HEART: Coordination of Heterogeneous Expert Agents for Physically Grounded Robotic Task Planning
Pith reviewed 2026-06-25 21:06 UTC · model grok-4.3
The pith
A multi-LLM system called HEART improves robot task plans by assigning specialized roles to agents and validating physical constraints before synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
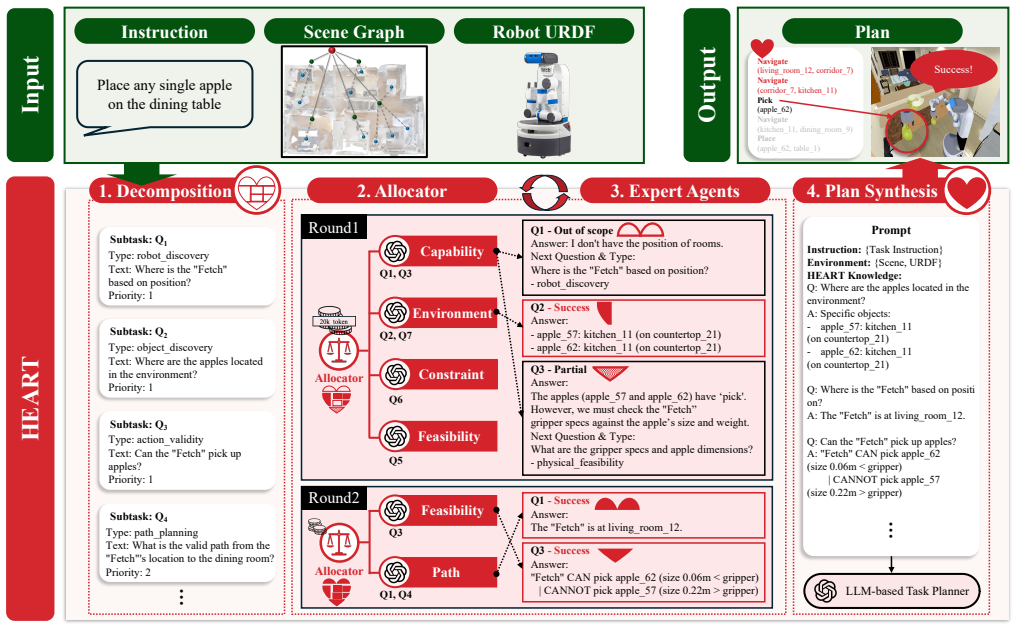
HEART is a heterogeneous multi-LLM framework that decomposes instructions into atomic reasoning tasks and allocates them to role-specialized expert agents under a token budget for real-world computational and communicational constraints. By combining role-oriented reasoning from heterogeneous agents followed by constraint-driven plan synthesis, HEART validates capability, reachability, and constraint conditions before planning and helps produce physically executable plans while maintaining efficiency. Experiments across different household benchmarks show that HEART consistently improves plan success compared to single-LLM and rule-based planners.
What carries the argument
The HEART framework, which decomposes instructions into atomic reasoning tasks allocated to role-specialized LLM agents under a token budget and follows with constraint-driven plan synthesis to validate physical conditions.
If this is right
- Plans satisfy explicit checks for capability, reachability, and logical constraints prior to execution.
- Efficiency is preserved because reasoning stays within a fixed token budget.
- Success rates rise consistently on household benchmarks relative to single-LLM baselines.
- Heterogeneous agent collaboration supports scalable planning under resource limits.
Where Pith is reading between the lines
- The role-allocation pattern could extend to other grounded reasoning tasks that require distinct expertise types.
- The token-budget mechanism suggests the method may transfer to low-compute robotic platforms.
- Integration with sensor feedback could test whether the pre-planning validations hold during actual execution.
Load-bearing premise
Role-specialized expert agents can reliably decompose instructions and validate physical constraints under a token budget without introducing new failure modes that offset the reported gains.
What would settle it
A direct comparison on the same household task benchmarks where HEART yields a lower rate of physically executable plans than a single-LLM planner or where the added validation steps produce more invalid outputs.
