FreeStory: Training-Free Character Consistency for Free-Form Visual Storytelling
Pith reviewed 2026-06-26 00:08 UTC · model grok-4.3
The pith
FreeStory maintains character consistency in visual storytelling under free-form prompts by entity-grounded feature reuse without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
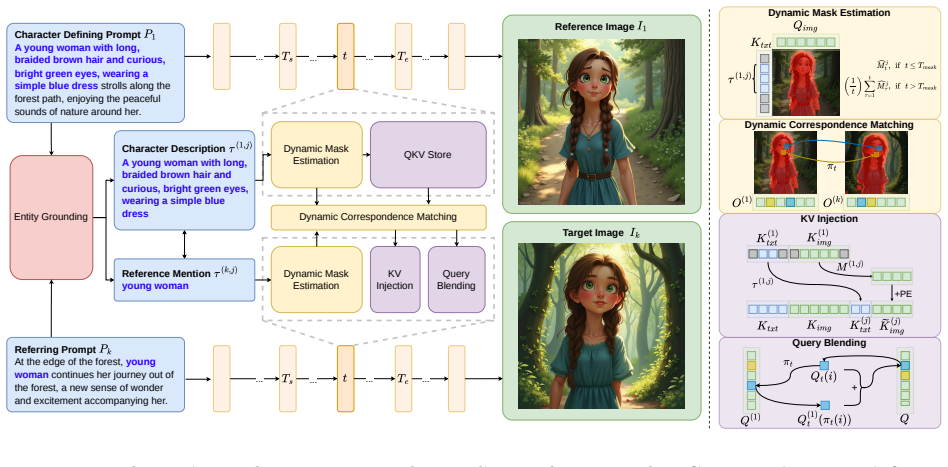
Character consistency under free-form prompts can be achieved by reformulating the task as entity-grounded feature reuse: reference mentions are associated with their initial character descriptions, after which dynamic character masks, correspondence-aware feature matching, key-value injection, and query blending are combined to preserve identity while retaining generation diversity.
What carries the argument
Entity-grounded feature reuse, which links prompt references to character descriptions and selectively reuses attention features through masks, matching, injection, and blending.
If this is right
- Character appearance remains consistent even when prompts introduce a character once and later refer to it indirectly.
- Generation diversity is retained while identity preservation improves over prior training-free baselines.
- A new benchmark enables direct measurement of consistency on both single- and multi-character free-form stories.
- State-of-the-art consistency among training-free methods is reached on both structured and free-form prompt sets.
Where Pith is reading between the lines
- The association step could be extended to handle longer narratives with multiple ambiguous references.
- Similar selective feature reuse might reduce repetition needs in other text-to-image or text-to-video pipelines.
- If the linking step scales, prompting interfaces for story generation could shift away from exhaustive repeated descriptions.
Load-bearing premise
The method assumes that reference mentions in free-form prompts can be reliably associated with their corresponding character descriptions without training or external supervision.
What would settle it
Running the method on free-form prompts that use only pronouns or short references and observing visibly inconsistent character appearances across the generated image sequence would falsify the consistency claim.
Figures











read the original abstract
Visual storytelling aims to generate image sequences that are both aligned with narrative prompts and consistent in character appearance across images. Recent training-free methods improve character consistency by reusing attention features, but rely on structured prompts where full character descriptions are repeated in every prompt. This assumption simplifies the task but deviates from natural storytelling, where characters are typically introduced once and later referred to using pronouns or type-based expressions. We propose \textbf{FreeStory}, a training-free framework that reformulates character consistency under free-form prompts as entity-grounded feature reuse. Our method associates reference mentions with their corresponding character descriptions and combines dynamic character masks, correspondence-aware feature matching, key-value injection, and query blending to preserve identity while retaining generation diversity. We also introduce \textbf{FreeStoryBench}, a benchmark for this setting that includes both single- and multi-character stories. Experiments show that FreeStory achieves state-of-the-art performance among training-free methods on structured benchmarks and stronger overall consistency over baselines under free-form prompts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FreeStory, a training-free framework for maintaining character consistency in visual storytelling under free-form prompts (where characters are introduced once and later referenced via pronouns or type expressions). It reformulates consistency as entity-grounded feature reuse via mention-to-description association, dynamic character masks, correspondence-aware feature matching, key-value injection, and query blending. The work also introduces FreeStoryBench (covering single- and multi-character stories) and claims state-of-the-art performance among training-free methods on structured benchmarks plus stronger overall consistency under free-form prompts.
