Semantic Consistency Policy Optimization for Reinforcement Learning of LLM Agents
Pith reviewed 2026-06-25 20:14 UTC · model grok-4.3
The pith
SCPO mitigates semantic credit inconsistency by recovering step-level credit from successful siblings in the same rollout group.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
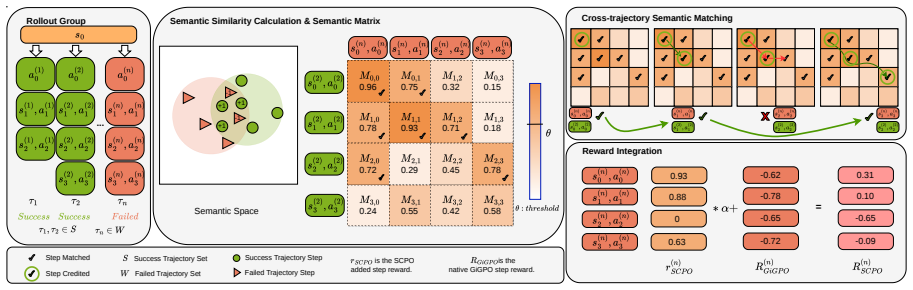
SCPO is a value-free reward-shaping method that mitigates semantic credit inconsistency by recovering step-level credit from successful siblings in the same rollout group. Concretely, SCPO scores each failed step against a successful sibling and adds positive step-level credit for new progress along that sibling.
What carries the argument
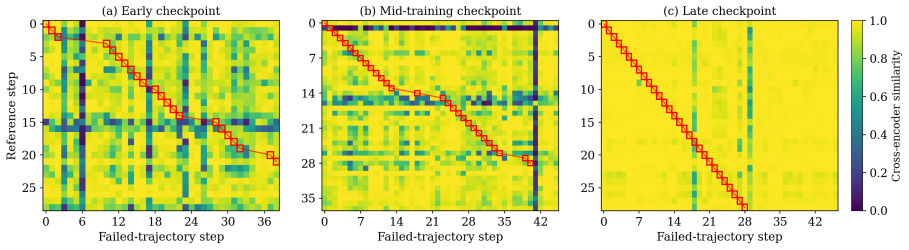
Semantic sibling matching within rollout groups, which identifies near-identical steps across successful and failed trajectories to transfer targeted positive credit.
If this is right
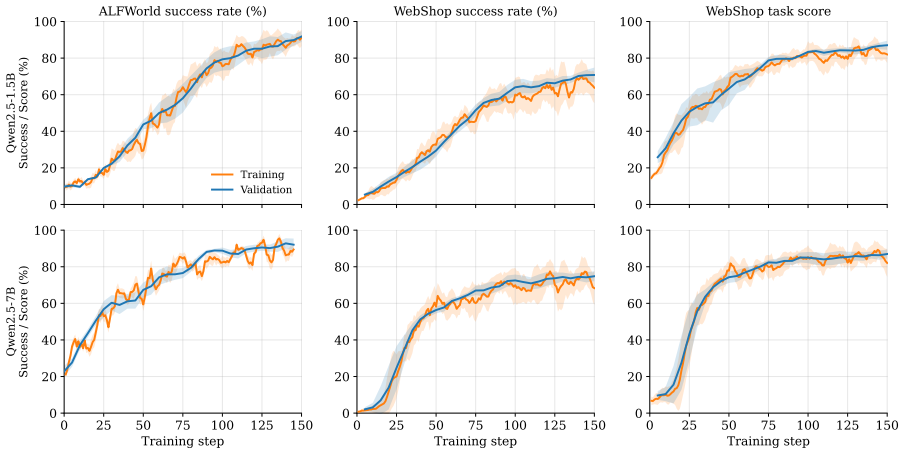
- SCPO reaches 93.7 percent success on ALFWorld and 74.8 percent on WebShop at 1.5B parameters.
- Performance gains concentrate on the hardest multi-step tasks.
- The method remains value-free and requires no separate value estimation.
- Credit is recovered only for new progress along the successful sibling path.
Where Pith is reading between the lines
- The same sibling-credit idea could be tested in non-LLM group-based RL settings that also suffer from sparse final rewards.
- Better semantic similarity metrics might further reduce any residual matching errors.
- The approach suggests that explicit trajectory grouping can substitute for some functions traditionally handled by critics.
Load-bearing premise
Semantically near-identical steps can be reliably matched across successful and failed trajectories and that credit transferred from successful siblings produces correct learning signals rather than new biases.