Figures

read the original abstract
Large Language Models (LLMs) can reason over complex instructions but often fail to satisfy the physical and spatial constraints required for robotic task planning. Recent LLM-based planners directly translate text into action sequences, yet they lack structured reasoning about feasibility, reachability, and logical order, resulting in invalid or incomplete plans. We present a heterogeneous multi-LLM framework that decomposes instructions into atomic reasoning tasks and allocates them to role-specialized expert agents under a token budget for real-world computational and communicational constraints. By combining role-oriented reasoning from heterogeneous agents followed by constraint-driven plan synthesis, HEART validates capability, reachability, and constraint conditions before planning and helps produce physically executable plans while maintaining efficiency. Experiments across different household benchmarks show that HEART consistently improves plan success compared to single-LLM and rule-based planners, demonstrating that heterogeneous LLM collaboration enables robust and scalable robotic task planning under resource constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HEART, a heterogeneous multi-LLM framework for robotic task planning. It decomposes complex instructions into atomic tasks assigned to role-specialized expert agents under a token budget, performs role-oriented reasoning to validate capability, reachability, and constraint conditions, then synthesizes plans via constraint-driven methods. The central claim is that this produces more physically executable plans than single-LLM or rule-based planners, with experiments on household benchmarks showing consistent improvements in plan success while respecting computational constraints.
Significance. If the empirical gains are robust and the validations demonstrably incorporate explicit physical checks rather than pure text reasoning, the work could advance structured multi-agent LLM approaches for robotics by addressing feasibility gaps in direct LLM planners under resource limits. The token-budget constraint and heterogeneous role allocation are practical strengths for real-world deployment.
major comments (2)
- [Abstract] Abstract: the assertion that 'Experiments across different household benchmarks show that HEART consistently improves plan success' supplies no quantitative results, baselines, error bars, success-rate deltas, or exclusion criteria, leaving the central empirical claim without visible data support.
- [Abstract] Abstract: the claim that agents 'validate capability, reachability, and constraint conditions' to produce 'physically executable plans' does not indicate whether validation uses explicit geometric/physics tools (e.g., 3D scene graphs, collision checkers, or simulators such as PyBullet) or relies solely on prompted LLM text outputs; this distinction is load-bearing for the contrast with single-LLM planners that 'lack structured reasoning about feasibility'.
minor comments (1)
- [Abstract] The abstract introduces 'role-specialized expert agents' and 'constraint-driven plan synthesis' without defining the exact roles or synthesis algorithm, which would aid clarity even in the summary.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and will revise the manuscript accordingly where the points strengthen clarity without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'Experiments across different household benchmarks show that HEART consistently improves plan success' supplies no quantitative results, baselines, error bars, success-rate deltas, or exclusion criteria, leaving the central empirical claim without visible data support.
Authors: We agree the abstract would be strengthened by including key quantitative support. The body of the paper reports success rates, baselines (single-LLM and rule-based planners), and comparative deltas across household benchmarks. We will revise the abstract to incorporate concise quantitative highlights such as overall success-rate improvements while respecting length constraints. revision: yes
-
Referee: [Abstract] Abstract: the claim that agents 'validate capability, reachability, and constraint conditions' to produce 'physically executable plans' does not indicate whether validation uses explicit geometric/physics tools (e.g., 3D scene graphs, collision checkers, or simulators such as PyBullet) or relies solely on prompted LLM text outputs; this distinction is load-bearing for the contrast with single-LLM planners that 'lack structured reasoning about feasibility'.
