WOLF-VLA: Whole-Body Humanoid Optimal Locomotion Framework for Vision-Language-Action Learning
Pith reviewed 2026-06-30 10:08 UTC · model grok-4.3
The pith
Optimal control motion synthesis generates the data needed to train vision-language-action models for humanoid locomotion from language instructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
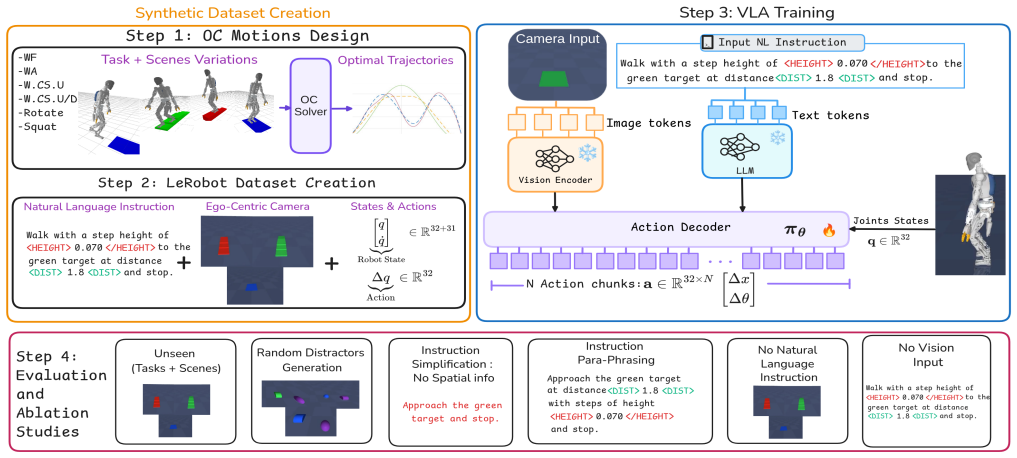
WOLF-VLA integrates whole-body optimal-control motion synthesis with a large-scale multi-modal dataset of dynamically feasible humanoid trajectories across six locomotion-related task families to train vision-language-action models that generate locomotion policies directly from natural-language instructions, yielding policies with strong reasoning, robustness to initial-condition variability, and competitive performance.
What carries the argument
The WOLF-VLA framework that pairs optimal-control trajectory generation with VLA training on joint trajectories, ego-centric visual observations, and language instructions.
If this is right
- Policies generated this way exhibit robustness to initial-condition variability.
- Competitive performance holds across multiple tasks and environment settings.
- Ablation results quantify the contribution of each input modality to overall performance.
- Open release of the dataset, checkpoints, and simulation suite supplies a reproducible benchmark for instruction-driven locomotion.
Where Pith is reading between the lines
- The same data-generation approach could be tested on combined locomotion-plus-manipulation tasks to check whether language instructions scale to more complex whole-body behaviors.
- Successful sim-to-real transfer of these policies would allow language commands to control humanoids in unstructured physical spaces.
- The focus on dynamic feasibility during data creation may encourage other learning pipelines to embed similar consistency checks before deployment.
Load-bearing premise
The dataset of optimal-control trajectories across six parameterized task families supplies enough variety for the trained model to generalize while preserving dynamic feasibility.
What would settle it
A trained policy that either produces physically inconsistent motions or shows no improvement over baselines on unseen initial conditions, tasks, or environments would falsify the claim.
Figures

read the original abstract
Vision-Language-Action (VLA) models have recently demonstrated strong generalization in robotic manipulation, yet their applicability to whole-body, contact-rich humanoid locomotion remains severely underexplored due to data scarcity, the absence of dynamically consistent demonstrations, and the difficulty of encoding optimality and safety in learning-based pipelines. This work introduces a unified framework WOLF-VLA that integrates whole-body optimal-control (OC) motion synthesis with large-scale multi-modal dataset to train VLAs capable of generating humanoid locomotion policies directly from natural-language instructions. We construct a comprehensive dataset of dynamically feasible humanoid trajectories across six locomotion-related task families, each parameterized by environmental variations, object colors, placements, and visual distractors. We train a VLA model using the collected joint trajectories, ego-centric visual observations and natural language instruction, yielding a policy that exhibits strong reasoning and robustness to initial-condition variability, and competitive performance across several tasks and environment settings. A systematic ablation study demonstrates the impact of each modality on the model performance. The full dataset, model checkpoints, and benchmarking simulation suite will be openly released, establishing a reproducible dynamically consistent benchmark for whole-body humanoid locomotion rich VLA control and enabling future research in scalable transfer of instruction-driven locomotion policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces WOLF-VLA, a framework integrating whole-body optimal-control (OC) motion synthesis with vision-language-action (VLA) models. It constructs a dataset of dynamically feasible humanoid trajectories across six locomotion task families (parameterized by environmental variations, object colors, placements, and distractors), trains a VLA on joint trajectories plus ego-centric vision and language instructions, and reports that the resulting policy exhibits strong reasoning, robustness to initial-condition variability, and competitive performance across tasks and settings. The work includes a systematic ablation study on modality impact and commits to open release of the dataset, model checkpoints, and benchmarking simulator.
