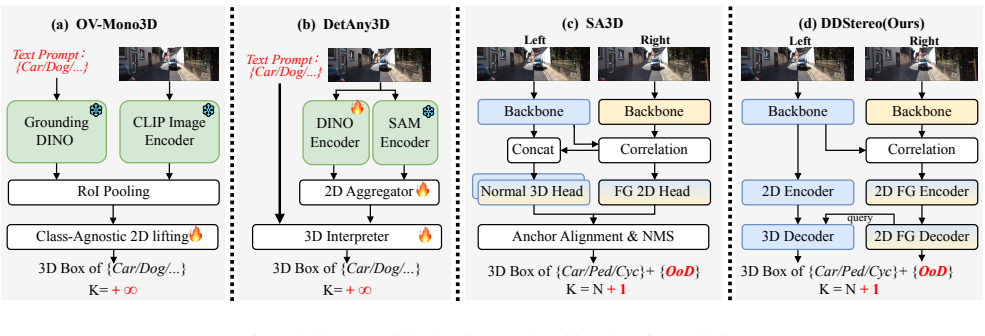
DDStereo introduces a Dual-Decoder Stereo Transformer consisting of two lightweight decoder branches—one for open-set foreground 2D detection and the other for 3D attribute regression—that share object-level queries to achieve unified target-level alignment, together with a compact disparity feature extractor and streamlined architecture, delivering state-of-the-art accuracy on public stereo benchmarks under both closed-set and open-set protocols and, for the first time, real-time inference speeds comparable to monocular methods.
What carries the argument
Two lightweight decoder branches sharing object-level queries to produce unified target-level alignment between open-set 2D detection and 3D regression.
If this is right
- Surpasses prior stereo 3D detectors in inference speed on public benchmarks.
- Achieves real-time performance comparable to monocular approaches for the first time.
- Maintains state-of-the-art accuracy under both closed-set and open-set protocols.
- Requires no additional post-processing or dataset-specific tuning for the reported results.
Where Pith is reading between the lines
- The shared-query pattern could be tested in other multi-task detection transformers to reduce alignment overhead.
- If the efficiency holds, the method could support 3D open-set detection in additional sensor setups beyond stereo cameras.
- The design leaves open whether the same dual-branch structure scales to higher-resolution inputs or longer video sequences without speed loss.
Load-bearing premise
The two lightweight decoder branches sharing object-level queries will produce unified target-level alignment that preserves both 2D open-set detection quality and 3D regression accuracy without requiring additional post-processing or dataset-specific tuning.
What would settle it
A controlled run on the same stereo benchmarks where the shared-query model either drops below the reported open-set mAP or fails to sustain claimed real-time FPS without extra post-processing.
Figures










read the original abstract
Stereo-based 3D object detection still faces two critical safety challenges: real-time performance and open-set generalization. Existing stereo 3D methods typically achieve twice the accuracy of monocular methods but suffer from significantly lower inference speeds, making them unsuitable for real-time applications. Meanwhile, recent advances in open-world detection have introduced open-set and open-vocabulary algorithms in monocular 2D and 3D settings, yet stereo-based open-set detection remains largely unexplored. To bridge this gap, we propose DDStereo, a novel Dual-Decoder Stereo Transformer for real-time open-set 3D object detection. DDStereo features two lightweight decoder branches: one for open-set foreground 2D detection and the other for 3D attribute regression. These decoders share object-level queries to achieve unified target-level alignment. To enhance inference efficiency, we designed a compact disparity feature extractor and a streamlined decoder architecture. Experiments on public stereo 3D benchmarks demonstrate that DDStereo achieves state-of-the-art accuracy under both closed-set and open-set protocols. Notably, our method surpasses existing stereo 3D detectors in inference speed and, for the first time, achieves real-time performance comparable to monocular approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DDStereo, a Dual-Decoder Stereo Transformer for real-time open-set 3D object detection on stereo inputs. It consists of two lightweight decoder branches that share object-level queries: one branch performs open-set 2D foreground detection while the other performs 3D attribute regression. A compact disparity feature extractor and streamlined decoder architecture are introduced to improve efficiency. Experiments on public stereo 3D benchmarks are claimed to show state-of-the-art accuracy under both closed-set and open-set protocols, with inference speeds that surpass prior stereo methods and reach real-time levels comparable to monocular detectors.
