LLM Evolution as an Industry-Scale Ecosystem: A Lifecycle Perspective on Continual Learning
Pith reviewed 2026-06-27 05:00 UTC · model grok-4.3
The pith
Industrial continual learning for LLMs should be reframed as a closed-loop versioned ecosystem where updates propagate hierarchically with capability inheritance across models and applications.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
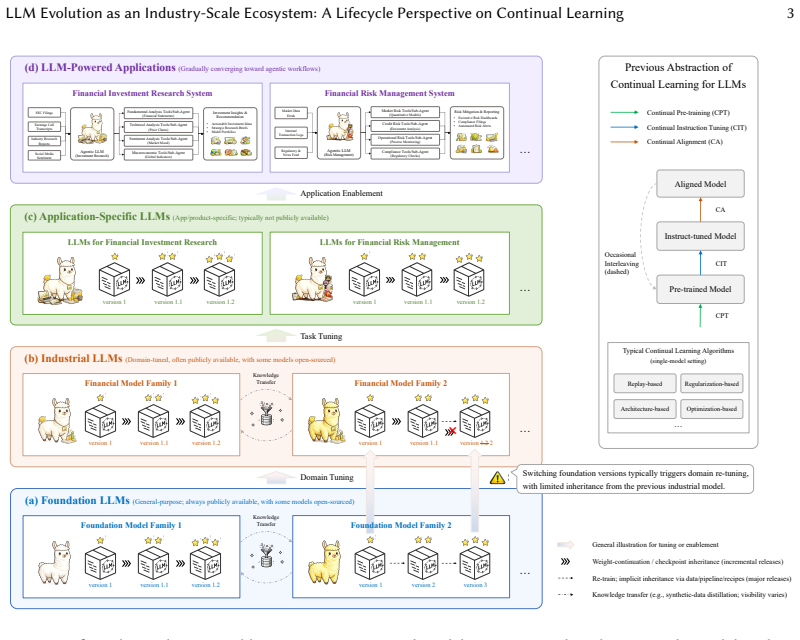
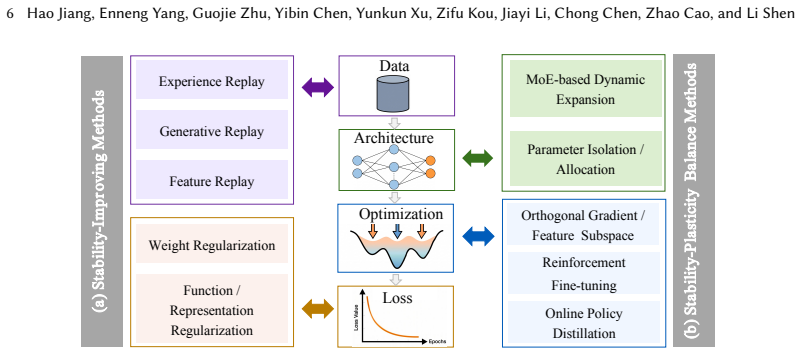
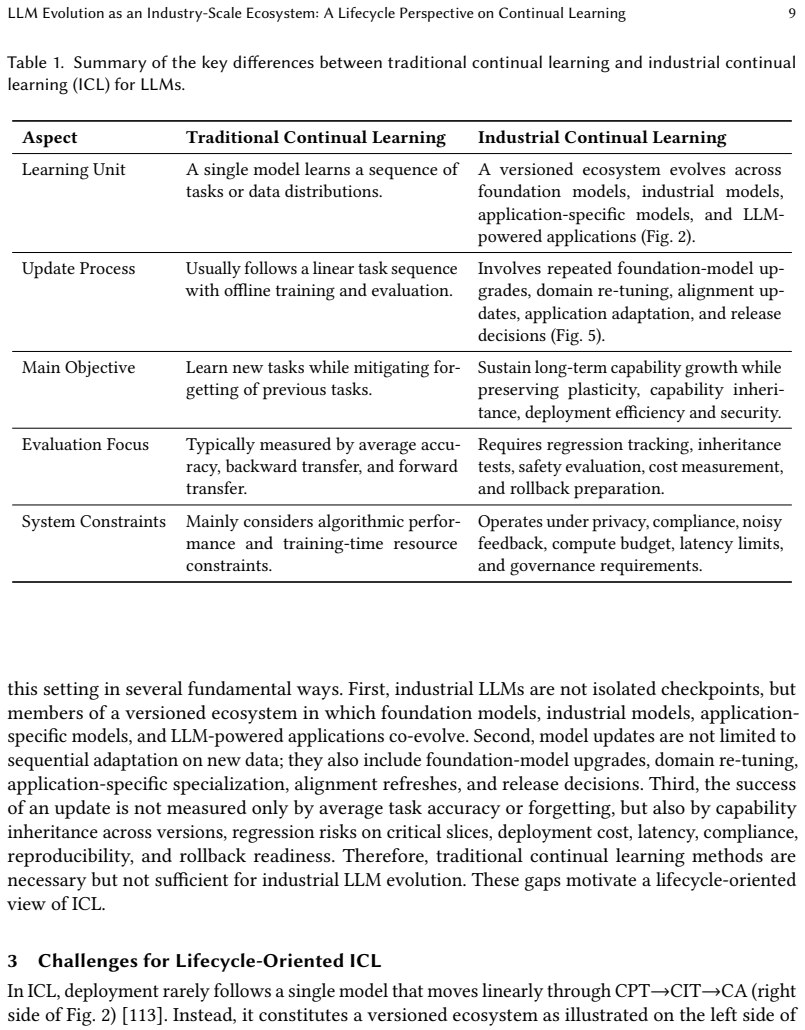
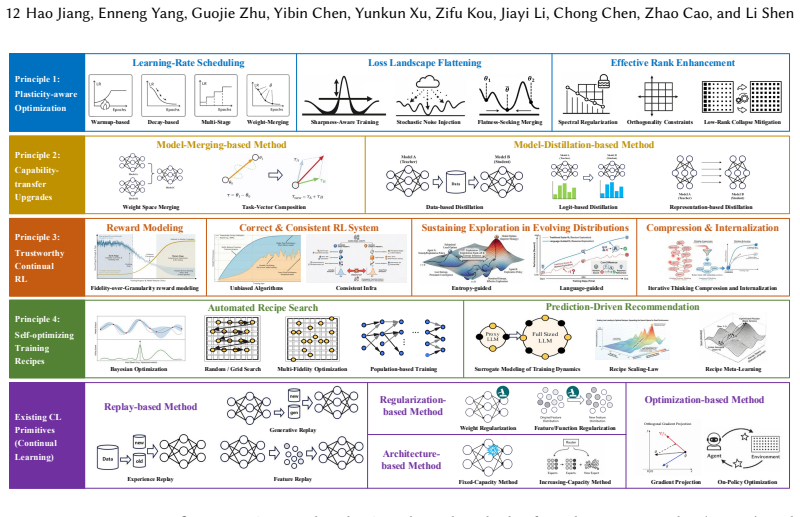
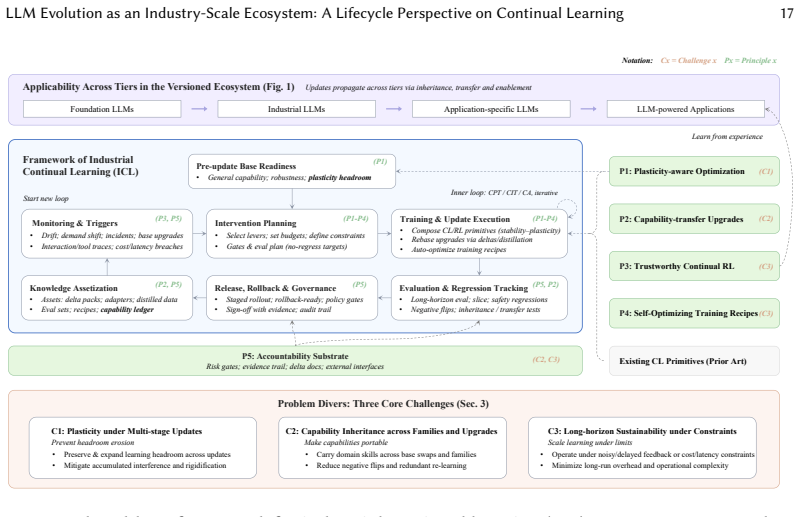
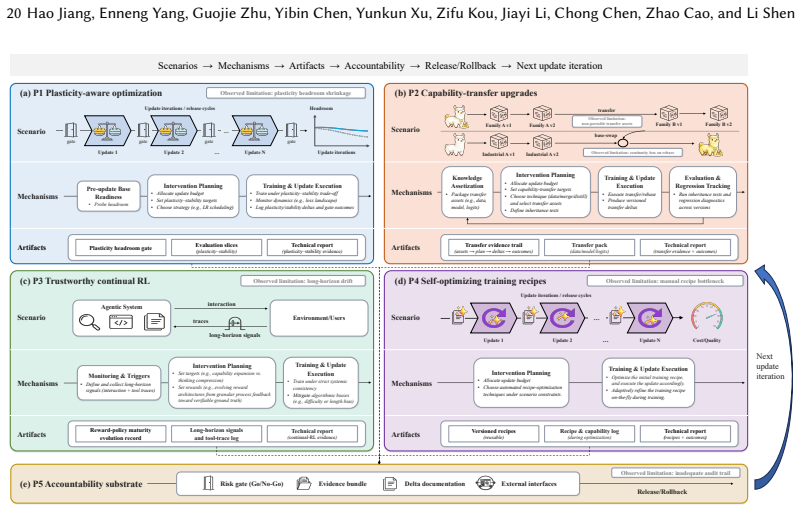
Industrial Continual Learning for LLMs should be treated as a closed-loop update-and-release problem in a versioned ecosystem where updates propagate hierarchically, with capability inheritance and transfer across versions and model families. From this view, the core challenges are repeated adaptation eroding model