Extreme Meta-Classification for Large-Scale Zero-Shot Retrieval
Pith reviewed 2026-06-25 21:44 UTC · model grok-4.3
The pith
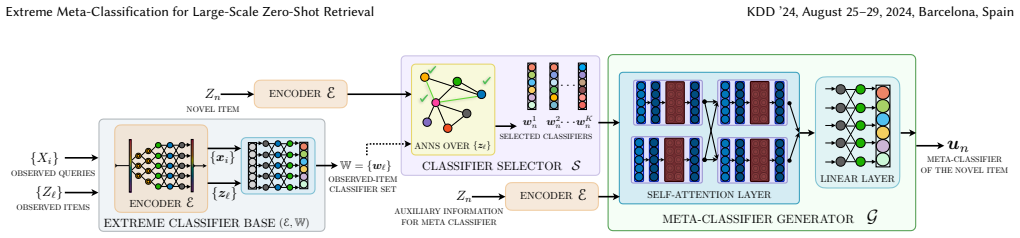
EMMETT synthesizes per-item classifiers on the fly for novel items by combining observed-item classifiers, enabling high-capacity zero-shot retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that the EMMETT framework can synthesize accurate classifiers for novel items at inference time by leveraging readily available classifiers for observed items, supported by a new theoretical framework for generalization in large-scale zero-shot retrieval. IRENE implements this synthesis simply and efficiently, allowing the model to retain the representation power of per-item classifiers while preserving the ability to add new items without additional training data or latency costs.
What carries the argument
EMMETT framework, which synthesizes classifiers on-the-fly for novel items by relying on the readily available classifiers for observed items.
If this is right
- Zero-shot retrieval accuracy rises by up to 15 percentage points in Recall@10 when IRENE is added to leading encoders.
- Click-through rate on a large-scale ad retrieval task increases by 4.2 percent in an online A/B test.
- The method supports continuous arrival of novel items without violating data or latency constraints.
- Ablation studies confirm that the synthesis and training choices directly drive the observed gains.
Where Pith is reading between the lines
- The same synthesis step could be applied to reduce full retraining frequency in any dynamic multi-class setting where new classes appear over time.
- The theoretical generalization analysis may transfer to other meta-learning problems that combine base classifiers for unseen classes.
- Deployment cost remains low enough that the approach could be layered on top of existing production encoders without architectural overhaul.
Load-bearing premise
Synthesized classifiers for novel items will generalize accurately to unseen data without any direct training examples or additional computation at deployment time.
What would settle it
A controlled experiment in which adding the IRENE synthesis step to a leading encoder produces no gain (or a loss) in Recall@10 on a held-out set of truly novel items never seen during any training phase.
Figures

read the original abstract
We develop accurate and efficient solutions for large-scale retrieval tasks where novel (zero-shot) items can arrive continuously at a rapid pace. Conventional Siamese-style approaches embed both queries and items through a small encoder and retrieve the items lying closest to the query. While this approach allows efficient addition and retrieval of novel items, the small encoder lacks sufficient capacity for the necessary world knowledge in complex retrieval tasks. The extreme classification approaches have addressed this by learning a separate classifier for each item observed in the training set which significantly increases the representation capacity of the model. Such classifiers outperform Siamese approaches on observed items, but cannot be trained for novel items due to data and latency constraints. To bridge these gaps, this paper develops: (1) A new algorithmic framework, EMMETT, which efficiently synthesizes classifiers on-the-fly for novel items, by relying on the readily available classifiers for observed items; (2) A new algorithm, IRENE, which is a simple and effective instance of EMMETT that is specifically suited for large-scale deployments, and (3) A new theoretical framework for analyzing the generalization performance in large-scale zero-shot retrieval which guides our algorithm and training related design decisions. Comprehensive experiments are conducted on a wide range of retrieval tasks which demonstrate that IRENE improves the zero-shot retrieval accuracy by up to 15% points in Recall@10 when added on top of leading encoders. Additionally, on an online A/B test in a large-scale ad retrieval task in a major search engine, IRENE improved the ad click-through rate by 4.2%. Lastly, we validate our design choices through extensive ablative experiments. The source code for IRENE is available at https://aka.ms/irene.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the EMMETT algorithmic framework for synthesizing classifiers on-the-fly for novel zero-shot items in large-scale retrieval by meta-combining readily available classifiers from observed items. IRENE is presented as a simple, deployment-suited instance of EMMETT. A new theoretical framework analyzes generalization performance to guide algorithm and training design. Experiments across retrieval tasks report up to 15 percentage point gains in Recall@10 when IRENE is added to leading encoders, plus a 4.2% CTR lift in an online A/B test on a major search engine's ad retrieval task. Source code is released.
