Fault of Our Stars: Behavioral Drivers of Rating-Sentiment Incongruence
Pith reviewed 2026-06-25 20:50 UTC · model grok-4.3
The pith
Star ratings frequently fail to match the sentiment in the accompanying review text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
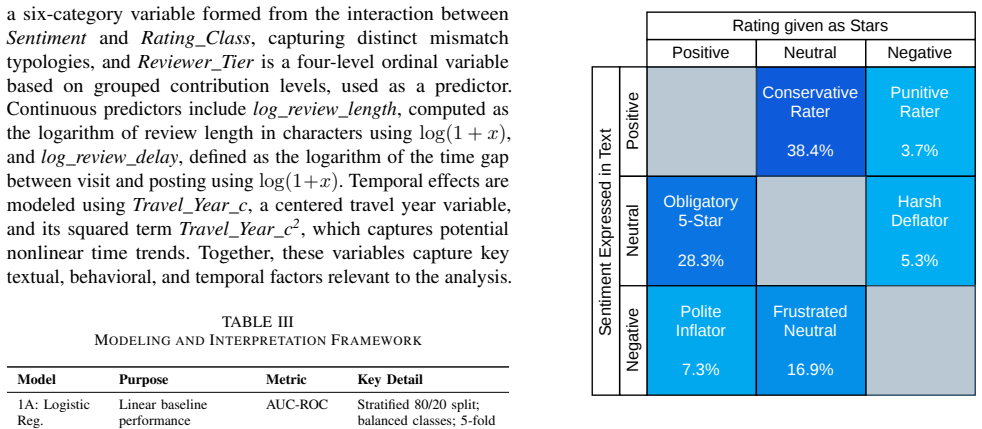
Sentiment-rating incongruence occurs in 18.6% of reviews and falls into six directional patterns, with Conservative Rater and Obligatory 5-Star behaviors accounting for the majority of mismatches. Prevalence varies across venue types, with museums showing the highest rates. Statistical tests, logistic regression, Random Forest, and SHAP analysis identify venue type, reviewer expertise, review length, and temporal factors as contributors to rating-text divergence. The study concludes that star ratings are not interchangeable with textual sentiment and should be validated before being treated as ground-truth labels in NLP.
What carries the argument
A transformer-based sentiment pipeline that derives textual sentiment independently of assigned ratings, used to flag incongruence and its drivers.
If this is right
- Datasets that use star ratings as weak labels for sentiment analysis contain systematic noise from incongruent cases.
- Models trained on rating labels may learn rating-specific biases instead of text sentiment patterns.
- Incongruence rates are higher for certain venue types such as museums.
- Longer reviews and those from more expert reviewers are more likely to show divergence.
- Machine learning models combined with SHAP values can surface the main behavioral and contextual drivers.
Where Pith is reading between the lines
- If the mismatch rate holds in other domains, then sentiment benchmarks that rely on rating labels may report inflated accuracy.
- Tools that automatically flag rating-text mismatches could be added to dataset cleaning pipelines.
- The behavioral patterns identified here may also appear in product or service reviews outside tourism.
- Testing whether the same drivers appear when reviewers are asked to assign both ratings and text in controlled settings would extend the finding.
Load-bearing premise
The transformer-based sentiment pipeline produces an accurate measure of textual sentiment that is independent of the assigned star rating.
What would settle it
Collecting fresh human judgments of sentiment on a random sample of the reviews and finding that they align with the star ratings in more than 90 percent of cases would undermine the reported rate of incongruence.
Figures

read the original abstract
When people share experiences online, they often express thoughts in two ways: a star rating and a written review. In sentiment analysis, ratings are widely used as convenient weak labels for textual sentiment, yet whether the two actually agree is rarely questioned. This study investigates sentiment-rating incongruence, where the sentiment expressed in review text differs from the sentiment implied by the assigned star rating, in Sri Lankan tourism attraction reviews. A dataset of 16,156 reviews from 2010 to 2023 is analyzed using a transformer-based sentiment pipeline that derives textual sentiment independently of assigned ratings. Incongruence occurs in 18.6% of reviews and falls into six directional patterns, with Conservative Rater and Obligatory 5-Star behaviors accounting for the majority of mismatches. Prevalence also varies across venue types, with museums showing the highest rates. Statistical tests, logistic regression, Random Forest, and SHAP analysis identify venue type, reviewer expertise, review length, and temporal factors as contributors to rating-text divergence. Overall, this study demonstrates that star ratings are not interchangeable with textual sentiment and should be validated before being treated as ground-truth labels in NLP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines 16,156 Sri Lankan tourism attraction reviews (2010–2023) and reports that a transformer-based sentiment pipeline finds textual sentiment incongruent with the assigned star rating in 18.6% of cases. It identifies six directional mismatch patterns (Conservative Rater and Obligatory 5-Star being most common), shows variation by venue type (highest in museums), and uses logistic regression, Random Forest, and SHAP analysis to attribute divergence to venue type, reviewer expertise, review length, and temporal factors. The central claim is that star ratings are not interchangeable with textual sentiment and require validation before use as ground-truth labels in NLP.