plasticity, foundation-model upgrades breaking capability inheritance, and sustainability constrained by deployment requirements. The technical landscape is organized around five principles: preserving plasticity headroom, treating upgrades as capability transfer, enabling trustworthy continual reinforcement learning, making training recipes self-optimizing, and building accountab
What carries the argument
The versioned ecosystem model of LLM evolution, which treats continual learning as hierarchical update propagation and capability inheritance rather than isolated retraining.
If this is right
- Repeated adaptations require explicit mechanisms to preserve plasticity headroom in models.
- Foundation model upgrades must be handled as capability transfer problems to avoid breaking downstream inheritance.
- Long-term iteration needs self-optimizing training recipes and accountability layers for sustainability.
- Trustworthy continual reinforcement learning becomes necessary for safe updates in production.
- Maturity evaluation reveals gaps that prevent current methods from supporting full industrial deployment.
Where Pith is reading between the lines
- Academic research on continual learning would benefit from incorporating versioned ecosystem constraints rather than isolated benchmarks.
- Industrial practitioners could use the proposed blueprint to structure their update pipelines hierarchically.
- Feeding deployment data back into research could close the gap between static benchmarks and real needs.
Load-bearing premise
The three identified challenges and five design principles comprehensively capture the main obstacles to real industrial deployment of continual learning for LLMs.
What would settle it
A successful long-term industrial deployment of LLMs that maintains performance and capabilities across repeated updates and model upgrades without addressing the three challenges would indicate the framework is not necessary.