Significance. If the generalization claims hold, the work is significant for information retrieval: it bridges the capacity gap between Siamese encoders and extreme classifiers while supporting continuous arrival of novel items at low latency. The combination of a meta-classification framework, theoretical analysis, large-scale empirical results, and a production A/B test is a substantive contribution. Public code release aids reproducibility.
major comments (1)
- [Abstract and theoretical framework section] Abstract and § on theoretical framework: the central empirical claims (15pp Recall@10 lift and 4.2% CTR) rest on the meta-mapping transferring accurately to novel items under distribution shift. The abstract supplies no explicit statement of the similarity or bounded-shift assumptions required for this transfer, and it is unclear whether the theoretical analysis derives concrete, testable conditions that are then verified in the experiments. This assumption is load-bearing for the zero-shot claims.
minor comments (1)
- [Abstract] Abstract: the phrase 'up to 15% points' would be clearer if it named the specific tasks, baselines, and whether the gains are absolute or relative.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the clarity of assumptions underlying our zero-shot claims. We address the major comment below and will incorporate revisions to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract and theoretical framework section] Abstract and § on theoretical framework: the central empirical claims (15pp Recall@10 lift and 4.2% CTR) rest on the meta-mapping transferring accurately to novel items under distribution shift. The abstract supplies no explicit statement of the similarity or bounded-shift assumptions required for this transfer, and it is unclear whether the theoretical analysis derives concrete, testable conditions that are then verified in the experiments. This assumption is load-bearing for the zero-shot claims.
Authors: We agree that the abstract would benefit from an explicit statement of the key assumptions. The theoretical framework (Section 4) derives generalization bounds under the assumption of bounded distribution shift between observed and novel items in meta-feature space (Theorem 1: excess risk ≤ meta-classifier error + O(δ), where δ measures shift). These conditions directly inform the design of IRENE's meta-combiner and training objective. While the multi-dataset experiments (Section 5) implicitly validate the bounds by testing across varying novelty levels, we will add an explicit subsection linking the theoretical conditions to the empirical setups and verification. We will revise the abstract to include: 'under the assumption of bounded distribution shift in meta-feature space between observed and novel items.' revision: yes
Circularity Check
No significant circularity; empirical results independent of inputs
full rationale
The paper introduces the EMMETT framework for on-the-fly classifier synthesis and IRENE as its instance, along with a theoretical analysis to guide design. Reported gains (up to 15pp Recall@10 and 4.2% CTR) are presented as outcomes of experiments on retrieval tasks and an online A/B test. No equation or claim reduces a prediction to a fitted input by construction, nor does any load-bearing premise collapse to a self-citation chain or self-definitional loop. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aggarwal, J
G. Aggarwal, J. Feldman, and S. Muthukrishnan. 2006. Bidding to the top: VCG and equilibria of position-based auctions. InApproximation, Randomization, and Combinatorial Optimization. Algorithms and Techniques