Significance. If the core association step proves reliable, the approach would meaningfully extend training-free consistency techniques beyond the restrictive structured-prompt regime used by prior work, supporting more natural narrative generation. The new benchmark is a constructive addition for evaluating free-form settings.
major comments (2)
- [Method (association module)] The reference-to-character association step (described in the method) is load-bearing for all downstream components (dynamic masks, correspondence-aware matching, KV injection, query blending) yet no accuracy, precision/recall, or error analysis is reported for it. Association errors on multi-character or pronoun-heavy stories would directly falsify the consistency gains claimed on FreeStoryBench.
- [Experiments] Experiments section reports SOTA claims and stronger consistency under free-form prompts but supplies no error bars, statistical significance tests, or ablations isolating the association module versus the other proposed components, leaving the support for the central claim unassessable from the provided details.
minor comments (2)
- [Method] Notation for the association and matching steps could be clarified with a short pseudocode or diagram to make the entity-grounded reuse pipeline easier to follow.
- [Abstract] The abstract would benefit from one sentence summarizing how the unsupervised association is implemented.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important aspects of the association module and experimental reporting that we will address in revision.
read point-by-point responses
-
Referee: [Method (association module)] The reference-to-character association step (described in the method) is load-bearing for all downstream components (dynamic masks, correspondence-aware matching, KV injection, query blending) yet no accuracy, precision/recall, or error analysis is reported for it. Association errors on multi-character or pronoun-heavy stories would directly falsify the consistency gains claimed on FreeStoryBench.
Authors: We agree that a direct quantitative evaluation of the association step would strengthen the claims. The module relies on mention-to-description matching within the free-form prompt setting, and while end-to-end consistency results on FreeStoryBench (including multi-character cases) provide supporting evidence, we did not report isolated precision/recall or error rates. In the revision we will add a dedicated subsection with accuracy metrics computed on a set of annotated free-form prompts, plus qualitative error cases. revision: yes
-
Referee: [Experiments] Experiments section reports SOTA claims and stronger consistency under free-form prompts but supplies no error bars, statistical significance tests, or ablations isolating the association module versus the other proposed components, leaving the support for the central claim unassessable from the provided details.
Authors: The original experiments focused on comparative consistency scores across methods and benchmarks. We acknowledge the value of statistical reporting and component ablations. In the revised manuscript we will report standard deviations over multiple random seeds, include paired significance tests where appropriate, and add an ablation study that measures the incremental contribution of the association module when combined with the remaining components. revision: yes
Circularity Check
No circularity: method is procedural description without equations or self-referential derivations
full rationale
The paper describes a training-free framework (FreeStory) that associates mentions with character descriptions and applies dynamic masks, feature matching, KV injection, and query blending. No equations, fitted parameters, or first-principles derivations are present in the abstract or described claims. Performance is evaluated empirically on benchmarks rather than derived from inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify core steps. The association step is a design choice whose accuracy is not quantified here, but that is an empirical limitation, not a circular reduction of any claimed result to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Blue noise for diffusion models
Omri Avrahami, Amir Hertz, Yael Vinker, Moab Arar, Shlomi Fruchter, Ohad Fried, Daniel Cohen-Or, and Dani Lischinski. The chosen one: Consistent characters in text-to-image diffusion models. InACM SIGGRAPH 2024 Conference Papers, SIGGRAPH ’24, New York, NY, USA, 2024. Association for Computing Machinery. ISBN 9798400705250. URL https://doi.org/10.1145/364...