Significance. If the performance claims hold, the work would be significant for autonomous driving and robotics by closing the accuracy-speed gap between stereo and monocular 3D detection while extending open-set capabilities to the stereo setting, which remains underexplored. The shared-query dual-decoder design offers a potentially efficient way to unify 2D open-set and 3D regression tasks without heavy post-processing.
major comments (2)
- Abstract: the central claims of SOTA accuracy under closed- and open-set protocols and real-time inference are presented without any quantitative results, tables, error bars, ablation studies, or dataset details; this makes it impossible to evaluate whether the dual-decoder unification actually delivers the stated benefits or whether the speed-accuracy trade-off is supported.
- Abstract: the load-bearing assumption that sharing object-level queries between the 2D open-set decoder and the 3D regression decoder produces unified target-level alignment without additional post-processing or dataset-specific tuning is stated but not accompanied by any verification mechanism or counter-example analysis in the provided description.
minor comments (1)
- Abstract: the title refers to 'Road Anomaly Detection' while the body describes 3D object detection; a brief clarification of how open-set detection maps to anomaly detection would improve consistency.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that strengthening the abstract with quantitative support and clarification on the shared-query mechanism will improve the manuscript. We address each point below and will make the corresponding revisions.
read point-by-point responses
-
Referee: Abstract: the central claims of SOTA accuracy under closed- and open-set protocols and real-time inference are presented without any quantitative results, tables, error bars, ablation studies, or dataset details; this makes it impossible to evaluate whether the dual-decoder unification actually delivers the stated benefits or whether the speed-accuracy trade-off is supported.
Authors: We acknowledge this limitation of the current abstract. In the revision we will add concise quantitative highlights (e.g., closed-set mAP, open-set AUROC, and FPS on the primary stereo benchmarks) together with the dataset names, while remaining within abstract length constraints. This will allow readers to directly assess the claimed speed-accuracy benefits of the dual-decoder design. revision: yes
-
Referee: Abstract: the load-bearing assumption that sharing object-level queries between the 2D open-set decoder and the 3D regression decoder produces unified target-level alignment without additional post-processing or dataset-specific tuning is stated but not accompanied by any verification mechanism or counter-example analysis in the provided description.
Authors: The full manuscript contains ablation studies and comparative results that verify the unified alignment achieved by shared queries without extra post-processing. To make this explicit already in the abstract, we will append a short clause referencing that the design is validated by experiments on public benchmarks. A brief counter-example discussion can also be added to the introduction if the referee considers it necessary. revision: partial
Circularity Check
No significant circularity
full rationale
The manuscript describes an architectural proposal (dual lightweight decoders sharing object-level queries) whose performance claims rest entirely on empirical benchmark comparisons under closed-set and open-set protocols. No equations, fitted parameters, or first-principles derivations are presented that could reduce to self-definition or to a fitted input relabeled as a prediction. The central result is therefore an empirical observation rather than a closed logical loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
3dos: Towards 3d open set learning – benchmark- ing and understanding semantic novelty detection on point clouds.arXiv e-prints, 2022
Antonio Alliegro, Francesco Cappio Borlino, and Tatiana Tommasi. 3dos: Towards 3d open set learning – benchmark- ing and understanding semantic novelty detection on point clouds.arXiv e-prints, 2022. 3
2022
-
[2]
Coda: Col- laborative novel box discovery and cross-modal alignment for open-vocabulary 3d object detection.Advances in Neu- ral Information Processing Systems, 36, 2024
Yang Cao, Zeng Yihan, Hang Xu, and Dan Xu. Coda: Col- laborative novel box discovery and cross-modal alignment for open-vocabulary 3d object detection.Advances in Neu- ral Information Processing Systems, 36, 2024. 3
