Offline Multi-agent Continual Cooperation via Skill Partition and Reuse
Pith reviewed 2026-06-25 21:12 UTC · model grok-4.3
The pith
COMAD discovers coordination skills from offline multi-agent data via auto-encoder and reuses them with a density estimator to support continual task streams without interference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
COMAD discovers skills from mixed multi-agent behavior data with an auto-encoder to transform coordination knowledge into reusable coordination skills. It then constructs a skill-augmented policy learning objective with multi-head architectures, explicitly guiding the advantage function with reusable skills identified via a density-based reusability estimator. Theoretical analysis shows the method approximates the optimum of a continual skill discovery problem.
What carries the argument
Density-based reusability estimator on skills extracted by auto-encoder from mixed behavior data, integrated into multi-head policy learning.
If this is right
- The skill library expands continually to mitigate interference between sequential tasks.
- Agents achieve superior forward and backward transfer on streams of multi-agent tasks.
- The approach resolves distributional shift and plasticity loss that arise with fixed-size skill libraries.
- Agents gain the capacity to continually discover and reuse coordination skills in open environments.
Where Pith is reading between the lines
- The framework could reduce reliance on online data collection when deploying multi-agent systems in changing environments.
- Similar partitioning and reuse logic might transfer to single-agent continual offline learning if the multi-agent coordination component is removed.
- Testing on task streams with increasing numbers of agents would reveal whether the density estimator scales without additional interference.
Load-bearing premise
Skills discovered via auto-encoder from mixed multi-agent behavior data can be reliably identified as reusable by a density-based estimator without introducing new interference or distributional shift in sequential tasks.
What would settle it
A sequence of MARL tasks in which COMAD's skill library expansion produces measurable performance drop on earlier tasks compared with a version lacking the density-based estimator.
Figures

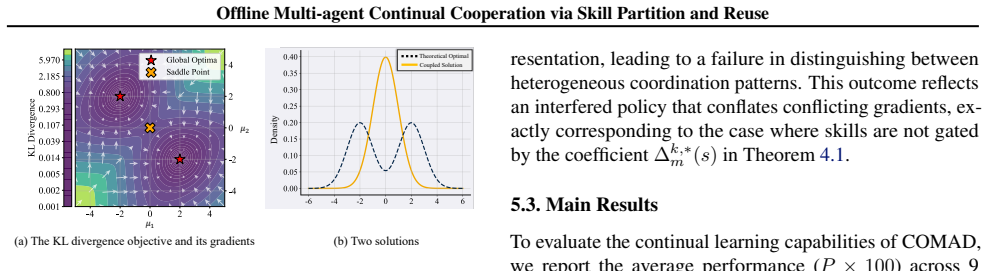


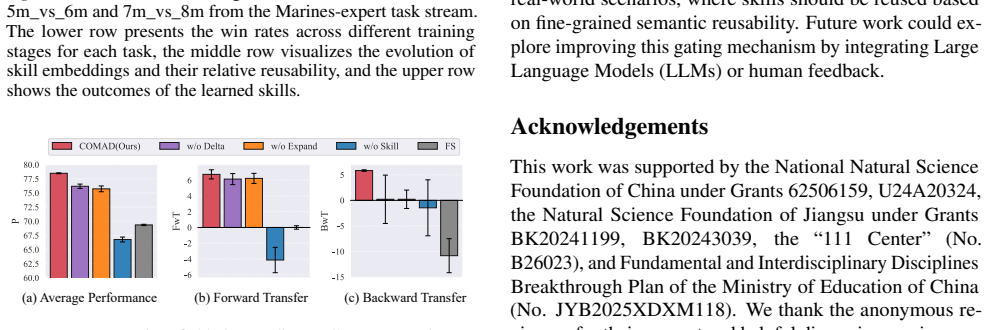

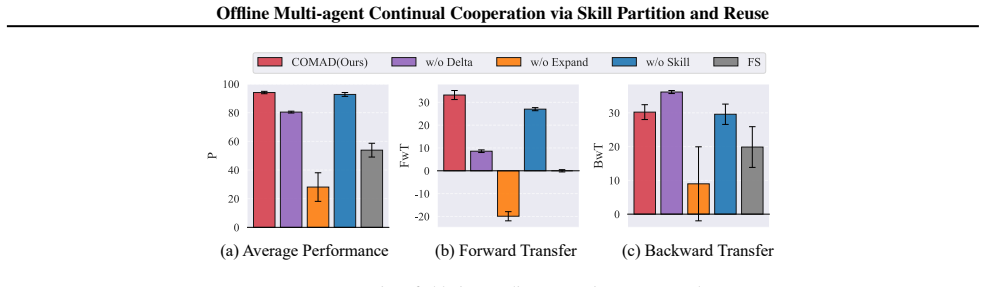
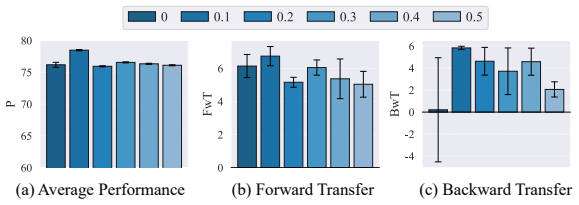




read the original abstract
Extracting skills from multi-agent offline dataset improves learning efficiency via sharing task-invariant coordination skills among tasks. In settings where tasks occur sequentially and the space of skills grows exponentially, existing approaches that rely on heuristically designed and fixed-sized skill libraries struggle to resolve the problem of distributional shift and interference, facing catastrophic forgetting and plasticity loss. To address this problem and endow agents with the