Significance. If the textual sentiment labels prove reliable, the result would demonstrate a non-negligible failure rate when ratings are used as weak supervision, with direct implications for dataset construction and model evaluation in sentiment analysis. The behavioral and venue-specific patterns add empirical granularity that could inform review-platform design and data-filtering practices.
major comments (1)
- [Abstract/Methods] Abstract/Methods: The manuscript states that the transformer pipeline 'derives textual sentiment independently' of the star rating, yet provides no accuracy, F1, or confusion-matrix results for the Sri Lankan tourism domain. This assumption is load-bearing for the reported 18.6% incongruence rate and all downstream logistic-regression and SHAP findings; systematic domain mismatch (local phrasing, code-switching) would directly inflate the mismatch statistics.
minor comments (1)
- [Abstract] Abstract does not name the six directional patterns or the specific transformer model and training corpus used.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract/Methods] Abstract/Methods: The manuscript states that the transformer pipeline 'derives textual sentiment independently' of the star rating, yet provides no accuracy, F1, or confusion-matrix results for the Sri Lankan tourism domain. This assumption is load-bearing for the reported 18.6% incongruence rate and all downstream logistic-regression and SHAP findings; systematic domain mismatch (local phrasing, code-switching) would directly inflate the mismatch statistics.
Authors: We agree this is a substantive gap. The manuscript does not report domain-specific accuracy, F1, or confusion-matrix results for the transformer pipeline on Sri Lankan tourism text, and the possibility of domain shift from local phrasing or code-switching is not quantified. In the revised version we will add a dedicated evaluation subsection that reports performance on a manually annotated held-out sample drawn from the same corpus (or, if annotation resources are limited, on a comparable tourism-domain benchmark), including accuracy, macro-F1, and the confusion matrix. We will also discuss the implications of any observed error rate for the 18.6 % incongruence statistic and the downstream regression/SHAP results. revision: yes
Circularity Check
No circularity: purely empirical observational study
full rationale
The paper performs an empirical analysis of review data by applying a pre-existing transformer pipeline to generate independent sentiment labels, then compares them to star ratings using standard statistical tools (logistic regression, Random Forest, SHAP). No equations, derivations, fitted parameters renamed as predictions, or self-referential definitions appear. The pipeline is asserted to operate independently; any concern about its domain accuracy is a validity issue, not a circular reduction of the claimed result to its inputs. No self-citation chains or uniqueness theorems are invoked as load-bearing. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
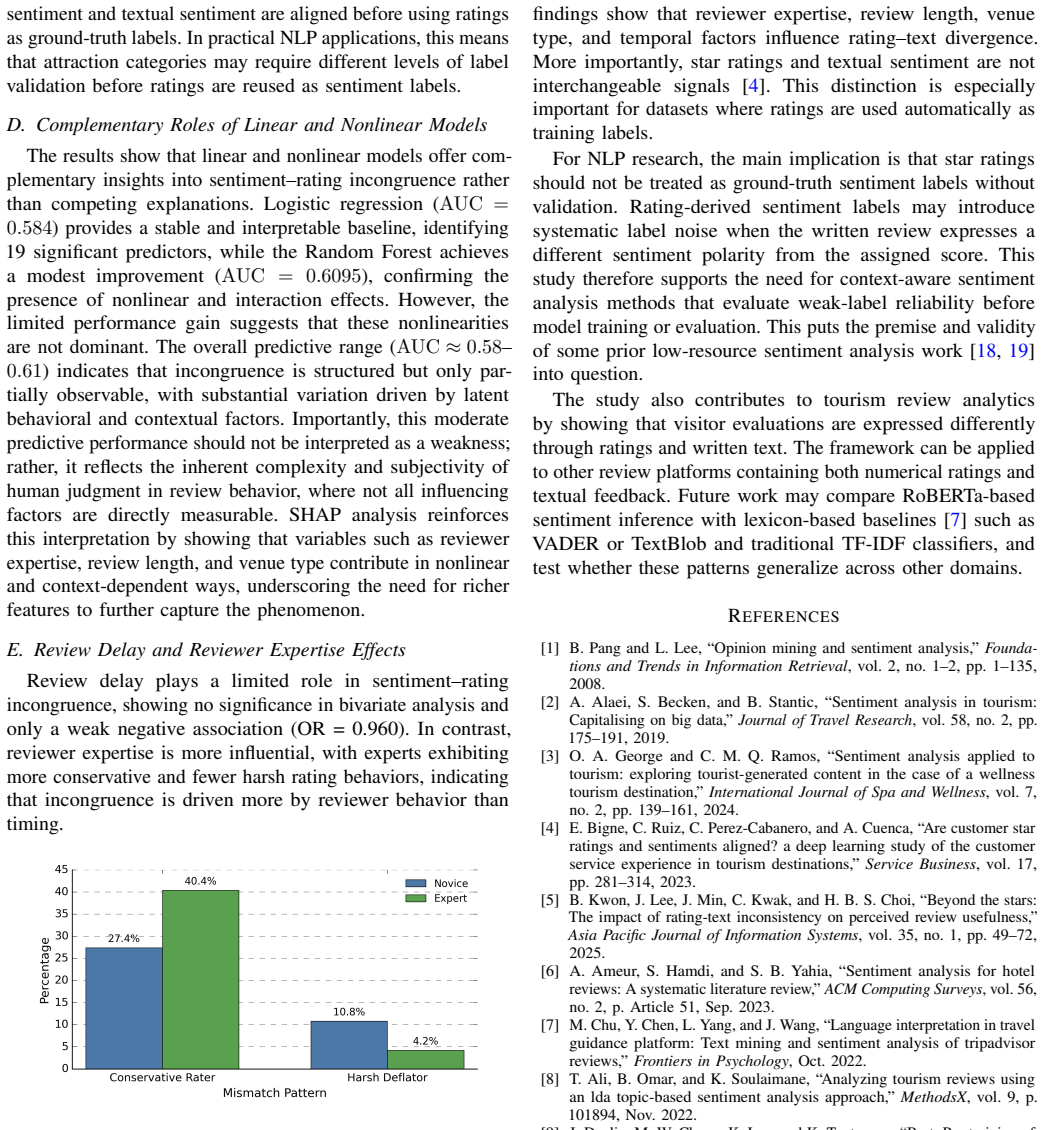
-
[1]
Opinion mining and sentiment analysis,
