Graph it first! Enabling Reasoning on Long-form Egocentric Videos through Scene Graphs
Pith reviewed 2026-06-25 20:56 UTC · model grok-4.3
The pith
Egocentric scene graphs convert long videos to compact text so MLLMs can reason over full sequences inside token limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
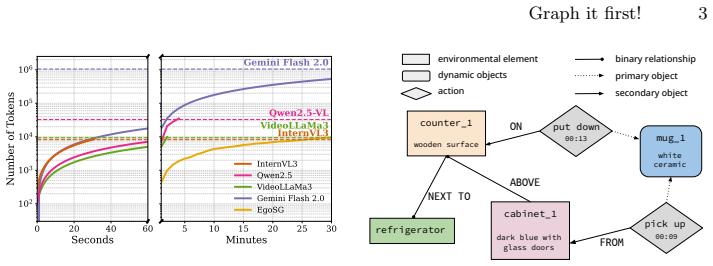
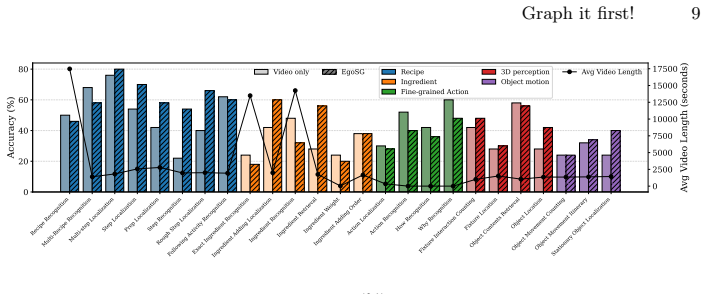
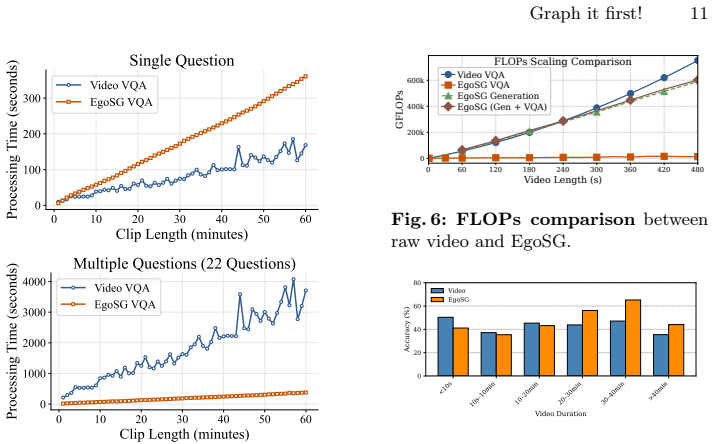
By representing videos as compact, text-based scene graphs called EgoSGs, which are temporally grounded structured representations that capture objects, attributes, spatial relations, and interactions over time, the method preserves the essential visual and temporal information of the original video in a symbolic form that drastically reduces input length while maintaining semantic richness, enabling MLLMs to reason efficiently over entire video sequences within their token budget and achieving state-of-the-art results on HD-EPIC VQA.
What carries the argument
Egocentric Scene Graphs (EgoSGs): temporally grounded, structured text representations that capture objects, attributes, spatial relations, and interactions over time.
If this is right
- MLLMs can accept full-length egocentric videos without forced frame dropping.
- Question-answering accuracy rises on datasets that require fine temporal tracking.
- Structured symbolic input becomes a practical route around context-length walls in video models.
- The same compression principle could extend to other tasks that need both spatial and temporal relations.
Where Pith is reading between the lines
- If graph construction improves, the performance gap versus raw video could widen further.
- The method might transfer to third-person long videos where camera motion is less chaotic.
- Real-time versions could feed live graphs into models for continuous egocentric assistance.
Load-bearing premise
Automatically built scene graphs from egocentric video keep enough semantic detail and correct timing that they do not introduce errors worse than the information loss from frame subsampling.
What would settle it
A controlled test on videos where the automatic graph generator misses key object interactions or state changes, showing that VQA accuracy then falls below the subsampled-video baseline on the same model.
Figures







read the original abstract
Existing multi-modal large language models (MLLMs) face significant challenges in processing long video sequences due to strict input token limitations. As a result, current video understanding approaches, especially in egocentric settings characterized by complex dynamics, frequent state changes, and moving cameras, are forced to massively subsample frames. This leads to severe loss of temporal and contextual information, constraining their ability to perform fine-grained video reasoning. In this work, we introduce a framework for egocentric video question answering (VQA) that overcomes these input constraints through Egocentric Scene Graphs (EgoSGs), i.e., temporally grounded, structured representations that capture objects, attributes, spatial relations, and interactions over time. By representing videos as compact, text-based scene graphs, our method preserves the essential visual and temporal information of the original video in a symbolic form that drastically reduces input length while maintaining semantic richness. Crucially, this enables MLLMs to reason efficiently over entire video sequences within their token budget. On HD-EPIC VQA, our method achieves state-of-the-art results, outperforming strong video-based baselines on multiple models and suggesting that structured, temporally grounded representations like EgoSGs can bridge long-form egocentric video understanding and the context limitations of today's MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Egocentric Scene Graphs (EgoSGs) as temporally grounded, text-based structured representations of long egocentric videos (capturing objects, attributes, spatial relations, and interactions). It claims these graphs preserve essential visual/temporal information in a compact symbolic form, enabling MLLMs to reason over full sequences within token limits and achieving SOTA results on HD-EPIC VQA that outperform video-based baselines across multiple models.