Figures

read the original abstract
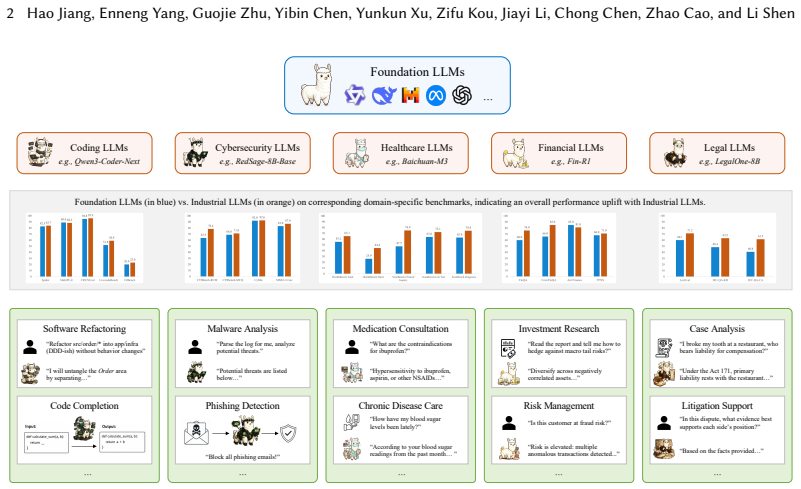
Continual learning capability is critical for Industrial LLMs, as deployed models must be continuously updated to meet evolving requirements and environments, rather than repeatedly retrained from scratch. However, most existing research focuses on improvements on static benchmarks, failing to capture real industrial needs. In this survey, we reformulate Industrial Continual Learning (ICL) for LLMs as a closed-loop update-and-release problem in a versioned ecosystem, where updates propagate hierarchically to industrial, application-specific models and LLM-powered applications, with capability inheritance and transfer across versions and model families. From this ecosystem perspective, we identify three core challenges: repeated adaptation erodes model plasticity, foundation-model upgrades break capability inheritance, and long-term sustainability is constrained by deployment requirements. We then organize the technical landscape of ICL around five lifecycle design principles: preserving plasticity headroom, treating upgrades as capability transfer, enabling trustworthy continual reinforcement learning, making training recipes self-optimizing, and building accountability as a base layer for long-term iteration. For each principle, we synthesize representative technical directions. Finally, we evaluate the maturity of each principle and its technical components via an evidence-based lens, identify key gaps hindering real-world deployment, and outline a practical ICL deployment blueprint and a pathway for feeding industrial realities back into academic research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper surveys continual learning for industrial LLMs and reframes it as a closed-loop update-and-release problem in a versioned ecosystem, where updates propagate hierarchically with capability inheritance across versions and model families. It extracts three core challenges (plasticity erosion from repeated adaptation, upgrade breakage from foundation-model changes, and sustainability constraints) and organizes existing work around five lifecycle design principles (preserving plasticity headroom, treating upgrades as capability transfer, enabling trustworthy continual RL, self-optimizing training recipes, and accountability as a base layer). The manuscript synthesizes technical directions under each principle, evaluates maturity via an evidence-based lens, identifies deployment gaps, and outlines a practical blueprint plus a feedback pathway from industry to academia.
Significance. If the reframing is adopted, the work supplies a structured lens that could redirect academic continual-learning research toward industrial lifecycle realities rather than static benchmarks. The explicit mapping of challenges to principles and the maturity assessment provide a concrete starting point for prioritizing research that addresses deployment constraints such as versioned inheritance and long-term sustainability.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, including the recognition of its reframing of industrial continual learning as a closed-loop ecosystem problem and the structured mapping of challenges to design principles. We appreciate the recommendation to accept.
Circularity Check
No significant circularity identified
full rationale