B. Pang and L. Lee, “Opinion mining and sentiment analysis,”Founda- tions and Trends in Information Retrieval, vol. 2, no. 1–2, pp. 1–135, 2008
2008
-
[2]
Sentiment analysis in tourism: Capitalising on big data,
A. Alaei, S. Becken, and B. Stantic, “Sentiment analysis in tourism: Capitalising on big data,”Journal of Travel Research, vol. 58, no. 2, pp. 175–191, 2019
2019
-
[3]
Sentiment analysis applied to tourism: exploring tourist-generated content in the case of a wellness tourism destination,
O. A. George and C. M. Q. Ramos, “Sentiment analysis applied to tourism: exploring tourist-generated content in the case of a wellness tourism destination,”International Journal of Spa and Wellness, vol. 7, no. 2, pp. 139–161, 2024
2024
-
[4]
Are customer star ratings and sentiments aligned? a deep learning study of the customer service experience in tourism destinations,
E. Bigne, C. Ruiz, C. Perez-Cabanero, and A. Cuenca, “Are customer star ratings and sentiments aligned? a deep learning study of the customer service experience in tourism destinations,”Service Business, vol. 17, pp. 281–314, 2023
2023
-
[5]
Beyond the stars: The impact of rating-text inconsistency on perceived review usefulness,
B. Kwon, J. Lee, J. Min, C. Kwak, and H. B. S. Choi, “Beyond the stars: The impact of rating-text inconsistency on perceived review usefulness,” Asia Pacific Journal of Information Systems, vol. 35, no. 1, pp. 49–72, 2025
2025
-
[6]
Sentiment analysis for hotel reviews: A systematic literature review,
A. Ameur, S. Hamdi, and S. B. Yahia, “Sentiment analysis for hotel reviews: A systematic literature review,”ACM Computing Surveys, vol. 56, no. 2, p. Article 51, Sep. 2023
2023
-
[7]
Language interpretation in travel guidance platform: Text mining and sentiment analysis of tripadvisor reviews,
M. Chu, Y . Chen, L. Yang, and J. Wang, “Language interpretation in travel guidance platform: Text mining and sentiment analysis of tripadvisor reviews,”Frontiers in Psychology, Oct. 2022
2022
-
[8]
Analyzing tourism reviews using an lda topic-based sentiment analysis approach,
T. Ali, B. Omar, and K. Soulaimane, “Analyzing tourism reviews using an lda topic-based sentiment analysis approach,”MethodsX, vol. 9, p. 101894, Nov. 2022
2022
-
[9]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M. W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inNAACL, Minneapolis, MN, USA, Jun. 2019, pp. 4171–4186
2019
-
[10]
Ernie: Enhanced representation through knowledge integration,
Y . Sun, S. Wang, Y . Li, S. Feng, X. Chen, H. Zhang, X. Tian, D. Zhu, H. Tian, and H. Wu, “Ernie: Enhanced representation through knowledge integration,”arXiv preprint arXiv:1904.09223, 2019
Pith/arXiv arXiv 1904
-
[11]
Sentiment analysis of hotel online reviews using the bert model and ernie model—data from china,
Y . Wen, Y . Liang, and X. Zhu, “Sentiment analysis of hotel online reviews using the bert model and ernie model—data from china,”PLOS ONE, vol. 18, no. 3, p. e0275382, Mar. 2023
2023
-
[12]
Predicting sentiment and rating of tourist reviews using machine learning,
K. Puh and M. B. Babac, “Predicting sentiment and rating of tourist reviews using machine learning,”Journal of Hospitality and Tourism Insights, vol. 6, no. 3, pp. 1188–1204, 2023