ability to continually discover and reuse coordination skills in open-environment, we propose COMAD, a principled framework for Continual Offline Multi-agent Skill Discovery via Skill Partition and Reuse. We first discover skills from mixed multi-agent behavior data with an auto-encoder to transform coordination knowledge into reusable coordination skills. Then we construct a skill-augmented policy learning objective with multi-head architectures, explicitly guiding the advantage function with reusable skills identified via a density-based reusability estimator. Theoretical analysis shows our method approximates the optimum of a continual skill discovery problem. Empirical results across diverse MARL benchmarks show that COMAD continually expands its skill library to mitigate interference, achieving superior forward and backward transfer for task streams compared to multiple baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes COMAD, a framework for continual offline multi-agent skill discovery and reuse. Skills are extracted from mixed multi-agent offline behavior data via an auto-encoder; a density-based reusability estimator then identifies reusable skills to condition a multi-head policy whose advantage function is explicitly guided by those skills. The central claims are that the approach approximates the optimum of a continual skill discovery problem (theoretical analysis) and that it achieves superior forward and backward transfer on sequential MARL task streams by dynamically expanding the skill library to reduce interference and forgetting (empirical results).
Significance. If the central claims hold, the work supplies a concrete mechanism for open-ended skill library growth in offline MARL that directly targets distributional shift and catastrophic forgetting, an issue that fixed-size heuristic libraries cannot resolve. The combination of auto-encoded skill discovery with density-based reuse estimation and multi-head advantage guidance is a technically coherent response to the exponential growth of coordination skills across task sequences.
major comments (3)
- [§4 (Theoretical Analysis)] §4 (Theoretical Analysis): the claim that the method approximates the optimum of the continual skill discovery problem is load-bearing for the no-forgetting guarantee, yet the derivation implicitly treats the density-based reusability estimator as error-free; no bound or sensitivity analysis is given for misclassification rates on high-dimensional multi-agent trajectories, which would produce incorrect skill conditioning and invalidate the approximation.
- [§3.2 (Skill-Augmented Policy Learning)] §3.2 (Skill-Augmented Policy Learning): the multi-head advantage guidance objective is defined conditional on the output of the density-based estimator; if the estimator introduces unmodeled distributional shift when labeling skills as reusable, the resulting policy optimization no longer satisfies the interference-mitigation property asserted in the central claim.