What would settle it
Running the same ALFWorld and WebShop experiments with SCPO and finding no improvement or outright degradation relative to the group-based baselines would falsify the central claim.
Figures

read the original abstract
Group-based reinforcement learning effectively post-trains LLM agents for long-horizon, sparse-reward tasks by deriving step-level credit from trajectory outcomes. However, this ties a step's credit to its rollout's final outcome: semantically near-identical intermediate steps receive opposite credit depending on whether their trajectory eventually succeeded or failed. Such semantic credit inconsistency sends conflicting gradients to similar actions and wastes the partially-correct progress inside failed rollouts. Motivated by this, we propose Semantic Consistency Policy Optimization (SCPO), a value-free reward-shaping method that mitigates this inconsistency by recovering step-level credit from successful siblings in the same rollout group. Concretely, SCPO scores each failed step against a successful sibling and adds positive step-level credit for new progress along that sibling. On ALFWorld and WebShop, SCPO matches or exceeds strong group-based baselines, reaching 93.7+/-4.1 percent success on ALFWorld and 74.8+/-2.0 percent on WebShop at 1.5B parameters, with gains concentrated on the hardest multi-step tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Semantic Consistency Policy Optimization (SCPO), a value-free reward-shaping method for group-based RL of LLM agents on long-horizon sparse-reward tasks. SCPO mitigates semantic credit inconsistency—where near-identical steps receive opposite credit depending on trajectory outcome—by recovering step-level credit from successful sibling trajectories within the same rollout group, specifically by scoring failed steps against successful ones and adding positive credit for detected new progress. On ALFWorld and WebShop, SCPO matches or exceeds strong baselines, reaching 93.7+/-4.1% success on ALFWorld and 74.8+/-2.0% on WebShop at 1.5B parameters, with gains on hardest multi-step tasks.
Significance. If the semantic step-matching is reliable and credit transfer produces correct signals without new biases, SCPO would usefully address a practical inconsistency in group-based RL for LLM agents by salvaging partial progress from failed rollouts. The reported results include standard deviations and concentrate gains on hard tasks, which strengthens the empirical case if the method details hold.
major comments (2)
- [Abstract and Method description] The central mechanism of SCPO requires an implicit semantic equivalence function (likely embedding- or LLM-based) to identify near-identical steps across trajectories and correctly detect incremental progress along successful siblings. The manuscript provides no description of this matcher, no ablation on matcher quality or accuracy, and no analysis of false-positive credit assignments. This is the load-bearing assumption for the claim that SCPO resolves inconsistency rather than injecting systematic bias.
- [Abstract and Experiments] The abstract reports final success rates (93.7% ALFWorld, 74.8% WebShop) but supplies no implementation details on the matching procedure, rollout grouping, credit computation, ablation results, or error analysis, so the data cannot be checked against the stated claim or reproduced.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the clarity and reproducibility of SCPO. We address each major point below and will revise the manuscript to incorporate additional details on the semantic matcher and implementation specifics.
read point-by-point responses
-
Referee: [Abstract and Method description] The central mechanism of SCPO requires an implicit semantic equivalence function (likely embedding- or LLM-based) to identify near-identical steps across trajectories and correctly detect incremental progress along successful siblings. The manuscript provides no description of this matcher, no ablation on matcher quality or accuracy, and no analysis of false-positive credit assignments. This is the load-bearing assumption for the claim that SCPO resolves inconsistency rather than injecting systematic bias.
Authors: We agree that the initial manuscript insufficiently described the semantic equivalence function, which is central to the method. In the revision we will add a dedicated subsection in the Method section detailing the matcher (cosine similarity over sentence embeddings from a fixed pre-trained model), provide pseudocode for the credit assignment step, include an ablation on matcher accuracy using human-annotated step pairs from ALFWorld, and report an error analysis of false-positive credit transfers with quantitative impact on final performance. revision: yes
-
Referee: [Abstract and Experiments] The abstract reports final success rates (93.7% ALFWorld, 74.8% WebShop) but supplies no implementation details on the matching procedure, rollout grouping, credit computation, ablation results, or error analysis, so the data cannot be checked against the stated claim or reproduced.