-
[2]
Vista: Vi- sual storytelling using multi-modal adapters for text-to-image diffusion models
Sibo Dong, Ismail Shaheen, Maggie Shen, Rupayan Mallick, and Sarah Adel Bargal. Vista: Vi- sual storytelling using multi-modal adapters for text-to-image diffusion models. InProceedings of the Winter Conference on Applications of Computer Vision (WACV), March 2026. 4
2026
-
[3]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis. InProceedings of the 41st International Conference on Machine Learning, ICML...
2024
-
[4]
Improved visual story generation with adaptive context modeling
Zhangyin Feng, Yuchen Ren, Xinmiao Yu, Xiaocheng Feng, Duyu Tang, Shuming Shi, and Bing Qin. Improved visual story generation with adaptive context modeling. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Findings of the Association for Computa- tional Linguistics: ACL 2023, pages 4939–4955, Toronto, Canada, July 2023. Association for Com...
2023
-
[5]
Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola
Stephanie Fu, Netanel Y. Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola. Dreamsim: learning new dimensions of human visual similarity using syn- thetic data. InProceedings of the 37th International Conference on Neural Information Pro- cessing Systems, NIPS ’23, Red Hook, NY, USA, 2023. Curran Associates Inc. 10
2023
-
[6]
Unleashing diffusion transformers for visual correspondence by modulating massive acti- vations
Chaofan Gan, Yuanpeng Tu, Xi Chen, Tieyuan Chen, Yuxi Li, Mehrtash Harandi, and Weiyao Lin. Unleashing diffusion transformers for visual correspondence by modulating massive acti- vations. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
-
[7]
URLhttps://openreview.net/forum?id=s3MwCBuqav. 7
-
[8]
Interactive story visualization with multiple characters
Yuan Gong, Youxin Pang, Xiaodong Cun, Menghan Xia, Yingqing He, Haoxin Chen, Longyue Wang, Yong Zhang, Xintao Wang, Ying Shan, and Yujiu Yang. Interactive story visualization with multiple characters. InSIGGRAPH Asia 2023 Conference Papers, SA ’23, New York, NY, USA, 2023. Association for Computing Machinery. ISBN 9798400703157. doi: 10.1145/ 3610548.3618184. 4
arXiv 2023
-
[9]
Huiguo He, Huan Yang, Zixi Tuo, Yuan Zhou, Qiuyue Wang, Yuhang Zhang, Zeyu Liu, Wenhao Huang, Hongyang Chao, and Jian Yin. Dreamstory: Open-domain story visualization by llm- guided multi-subject consistent diffusion.arXiv preprint arXiv:2407.12899, 2024. 4
arXiv 2024
-
[10]
CLIPScore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. CLIPScore: A reference-free evaluation metric for image captioning. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors,Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7514–7528, Online and Punta Cana, D...
2021
-
[11]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024. 1, 3, 4, 10
2024
-
[12]
Flux.1 kontext: Flow matching for in-context image generation and editing in latent space, 2025
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas Müller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext: Flow matching for in-context image ...
Pith/arXiv arXiv 2025
-
[13]
In- telligent grimm - open-ended visual storytelling via latent diffusion models
Chang Liu, Haoning Wu, Yujie Zhong, Xiaoyun Zhang, Yanfeng Wang, and Weidi Xie. In- telligent grimm - open-ended visual storytelling via latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6190–6200, June 2024. 4
2024
-
[14]
One-prompt-one-story: Free-lunch consistent text- to-image generation using a single prompt
Tao Liu, Kai Wang, Senmao Li, Joost van de Weijer, Fahad Shahbaz Khan, Shiqi Yang, Yaxing Wang, Jian Yang, and Ming-Ming Cheng. One-prompt-one-story: Free-lunch consistent text- to-image generation using a single prompt. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=cD1kl2QKv1. 1, 3, 4, 9, 10, 12
2025
-
[15]
Yuhang Ma, Wenting Xu, Chaoyi Zhao, Keqiang Sun, Qinfeng Jin, Zeng Zhao, Changjie Fan, and Zhipeng Hu. Storynizor: Consistent story generation via inter-frame synchronized and shuffled id injection.arXiv preprint arXiv:2409.19624, 2024. 4
arXiv 2024
-
[16]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khali- dov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick L...