- [Experiments section, transfer tables] Experiments section, transfer tables: the reported forward and backward transfer gains are attributed to continual expansion of the skill library, but the manuscript provides no ablation or diagnostic on the estimator’s precision/recall across task boundaries; without this, it is impossible to confirm that the observed gains arise from correct reuse rather than from other implementation details.
minor comments (2)
- [Abstract] The abstract states that skills are discovered 'from mixed multi-agent behavior data' but does not clarify whether the auto-encoder is trained once on the union of all tasks or incrementally; this ambiguity affects reproducibility of the continual setting.
- [§3.1] Notation for the density-based estimator (e.g., the bandwidth or kernel choice) is introduced without an explicit equation or hyper-parameter table, making it difficult to replicate the reusability threshold.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. Below we respond point-by-point to the major concerns, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [§4 (Theoretical Analysis)] the claim that the method approximates the optimum of the continual skill discovery problem is load-bearing for the no-forgetting guarantee, yet the derivation implicitly treats the density-based reusability estimator as error-free; no bound or sensitivity analysis is given for misclassification rates on high-dimensional multi-agent trajectories, which would produce incorrect skill conditioning and invalidate the approximation.
Authors: We agree that the theoretical analysis establishes the approximation under the assumption of an error-free estimator, which is a common ideal-case starting point for such derivations. The no-forgetting guarantee is therefore conditional on correct skill identification. To address the concern, we will add a dedicated paragraph in §4 discussing the sensitivity of the result to estimator misclassification rates and outlining a simple error-propagation argument based on the density estimation step. revision: yes
-
Referee: [§3.2 (Skill-Augmented Policy Learning)] the multi-head advantage guidance objective is defined conditional on the output of the density-based estimator; if the estimator introduces unmodeled distributional shift when labeling skills as reusable, the resulting policy optimization no longer satisfies the interference-mitigation property asserted in the central claim.
Authors: The interference-mitigation property is formally derived assuming the estimator correctly labels reusable skills. We will revise §3.2 to state this assumption explicitly and add a short remark noting that estimator-induced shift could weaken the property in practice, thereby qualifying the central claim. revision: yes
-
Referee: Experiments section, transfer tables: the reported forward and backward transfer gains are attributed to continual expansion of the skill library, but the manuscript provides no ablation or diagnostic on the estimator’s precision/recall across task boundaries; without this, it is impossible to confirm that the observed gains arise from correct reuse rather than from other implementation details.
Authors: The current experiments compare against baselines that lack continual skill expansion and show consistent gains, but we did not include a direct diagnostic of the estimator’s precision/recall. We will add an ablation subsection reporting precision/recall of the density-based estimator across task boundaries and correlating these metrics with the observed transfer improvements. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe a framework using an auto-encoder for skill extraction from offline data followed by a density-based reusability estimator, with a multi-head policy objective and a claim of theoretical approximation to an optimum. No equations, derivation steps, or self-citations are quoted that reduce any prediction or optimum to fitted parameters or prior author results by construction. The central claims rest on the method's design and empirical benchmarks rather than self-referential definitions or fitted inputs renamed as predictions. Without load-bearing reductions exhibited in the text, the derivation chain is treated as self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
National Science Review , volume=
Open-environment machine learning , author=. National Science Review , volume=. 2022 , publisher=
2022
-
[2]
arXiv preprint arXiv:2312.01058 , year=
A survey of progress on cooperative multi-agent reinforcement learning in open environment , author=. arXiv preprint arXiv:2312.01058 , year=
-
[3]
arXiv preprint arXiv:2505.05108 , year=
Multi-agent embodied ai: Advances and future directions , author=. arXiv preprint arXiv:2505.05108 , year=