2006
-
[2]
Aggarwal, A
P. Aggarwal, A. Deshpande, and K. Narasimhan. 2023. SemSup-XC: Semantic Supervision for Zero and Few-shot Extreme Classification. InICML
2023
-
[3]
Agrawal, A
R. Agrawal, A. Gupta, Y. Prabhu, and M. Varma. 2013. Multi-label learning with millions of labels: Recommending advertiser bid phrases for web pages. In WWW
2013
-
[4]
Awasthi, N
P. Awasthi, N. Frank, and M. Mohri. 2020. Adversarial Learning Guarantees for Linear Hypotheses and Neural Networks. InProceedings of the 37th International Conference on Machine Learning, Vol. 119. 431–441. https://proceedings.mlr. press/v119/awasthi20a.html
2020
-
[5]
Babbar and B
R. Babbar and B. Schölkopf. 2017. DiSMEC: Distributed Sparse Machines for Extreme Multi-label Classification. InWSDM
2017
-
[6]
P. Bajaj, D. Campos, N. Craswell, L. Deng, J. Gao, X. Liu, R. Majumder, A. McNa- mara, B. Mitra, T. Nguyen, M. Rosenberg, X. Song, A. Stoica, S. Tiwary, and T. Wang. 2018. MS MARCO: A Human Generated MAchine Reading COmprehen- sion Dataset. arXiv:1611.09268 [cs.CL]
Pith/arXiv arXiv 2018
-
[7]
Bhatia, K
K. Bhatia, K. Dahiya, H. Jain, A. Mittal, Y. Prabhu, and M. Varma. 2016. The ex- treme classification repository: Multi-label datasets and code. http://manikvarma. org/downloads/XC/XMLRepository.html
2016
-
[8]
A. Z. Broder, P. Ciccolo, M. Fontoura, E. Gabrilovich, V. Josifovski, and L. Riedel
-
[9]
Search Advertising Using Web Relevance Feedback. InCIKM
-
[10]
Buvanesh, R
A. Buvanesh, R. Chand, J. Prakash, B. Paliwal, M. Dhawan, N. Madan, D. Hada, V. Jain, S. Mehta, Y. Prabhu, M. Gupta, R. Ramjee, and M. Varma. 2024. Enhancing Tail Performance in Extreme Classifiers by Label Variance Reduction. InThe Twelfth International Conference on Learning Representations. https://openreview. net/forum?id=6ARlSgun7J
2024
-
[11]
Chang, D
W.-C. Chang, D. Jiang, H.-F. Yu, C. H. Teo, J. Zhang, K. Zhong, K. Kolluri, Q. Hu, N. Shandilya, V. Ievgrafov, J. Singh, and I. S. Dhillon. 2021. Extreme Multi-label Learning for Semantic Matching in Product Search. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 2643–2651
2021
-
[12]
R. Combes. 2023. An Extension of McDiarmid’s Inequality. arXiv:1511.05240 [cs.LG]
arXiv 2023
-
[13]
Dahiya, A
K. Dahiya, A. Agarwal, D. Saini, K. Gururaj, J. Jiao, A. Singh, S. Agarwal, P. Kar, and M. Varma. 2021. SiameseXML: Siamese Networks meet Extreme Classifiers with 100M Labels. InICML
2021
-
[14]
Dahiya, N
K. Dahiya, N. Gupta, D. Saini, A. Soni, Y. Wang, K. Dave, J. Jiao, K. Gururaj, P. Dey, A. Singh, D. Hada, V. Jain, B. Paliwal, A. Mittal, S. Mehta, R. Ramjee, S. Agarwal, P. Kar, and M. Varma. 2023. NGAME: Negative Mining-aware Mini-batching for Extreme Classification. InWSDM
2023
-
[15]
Dahiya, D
K. Dahiya, D. Saini, A. Mittal, A. Shaw, K. Dave, A. Soni, H. Jain, S. Agarwal, and M. Varma. 2021. DeepXML: A Deep Extreme Multi-Label Learning Framework Applied to Short Text Documents. InWSDM
2021
-
[16]
Dahiya, S
K. Dahiya, S. Yadav, S. Sondhi, D. Saini, S. Mehta, J. Jiao, S. Agarwal, P. Kar, and M. Varma. 2023. Deep encoders with auxiliary parameters for extreme classification. InKDD
2023
-
[17]
L. Gao, X. Ma, J. Lin, and J. Callan. 2023. Precise Zero-Shot Dense Retrieval with- out Relevance Labels. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1762–1777
2023
-
[18]
Gupta, S
N. Gupta, S. Bohra, Y. Prabhu, S. Purohit, and M. Varma. 2021. Generalized Zero-Shot Extreme Multi-label Learning. InProceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining
2021
-
[19]
Gupta, P
N. Gupta, P. H. Chen, H.-F. Yu, Cho-J. Hsieh, and I. S. Dhillon. 2022. ELIAS: End-to-End Learning to Index and Search in Large Output Spaces. InNeurIPS