2024
-
[17]
Nobuyuki Otsu. A threshold selection method from gray-level histograms.IEEE Transactions on Systems, Man, and Cybernetics, 9(1):62–66, 1979. doi: 10.1109/TSMC.1979.4310076. 6
-
[18]
In: IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pp
Xichen Pan, Pengda Qin, Yuhong Li, Hui Xue, and Wenhu Chen. Synthesizing coherent story with auto-regressive latent diffusion models. In2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 2908–2918, 2024. doi: 10.1109/WACV57701. 2024.00290. 4
-
[19]
SDXL: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. SDXL: Improving latent diffusion models for high-resolution image synthesis. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=di52zR8xgf. 1, 3, 10
2024
-
[20]
Peng Qi, Yuhao Zhang, Yuhui Zhang, Jason Bolton, and Christopher D. Manning. Stanza: A Python natural language processing toolkit for many human languages. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations,
-
[21]
9, 27 15
URLhttps://nlp.stanford.edu/pubs/qi2020stanza.pdf. 9, 27 15
-
[22]
Reproducible scaling laws for contrastive language-image learning
Tanzila Rahman, Hsin-Ying Lee, Jian Ren, Sergey Tulyakov, Shweta Mahajan, and Leonid Si- gal. Make-a-story: Visual memory conditioned consistent story generation. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2493–2502, 2023. doi: 10.1109/CVPR52729.2023.00246. 4
-
[23]
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159, 2024. 10, 18
Pith/arXiv arXiv 2024
-
[24]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10674–10685, 2022. doi: 10.1109/ CVPR52688.2022.01042. 1, 3
arXiv 2022
-
[25]
Xiaoqian Shen and Mohamed Elhoseiny. Storygpt-v: Large language models as consistent story visualizers. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13273–13283, 2025. doi: 10.1109/CVPR52734.2025.01239. 4
-
[26]
Singfake: Singing voice deepfake detection,
Tianyi Song, Jiuxin Cao, Kun Wang, Bo Liu, and Xiaofeng Zhang. Causal-story: Local causal attention utilizing parameter-efficient tuning for visual story synthesis. InICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 3350–3354, 2024. doi: 10.1109/ICASSP48485.2024.10446420. 4
-
[27]
Emer- gent correspondence from image diffusion
LumingTang, MenglinJia, QianqianWang, ChengPerngPhoo, andBharathHariharan. Emer- gent correspondence from image diffusion. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://openreview.net/forum?id=ypOiXjdfnU. 7
2023
-
[28]
Storyimager: A unified and efficient framework for coherent story visualization and completion
Ming Tao, Bing-Kun Bao, Hao Tang, Yaowei Wang, and Changsheng Xu. Storyimager: A unified and efficient framework for coherent story visualization and completion. InComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part LVI, page 479–495, Berlin, Heidelberg, 2024. Springer-Verlag. ISBN 978-3- 03...