-
[4]
Handbook of reinforcement learning and control , pages=
Multi-agent reinforcement learning: A selective overview of theories and algorithms , author=. Handbook of reinforcement learning and control , pages=. 2021 , publisher=
2021
-
[5]
International Conference on Learning Representations , year =
Zuxin Liu and Jesse Zhang and Kavosh Asadi and Yao Liu and Ding Zhao and Shoham Sabach and Rasool Fakoor , title =. International Conference on Learning Representations , year =
-
[6]
ACM Computing Surveys (CSUR) , volume=
Hierarchical reinforcement learning: A comprehensive survey , author=. ACM Computing Surveys (CSUR) , volume=. 2021 , publisher=
2021
-
[7]
Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems , pages=
M3: Modularization for Multi-task and Multi-agent Offline Pre-training , author=. Proceedings of the 2023 International Conference on Autonomous Agents and Multiagent Systems , pages=
2023
-
[8]
arXiv preprint arXiv:2405.16386 , year=
Variational offline multi-agent skill discovery , author=. arXiv preprint arXiv:2405.16386 , year=
-
[9]
Advances in Neural Information Processing Systems , pages=
Learning to discover skills through guidance , author=. Advances in Neural Information Processing Systems , pages=
-
[10]
Anurag Ajay and Aviral Kumar and Pulkit Agrawal and Sergey Levine and Ofir Nachum , booktitle=
-
[11]
Journal of Artificial Intelligence Research , volume=
Structure in deep reinforcement learning: A survey and open problems , author=. Journal of Artificial Intelligence Research , volume=
-
[12]
arXiv preprint arXiv:2005.01643 , year=
Offline reinforcement learning: Tutorial, review, and perspectives on open problems , author=. arXiv preprint arXiv:2005.01643 , year=
Pith/arXiv arXiv 2005
-
[13]
IEEE Transactions on Neural Networks and Learning Systems , volume=
A survey on offline reinforcement learning: Taxonomy, review, and open problems , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2023 , publisher=
2023
-
[14]
Artificial Intelligence Review , volume=
Multi-agent deep reinforcement learning: a survey , author=. Artificial Intelligence Review , volume=. 2022 , publisher=
2022
-
[15]
2024 , publisher=
Multi-agent reinforcement learning: Foundations and modern approaches , author=. 2024 , publisher=
2024
-
[16]
arXiv preprint arXiv:1412.3555 , year=
Empirical evaluation of gated recurrent neural networks on sequence modeling , author=. arXiv preprint arXiv:1412.3555 , year=
-
[17]
arXiv preprint arXiv:1906.02691 , year=
An introduction to variational autoencoders , author=. arXiv preprint arXiv:1906.02691 , year=
arXiv 1906
-
[18]
arXiv preprint arXiv:2506.21872 , year=
A Survey of Continual Reinforcement Learning , author=. arXiv preprint arXiv:2506.21872 , year=
-
[19]
2016 , publisher=
A concise introduction to decentralized POMDPs , author=. 2016 , publisher=
2016
-
[20]
Advances in Neural Information Processing Systems , pages=
Offline multi-agent reinforcement learning with implicit global-to-local value regularization , author=. Advances in Neural Information Processing Systems , pages=
-
[21]
The journal of machine learning research , volume=
Noise-contrastive estimation of unnormalized statistical models, with applications to natural image statistics , author=. The journal of machine learning research , volume=
-
[22]
International Conference on Machine Learning , pages=
Off-policy deep reinforcement learning without exploration , author=. International Conference on Machine Learning , pages=
-
[23]
Advances in Neural Information Processing Systems , pages=
Believe what you see: Implicit constraint approach for offline multi-agent reinforcement learning , author=. Advances in Neural Information Processing Systems , pages=
-
[24]
International Conference on Learning Representations , year=
Offline Reinforcement Learning with Implicit Q-Learning , author=. International Conference on Learning Representations , year=
-
[25]
Advances in neural information processing systems , pages=
Conservative q-learning for offline reinforcement learning , author=. Advances in neural information processing systems , pages=
-
[26]
Advances in neural information processing systems , pages=
A minimalist approach to offline reinforcement learning , author=. Advances in neural information processing systems , pages=
-
[27]
IEEE transactions on pattern analysis and machine intelligence , volume=
A comprehensive survey of continual learning: Theory, method and application , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2024 , publisher=
2024
-
[28]
Journal of Artificial Intelligence Research , volume=
Towards continual reinforcement learning: A review and perspectives , author=. Journal of Artificial Intelligence Research , volume=
-
[29]
Advances in Neural Information Processing Systems , pages=