Significance. If the empirical claims hold after proper validation, the work would be significant for long-form video understanding, as it directly addresses MLLM context-length bottlenecks in egocentric settings with complex dynamics. The approach offers a potential bridge between symbolic representations and neural models, with possible extensions to other video tasks.
major comments (2)
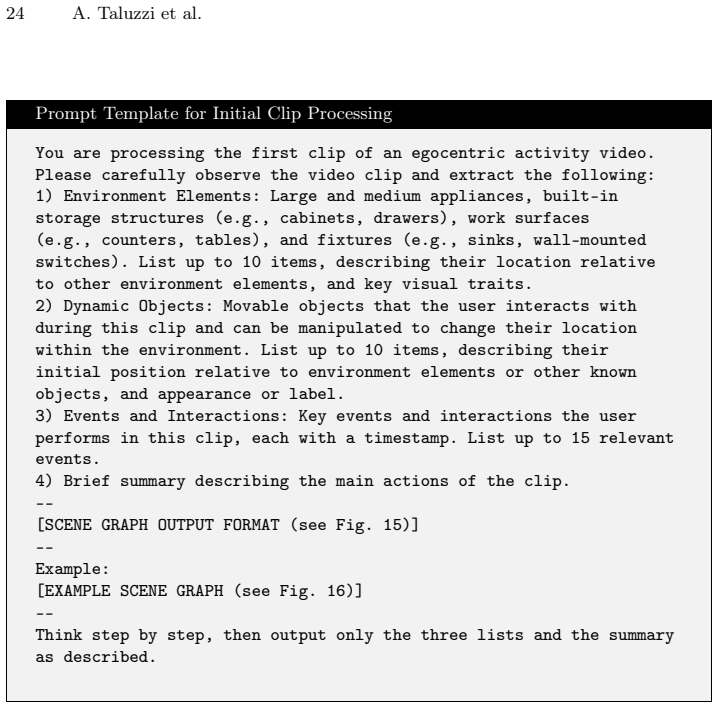
- [§3] §3 (method): The EgoSG construction pipeline (object/attribute/relation extraction + temporal linking via learned vision models) is presented without any quantified error rates, fidelity metrics, or ablation comparing graph-based VQA performance against raw-frame input or ground-truth graphs. This is load-bearing for the central preservation claim and the token-budget advantage.
- [Experiments] Experiments and results sections: SOTA claims on HD-EPIC VQA are asserted without details on baseline implementations, statistical significance tests, error bars, or multiple-run variance, preventing assessment of whether gains are representation-driven or model-specific.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and commit to revisions that directly strengthen the empirical support for our central claims.
read point-by-point responses
-
Referee: §3 (method): The EgoSG construction pipeline (object/attribute/relation extraction + temporal linking via learned vision models) is presented without any quantified error rates, fidelity metrics, or ablation comparing graph-based VQA performance against raw-frame input or ground-truth graphs. This is load-bearing for the central preservation claim and the token-budget advantage.
Authors: We agree that the absence of these metrics weakens the preservation argument. In the revised manuscript we will report precision/recall and temporal consistency metrics for the EgoSG extraction pipeline on a held-out validation set, and add an ablation that compares end-to-end VQA accuracy using (i) EgoSGs, (ii) raw-frame input at the same token budget, and (iii) oracle graphs derived from ground-truth annotations where available. These additions will quantify the information loss (or retention) introduced by the symbolic representation. revision: yes
-
Referee: Experiments and results sections: SOTA claims on HD-EPIC VQA are asserted without details on baseline implementations, statistical significance tests, error bars, or multiple-run variance, preventing assessment of whether gains are representation-driven or model-specific.
Authors: We acknowledge that the current version lacks the requested statistical rigor and implementation transparency. The revision will include: (a) full hyper-parameter and prompting details for every baseline, (b) mean and standard deviation over at least three independent runs with different random seeds, and (c) paired statistical significance tests (e.g., McNemar or Wilcoxon) between EgoSG and the strongest video baseline for each MLLM. These changes will allow readers to evaluate whether the reported gains are attributable to the scene-graph representation. revision: yes
Circularity Check
No derivation chain present; empirical claims only
full rationale
The paper advances an empirical framework for egocentric VQA via EgoSG construction and MLLM input, with SOTA results on HD-EPIC VQA. No equations, fitted parameters, predictions, or mathematical derivations appear in the abstract or described method. The central claim that graphs 'preserve the essential visual and temporal information' is presented as a design motivation and tested via downstream performance, not derived from or reduced to prior steps by construction. No self-citation load-bearing steps or ansatz smuggling are identifiable. This is a standard non-finding for an applied empirical paper without a formal derivation chain.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Egocentric Scene Graphs (EgoSGs)
no independent evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.