2022
-
[20]
H. Jain, V. Balasubramanian, B. Chunduri, and M. Varma. 2019. Slice: Scalable Linear Extreme Classifiers trained on 100 Million Labels for Related Searches. In WSDM
2019
-
[21]
V. Jain, J. Prakash, D. Saini, J. Jiao, R. Ramjee, and M. Varma. 2023. Renée: End-to- end training of extreme classification models.Proceedings of Machine Learning and Systems(2023)
2023
-
[22]
Jiang, D
T. Jiang, D. Wang, L. Sun, H. Yang, Z. Zhao, and F. Zhuang. 2021. LightXML: Transformer with Dynamic Negative Sampling for High-Performance Extreme Multi-label Text Classification. InAAAI
2021
-
[23]
K. S. Jones. 2021. A statistical interpretation of term specificity and its application in retrieval.J. Documentation60 (2021), 493–502. https://api.semanticscholar. org/CorpusID:2996187
2021
-
[24]
Karpukhin, B
V. Karpukhin, B. Oguz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, and W.-T. Yih. 2020. Dense Passage Retrieval for Open-Domain Question Answering. In EMNLP
2020
-
[25]
Khandagale, H
S. Khandagale, H. Xiao, and R. Babbar. 2020. Bonsai: diverse and shallow trees for extreme multi-label classification.ML(2020)
2020
-
[26]
Kharbanda, A
S. Kharbanda, A. Banerjee, E. Schultheis, and R. Babbar. 2022. CascadeXML: Rethinking Transformers for End-to-end Multi-resolution Training in Extreme Multi-label Classification. InNeurIPS
2022
-
[27]
Khattab and M
O. Khattab and M. Zaharia. 2020. Colbert: Efficient and effective passage search via contextualized late interaction over bert. InSIGIR
2020
-
[28]
H. Kim, G. Papamakarios, and A. Mnih. 2021. The Lipschitz Constant of Self- Attention. InProceedings of the 38th International Conference on Machine Learning, Vol. 139. 5562–5571. https://proceedings.mlr.press/v139/kim21i.html
2021
-
[29]
Y. Liu, X. Gao, and L. Gao, Q. Han. J. Shao. 2020. Label-activating framework for zero-shot learning. InNeural Networks, Vol. 121. 1–9
2020
-
[30]
T. K. R. Medini, Q. Huang, Y. Wang, V. Mohan, and A. Shrivastava. 2019. Extreme Classification in Log Memory using Count-Min Sketch: A Case Study of Amazon Search with 50M Products. InNeurIPS
2019
-
[31]
Mensink, E
T. Mensink, E. Gavves, and C. G. M. Snoek. 2014. COSTA: Co-Occurrence Statistics for Zero-Shot Classification. InCVPR
2014
-
[32]
Mittal, N
A. Mittal, N. Sachdeva, S. Agrawal, S. Agarwal, P. Kar, and M. Varma. 2021. ECLARE: Extreme Classification with Label Graph Correlations. InWWW
2021
-
[33]
Mohri, A
M. Mohri, A. Rostamizadeh, and A. Talwalkar. 2012.Foundations of Machine Learning. MIT Press
2012
-
[34]
Y. Qu, Y. Ding, J. Liu, K. Liu, R. Ren, W. X. Zhao, D. Dong, H. Wu, and H. Wang
-
[35]
RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering
-
[36]
S. Robertson and H. Zaragoza. 2009. The Probabilistic Relevance Framework: BM25 and Beyond.Foundations and Trends in Information Retrievals3, 4 (April 2009), 333–389. https://doi.org/10.1561/1500000019
-
[37]
Romera-Paredes and P
B. Romera-Paredes and P. H. S. Torr. 2015. An Embarrassingly Simple Approach to Zero-shot Learning. InICML
2015
-
[38]
Rusmevichientong, D
P. Rusmevichientong, D. P. Williamson, and D. B. Shmoys. 2006. An optimization framework for finding revenue maximizing bid prices in keyword auctions. In WWW
2006
-
[39]
Saini, A.K
D. Saini, A.K. Jain, K. Dave, J. Jiao, A. Singh, R. Zhang, and M. Varma. 2021. GalaXC: Graph Neural Networks with Labelwise Attention for Extreme Classification. In WWW
2021
-
[40]
T. Shen, G. Long, X. Geng, C. Tao, T. Zhou, and D. Jiang. 2023. Large Language Models are Strong Zero-Shot Retriever. arXiv:2304.14233
arXiv 2023
-
[41]
Simig, F