Significance. If the empirical results on generalization and dynamic consistency hold, the contribution would be significant for humanoid robotics by addressing data scarcity and the lack of dynamically consistent demonstrations in VLA pipelines. The explicit open release of dataset, checkpoints, and simulator is a concrete strength that supports reproducibility and future work on instruction-driven locomotion policies.
major comments (2)
- [Abstract] Abstract: The central claims of 'strong reasoning and robustness to initial-condition variability, and competitive performance across several tasks and environment settings' are asserted without any quantitative metrics, baselines, error bars, or validation details. This absence is load-bearing for assessing whether the OC-generated dataset actually enables a VLA that generalizes while preserving dynamic consistency.
- [Abstract] Abstract (and implied methods): The manuscript states that the constructed dataset is 'sufficient to train a VLA that generalizes beyond the training distribution while preserving dynamic consistency,' yet provides no concrete test (e.g., out-of-distribution initial conditions, unseen environmental parameters, or dynamic feasibility metrics) to support this weakest assumption. Without such evidence the generalization claim cannot be evaluated.
minor comments (1)
- [Abstract] Abstract: The phrase 'strong reasoning' is used without definition or operationalization; a brief clarification of what reasoning capability is measured (e.g., via specific instruction-following metrics) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. We agree that the abstract requires quantitative support and explicit references to generalization tests to substantiate the claims. We will revise the abstract accordingly while preserving the manuscript's core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of 'strong reasoning and robustness to initial-condition variability, and competitive performance across several tasks and environment settings' are asserted without any quantitative metrics, baselines, error bars, or validation details. This absence is load-bearing for assessing whether the OC-generated dataset actually enables a VLA that generalizes while preserving dynamic consistency.
Authors: We agree the abstract would be strengthened by including quantitative metrics. The full manuscript reports success rates, baseline comparisons, and robustness statistics (with error bars) in the experiments section. We will revise the abstract to incorporate key metrics such as average task success rates, robustness to initial-condition perturbations, and competitive performance deltas versus baselines. revision: yes
-
Referee: [Abstract] Abstract (and implied methods): The manuscript states that the constructed dataset is 'sufficient to train a VLA that generalizes beyond the training distribution while preserving dynamic consistency,' yet provides no concrete test (e.g., out-of-distribution initial conditions, unseen environmental parameters, or dynamic feasibility metrics) to support this weakest assumption. Without such evidence the generalization claim cannot be evaluated.
Authors: The manuscript contains explicit evaluations of generalization to out-of-distribution initial conditions, unseen environmental parameters, and dynamic feasibility (e.g., torque and contact metrics) in the results and ablation sections. However, the abstract does not reference these tests. We will update the abstract to explicitly cite these concrete tests and metrics supporting the generalization and dynamic consistency claims. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper presents an integration framework: optimal-control synthesis generates a dataset of feasible trajectories, which is then used to train a VLA model. No equations, derivations, or first-principles results are shown that reduce any claimed output to its inputs by construction. The argument relies on dataset construction followed by standard supervised training and ablations; these steps are independent of the target policy performance and do not invoke self-citations or uniqueness theorems as load-bearing premises. The work is therefore self-contained as an empirical engineering contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Investigations into exploiting the full capabilities of a series- parallel hybrid humanoid using whole body trajectory optimization,