Authors: The validation step in HEART is performed exclusively via role-oriented reasoning by heterogeneous LLM agents that are prompted to assess capability, reachability, and constraints using their embedded knowledge of physical and spatial principles. No explicit geometric or physics simulators are invoked; the structured multi-agent decomposition itself supplies the feasibility reasoning absent in monolithic LLM planners. We will revise the abstract to explicitly note that validation occurs through prompted LLM reasoning rather than external tools. revision: yes
Circularity Check
No circularity detected in derivation or claims
full rationale
The paper presents a multi-LLM agent framework for robotic task planning, with claims resting on experimental success rates across household benchmarks rather than any mathematical derivation, fitted parameters, or self-referential definitions. No equations, ansatzes, uniqueness theorems, or predictions appear in the provided text. The method is described as allocating tasks to role-specialized agents and synthesizing plans, with validation occurring before planning; these are architectural choices evaluated externally via benchmarks, not reductions to inputs by construction. Self-citations are not load-bearing in the abstract or described claims. This is a standard non-circular empirical systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sayplan: Grounding large language models using 3D scene graphs for scalable robot task planning,
K. Rana, J. Haviland, S. Garg, J. Abou-Chakra, I. Reid, and N. Suen- derhauf, “Sayplan: Grounding large language models using 3D scene graphs for scalable robot task planning,” inProc. Conf. Robot Learn., vol. 229, 2023, pp. 23–72
2023
-
[2]
Delta: Decomposed efficient long-term robot task planning using large lan- guage models,
Y . Liu, L. Palmieri, S. Koch, I. Georgievski, and M. Aiello, “Delta: Decomposed efficient long-term robot task planning using large lan- guage models,” inProc. IEEE Int. Conf. Robot. Autom., 2025, pp. 10 995–11 001
2025
-
[3]
PaLM-E: An embodied multimodal language model,
D. Driesset al., “PaLM-E: An embodied multimodal language model,” inProc. Int. Conf. Mach. Learn., vol. 202, 2023, pp. 8469–8488
2023
-
[4]
Coherent: Collaboration of heterogeneous multi-robot system with large language models,
K. Liu, Z. Tang, D. Wang, Z. Wang, X. Li, and B. Zhao, “Coherent: Collaboration of heterogeneous multi-robot system with large language models,” inProc. IEEE Int. Conf. Robot. Autom., 2025, pp. 10 208– 10 214
2025
-
[5]
The FF planning system: Fast plan generation through heuristic search,
J. Hoffmann and B. Nebel, “The FF planning system: Fast plan generation through heuristic search,”J. Artif. Intell. Res., vol. 14, pp. 253–302, 2001
2001
-
[6]
Lost in the middle: How language models use long contexts,
N. F. Liuet al., “Lost in the middle: How language models use long contexts,”Trans. Assoc. Comput. Linguist., vol. 12, pp. 157–173, 2024
2024
-
[7]
Roco: Dialectic multi-robot collab- oration with large language models,
Z. Mandi, S. Jain, and S. Song, “Roco: Dialectic multi-robot collab- oration with large language models,” inProc. IEEE Int. Conf. Robot. Autom., 2024, pp. 286–299
2024
-
[8]
Large language model based multi-agents: A survey of progress and challenges,
T. Guoet al., “Large language model based multi-agents: A survey of progress and challenges,” inProc. Int. Joint Conf. Artif. Intell., 2024, pp. 8048–8057
2024
-
[9]
Scalable multi-robot collaboration with large language models: Centralized or decentralized systems?