-
[29]
Training-free consistent text-to-image generation.ACM Trans
YoadTewel, OmriKaduri, RinonGal, YoniKasten, LiorWolf, GalChechik, andYuvalAtzmon. Training-free consistent text-to-image generation.ACM Trans. Graph., 43(4), July 2024. ISSN 0730-0301. doi: 10.1145/3658157. 1, 4, 6, 7, 10, 12
-
[30]
Jiahao Wang, Caixia Yan, Haonan Lin, and Weizhan Zhang. Oneactor: Consistent character generation via cluster-conditioned guidance.arXiv preprint arXiv:2404.10267, 2024. 4
arXiv 2024
-
[31]
Characonsist: Fine-grained consistent character generation
Mengyu Wang, Henghui Ding, Jianing Peng, Yao Zhao, Yunpeng Chen, and Yunchao Wei. Characonsist: Fine-grained consistent character generation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 16058–16067, October 2025. 4, 6, 7
2025
-
[32]
Shuai Yang, Yuying Ge, Yang Li, Yukang Chen, Yixiao Ge, Ying Shan, and Yingcong Chen. Seed-story: Multimodal long story generation with large language model.arXiv preprint arXiv:2407.08683, 2024. URLhttps://arxiv.org/abs/2407.08683. 4
arXiv 2024
-
[33]
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721, 2023. 1 16
Pith/arXiv arXiv 2023
-
[34]
Sixiao Zheng and Yanwei Fu. Temporalstory: Enhancing consistency in story visualization using spatial-temporal attention.arXiv preprint arXiv:2407.09774, 2024. 4
arXiv 2024
-
[35]
Storydiffu- sion: Consistent self-attention for long-range image and video generation
Yupeng Zhou, Daquan Zhou, Ming-Ming Cheng, Jiashi Feng, and Qibin Hou. Storydiffu- sion: Consistent self-attention for long-range image and video generation. InThe Thirty- eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps: //openreview.net/forum?id=VFqzxhINFU. 1, 4, 10, 12
2024
-
[36]
Zhengguang Zhou, Jing Li, Huaxia Li, Nemo Chen, and Xu Tang. Storymaker: Towards holistic consistent characters in text-to-image generation.arXiv preprint arXiv:2409.12576, 2024. 4
arXiv 2024
-
[37]
Dual-Generation
Zhongyang Zhu and Jie Tang. Cogcartoon: Towards practical story visualization.Int. J. Comput. Vision, 133(4):1808–1833, October 2024. ISSN 0920-5691. doi: 10.1007/ s11263-024-02267-5. 4 17 A Method A.1 Dynamic Mask Extraction Figure 4: Mean IoU between attention- derived masks and Grounded SAM seg- mentation across diffusion timesteps. To better understan...
2024
-
[38]
story_id
JSON Schema Your output must validate against this schema: ‘‘‘json [ { "story_id": 1, // Integer: Unique ID for the story. You will be given this in the task section at the end. 19 "metadata": { "title": "Story Title", // String: A human-readable title. "genre": ["Genre"], // List[String]: \eg., "Sci-Fi", "Fantasy", "Realism". "num_scenes": 3, // Integer:...
-
[39]
story_id
High-Quality Example Here is a perfect example of a single story entry. ‘‘‘json [ { "story_id": 1, "metadata": { "title": "The Curious Robot", "genre": ["Sci-Fi"], "num_scenes": 3, "num_characters": 1, "keywords": ["robot", "park", "butterfly", "curiosity"] }, "characters": [ 20 { "char_id": "c1", "category": "object", "name": "Beeper", "type": "Robot", "...
-
[40]
they" or
Core Generation Rules For story_action: - story_action should be a linguisitically sound and coherent description of the story scene, while semantic_action should be a templated version of the story_action that replaces character mentions with character placeholders. - The first story_action in the first scene should introduce the character(s) using the c...
-
[41]
story_id
TASK Generate a new, unique story entry as a single JSON object. Constraints for this story that you should follow are: - story\_id: <story_id> - num\_characters: <character_count> - Each scene must include <character_presence> from the ‘characters‘ list. - category: <character_category> - num\_scenes: 6 Respond ONLY with the single JSON object. A.2.3 Sto...