A definition of continual reinforcement learning , author=. Advances in Neural Information Processing Systems , pages=
-
[30]
International Conference on Machine Learning , pages=
The ideal continual learner: An agent that never forgets , author=. International Conference on Machine Learning , pages=
-
[31]
Conference on lifelong learning agents , pages=
Loss of plasticity in continual deep reinforcement learning , author=. Conference on lifelong learning agents , pages=. 2023 , organization=
2023
-
[32]
International Conference on Machine Learning , pages =
Mitigating Plasticity Loss in Continual Reinforcement Learning by Reducing Churn , author =. International Conference on Machine Learning , pages =
-
[33]
Proceedings of the national academy of sciences , volume=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the national academy of sciences , volume=
-
[34]
Proceedings of the European conference on computer vision , pages=
Memory aware synapses: Learning what (not) to forget , author=. Proceedings of the European conference on computer vision , pages=
-
[35]
International conference on machine learning , pages=
Continual learning through synaptic intelligence , author=. International conference on machine learning , pages=
-
[36]
arXiv preprint arXiv:2411.10809 , year=
Stable continual reinforcement learning via diffusion-based trajectory replay , author=. arXiv preprint arXiv:2411.10809 , year=
-
[37]
IEEE Transactions on Neural Networks and Learning Systems , year=
Continual Diffuser (CoD): Mastering Continual Offline RL With Experience Rehearsal , author=. IEEE Transactions on Neural Networks and Learning Systems , year=
-
[38]
Advances in Neural Information Processing Systems , pages=
Experience replay for continual learning , author=. Advances in Neural Information Processing Systems , pages=
-
[39]
Proceedings of the
Same state, different task: Continual reinforcement learning without interference , author=. Proceedings of the
-
[40]
arXiv preprint arXiv:1706.05296 , year=
Value-decomposition networks for cooperative multi-agent learning , author=. arXiv preprint arXiv:1706.05296 , year=
-
[41]
International Conference on Machine Learning , pages=
QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning , author=. International Conference on Machine Learning , pages=
-
[42]
International Conference on Learning Representations , year=
QPLEX: Duplex Dueling Multi-Agent Q-Learning , author=. International Conference on Learning Representations , year=
-
[43]
Yihan Wang and Beining Han and Tonghan Wang and Heng Dong and Chongjie Zhang , booktitle=
-
[44]
International Conference on Learning Representations , year=
Discovering Generalizable Multi-agent Coordination Skills from Multi-task Offline Data , author=. International Conference on Learning Representations , year=
-
[45]
International Conference on Learning Representations , year=
Learning Generalizable Skills from Offline Multi-Task Data for Multi-Agent Cooperation , author=. International Conference on Learning Representations , year=
-
[46]
Proceedings of the 37th International Conference on Machine Learning , pages=
ROMA: multi-agent reinforcement learning with emergent roles , author=. Proceedings of the 37th International Conference on Machine Learning , pages=
-
[47]
International Conference on Learning Representations , year=
RODE: learning roles to decompose multi-agent tasks , author=. International Conference on Learning Representations , year=
-
[48]
International Conference on Learning Representations , year=
Action Semantics Network: Considering the Effects of Actions in Multiagent Systems , author=. International Conference on Learning Representations , year=
-
[49]
International Conference on Learning Representations , year=
UPDeT: Universal Multi-agent RL via Policy Decoupling with Transformers , author=. International Conference on Learning Representations , year=
-
[50]
2023 , publisher =
Formanek, Claude and Jeewa, Asad and Shock, Jonathan and Pretorius, Arnu , title =. 2023 , publisher =
2023
-
[51]
International conference on machine learning , pages=
Plan better amid conservatism: Offline multi-agent reinforcement learning with actor rectification , author=. International conference on machine learning , pages=
-
[52]
arXiv preprint arXiv:1606.04671 , year=
Progressive neural networks , author=. arXiv preprint arXiv:1606.04671 , year=
-
[53]
Proceedings of the
Continual learning with scaled gradient projection , author=. Proceedings of the
-
[54]
International Conference on Learning Representations , year=
Gradient Projection Memory for Continual Learning , author=. International Conference on Learning Representations , year=
-