Y . Chen, J. Arkin, Y . Zhang, N. Roy, and C. Fan, “Scalable multi-robot collaboration with large language models: Centralized or decentralized systems?” inProc. IEEE Int. Conf. Robot. Autom., 2024, pp. 4311– 4317
2024
-
[10]
Multi-agent consensus seeking via large language models,
H. Chen, W. Ji, L. Xu, and S. Zhao, “Multi-agent consensus seeking via large language models,”arXiv preprint arXiv:2310.20151, 2023
arXiv 2023
-
[11]
Mixture- of-agents enhances large language model capabilities,
J. Wang, J. Wang, B. Athiwaratkun, C. Zhang, and J. Zou, “Mixture- of-agents enhances large language model capabilities,” inProc. Int. Conf. Learn. Represent., 2025
2025
-
[12]
Improving test-time search for LLMs with back- tracking against in-context value verifiers,
A. Singhet al., “Improving test-time search for LLMs with back- tracking against in-context value verifiers,” inICLR Workshop Reason. Plan. Large Lang. Models, 2025
2025
-
[13]
Multi-agent collaboration mechanisms: A survey of llms,
K.-T. Tran, D. Dao, M.-D. Nguyen, Q.-V . Pham, B. O’Sullivan, and H. D. Nguyen, “Multi-agent collaboration mechanisms: A survey of llms,”arXiv preprint arXiv:2501.06322, 2025
Pith/arXiv arXiv 2025
-
[14]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances,
M. Ahnet al., “Do As I Can, Not As I Say: Grounding Language in Robotic Affordances,” inProc. Conf. Robot Learn., vol. 205, 2023, pp. 287–318
2023
-
[15]
SMART-LLM: Smart multi-agent robot task planning using large language models,
S. S. Kannan, V . L. Venkatesh, and B.-C. Min, “SMART-LLM: Smart multi-agent robot task planning using large language models,” inProc. IEEE/RSJ Int. Conf. Intell. Robots Syst., 2024, pp. 12 140–12 147
2024
-
[16]
Large language models still can’t plan (a benchmark for llms on planning and reasoning about change),
K. Valmeekam, A. Olmo, S. Sreedharan, and S. Kambhampati, “Large language models still can’t plan (a benchmark for llms on planning and reasoning about change),” inNeurIPS Workshop Found. Models Decis. Making, 2022
2022
-
[17]
On the prospects of incorporating large language models (LLMs) in automated planning and scheduling (APS),
V . Pallaganiet al., “On the prospects of incorporating large language models (LLMs) in automated planning and scheduling (APS),” inProc. Int. Conf. Autom. Plan. Sched., vol. 34, 2024, pp. 432–444
2024
-
[18]
PDDL2.1: An extension to PDDL for express- ing temporal planning domains,
M. Fox and D. Long, “PDDL2.1: An extension to PDDL for express- ing temporal planning domains,”J. Artif. Intell. Res., vol. 20, pp. 61– 124, 2003
2003
-
[19]
SELP: Generating safe and efficient task plans for robot agents with large language models,
Y . Wuet al., “SELP: Generating safe and efficient task plans for robot agents with large language models,” inProc. IEEE Int. Conf. Robot. Autom., 2025, pp. 2599–2605
2025
-
[20]
AutoTAMP: Autoregressive task and motion planning with llms as translators and checkers,
Y . Chen, J. Arkin, C. Dawson, Y . Zhang, N. Roy, and C. Fan, “AutoTAMP: Autoregressive task and motion planning with llms as translators and checkers,” inProc. IEEE Int. Conf. Robot. Autom., 2024, pp. 6695–6702
2024
-
[21]
Why solving multi-agent path finding with large language model has not succeeded yet,
W. Chen, S. Koenig, and B. Dilkina, “Why solving multi-agent path finding with large language model has not succeeded yet,”arXiv preprint arXiv:2401.03630, 2024
arXiv 2024
-
[22]
Challenges faced by large language models in solving multi-agent flocking,
P. Li, V . Menon, B. Gudiguntla, D. Ting, and L. Zhou, “Challenges faced by large language models in solving multi-agent flocking,”arXiv preprint arXiv:2404.04752, 2024
arXiv 2024
-
[23]
Adaptive domain modeling with language models: A multi-agent approach to task planning,
H. Babu, P. Schillinger, and T. Asfour, “Adaptive domain modeling with language models: A multi-agent approach to task planning,”arXiv preprint arXiv:2506.19592, 2025
arXiv 2025
-
[24]
LLM-Collab: a framework for enhancing task planning via chain-of-thought and multi-agent collaboration,
