Falcon: Functional Assembly and Language for Compositional Reasoning in X-ray
Pith reviewed 2026-06-25 20:50 UTC · model grok-4.3
The pith
Falcon injects an explicit structured safety state into language models to reason about relational threats rather than isolated objects in X-ray scans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
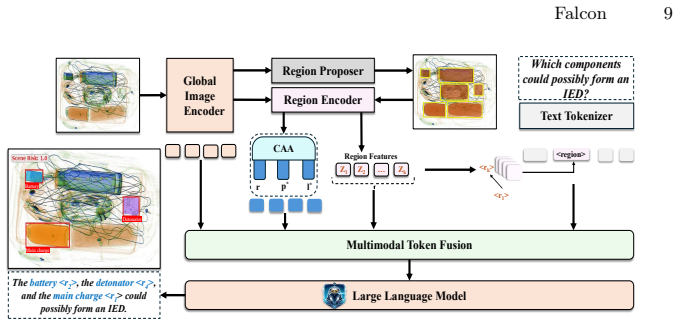
Falcon abstracts segmentation-aware region features into a structured safety state capturing component presence, pairwise functional compatibility, and scene-level risk; this state is injected into the language model as an explicit intermediate interface to encourage relationally consistent and safety-aware reasoning.
What carries the argument
The structured safety state that encodes component presence, pairwise functional compatibility, and scene-level risk, serving as an explicit intermediate interface between vision features and the language model.
If this is right
- Existing multimodal models adapt to appearance but struggle with compositional safety reasoning.
- Falcon improves functional grounding and produces more coherent threat assessments.
- Compositional safety reasoning becomes a distinct evaluation paradigm for multimodal systems.
- Risk is modeled as a relational property of grounded regions rather than an independent detection outcome.
Where Pith is reading between the lines
- The same explicit-state approach could transfer to other settings where function depends on part relations, such as medical device inspection or assembly verification.
- Falcon-X offers a template for benchmarks that jointly test dense localization and structured relational inference.
- If the intermediate state proves reliable, it may reduce the need for purely end-to-end training on complex safety tasks.
Load-bearing premise
Abstracting segmentation-aware region features into an explicit structured safety state and injecting it into the language model will encourage relationally consistent and safety-aware reasoning.
What would settle it
A controlled test in which language models receive only raw region features without the explicit safety state yet match Falcon's performance on compositional threat inference tasks using the Falcon-X benchmark.
Figures






read the original abstract
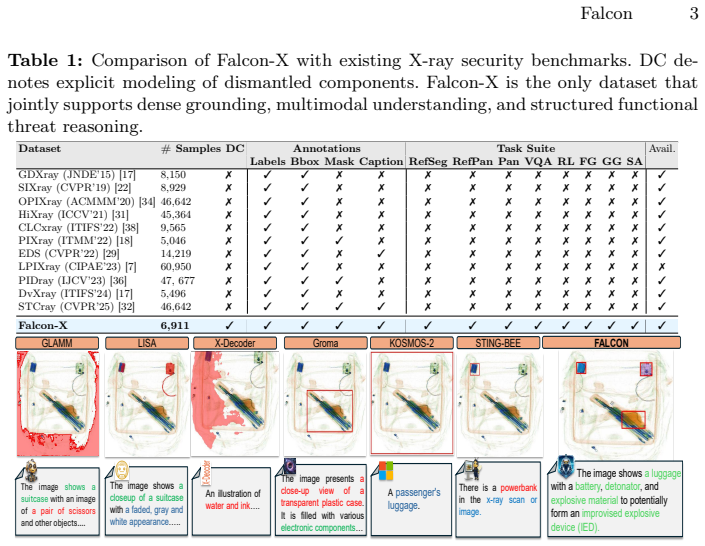
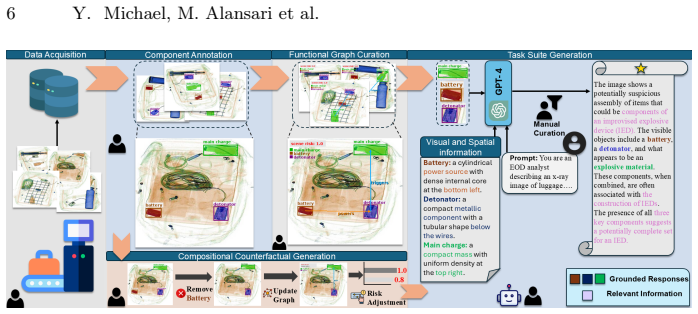
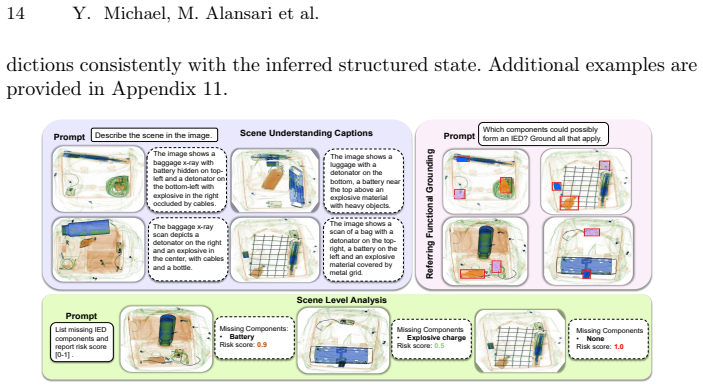
Conventional vision-language models are largely object-centric, focusing on detecting and describing individual entities. In safety-critical X-ray baggage screening, however, threat often emerges not from a single object but from the functional compatibility of spatially dispersed components, such as batteries, detonators, and explosive charges. We formalize this setting as \emph{compositional threat reasoning}, where risk is modeled as a relational property of grounded regions rather than an independent detection outcome. We introduce \textbf{Falcon}, a multimodal framework that abstracts segmentation-aware region features into a structured safety state capturing component presence, pairwise functional compatibility, and scene-level risk. This structured representation is injected into the language model