2024
-
[3]
Open-set 3d object detection
Jun Cen, Peng Yun, Junhao Cai, Michael Yu Wang, and Ming Liu. Open-set 3d object detection. In2021 International conference on 3D vision (3DV), pages 869–878. IEEE, 2021. 3
2021
-
[4]
Dsc3d: Deformable sampling constraints in stereo 3d ob- ject detection for autonomous driving.IEEE Transactions on Circuits and Systems for Video Technology, 35(3):2794– 2805, 2025
Jiawei Chen, Qi Song, Wenzhong Guo, and Rui Huang. Dsc3d: Deformable sampling constraints in stereo 3d ob- ject detection for autonomous driving.IEEE Transactions on Circuits and Systems for Video Technology, 35(3):2794– 2805, 2025. 3, 6, 7
2025
-
[5]
Yolo-world: Real-time open-vocabulary object detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xing- gang Wang, and Ying Shan. Yolo-world: Real-time open-vocabulary object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16901–16911, 2024. 3
2024
-
[6]
Generative region-language pretraining for open- ended object detection
Lin Chuang, Jiang Yi, Qu Lizhen, Yuan Zehuan, and Cai Jianfei. Generative region-language pretraining for open- ended object detection. InProceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 3
2024
-
[7]
The overlooked elephant of object detection: Open set
Akshay Dhamija, Manuel Gunther, Jonathan Ventura, and Terrance Boult. The overlooked elephant of object detection: Open set. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1021–1030, 2020. 3
2020
-
[8]
Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, and Yin Cui. Open-vocabulary object detection via vision and language knowledge distillation.arXiv preprint arXiv:2104.13921,
-
[9]
Ow-detr: Open-world detection transformer
Akshita Gupta, Sanath Narayan, KJ Joseph, Salman Khan, Fahad Shahbaz Khan, and Mubarak Shah. Ow-detr: Open-world detection transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9235–9244, 2022. 3
2022
-
[10]
Expanding low-density latent regions for open-set object detection
Jiaming Han, Yuqiang Ren, Jian Ding, Xingjia Pan, Ke Yan, and Gui-Song Xia. Expanding low-density latent regions for open-set object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9591–9600, 2022. 3
2022
-
[11]
A baseline for detect- ing misclassified and out-of-distribution examples in neural networks
Dan Hendrycks and Kevin Gimpel. A baseline for detect- ing misclassified and out-of-distribution examples in neural networks. InInternational Conference on Learning Repre- sentations, 2017. 5, 8
2017
-
[12]
Scaling out-of-distribution detection for real-world settings
Dan Hendrycks, Steven Basart, Mantas Mazeika, Andy Zou, Joseph Kwon, Mohammadreza Mostajabi, Jacob Steinhardt, and Dawn Song. Scaling out-of-distribution detection for real-world settings. InInternational Conference on Machine Learning, pages 8759–8773. PMLR, 2022. 5, 8
2022
-
[13]
Monodtr: Monocular 3d object detection with depth-aware transformer
Kuan-Chih Huang, Tsung-Han Wu, Hung-Ting Su, and Win- ston H Hsu. Monodtr: Monocular 3d object detection with depth-aware transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4012–4021, 2022. 7
2022
-
[14]
Towards open world object de- tection
KJ Joseph, Salman Khan, Fahad Shahbaz Khan, and Vi- neeth N Balasubramanian. Towards open world object de- tection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5830–5840,
-
[15]
Learning-based shape estimation with grid map patches for realtime 3d ob- ject detection for automated driving
Hendrik Konigshof and Christoph Stiller. Learning-based shape estimation with grid map patches for realtime 3d ob- ject detection for automated driving. In2020 IEEE 23rd In- ternational conference on intelligent transportation systems (ITSC), pages 1–6. IEEE, 2020. 3, 6, 7
2020
-
[16]
Realtime 3d object detection for automated driving using stereo vision and semantic information
Hendrik Konigshof, Niels Ole Salscheider, and Christoph Stiller. Realtime 3d object detection for automated driving using stereo vision and semantic information. In2019 IEEE Intelligent Transportation Systems Conference (ITSC), 2019. 3, 6, 7
2019
-
[17]
Stereo r- cnn based 3d object detection for autonomous driving
Peiliang Li, Xiaozhi Chen, and Shaojie Shen. Stereo r- cnn based 3d object detection for autonomous driving. In 2019 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), 2019. 3, 6
2019
-
[18]
Rts3d: Real- time stereo 3d detection from 4d feature-consistency em- bedding space for autonomous driving