H. Cao, R. Ma, Y . Zhai, and J. Shen, “LLM-Collab: a framework for enhancing task planning via chain-of-thought and multi-agent collaboration,”Appl. Comput. Intell., vol. 4, no. 2, pp. 328–348, 2024
2024
-
[25]
Multi-agent systems for robotic autonomy with LLMs,
J. Chen, Z. Yang, H. G. Xu, D. Zhang, and G. Mylonas, “Multi-agent systems for robotic autonomy with LLMs,” inProc. CVPR Workshop Multi-Agent Embod. Intell. Syst., 2025
2025
-
[26]
Z. Jia, H. Gao, F. Li, J. Liu, H. Li, and Q. Liu, “Triple-S: A collabo- rative multi-llm framework for solving long-horizon implicative tasks in robotics,”arXiv preprint arXiv:2508.07421, 2025
arXiv 2025
-
[27]
Flowplan: Zero-shot task planning with llm flow engineering for robotic instruction following,
Z. Lin, C. Tang, H. Ye, and H. Zhang, “Flowplan: Zero-shot task planning with llm flow engineering for robotic instruction following,” arXiv preprint arXiv:2503.02698, 2025
arXiv 2025
-
[28]
A formal analysis and taxonomy of task allocation in multi-robot systems,
B. P. Gerkey and M. J. Matari ´c, “A formal analysis and taxonomy of task allocation in multi-robot systems,”Int. J. Robot. Res., vol. 23, no. 9, pp. 939–954, 2004
2004
-
[29]
Market-based multirobot coordination: A survey and analysis,
M. B. Dias, R. Zlot, N. Kalra, and A. Stentz, “Market-based multirobot coordination: A survey and analysis,”Proc. IEEE, vol. 94, no. 7, pp. 1257–1270, 2006
2006
-
[30]
A comprehensive taxonomy for multi-robot task allocation,
G. A. Korsah, A. Stentz, and M. B. Dias, “A comprehensive taxonomy for multi-robot task allocation,”Int. J. Robot. Res., vol. 32, no. 12, pp. 1495–1512, 2013
2013
-
[31]
Performance-effective and low-complexity task scheduling for heterogeneous computing,
H. Topcuoglu, S. Hariri, and M.-Y . Wu, “Performance-effective and low-complexity task scheduling for heterogeneous computing,”IEEE Trans. Parallel Distrib. Syst., vol. 13, no. 3, pp. 260–274, 2002
2002
-
[32]
Socially guided intrinsic motivation for robot learning of motor skills,
S. M. Nguyen and P.-Y . Oudeyer, “Socially guided intrinsic motivation for robot learning of motor skills,”Auton. Robots, vol. 36, no. 3, pp. 273–294, 2014
2014
-
[33]
Active choice of teachers, learning strategies and goals for a socially guided intrinsic motivation learner,
——, “Active choice of teachers, learning strategies and goals for a socially guided intrinsic motivation learner,”Paladyn, vol. 3, no. 3, pp. 136–146, 2012
2012
-
[34]
Scaling llm test-time compute optimally can be more effective than scaling model parameters,
C. Snell, J. Lee, K. Xu, and A. Kumar, “Scaling llm test-time compute optimally can be more effective than scaling model parameters,”arXiv preprint arXiv:2408.03314, 2024
Pith/arXiv arXiv 2024
-
[35]
3D Scene Graph: A structure for unified semantics, 3d space, and camera,
I. Armeniet al., “3D Scene Graph: A structure for unified semantics, 3d space, and camera,” inProc. IEEE/CVF Int. Conf. Comput. Vis., 2019, pp. 5663–5672
2019
-
[36]
Sentence-BERT: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence embeddings using siamese bert-networks,” inProc. Conf. Empir. Methods Nat. Lang. Process., 2019, pp. 3982–3992
2019
-
[37]
Small language models are the future of agentic ai,
P. Belcaket al., “Small language models are the future of agentic ai,” arXiv preprint arXiv:2506.02153, 2025
Pith/arXiv arXiv 2025
-
[38]
A survey of large language model agents for question answering,
M. Yue, “A survey of large language model agents for question answering,”arXiv preprint arXiv:2503.19213, 2025
arXiv 2025
-
[39]
iGibson 2.0: Object-centric simulation for robot learning of everyday household tasks,
C. Liet al., “iGibson 2.0: Object-centric simulation for robot learning of everyday household tasks,” inProc. Conf. Robot Learn., 2021
2021
-
[40]
V AL: Automatic plan validation, continuous effects and mixed initiative planning using PDDL,
R. Howey, D. Long, and M. Fox, “V AL: Automatic plan validation, continuous effects and mixed initiative planning using PDDL,” inProc. IEEE Int. Conf. Tools Artif. Intell., 2004, pp. 294–301
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.