as an explicit intermediate interface, encouraging relationally consistent and safety-aware reasoning. To evaluate this problem, we present \textbf{Falcon-X}, a benchmark that unifies dense grounding with structured supervision over component completeness and risk inference in cluttered X-ray imagery. Experiments show that while existing multimodal models adapt to appearance, they struggle with compositional safety reasoning. Falcon improves functional grounding and produces more coherent threat assessments, establishing compositional safety reasoning as a distinct evaluation paradigm for multimodal systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Falcon, a multimodal framework for compositional threat reasoning in X-ray baggage screening. It abstracts segmentation-aware region features into a structured safety state capturing component presence, pairwise functional compatibility, and scene-level risk; this state is injected into the language model as an explicit intermediate interface. The paper presents the Falcon-X benchmark unifying dense grounding with structured supervision over component completeness and risk inference, and reports that Falcon improves functional grounding and produces more coherent threat assessments than existing multimodal models, establishing compositional safety reasoning as a distinct evaluation paradigm.
Significance. If the central mechanism is shown to causally improve relational consistency, the work could meaningfully advance safety-critical multimodal reasoning by shifting focus from object-centric detection to functional assembly and relational risk modeling. The introduction of Falcon-X as a benchmark with structured supervision is a concrete contribution that could support future research in this area.
major comments (1)
- [Abstract] Abstract (paragraph describing the framework): the claim that abstracting segmentation-aware region features into an explicit structured safety state (component presence, pairwise compatibility, scene risk) and injecting it 'encourages relationally consistent and safety-aware reasoning' is not supported by any described ablation or isolation experiment. No comparison is provided against a baseline that receives the same region features without the structured state, so it remains unclear whether observed gains on Falcon-X are attributable to the claimed mechanism rather than segmentation quality, benchmark supervision, or other factors.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract claim. We address the point below.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph describing the framework): the claim that abstracting segmentation-aware region features into an explicit structured safety state (component presence, pairwise compatibility, scene risk) and injecting it 'encourages relationally consistent and safety-aware reasoning' is not supported by any described ablation or isolation experiment. No comparison is provided against a baseline that receives the same region features without the structured state, so it remains unclear whether observed gains on Falcon-X are attributable to the claimed mechanism rather than segmentation quality, benchmark supervision, or other factors.