Peixuan Li, Shun Su, and Huaici Zhao. Rts3d: Real- time stereo 3d detection from 4d feature-consistency em- bedding space for autonomous driving. InProceedings of the AAAI Conference on Artificial Intelligence, pages 1930– 1939, 2021. 6
1930
-
[19]
Monojsg: Joint semantic and geometric cost volume for monocular 3d ob- ject detection
Qing Lian, Peiliang Li, and Xiaozhi Chen. Monojsg: Joint semantic and geometric cost volume for monocular 3d ob- ject detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1070– 1079, 2022. 6
2022
-
[20]
Generative region-language pretraining for open-ended object detection
Chuang Lin, Yi Jiang, Lizhen Qu, Zehuan Yuan, and Jianfei Cai. Generative region-language pretraining for open-ended object detection. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 13958–13968, 2024. 2
2024
-
[21]
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection.arXiv preprint arXiv:2303.05499, 2023. 3
Pith/arXiv arXiv 2023
-
[22]
Yolostereo3d: A step back to 2d for efficient stereo 3d detection
Yuxuan Liu, Lujia Wang, and Ming Liu. Yolostereo3d: A step back to 2d for efficient stereo 3d detection. In2021 IEEE International Conference on Robotics and Automation (ICRA), 2021. 3, 5, 6, 7, 1
2021
-
[23]
Open-vocabulary point-cloud object detection without 3d an- notation
Yuheng Lu, Chenfeng Xu, Xiaobao Wei, Xiaodong Xie, Masayoshi Tomizuka, Kurt Keutzer, and Shanghang Zhang. Open-vocabulary point-cloud object detection without 3d an- notation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1190–1199,
-
[24]
Gupnet++: Geometry uncertainty propagation network for monocular 3d object detection.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 2024
Yan Lu, Xinzhu Ma, Lei Yang, Tianzhu Zhang, Yating Liu, Qi Chu, Tong He, Yonghui Li, and Wanli Ouyang. Gupnet++: Geometry uncertainty propagation network for monocular 3d object detection.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 2024. 6, 7
2024
-
[25]
Shiyi Mu, Zichong Gu, Hanqi Lyu, Yilin Gao, and Shugong Xu. Stereo-based 3d anomaly object detection for au- tonomous driving: A new dataset and baseline.arXiv preprint arXiv:2507.09214, 2025. 1, 2, 3, 5, 6, 7, 8
arXiv 2025
-
[26]
Side: Center-based stereo 3d detector with structure-aware in- stance depth estimation
Xidong Peng, Xinge Zhu, Tai Wang, and Yuexin Ma. Side: Center-based stereo 3d detector with structure-aware in- stance depth estimation. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 119–128, 2022. 3, 6
2022
-
[27]
Pon, Jason Ku, Chengyao Li, and Steven L
Alex D. Pon, Jason Ku, Chengyao Li, and Steven L. Waslan- der. Object-centric stereo matching for 3d object detection. In2020 IEEE International Conference on Robotics and Au- tomation (ICRA), pages 8383–8389, 2020. 6, 7
2020
-
[28]
Mon- odgp: Monocular 3d object detection with decoupled-query and geometry-error priors
Fanqi Pu, Yifan Wang, Jiru Deng, and Wenming Yang. Mon- odgp: Monocular 3d object detection with decoupled-query and geometry-error priors. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6520– 6530, 2025. 4, 5, 6
2025
-
[29]
Triangulation learn- ing network: from monocular to stereo 3d object detection
Zengyi Qin, Jinglu Wang, and Yan Lu. Triangulation learn- ing network: from monocular to stereo 3d object detection. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 7615–7623, 2019. 3, 6
2019
-
[30]
Stereo centernet-based 3d object detection for autonomous driving
Yuguang Shi, Yu Guo, Zhenqiang Mi, and Xinjie Li. Stereo centernet-based 3d object detection for autonomous driving. Neurocomputing, 471:219–229, 2022. 6
2022
-
[31]
Transformer-based stereo-aware 3d object detection from binocular images.IEEE Transactions on Intelligent Trans- portation Systems, 25(12):19675–19687, 2024
Hanqing Sun, Yanwei Pang, Jiale Cao, Jin Xie, and Xuelong Li. Transformer-based stereo-aware 3d object detection from binocular images.IEEE Transactions on Intelligent Trans- portation Systems, 25(12):19675–19687, 2024. 3, 6
2024
-
[32]
An efficient 3d object detection method based on fast guided anchor stereo rcnn.Advanced Engineering Informatics, 57:102069, 2023
Chongben Tao, Chunlin Cao, Hanjing Cheng, Zhen Gao, Xizhao Luo, Zuofeng Zhang, and Sifa Zheng. An efficient 3d object detection method based on fast guided anchor stereo rcnn.Advanced Engineering Informatics, 57:102069, 2023. 6
2023
-
[33]
Zhenyu Wang, Yali Li, Taichi Liu, Hengshuang Zhao, and Shengjin Wang. Ov-uni3detr: Towards unified open- vocabulary 3d object detection via cycle-modality propaga- tion.arXiv preprint arXiv:2403.19580, 2024. 3
arXiv 2024
-
[34]