[55]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Multiagent continual coordination via progressive task contextualization , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=
-
[56]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence , pages=
From general relation patterns to task-specific decision-making in continual multi-agent coordination , author=. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence , pages=
-
[57]
arXiv preprint arXiv:2506.14990 , year=
MEAL: A Benchmark for Continual Multi-Agent Reinforcement Learning , author=. arXiv preprint arXiv:2506.14990 , year=
-
[58]
Advances in Neural Information Processing Systems , pages=
On the utility of learning about humans for human-AI coordination , author=. Advances in Neural Information Processing Systems , pages=
-
[59]
Advances in Neural Information Processing Systems , pages=
Attention is all you need , author=. Advances in Neural Information Processing Systems , pages=
-
[60]
Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Benchmarking Multi-Agent Deep Reinforcement Learning Algorithms in Cooperative Tasks , author=. Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[61]
Advances in Neural Information Processing Systems , pages=
Multi-agent actor-critic for mixed cooperative-competitive environments , author=. Advances in Neural Information Processing Systems , pages=
-
[62]
Mikayel Samvelyan and Tabish Rashid and Christian Schroeder de Witt and Gregory Farquhar and Nantas Nardelli and Tim G. J. Rudner and Chia-Man Hung and Philiph H. S. Torr and Jakob Foerster and Shimon Whiteson , journal =
-
[63]
Advances in Neural Information Processing Systems , volume=
Smacv2: An improved benchmark for cooperative multi-agent reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[64]
Advances in Neural Information Processing Systems , pages=
Facmac: Factored multi-agent centralised policy gradients , author=. Advances in Neural Information Processing Systems , pages=
-
[65]
Proceedings of the
Emergence of grounded compositional language in multi-agent populations , author=. Proceedings of the
-
[66]
International Conference on Learning Representations , year=
Diversity is All You Need: Learning Skills without a Reward Function , author=. International Conference on Learning Representations , year=
-
[67]
International Conference on Learning Representations , year=
Dynamics-Aware Unsupervised Discovery of Skills , author=. International Conference on Learning Representations , year=
-
[68]
International Symposium on abstraction, reformulation, and approximation , pages=
Learning options in reinforcement learning , author=. International Symposium on abstraction, reformulation, and approximation , pages=. 2002 , organization=
2002
-
[69]
International Conference on Learning Representations , year=
METRA: Scalable Unsupervised RL with Metric-Aware Abstraction , author=. International Conference on Learning Representations , year=
-
[70]
International Conference on Machine Learning , pages=
Foundation Policies with Hilbert Representations , author=. International Conference on Machine Learning , pages=
-
[71]
International Conference on Robotics and Automation (ICRA) , pages=
Lotus: Continual imitation learning for robot manipulation through unsupervised skill discovery , author=. International Conference on Robotics and Automation (ICRA) , pages=
-
[72]
Advances in Neural Information Processing Systems , pages=
Continual world: A robotic benchmark for continual reinforcement learning , author=. Advances in Neural Information Processing Systems , pages=
-
[73]
2012 IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
MuJoCo: A physics engine for model-based control , author=. 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
2012
-
[74]
Journal of Machine Learning Research , year =
Yifan Zhong and Jakub Grudzien Kuba and Xidong Feng and Siyi Hu and Jiaming Ji and Yaodong Yang , title =. Journal of Machine Learning Research , year =
-
[75]
Advances in Neural Information Processing Systems , volume=
Disentangling transfer in continual reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[76]
arXiv preprint arXiv:1312.6114 , year=
Auto-encoding variational bayes , author=. arXiv preprint arXiv:1312.6114 , year=
-
[77]
International Conference on Machine Learning , pages=
Optidice: Offline policy optimization via stationary distribution correction estimation , author=. International Conference on Machine Learning , pages=
-
[78]
International Conference on Machine Learning , year=
Optimal Task Order for Continual Learning of Multiple Tasks , author=. International Conference on Machine Learning , year=
-
[79]
arXiv preprint arXiv:2205.13323 , year=
The effect of task ordering in continual learning , author=. arXiv preprint arXiv:2205.13323 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.