Authors: We agree that the current manuscript lacks an ablation that directly isolates the contribution of the structured safety state by comparing against a baseline receiving identical segmentation-aware region features without the structured interface. The reported experiments compare Falcon to existing multimodal models but do not rule out that gains could arise from segmentation quality or benchmark supervision alone. In the revised version we will add this ablation experiment to provide causal evidence for the mechanism. revision: yes
Circularity Check
No derivations or equations present; framework proposal has no circular derivation chain
full rationale
The manuscript introduces Falcon as a multimodal framework that abstracts segmentation-aware region features into a structured safety state (component presence, pairwise compatibility, scene risk) and injects it into the language model. The abstract and description contain no equations, no first-principles derivations, no fitted parameters renamed as predictions, and no self-citation chains invoked to justify a mathematical result. The central claim is an empirical assertion that the framework improves functional grounding and threat assessment coherence on the Falcon-X benchmark. This does not reduce by construction to its inputs, nor does it rely on any of the enumerated circularity patterns. The absence of a derivation chain means the circularity score defaults to 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: ICCV (2025)
Cai, Z., Ke, F., Jahangard, S., Garcia de la Banda, M., Haffari, R., Stuckey, P.J., Rezatofighi, H.: Naver: A neuro-symbolic compositional automaton for vi- sual grounding with explicit logic reasoning. In: ICCV (2025)
2025
-
[2]
Knowledge- Based Systems (2022)
Chang,A.,Zhang,Y.,Zhang,S.,Zhong,L.,Zhang,L.:Detectingprohibitedobjects with physical size constraint from cluttered x-ray baggage images. Knowledge- Based Systems (2022)
2022
-
[3]
arXiv preprint arXiv:2306.15195 (2023)
Chen, K., Zhang, Z., Zeng, W., Zhang, R., Zhu, F., Zhao, R.: Shikra: Unleash- ing multimodal llm’s referential dialogue magic. arXiv preprint arXiv:2306.15195 (2023)
Pith/arXiv arXiv 2023
-
[4]
Chiang, W.L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., Stoica, I., Xing, E.P.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality (March 2023),https://lmsys.org/ blog/2023-03-30-vicuna/
2023
-
[5]
United States Patent Application US20160161228A1 (June 2016)
Eshetu, A., Burton, T.B., Howell, J.D., Rutter, M.F., Winnett, T.J.: Inert ied training kits. United States Patent Application US20160161228A1 (June 2016)
2016
-
[6]
In: ICCV (2025)
Garcia-Fernandez,P.,Vaquero,L.,Liu,M.,Xue,F.,Cores,D.,Sebe,N.,Mucientes, M., Ricci, E.: Superpowering open-vocabulary object detectors for x-ray vision. In: ICCV (2025)
2025
-
[7]
CIPAE (2023)
He, C., Mu, T., Ren, W., Zhao, B.: Lpixray: A large-scale logistics prohibited item x-ray dataset for the application of deep learning in security inspection. CIPAE (2023)
2023
-
[8]
In: ICCV (2017) 16 Y
He, K., Gkioxari, G., Dollár, P., Girshick, R.: Mask r-cnn. In: ICCV (2017) 16 Y. Michael, M. Alansari et al