2023
-
[13]
Tourism and travel reviews: Sri lankan destinations,
T. Sewwandi, “Tourism and travel reviews: Sri lankan destinations,” Mendeley Data, V1, 2023
2023
-
[14]
Exploring tourist experience through online reviews using aspect-based sentiment analysis with zero-shot learning for hospitality service enhancement,
I. Nawawi, K. F. Ilmawan, M. F. Maarif, and M. Syafrudin, “Exploring tourist experience through online reviews using aspect-based sentiment analysis with zero-shot learning for hospitality service enhancement,” Information, vol. 15, no. 8, p. 499, Aug. 2024
2024
-
[15]
Sentiment analysis in user reviews: A study of incompatibility in hotel reviews in city of anuradhapura, sri lanka,
H. P. P. M. Abeysinghe and C. K. Walgampaya, “Sentiment analysis in user reviews: A study of incompatibility in hotel reviews in city of anuradhapura, sri lanka,” inProceedings of iPURSE, vol. 23, Peradeniya, Sri Lanka, Nov. 2021
2021
-
[16]
A novel self-learning approach to overcome incompatibility on tripadvisor reviews,
P. Abeysinghe and T. Bandara, “A novel self-learning approach to overcome incompatibility on tripadvisor reviews,”Data Science and Management, vol. 5, pp. 1–10, 2022
2022
-
[17]
Survey on Publicly Available Sinhala Natural Language Processing Tools and Research,
N. de Silva, “Survey on Publicly Available Sinhala Natural Language Processing Tools and Research,”arXiv preprint arXiv:1906.02358v26, 2026
arXiv 1906
-
[18]
Seeking sinhala sentiment: Predicting facebook reactions of sinhala posts,
V . Jayawickrama, G. Weeraprameshwara, N. de Silva, and Y . Wijeratne, “Seeking sinhala sentiment: Predicting facebook reactions of sinhala posts,” inInternational Conference on Advances in ICT for Emerging Regions, 2021, pp. 177–182
2021
-
[19]
Facebook for sentiment analysis: Baseline models to predict facebook reactions of sinhala posts,
——, “Facebook for sentiment analysis: Baseline models to predict facebook reactions of sinhala posts,”The International Journal on Advances in ICT for Emerging Regions, vol. 15, no. 2, 2022
2022
-
[20]
Sinhala Sentence Embedding: A Two-Tiered Structure for Low-Resource Languages,
G. Weeraprameshwara, V . Jayawickrama, N. de Silva, and Y . Wijeratne, “Sinhala Sentence Embedding: A Two-Tiered Structure for Low-Resource Languages,” inProceedings of the 36th Pacific Asia Conference on Language, Information and Computation, 2022, pp. 325–336
2022
-
[21]
Sentiment Analysis with Deep Learning Models: A Comparative Study on a Decade of Sinhala Language Facebook Data,
——, “Sentiment Analysis with Deep Learning Models: A Comparative Study on a Decade of Sinhala Language Facebook Data,” in2022 The 3rd International Conference on Artificial Intelligence in Electronics Engineering. Association for Computing Machinery, 2022, pp. 16–22
2022
-
[22]
Understanding review helpfulness as a function of reviewer reputation, review rating, and review depth,
A. Y . K. Chua and S. Banerjee, “Understanding review helpfulness as a function of reviewer reputation, review rating, and review depth,”Journal of the Association for Information Science and Technology, vol. 66, no. 2, pp. 354–362, 2015
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.