M. Boukheddimi, R. Kumar, S. Kumar, J. Carpentier, and F. Kirch- ner, “Investigations into exploiting the full capabilities of a series- parallel hybrid humanoid using whole body trajectory optimization,” inIEEE/RSJ IROS, 2023
2023
-
[2]
A direct-indirect hybridization approach to control-limited ddp,
C. Mastalli, W. Merkt, J. Marti-Saumell, H. Ferrolho, , J. Sola, N. Mansard, and S. Vijayakumar, “A direct-indirect hybridization approach to control-limited ddp,”arXiv:2010.00411, 2021
-
[3]
Feedback MPC for torque-controlled legged robots,
R. Grandia, F. Farshidian, R. Ranftl, and M. Hutter, “Feedback MPC for torque-controlled legged robots,” inIEEE/RSJ IROS, 2019
2019
-
[4]
Advancements in humanoid robots: A comprehensive review and future prospects,
Y . Tong, H. Liu, and Z. Zhang, “Advancements in humanoid robots: A comprehensive review and future prospects,”IEEE/CAA Journal of Automatica Sinica, vol. 11, no. 2, pp. 301–328, 2024
2024
-
[5]
A walk in the park: Learning to walk in 20 minutes with model-free reinforcement learning,
L. Smith, I. Kostrikov, and S. Levine, “A walk in the park: Learning to walk in 20 minutes with model-free reinforcement learning,” 2022
2022
-
[6]
Real-world humanoid locomotion with reinforcement learning,
I. Radosavovic, T. Xiao, B. Zhang, T. Darrell, J. Malik, and K. Sreenath, “Real-world humanoid locomotion with reinforcement learning,”Science Robotics, vol. 9, no. 89, p. eadi9579, 2024
2024
-
[7]
Sfv: Reinforcement learning of physical skills from videos,
X. B. Peng, A. Kanazawa, J. Malik, P. Abbeel, and S. Levine, “Sfv: Reinforcement learning of physical skills from videos,”ACM Transactions On Graphics (TOG), 2018
2018
-
[8]
Amp: Ad- versarial motion priors for stylized physics-based character control,
X. B. Peng, Z. Ma, P. Abbeel, S. Levine, and A. Kanazawa, “Amp: Ad- versarial motion priors for stylized physics-based character control,” ACM ToG, 2021
2021
-
[9]
Deep reinforcement learning for humanoid robot behaviors,
A. F. Muzio, M. R. Maximo, and T. Yoneyama, “Deep reinforcement learning for humanoid robot behaviors,”Journal of Intelligent & Robotic Systems, vol. 105, no. 1, p. 12, 2022
2022
-
[10]
backslashpi0 : A vision- language-action flow model for general robot control,
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter,et al., “backslashpi0 : A vision- language-action flow model for general robot control,” 2024
2024
-
[11]
π 0.5: a vision-language-action model with open-world generalization,
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail,et al., “π 0.5: a vision-language-action model with open-world generalization,” 2025
2025
-
[12]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choro- manski, T. Ding,et al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” 2023
2023
-
[13]
Openvla: An open-source vision-language-action model,
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov,et al., “Openvla: An open-source vision-language-action model,” 2024
2024
-
[14]
Open x- embodiment: Robotic learning datasets and rt-x models: Open x- embodiment collaboration 0,
A. ONeill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain,et al., “Open x- embodiment: Robotic learning datasets and rt-x models: Open x- embodiment collaboration 0,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 6892–6903
2024
-
[15]
Robot utility models: General policies for zero-shot deployment in new environments,
H. Etukuru, N. Naka, Z. Hu, S. Lee, J. Mehu, A. Edsinger, C. Paxton, S. Chintala, L. Pinto, and N. M. M. Shafiullah, “Robot utility models: General policies for zero-shot deployment in new environments,” 2024
2024
-
[16]
Palm-e: An embodied multimodal language model,
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, et al., “Palm-e: An embodied multimodal language model,” 2023
2023
-
[17]
Flower: Democratizing generalist robot policies with efficient vision-language-action flow policies,
M. Reuss, H. Zhou, M. Rhle, mer Erdin Yamurlu, F. Otto, and R. Lioutikov, “Flower: Democratizing generalist robot policies with efficient vision-language-action flow policies,” 2025
2025
-
[18]
Gr00t n1: An open foundation model for generalist humanoid robots,
NVIDIA, :, J. Bjorck, F. Castaeda, N. Cherniadev, X. Da, R. Ding, L. J. Fan, Y . Fang,et al., “Gr00t n1: An open foundation model for generalist humanoid robots,” 2025
2025
-
[19]