The paper is a literature survey that reformulates Industrial Continual Learning as a closed-loop ecosystem perspective and proposes three challenges plus five design principles as an organizing lens for synthesizing existing work. No derivations, equations, fitted parameters, predictions, or self-referential reductions appear in the text; the central contribution is explicitly framed as a reframing rather than a quantity derived from prior results by the same authors. The analysis is therefore self-contained against external benchmarks with no load-bearing steps that reduce to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Continual learning research on static benchmarks fails to capture industrial deployment constraints
- domain assumption Updates propagate hierarchically with capability inheritance across versions and model families
Reference graph
Works this paper leans on
-
[1]
Istabrak Abbes, Gopeshh Subbaraj, Matthew Riemer, et al. 2025. Revisiting replay and gradient alignment for continual pre-training of large language models.arXiv:2508.01908(2025)
arXiv 2025
-
[2]
Sayanta Adhikari, Sanjay Agrawal, and Vivek Sembium. 2025. FR-LoRA: Fisher Regularized LoRA for Multilingual Continual Learning. InCIKM
2025
-
[3]
Meta AI. 2025. The llama 4 herd: The beginning of a new era of natively multimodal ai innovation. https: //ai.meta.com/blog/llama-4-multimodal-intelligence/ Published: 5 April 2025
2025
-
[4]
Rio Akizuki, Yuya Kudo, Nozomu Yoshinari, et al. 2025. Surrogate benchmarks for model merging optimization. arXiv:2509.02555(2025)
Pith/arXiv arXiv 2025
-
[5]
Rahaf Aljundi, Eugene Belilovsky, Tinne Tuytelaars, Laurent Charlin, Massimo Caccia, Min Lin, and Lucas Page-Caccia
-
[6]
Online continual learning with maximal interfered retrieval.NeurIPS32 (2019), 11849–11860
2019
-
[7]
Lama Alssum, Hani Itani, Hasan Abed Al Kader Hammoud, et al . 2025. Unforgotten Safety: Preserving Safety Alignment of Large Language Models with Continual Learning. arXiv:2512.10150
arXiv 2025
-
[8]
Anthropic. 2025. Responsible Scaling Policy (Version 2.2). https://www.anthropic.com/responsible-scaling-policy Effective: 14 May 2025
2025
-
[9]
Vladimir Araujo, Marie-Francine Moens, and Tinne Tuytelaars. 2024. Learning to Route for Dynamic Adapter Composition in Continual Learning with Language Models. arXiv:2408.09053
arXiv 2024
-
[10]
Jihwan Bang, Heesu Kim, YoungJoon Yoo, Jung-Woo Ha, and Jonghyun Choi. 2021. Rainbow memory: Continual learning with a memory of diverse samples.CVPR(2021), 8218–8227
2021
-
[11]
Yoshua Bengio. 2012. Practical Recommendations for Gradient-Based Training of Deep Architectures.Lecture Notes in Computer Science(2012), 437–478
2012
-
[12]
Junbum Cha, Sanghyuk Chun, Kyungjae Lee, et al . 2021. Swad: Domain generalization by seeking flat minima. NeurIPS34 (2021), 22405–22418
2021
-
[13]
Arslan Chaudhry, Naeemullah Khan, Puneet Dokania, and Philip Torr. 2020. Continual learning in low-rank orthogonal subspaces.NeurIPS33 (2020), 9900–9911
2020
-
[14]
Chen Chen, Ruizhe Li, Yuchen Hu, Yuanyuan Chen, Chengwei Qin, and Qiang Zhang. 2024. Overcoming catastrophic forgetting by exemplar selection in task-oriented dialogue system.ACL(2024), 48–61
2024
-
[15]
Howard Chen, Noam Razin, Karthik Narasimhan, et al . 2025. Retaining by doing: The role of on-policy data in mitigating forgetting.arXiv:2510.18874(2025)
arXiv 2025
-
[16]
Wuyang Chen, Yanqi Zhou, Nan Du, Yanping Huang, James Laudon, Zhifeng Chen, and Claire Cui. 2023. Lifelong language pretraining with distribution-specialized experts. InICML. PMLR, 5383–5395
2023
-
[17]
Daixuan Cheng, Shaohan Huang, Xuekai Zhu, Bo Dai, Wayne Xin Zhao, Zhenliang Zhang, and Furu Wei. 2025. Reasoning with exploration: An entropy perspective.arXiv:2506.14758(2025)
Pith/arXiv arXiv 2025
-
[18]
Clément Christophe, Praveen K Kanithi, Tathagata Raha, et al . 2024. Med42-v2: A Suite of Clinical LLMs. arXiv:2408.06142