2017
-
[9]
In: ICLR (2022)
Hu, E.J., yelong shen, Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language models. In: ICLR (2022)
2022
-
[10]
In: ICCV (2025)
Lafon, M., Karmim, Y., Silva-Rodríguez, J., Couairon, P., Rambour, C., Fournier- Sniehotta, R., Ayed, I.B., Dolz, J., Thome, N.: Vilu: Learning vision-language uncertainties for failure prediction. In: ICCV (2025)
2025
-
[11]
In: CVPR (2024)
Lai, X., Tian, Z., Chen, Y., Li, Y., Yuan, Y., Liu, S., Jia, J.: Lisa: Reasoning segmentation via large language model. In: CVPR (2024)
2024
-
[12]
In: ICML (2023)
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: bootstrapping language-image pre- training with frozen image encoders and large language models. In: ICML (2023)
2023
-
[13]
TNNLS36(2024)
Li, M., Jia, T., Wang, H., Ma, B., Lu, H., Lin, S., Cai, D., Chen, D.: Ao-detr: Anti-overlapping detr for x-ray prohibited items detection. TNNLS36(2024)
2024
-
[14]
In: ECCV (2014)
Lin, T.Y., Maire, M., Belongie, S.J., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: ECCV (2014)
2014
-
[15]
In: CVPR (2023)
Liu, C., Ding, H., Jiang, X.: GRES: Generalized referring expression segmentation. In: CVPR (2023)
2023
-
[16]
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning (2023)
2023
-
[17]
ITIFS19, 3866–3878 (2024)
Ma, B., Jia, T., Li, M., Wu, S., Wang, H., Chen, D.: Toward dual-view x-ray baggage inspection: A large-scale benchmark and adaptive hierarchical cross re- finement for prohibited item discovery. ITIFS19, 3866–3878 (2024)
2024
-
[18]
ITMM25, 4374–4386 (2022)
Ma, B., Jia, T., Su, M., Jia, X., Chen, D., Zhang, Y.: Automated segmentation of prohibited items in x-ray baggage images using dense de-overlap attention snake. ITMM25, 4374–4386 (2022)
2022
-
[19]
In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G
Ma, C., Jiang, Y., Wu, J., Yuan, Z., Qi, X.: Groma: Localized visual tokenization for grounding multimodal large language models. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision – ECCV 2024. pp. 417–435. Springer Nature Switzerland, Cham (2025)
2024
-
[20]
In: ICLR (2019)
Mao, J., Gan, C., Kohli, P., Tenenbaum, J.B., Wu, J.: The neuro-symbolic concept learner: Interpreting scenes, words, and sentences from natural supervision. In: ICLR (2019)
2019
-
[21]
Journal of Nondestructive Evaluation (2015)
Mery, D., Riffo, V., Zscherpel, U., Mondragón, G., Lillo, I., Zuccar, I., Lobel, H., Carrasco, M.: Gdxray: The database of x-ray images for nondestructive testing. Journal of Nondestructive Evaluation (2015)
2015
-
[22]
In: CVPR (2019)
Miao, C., Xie, L., Wan, F., Su, c., Liu, H., Jiao, j., Ye, Q.: Sixray: A large-scale security inspection x-ray benchmark for prohibited item discovery in overlapping images. In: CVPR (2019)
2019
-
[23]
Transactions on Machine Learning Research (2024)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., HAZIZA, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y., Li, S.W., Misra, I., Rabbat, M., Sharma, V., Synnaeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: DINOv2: Learning robust visual feat...