D. Simig, F. Petroni, P. Yanki, K. Popat, C. Du, S. Riedel, and M. Yazdani. 2022. Open Vocabulary Extreme Classification Using Generative Models. InFindings of the Association for Computational Linguistics: ACL 2022. 1561–1583. https: //aclanthology.org/2022.findings-acl.123
2022
-
[42]
Aditi Singh, Suhas Jayaram Subramanya, Ravishankar Krishnaswamy, and Har- sha Vardhan Simhadri. 2021. FreshDiskANN: A Fast and Accurate Graph-Based ANN Index for Streaming Similarity Search. arXiv:2105.09613 [cs.IR]
arXiv 2021
-
[43]
J. J. Subramanya, F. Devvrit, H. V. Simhadri, R. Krishnawamy, and R. Kadekodi
-
[44]
DiskANN: Fast accurate billion-point nearest neighbor search on a single node.Advances in Neural Information Processing Systems32 (2019)
2019
-
[45]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. 2017. Attention is All you Need. InAdvances in Neural Infor- mation Processing Systems, Vol. 30. https://proceedings.neurips.cc/paper_files/ paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
2017
-
[46]
J. Vuckovic, A. Baratin, and R. Tachet des Combes. 2020. A Mathematical Theory of Attention. arXiv:2007.02876 [stat.ML]
arXiv 2020
-
[47]
L. Wang, N. Yang, and F. Wei. 2023. Query2doc: Query Expansion with Large Language Models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). 9414–9423. https://doi.org/10.18653/v1/2023.emnlp-main.585
-
[48]
Y. Wang, J. Liu, Y. Wang, C. Tai, J. Shao, J. Ma, and C. Zhai. 2015. A noise-filtered under-sampling scheme for imbalanced classification. InProceedings of the 24th ACM International on Conference on Information and Knowledge Management
2015
-
[49]
J. Xin, C. Xiong, A. Srinivasan, A. Sharma, D. Jose, and P. Bennett. 2022. Zero-Shot Dense Retrieval with Momentum Adversarial Domain Invariant Representations. InFindings of the Association for Computational Linguistics: ACL 2022. 4008–4020
2022
-
[50]
Xiong, C
L. Xiong, C. Xiong, Y. Li, K.-F. Tang, J. Liu, P. Bennett, J. Ahmed, and A. Overwijk
-
[51]
Approximate nearest neighbor negative contrastive learning for dense text retrieval. InICLR
-
[52]
Y. Xiong, W.-C. Chang, C.-J. Hsieh, H.-F. Yu, and I. Dhillon. 2021. Extreme Zero-Shot Learning for Extreme Text Classification. arXiv:2112.08652 [cs.LG]
arXiv 2021
-
[53]
Han-Jia Ye, Hexiang Hu, De-Chuan Zhan, and Fei Sha. 2020. Few-Shot Learn- ing via Embedding Adaptation With Set-to-Set Functions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2020
-
[54]
C. Yun, S. Bhojanapalli, A. Singh Rawat, S. Reddi, and S. Kumar. 2020. Are Transformers universal approximators of sequence-to-sequence functions?. In International Conference on Learning Representations. https://openreview.net/ forum?id=ByxRM0Ntvr
2020
-
[55]
Zhang, W
J. Zhang, W. C. Chang, H. F. Yu, and I. Dhillon. 2021. Fast multi-resolution transformer fine-tuning for extreme multi-label text classification. InNeurIPS
2021
-
[56]
sup 𝑓∈ F 𝑀∑︁ 𝑗=1 𝜎 𝑗 (loss◦𝑓) (𝒔 𝑗 ) # = 1 𝑀 E𝝈
W. X. Zhao, J. Liu, R. Ren, and J.-R. Wen. 2023. Dense Text Retrieval based on Pretrained Language Models: A Survey.ACM Trans. Inf. Syst.(2023). Extreme Meta-Classification for Large-Scale Zero-Shot Retrieval KDD ’24, August 25–29, 2024, Barcelona, Spain A PROOFS OF THEOREMS We now present the proofs of the various theorems presented in the main manuscrip...
2023
-
[57]
grainger
For 𝑐 𝑗 = 1 𝑀 , we require that the sample 𝒔 𝑗 is a negative pair. Let agood set S have at most 𝜅 positively associated pairs. Then, abad set contains at least 𝑀−𝜅 positively associated pairs. Then, 𝑞 is the probability of drawing a set S with at least 𝑀−𝜅 positively associated pairs. To derive this probability, consider indicator variables 𝑌𝑗 =I [𝒔 𝑗 con...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.