arXiv 2024
-
[19]
Pierre Colombo, Telmo Pires, Malik Boudiaf, et al. 2024. SaulLM-54B & SaulLM-141B: Scaling Up Domain Adaptation for the Legal Domain. arXiv:2407.19584
arXiv 2024
-
[20]
DeepSeek-AI, Qihao Zhu, Daya Guo, et al. 2024. DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence. arXiv:2406.11931. 24 Hao Jiang, Enneng Yang, Guojie Zhu, Yibin Chen, Yunkun Xu, Zifu Kou, Jiayi Li, Chong Chen, Zhao Cao, and Li Shen
Pith/arXiv arXiv 2024
-
[21]
Department for Science, Innovation and Technology and AI Safety Institute. 2024. AI Safety Institute approach to evaluations. https://www.gov.uk/government/publications/ai-safety-institute-approach-to-evaluations Published: 9 February 2024
2024
-
[22]
Xuanwen Ding, Jie Zhou, Liang Dou, Qin Chen, Yuanbin Wu, Arlene Chen, and Liang He. 2024. Boosting Large Language Models with Continual Learning for Aspect-based Sentiment Analysis. InFindings of the Association for Computational Linguistics: EMNLP 2024 (Findings of ACL, Vol. EMNLP 2024). Association for Computational Linguistics, 4367–4377
2024
-
[23]
Fernando Hernandez-Garcia, Qingfeng Lan, et al
Shibhansh Dohare, J. Fernando Hernandez-Garcia, Qingfeng Lan, et al. 2024. Loss of plasticity in deep continual learning.Nature632, 8026 (2024), 768–774
2024
-
[24]
Guodong Du, Xuanning Zhou, Junlin Li, et al. 2025. Knowledge grafting of large language models.arXiv:2505.18502 (2025)
arXiv 2025
-
[25]
Jessica Maria Echterhoff, Fartash Faghri, Raviteja Vemulapalli, Ting-Yao Hu, Chun-Liang Li, Oncel Tuzel, and Hadi Pouransari. 2024. Muscle: A model update strategy for compatible llm evolution. InFindings of EMNLP. 7320–7332
2024
-
[26]
Mehrdad Farajtabar, Navid Azizan, Alex Mott, and Ang Li. 2020. Orthogonal gradient descent for continual learning. InAISTATS. PMLR, 3762–3773
2020
-
[27]
Zhiwei Fei, Songyang Zhang, Xiaoyu Shen, et al . 2025. InternLM-Law: An Open-Sourced Chinese Legal Large Language Model. InCOLING
2025
-
[28]
Pierre Foret, Ariel Kleiner, Hossein Mobahi, et al. 2021. Sharpness-Aware Minimization for Efficiently Improving Generalization. InICLR
2021
-
[29]
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé Iii, and Kate Crawford. 2021. Datasheets for datasets.Commun. ACM64, 12 (2021), 86–92
2021
-
[30]
Varun Godbole, George E Dahl, Justin Gilmer, et al . 2023. Deep learning tuning playbook. Preprint at https: //github.com/google-research/tuning_playbook
2023
-
[31]
Google DeepMind. 2025. Frontier Safety Framework (Version 3.0). https://storage.googleapis.com/deepmind-media/ DeepMind.com/Blog/strengthening-our-frontier-safety-framework/frontier-safety-framework_3.pdf Published: 22 September 2025
2025
-
[32]
Priya Goyal, Piotr Dollár, Ross Girshick, et al . 2017. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv:1706.02677(2017)
Pith/arXiv arXiv 2017
-
[33]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. 2025. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.Nature645, 8081 (2025), 633–638
2025
-
[34]
Yiduo Guo, Jie Fu, Huishuai Zhang, Dongyan Zhao, and Yikang Shen. 2024. Efficient continual pre-training by mitigating the stability gap. InarXiv preprint arXiv:2406.14833
arXiv 2024
-
[35]
Suchin Gururangan, Ana Marasović, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A Smith
-
[36]
Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks. InACL. 8342–8360
-
[37]
Naicheng He, Kaicheng Guo, Arjun Prakash, Saket Tiwari, Ruo Yu Tao, Tyrone Serapio, Amy Greenwald, and George Konidaris. 2025. Spectral Collapse Drives Loss of Plasticity in Deep Continual Learning.arXiv:2509.22335(2025)
Pith/arXiv arXiv 2025
-