2024
-
[24]
Peng, Z., Wang, W., Dong, L., Hao, Y., Huang, S., Ma, S., Wei, F.: Kosmos-2: Grounding multimodal large language models to the world. ArXiv abs/2306.14824(2023)
Pith/arXiv arXiv 2023
-
[25]
In: ICML (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: ICML (2021)
2021
-
[26]
CVPR (2024) Falcon 17
Rasheed, H., Maaz, M., Shaji, S., Shaker, A., Khan, S., Cholakkal, H., Anwer, R.M., Xing, E., Yang, M.H., Khan, F.S.: Glamm: Pixel grounding large multimodal model. CVPR (2024) Falcon 17
2024
-
[27]
In: ICLR (2026)
Robinson,I.,Robicheaux,P.,Popov,M.,Ramanan,D.,Peri,N.:RF-DETR:Neural architecture search for real-time detection transformers. In: ICLR (2026)
2026
-
[28]
In: CVPR (2022)
Tao, R., Li, H., Wang, T., Wei, Y., Ding, Y., Bowei Jin and, H.Z., Liu, X., Liu, A.: Exploring endogenous shift for cross-domain detection: A large-scale benchmark and perturbation suppression network. In: CVPR (2022)
2022
-
[29]
In: ICCV (2021)
Tao, R., Wei, Y., Jiang, X., Li, H., Qin, H., Wang, J., Ma, Y., Zhang, L., Liu, X.: Towards real-world x-ray security inspection: A high-quality benchmark and lateral inhibition module for prohibited items detection. In: ICCV (2021)
2021
-
[30]
In: ICCV (2021)
Tao, R., Wei, Y., Jiang, X., Li, H., Qin, H., Wang, J., Ma, Y., Zhang, L., Liu*, X.: Towards real-world x-ray security inspection: A high-quality benchmark and lateral inhibition module for prohibited items detection. In: ICCV (2021)
2021
-
[31]
In: CVPR (2025)
Velayudhan, D., Ahmed, A., Alansari, M., Gour, N., Behouch, A., Hassan, T., Wasim, S.T., Maalej, N., Naseer, M., Gall, J., et al.: Sting-bee: Towards vision- language model for real-world x-ray baggage security inspection. In: CVPR (2025)
2025
-
[32]
ACM Computing Surveys55(8) (2022)
Velayudhan, D., Hassan, T., Damiani, E., Werghi, N.: Recent advances in bag- gage threat detection: A comprehensive and systematic survey. ACM Computing Surveys55(8) (2022)
2022
-
[33]
In: ACMMM (2020)
Wei, Y., Tao, R., Wu, Z., Ma, Y., Zhang, L., Liu, X.: Occluded prohibited items detection:Anx-raysecurityinspectionbenchmarkandde-occlusionattentionmod- ule. In: ACMMM (2020)
2020
-
[34]
arXiv (2025)
Yuan, H., Li, X., Zhang, T., Huang, Z., Xu, S., Ji, S., Tong, Y., Qi, L., Feng, J., Yang, M.H.: Sa2va: Marrying sam2 with llava for dense grounded understanding of images and videos. arXiv (2025)
2025
-
[35]
IJCV (2023)
Zhang, L., Jiang, L., Ji, R., Fan, H.: Pidray: A large-scale x-ray benchmark for real-world prohibited item detection. IJCV (2023)
2023
-
[36]
In: Del Bue, A., Canton, C., Pont-Tuset, J., Tommasi, T
Zhang, S., Sun, P., Chen, S., Xiao, M., Shao, W., Zhang, W., Liu, Y., Chen, K., Luo, P.: Gpt4roi: Instruction tuning large language model on region-of-interest. In: Del Bue, A., Canton, C., Pont-Tuset, J., Tommasi, T. (eds.) Computer Vision – ECCV 2024 Workshops. pp. 52–70. Springer Nature Switzerland, Cham (2025)
2024
-
[37]
ITIFS17, 998–1009 (2022)
Zhao, C., Zhu, L., Dou, S., Deng, W., Wang, L.: Detecting overlapped objects in x-ray security imagery by a label-aware mechanism. ITIFS17, 998–1009 (2022)
2022
-
[38]
scene-caption
Zhu, D., Chen, J., Shen, X., Li, X., Elhoseiny, M.: Minigpt-4: Enhancing vision- language understanding with advanced large language models. In: ICLR (2024) Falcon 1 Appendix –Additional Details on Falcon-X (section 9) –Additional Details on Falcon-X Task Suite Generation (section 10) –Qualitative Results (section 11) –Cross-dataset Evaluation (section 12...
2024
-
[39]
Which components could possibly form an IED. Ground all that apply
Scene captions must describe only visible components. 2. Referring instructions must be uniquely resolvable from spatial metadata. 3. VQA questions must be answerable from structured annotations. 4. Functional links must be inferred using spatial proximity and component types. 5. Risk score guidelines: - 0.0–0.3: benign - 0.3–0.6: incomplete assembly - 0....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.