Authors: We acknowledge that key implementation details were not sufficiently prominent for verification. The revised version will expand the Experiments and Method sections with explicit descriptions of the matching procedure, rollout grouping (fixed group size of 8), the exact credit computation formula, ablation tables, and error analysis; these will also be summarized briefly in the abstract where space permits, ensuring full reproducibility. revision: yes
Circularity Check
No significant circularity; derivation is descriptive with no equations or self-referential reductions shown
full rationale
The provided manuscript text (abstract and description) contains no equations, derivations, fitted parameters, or self-citations that reduce the claimed SCPO method to its inputs by construction. The method is presented as a reward-shaping heuristic that scores failed steps against successful siblings, but without any mathematical formulation or load-bearing self-reference, the central claim remains independent of the patterns that would trigger circularity flags. This is the expected honest non-finding for a paper whose contribution is algorithmic description rather than a closed-form derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam and others (OpenAI). 2023. GPT-4 technical report. arXiv preprint arXiv:2303.08774
Pith/arXiv arXiv 2023
-
[2]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. M3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. In Findings of the Association for Computational Linguistics: ACL 2024, pages 2318--2335
2024
-
[3]
Wentse Chen, Jiayu Chen, Hao Zhu, and Jeff Schneider. 2025. https://openreview.net/forum?id=6CE5PLsZdW Context-lite multi-turn reinforcement learning for LLM agents . In ICML 2025 Workshop
2025
-
[4]
Sanjiban Choudhury. 2025. https://github.com/sanjibanc/agent_prm Process reward models for LLM agents: Practical framework and directions . arXiv preprint arXiv:2502.10325
arXiv 2025
-
[5]
Cormen, Charles E
Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. 2009. Introduction to Algorithms, 3 edition. MIT Press
2009
-
[6]
Fu, Stefano Ermon, Atri Rudra, and Christopher R \'e
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher R \'e . 2022. FlashAttention : Fast and memory-efficient exact attention with IO -awareness. In Advances in Neural Information Processing Systems (NeurIPS)
2022
-
[7]
DeepSeek-AI. 2025. DeepSeek-R1 : Incentivizing reasoning capability in LLM s via reinforcement learning. Nature, 645:633--638
2025
-
[8]
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. 2025. https://github.com/langfengQ/verl-agent Group-in-group policy optimization for LLM agent training . In Advances in Neural Information Processing Systems (NeurIPS)
2025
-
[9]
Google Gemini Team. 2024. Gemini: A family of highly capable multimodal models. arXiv preprint arXiv:2312.11805
Pith/arXiv arXiv 2024
-
[10]
van Hasselt, Greg Wayne, Satinder Singh, Doina Precup, and R \'e mi Munos
Anna Harutyunyan, Will Dabney, Thomas Mesnard, Mohammad Gheshlaghi Azar, Bilal Piot, Nicolas Heess, Hado P. van Hasselt, Greg Wayne, Satinder Singh, Doina Precup, and R \'e mi Munos. 2019. Hindsight credit assignment. In Advances in Neural Information Processing Systems (NeurIPS)
2019
-
[11]
Shuo He, Lang Feng, Qi Wei, Xin Cheng, Lei Feng, and Bo An. 2026. Hierarchy-of-groups policy optimization for long-horizon agentic tasks. In International Conference on Learning Representations (ICLR)
2026
-
[12]
Jonathan Ho and Stefano Ermon. 2016. Generative adversarial imitation learning. In Advances in Neural Information Processing Systems (NeurIPS)
2016
-
[13]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. Search-R1 : Training LLM s to reason and leverage search engines with reinforcement learning. In Conference on Language Modeling (COLM)
2025
-
[14]
Knuth, James H
Donald E. Knuth, James H. Morris, and Vaughan R. Pratt. 1977. Fast pattern matching in strings. SIAM Journal on Computing, 6(2):323--350
1977
-
[15]
Aobo Kong, Wentao Ma, Shiwan Zhao, Yongbin Li, Yuchuan Wu, Ke Wang, Xiaoqian Liu, Qicheng Li, Yong Qin, and Fei Huang. 2025. SDPO : Segment-level direct preference optimization for social agents. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL)
2025
-
[16]
Wouter Kool, Herke van Hoof, and Max Welling. 2019. Buy 4 REINFORCE samples, get a baseline for free! ICLR 2019 Workshop: Deep Reinforcement Learning Meets Structured Prediction
2019
-
[17]