Cora: Adapting clip for open-vocabulary detection with region prompting and anchor pre-matching
Xiaoshi Wu, Feng Zhu, Rui Zhao, and Hongsheng Li. Cora: Adapting clip for open-vocabulary detection with region prompting and anchor pre-matching. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7031–7040, 2023. 3
2023
-
[35]
Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding
Le Xue, Mingfei Gao, Chen Xing, Roberto Mart ´ın-Mart´ın, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, and Silvio Savarese. Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 1179–1189, 2023. 3
2023
-
[36]
Open vocabulary monocular 3d object detection
Jin Yao, Hao Gu, Xuweiyi Chen, Jiayun Wang, and Zezhou Cheng. Open vocabulary monocular 3d object detection. arXiv preprint arXiv:2411.16833, 2024. 1, 2, 7
arXiv 2024
-
[37]
Detclip: Dictionary-enriched visual-concept paralleled pre- training for open-world detection.Advances in Neural Infor- mation Processing Systems, 35:9125–9138, 2022
Lewei Yao, Jianhua Han, Youpeng Wen, Xiaodan Liang, Dan Xu, Wei Zhang, Zhenguo Li, Chunjing Xu, and Hang Xu. Detclip: Dictionary-enriched visual-concept paralleled pre- training for open-world detection.Advances in Neural Infor- mation Processing Systems, 35:9125–9138, 2022. 3
2022
-
[38]
Detclipv2: Scal- able open-vocabulary object detection pre-training via word- region alignment
Lewei Yao, Jianhua Han, Xiaodan Liang, Dan Xu, Wei Zhang, Zhenguo Li, and Hang Xu. Detclipv2: Scal- able open-vocabulary object detection pre-training via word- region alignment. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 23497–23506, 2023. 3
2023
-
[39]
Detclipv3: To- wards versatile generative open-vocabulary object detection
Lewei Yao, Renjie Pi, Jianhua Han, Xiaodan Liang, Hang Xu, Wei Zhang, Zhenguo Li, and Dan Xu. Detclipv3: To- wards versatile generative open-vocabulary object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27391–27401, 2024. 3
2024
-
[40]
Detect anything 3d in the wild.arXiv preprint arXiv:2504.07958, 2025
Hanxue Zhang, Haoran Jiang, Qingsong Yao, Yanan Sun, Renrui Zhang, Hao Zhao, Hongyang Li, Hongzi Zhu, and Zetong Yang. Detect anything 3d in the wild.arXiv preprint arXiv:2504.07958, 2025. 1, 2
arXiv 2025
-
[41]
Pointclip: Point cloud understanding by clip
Renrui Zhang, Ziyu Guo, Wei Zhang, Kunchang Li, Xu- peng Miao, Bin Cui, Yu Qiao, Peng Gao, and Hongsheng Li. Pointclip: Point cloud understanding by clip. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8552–8562, 2022. 3
2022
-
[42]
Monodetr: Depth- guided transformer for monocular 3d object detection
Renrui Zhang, Han Qiu, Tai Wang, Ziyu Guo, Ziteng Cui, Yu Qiao, Hongsheng Li, and Peng Gao. Monodetr: Depth- guided transformer for monocular 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9155–9166, 2023. 4, 5, 6, 8, 1
2023
-
[43]
Objects are differ- ent: Flexible monocular 3d object detection
Yunpeng Zhang, Jiwen Lu, and Jie Zhou. Objects are differ- ent: Flexible monocular 3d object detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 3289–3298, 2021. 6, 7
2021
-
[44]
Tiancheng Zhao, Peng Liu, Xuan He, Lu Zhang, and Kyu- song Lee. Real-time transformer-based open-vocabulary detection with efficient fusion head.arXiv preprint arXiv:2403.06892, 2024. 3
arXiv 2024
-
[45]
Chenming Zhu, Wenwei Zhang, Tai Wang, Xihui Liu, and Kai Chen. Object2scene: Putting objects in context for open- vocabulary 3d detection.arXiv preprint arXiv:2309.09456,
-
[46]
3 DDStereo: Efficient Dual Decoder Transformers for Stereo 3D Road Anomaly Detection Supplementary Material
-
[47]
In Table 11 and Table 12 we compare the impact of these auxiliary losses on both open-set and closed-set detection, reporting results at Mod difficulty
Ablation of depth map and disparity loss DDStereo continues the auxiliary-supervision paradigm of disparity-map and depth-map prediction introduced in YOLOStereo3D[22] and MonoDETR[42], and adopts the same loss functions. In Table 11 and Table 12 we compare the impact of these auxiliary losses on both open-set and closed-set detection, reporting results a...
-
[48]
Figure 7 local- izes the scarecrow and lion statue, yet the scale estimates still exhibit noticeable error
Visualization Figures 7– 11 visualize open-set detections. Figure 7 local- izes the scarecrow and lion statue, yet the scale estimates still exhibit noticeable error. Figure 8 successfully detects the elephant and cougar. Figure 9 identifies the red and gray discarded metal barrels. Figure 10 presents results for large trash bins, owing to the limited vie...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.