Learning fine-grained bimanual manipulation with low-cost hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,” 2023
2023
-
[20]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi,et al., “Smolvla: A vision-language- action model for affordable and efficient robotics,”arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Humanoid locomotion as next token prediction,
I. Radosavovic, J. Rajasegaran, B. Shi, B. Zhang, S. Kamat, K. Sreenath, T. Darrell, and J. Malik, “Humanoid locomotion as next token prediction,” inConference on Neural Information Processing Systems, 2024
2024
-
[22]
Leverb: Humanoid whole-body control with latent vision-language instruction,
H. Xue, X. Huang, D. Niu, Q. Liao, T. Kragerud, J. T. Gravdahl, X. B. Peng, G. Shi,et al., “Leverb: Humanoid whole-body control with latent vision-language instruction,” 2025
2025
-
[23]
H. Jiang, J. Chen, Q. Bu, L. Chen, M. Shi, Y . Zhang, D. Li, C. Suo, C. Wang, Z. Peng,et al., “Wholebodyvla: Towards unified latent vla for whole-body loco-manipulation control,”arXiv preprint arXiv:2512.11047, 2025
-
[24]
Sentinel: A fully end-to-end language-action model for humanoid whole body control,
Y . Wang, H. Jiang, S. Yao, Z. Ding, and Z. Lu, “Sentinel: A fully end-to-end language-action model for humanoid whole body control,” arXiv preprint arXiv:2511.19236, 2025
-
[25]
Locomujoco: A comprehensive imitation learning benchmark for locomotion,
F. Al-Hafez, G. Zhao, J. Peters, and D. Tateo, “Locomujoco: A comprehensive imitation learning benchmark for locomotion,”arXiv preprint arXiv:2311.02496, 2023
-
[26]
Hu- manoidbench: Simulated humanoid benchmark for whole-body locomotion and manipulation
C. Sferrazza, D.-M. Huang, X. Lin, Y . Lee, and P. Abbeel, “Humanoid- bench: Simulated humanoid benchmark for whole-body locomotion and manipulation,”arXiv preprint arXiv:2403.10506, 2024
-
[27]
Smplolympics: Sports environments for physically simulated humanoids,
Z. Luo, J. Wang, K. Liu, H. Zhang, C. Tessler, J. Wang, Y . Yuan, et al., “Smplolympics: Sports environments for physically simulated humanoids,”arXiv preprint arXiv:2407.00187, 2024
-
[28]
arXiv preprint arXiv:2412.17730 (2024)
Y . Liu, B. Yang, L. Zhong, H. Wang, and L. Yi, “Mimicking-bench: A benchmark for generalizable humanoid-scene interaction learning via human mimicking,”arXiv preprint arXiv:2412.17730, 2024
-
[29]
Langwbc: Language-directed humanoid whole-body control via end-to-end learning,
Y . Shao, X. Huang, B. Zhang, Q. Liao, Y . Gao, Y . Chi, Z. Li, S. Shao, and K. Sreenath, “Langwbc: Language-directed humanoid whole-body control via end-to-end learning,”arXiv preprint, 2025
2025
-
[30]
Togglemimic: A two-stage policy for text-driven humanoid whole-body control,
W. Zheng, S. Wang, and B. Qian, “Togglemimic: A two-stage policy for text-driven humanoid whole-body control,”Sensors, 2025
2025
-
[31]
Mujoco: A physics engine for model-based control,
E. Todorov, T. Erez, and Y . Tassa, “Mujoco: A physics engine for model-based control,” inIEEE/RSJ IROS. IEEE, 2012
2012
-
[32]
Featherstone,Rigid Body Dynamics Algorithms
R. Featherstone,Rigid Body Dynamics Algorithms. Springer, 2014
2014
-
[33]
Numerical optimal control (preliminary and incomplete draft),
M. Diehl and S. Gros, “Numerical optimal control (preliminary and incomplete draft),” 2017
2017
-
[34]
Pinocchio: fast forward and inverse dynamics for poly-articulated systems,
J. Carpentier, F. Valenza, N. Mansard,et al., “Pinocchio: fast forward and inverse dynamics for poly-articulated systems,” https://stack-of- tasks.github.io/pinocchio, 2015–2021
2015
-
[35]
Gymnasium: A standard interface for reinforcement learning environments,
M. Towers, A. Kwiatkowski, J. Terry, J. U. Balis, G. De Cola, T. Deleu, M. Goul ˜ao, A. Kallinteris, M. Krimmel, A. KG,et al., “Gymnasium: A standard interface for reinforcement learning environments,” 2024
2024
-
[36]
Evolutionary continuous adaptive rl-powered co-design for humanoid chin-up performance,
T. Jin, M. Boukheddimi, R. Kumar, G. Fadini, and F. Kirchner, “Evolutionary continuous adaptive rl-powered co-design for humanoid chin-up performance,” 2025
2025
-
[37]
Lerobot: An open-source library for end-to-end robot learning,
R. Cadene, S. Aliberts, F. Capuano, M. Aractingi, A. Zouitine, P. Kooijmans, J. Choghari, M. Russi, C. Pascal,et al., “Lerobot: An open-source library for end-to-end robot learning,” 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.