-
[43]
The nimble female archer wearing a green tunic and leather bracers begins to walk down the path, and The massive grey wolf with a distinctive white patch on his chest follows closely behind her
-
[44]
The nimble female archer wearing a green tunic and leather bracers leaps across the wet stones as The massive grey wolf with a distinctive white patch on his chest splashes through the water to stay by her side
-
[45]
The nimble female archer wearing a green tunic and leather bracers and The massive grey wolf with a distinctive white patch on his chest reach the ruins and scan the area for any signs of movement
-
[46]
The nimble female archer wearing a green tunic and leather bracers notches an arrow, while The massive grey wolf with a distinctive white patch on his chest lets out a low growl to protect her
-
[47]
V2: Single→Mix({‘mode’: ‘single’, ‘fallback’: ‘mix’})
Finally, The nimble female archer wearing a green tunic and leather bracers sits on the cliff’s edge with The massive grey wolf with a distinctive white patch on his chest as they watch the sun disappear. V2: Single→Mix({‘mode’: ‘single’, ‘fallback’: ‘mix’})
-
[49]
She begins to walk down the path, and the wolf follows closely behind her
-
[50]
The archer leaps across the wet stones as the wolf splashes through the water to stay by her side
-
[51]
They both reach the ruins and scan the area for any signs of movement
-
[52]
The archer notches an arrow, while the wolf lets out a low growl to protect her
-
[53]
V3: Single→Type({‘mode’: ‘single’, ‘fallback’: ‘type’})
Finally, she sits on the cliff’s edge with the wolf as they watch the sun disappear. V3: Single→Type({‘mode’: ‘single’, ‘fallback’: ‘type’})
-
[54]
A nimble female archer wearing a green tunic and leather bracers stands at the forest edge while a massive grey wolf with a distinctive white patch on his chest sniffs the ground nearby
-
[59]
V4: Single→Name({‘mode’: ‘single’, ‘fallback’: ‘name’})
Finally, The Archer sits on the cliff’s edge with The Wolf as they watch the sun disappear. V4: Single→Name({‘mode’: ‘single’, ‘fallback’: ‘name’})
-
[60]
Eara, The nimble female archer wearing a green tunic and leather bracers, stands at the forest edge while Silver, The massive grey wolf with a distinctive white patch on his chest, sniffs the ground nearby
-
[65]
25 V5: No Description→Type({‘mode’: ‘no_desc’, ‘fallback’: ‘type’})
Finally, Eara sits on the cliff’s edge with Silver as they watch the sun disappear. 25 V5: No Description→Type({‘mode’: ‘no_desc’, ‘fallback’: ‘type’})
-
[66]
The Archer stands at the forest edge while The Wolf sniffs the ground nearby
-
[67]
The Archer begins to walk down the path, and The Wolf follows closely behind her
-
[68]
The Archer leaps across the wet stones as The Wolf splashes through the water to stay by her side
-
[69]
The Archer and The Wolf reach the ruins and scan the area for any signs of movement
-
[70]
The Archer notches an arrow, while The Wolf lets out a low growl to protect her
-
[71]
V6: No Description→Name({‘mode’: ‘no_desc’, ‘fallback’: ‘name’})
Finally, The Archer sits on the cliff’s edge with The Wolf as they watch the sun disappear. V6: No Description→Name({‘mode’: ‘no_desc’, ‘fallback’: ‘name’})
-
[72]
Eara stands at the forest edge while Silver sniffs the ground nearby
-
[73]
Eara begins to walk down the path, and Silver follows closely behind her
-
[74]
Eara leaps across the wet stones as Silver splashes through the water to stay by her side
-
[75]
Eara and Silver reach the ruins and scan the area for any signs of movement
-
[76]
Eara notches an arrow, while Silver lets out a low growl to protect her
-
[77]
Finally, Eara sits on the cliff’s edge with Silver as they watch the sun disappear. B Implementation Details and Additional Results B.1 Background Removal for Evaluation Figure 5: Comparison of background re- moval using CarveKit and Grounded- SAM.Theexamplesillustratethreetyp- ical failure modes of CarveKit. Previous works commonly adopt CarveKit for bac...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.