[38]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network.arXiv:1503.02531 (2015)
Pith/arXiv arXiv 2015
-
[39]
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, et al. 2022. Training compute-optimal large language models. arXiv:2203.15556(2022)
Pith/arXiv arXiv 2022
-
[40]
Joey Hong, Kang Liu, Zhan Ling, Jiecao Chen, and Sergey Levine. 2025. Natural Language Actor-Critic: Scalable Off-Policy Learning in Language Space.arXiv:2512.04601(2025)
arXiv 2025
-
[41]
Jianheng Huang, Leyang Cui, Ante Wang, Chengyi Yang, Xinting Liao, Linfeng Song, Junfeng Yao, and Jinsong Su
-
[42]
Mitigating Catastrophic Forgetting in Large Language Models with Self-Synthesized Rehearsal, In ACL.ACL, 1416–1428
-
[43]
Libo Huang, Yan Zeng, Chuanguang Yang, Zhulin An, Boyu Diao, and Yongjun Xu. 2024. eTag: Class-Incremental Learning via Embedding Distillation and Task-Oriented Generation. InAAAI, Vol. 38. 12591–12599
2024
-
[44]
Quzhe Huang, Mingxu Tao, Chen Zhang, et al. 2023. Lawyer LLaMA Technical Report. arXiv:2305.15062
arXiv 2023
-
[45]
Zitong Huang, Ze Chen, Zhixing Chen, et al . 2024. Learning prompt with distribution-based feature replay for few-shot class-incremental learning.arXiv:2401.01598(2024)
arXiv 2024
-
[46]
Tingfeng Hui, Zhenyu Zhang, Shuohuan Wang, et al. 2024. Upcycling Instruction Tuning from Dense to Mixture-of- Experts via Parameter Merging. arXiv:2410.01610
arXiv 2024
-
[47]
Frank Hutter, Holger H Hoos, Kevin Leyton-Brown, et al. 2011. SMAC: Sequential model-based algorithm configura- tion
2011
-
[48]
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, et al. 2023. Editing models with task arithmetic. InICLR. LLM Evolution as an Industry-Scale Ecosystem: A Lifecycle Perspective on Continual Learning 25
2023
-
[49]
Ahmet Iscen, Jeffrey Zhang, Svetlana Lazebnik, and Cordelia Schmid. 2020. Memory-efficient incremental learning through feature adaptation. InECCV. Springer, 699–715
2020
-
[50]
Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. 2018. Averaging weights leads to wider optima and better generalization.arXiv:1803.05407(2018)
Pith/arXiv arXiv 2018
-
[51]
Kishaan Jeeveswaran, Prashant Shivaram Bhat, Bahram Zonooz, and Elahe Arani. 2023. BiRT: Bio-inspired Replay in Vision Transformers for Continual Learning. InICML. PMLR, 14817–14835
2023
-
[52]
Yu Jin, Jie Liu, and Shaowei Chen. 2025. Multi-LoRA continual learning based instruction tuning framework for universal information extraction.Know.-Based Syst.308, C (2025)
2025
-
[53]
Jared Kaplan, Sam McCandlish, Tom Henighan, et al. 2020. Scaling laws for neural language models.arXiv:2001.08361 (2020)
Pith/arXiv arXiv 2020
-
[54]
Aran Komatsuzaki, Joan Puigcerver, James Lee-Thorp, et al. 2023. Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints. arXiv:2212.05055
arXiv 2023
-
[55]
Song Lai, Haohan Zhao, Rong Feng, Changyi Ma, Wenzhuo Liu, Hongbo Zhao, Xi Lin, Dong Yi, Qingfu Zhang, Hongbin Liu, et al. 2025. Reinforcement fine-tuning naturally mitigates forgetting in continual post-training.arXiv preprint arXiv:2507.05386(2025)
arXiv 2025
-
[56]
Ao Li, Bin Yan, Bingfeng Cai, et al. 2025. QuarkMed Medical Foundation Model Technical Report. arXiv:2508.11894
arXiv 2025
-
[57]
Haitao Li, Yifan Chen, Shuo Miao, Qian Dong, Jia Chen, Yiran Hu, Junjie Chen, Minghao Qin, Qingyao Ai, Yiqun Liu, et al. 2026. LegalOne: A Family of Foundation Models for Reliable Legal Reasoning.arXiv:2602.00642(2026)
arXiv 2026
-
[58]
Shupeng Li, Weipeng Lu, Linyun Liu, et al. 2025. QianfanHuijin Technical Report: A Novel Multi-Stage Training Paradigm for Finance Industrial LLMs. arXiv:2512.24314
arXiv 2025
-
[59]
Yunshui Li, Yiyuan Ma, Shen Yan, et al . 2025. Model Merging in Pre-training of Large Language Models. arXiv:2505.12082
arXiv 2025
-
[60]
Yusheng Liao, Chaoyi Wu, Junwei Liu, et al. 2025. EHR-R1: A Reasoning-Enhanced Foundational Language Model for Electronic Health Record Analysis. arXiv:2510.25628
arXiv 2025
-
[61]
Sen Lin, Li Yang, Deliang Fan, et al . 2022. TRGP: Trust Region Gradient Projection for Continual Learning. arXiv:2202.02931
arXiv 2022
-
[62]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. 2025. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv:2512.02556 (2025)
Pith/arXiv arXiv 2025
-
[63]
Hong Liu, Sang Michael Xie, Zhiyuan Li, and Tengyu Ma. 2023. Same pre-training loss, better downstream: Implicit bias matters for language models. InICML. PMLR, 22188–22214
2023
-
[64]
Jiacai Liu, Yingru Li, Yuqian Fu, Jiawei Wang, Qian Liu, and Yu Shen. 2025. When Speed Kills Stability: Demystifying RL Collapse from the Training-Inference Mismatch. https://richardli.xyz/rl-collapse
2025
-
[65]
Jingyuan Liu, Jianlin Su, Xingcheng Yao, et al. 2025. Muon is Scalable for LLM Training. arXiv:2502.16982
Pith/arXiv arXiv 2025
-
[66]
Qian Liu, Xiaosen Zheng, Niklas Muennighoff, et al. 2024. Regmix: Data mixture as regression for language model pre-training.arXiv:2407.01492(2024)
arXiv 2024
-
[67]
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. 2025. Understanding r1-zero-like training: A critical perspective.arXiv:2503.20783(2025)
Pith/arXiv arXiv 2025
-
[68]
Zhaowei Liu, Xin Guo, Zhi Yang, et al . 2025. Fin-R1: A Large Language Model for Financial Reasoning through Reinforcement Learning. arXiv:2503.16252
arXiv 2025
-
[69]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. InICLR
2019
-
[70]
Wenhan Ma, Hailin Zhang, Liang Zhao, Yifan Song, Yudong Wang, Zhifang Sui, and Fuli Luo. 2025. Stabilizing moe reinforcement learning by aligning training and inference routers.arXiv:2510.11370(2025)
arXiv 2025
-
[71]
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. 2019. Model cards for model reporting. InProceedings of the conference on fairness, accountability, and transparency. 220–229
2019
-
[72]
Le, et al
Arvind Neelakantan, Luke Vilnis, Quoc V. Le, et al. 2015. Adding Gradient Noise Improves Learning for Very Deep Networks. InICLR
2015
-
[73]
OpenAI. 2025. Preparedness Framework (Version 2). https://cdn.openai.com/pdf/18a02b5d-6b67-4cec-ab64- 68cdfbddebcd/preparedness-framework-v2.pdf Last updated: 15 April 2025
2025
-
[74]
Qwen Team. [n. d.].Qwen3-Coder-Next Technical Report. Technical Report. Qwen Team. https://github.com/QwenLM/ Qwen3-Coder/blob/main/qwen3_coder_next_tech_report.pdf Accessed: 2026-02-03
2026
-
[75]
Anastasia Razdaibiedina, Yuning Mao, Rui Hou, et al. 2023. Progressive Prompts: Continual Learning for Language Models. arXiv:2301.12314
arXiv 2023
-
[76]
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. 2017. icarl: Incremental classifier and representation learning.CVPR(2017), 2001–2010. 26 Hao Jiang, Enneng Yang, Guojie Zhu, Yibin Chen, Yunkun Xu, Zifu Kou, Jiayi Li, Chong Chen, Zhao Cao, and Li Shen
2017
-
[77]
Filippo Rinaldi, Giacomo Capitani, Lorenzo Bonicelli, et al. 2025. Update Your Transformer to the Latest Release: Re-Basin of Task Vectors. InICML
2025
-
[78]
Anthony Robins. 1995. Catastrophic forgetting, rehearsal and pseudorehearsal.Connection Science7, 2 (1995), 123–146
1995
-
[79]
Gobinda Saha, Isha Garg, and Kaushik Roy. 2021. Gradient Projection Memory for Continual Learning. arXiv:2103.09762
arXiv 2021
-
[80]
Gobinda Saha and Kaushik Roy. 2023. Continual Learning with Scaled Gradient Projection. arXiv:2302.01386
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.