Xiaoqian Liu, Ke Wang, Yuchuan Wu, Fei Huang, Yongbin Li, Junge Zhang, and Jianbin Jiao. 2025. Agentic reinforcement learning with implicit step rewards. arXiv preprint arXiv:2509.19199
arXiv 2025
-
[18]
Andrew Y Ng, Daishi Harada, and Stuart Russell. 1999. Policy invariance under reward transformations: Theory and application to reward shaping. In Proceedings of the Sixteenth International Conference on Machine Learning (ICML)
1999
-
[19]
Junhyuk Oh, Yijie Guo, Satinder Singh, and Honglak Lee. 2018. Self-imitation learning. In Proceedings of the 35th International Conference on Machine Learning (ICML)
2018
-
[20]
Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems (NeurIPS), 35:27730--27744
2022
-
[21]
Francesco Pappone, Ruggero Marino Lazzaroni, Federico Califano, Niccol\`o Gentile, and Roberto Marras. 2025. Shaping explanations: Semantic reward modeling with encoder-only transformers for GRPO . arXiv preprint arXiv:2509.13081
arXiv 2025
-
[22]
Eduardo Pignatelli, Johan Ferret, Matthieu Geist, Thomas Mesnard, Hado van Hasselt, and Laura Toni. 2024. A survey of temporal credit assignment in deep reinforcement learning. Transactions on Machine Learning Research
2024
-
[23]
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani-T\"ur, Gokhan Tur, and Heng Ji. 2025. ToolRL : Reward is all tool learning needs. In Advances in Neural Information Processing Systems (NeurIPS)
2025
-
[24]
Yulei Qin, Xiaoyu Tan, Zhengbao He, Gang Li, Haojia Lin, Zongyi Li, Zihan Xu, Yuchen Shi, Siqi Cai, Renting Rui, and 1 others. 2026. Learn the ropes, then trust the wins: Self-imitation with progressive exploration for agentic reinforcement learning. In International Conference on Learning Representations (ICLR)
2026
-
[25]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347
Pith/arXiv arXiv 2017
-
[26]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, and 1 others. 2024. DeepSeekMath : Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300
Pith/arXiv arXiv 2024
-
[27]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion : Language agents with verbal reinforcement learning. In Advances in Neural Information Processing Systems (NeurIPS)
2023
-
[28]
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mottaghi, Luke Zettlemoyer, and Dieter Fox. 2020. ALFRED : A benchmark for interpreting grounded instructions for everyday tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2020
-
[29]
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre C\^ot\'e, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. 2021. ALFW orld: Aligning text and embodied environments for interactive learning. In International Conference on Learning Representations (ICLR)
2021
-
[30]
Hui-Ze Tan, Xiao-Wen Yang, Hao Chen, Jie-Jing Shao, Yi Wen, Yuteng Shen, Weihong Luo, Xiku Du, Lan-Zhe Guo, and Yu-Feng Li. 2026. Hindsight credit assignment for long-horizon LLM agents. arXiv preprint arXiv:2603.08754
arXiv 2026
-
[31]
Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t- SNE . Journal of Machine Learning Research, 9:2579--2605
2008
-
[32]
Hanlin Wang, Chak Tou Leong, Jiashuo Wang, Jian Wang, and Wenjie Li. 2025 a . SPA-RL : Reinforcing LLM agents via stepwise progress attribution. arXiv preprint arXiv:2505.20732
arXiv 2025
-
[33]
Jiawei Wang, Jiacai Liu, Yuqian Fu, Yingru Li, Xintao Wang, Yuan Lin, Yu Yue, Lin Zhang, Yang Wang, and Ke Wang. 2025 b . Harnessing uncertainty: Entropy-modulated policy gradients for long-horizon LLM agents. arXiv preprint arXiv:2509.09265
arXiv 2025
-
[34]
Tao Wang, Suhang Zheng, and Xiaoxiao Xu. 2026. RTMC : Step-level credit assignment via rollout trees. arXiv preprint arXiv:2604.11037
Pith/arXiv arXiv 2026
-
[35]
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. 2020. Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. In Advances in Neural Information Processing Systems (NeurIPS)
2020
-
[36]
Ziliang Wang, Xuhui Zheng, Kang An, Cijun Ouyang, Jialu Cai, Yuhang Wang, and Yichao Wu. 2025 c . StepSearch : Igniting LLMs search ability via step-wise proximal policy optimization. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP)
2025
-
[37]
Zhiheng Xi, Chenyang Liao, Guanyu Li, Yajie Yang, Wenxiang Chen, Zhihao Zhang, Binghai Wang, Senjie Jin, Yuhao Zhou, Jian Guan, Wei Wu, Tao Ji, Tao Gui, Qi Zhang, and Xuanjing Huang. 2025. AgentPRM : Process reward models for LLM agents via step-wise promise and progress. arXiv preprint arXiv:2511.08325
arXiv 2025
-
[38]
Yu Xia, Jingru Fan, Weize Chen, Siyu Yan, Xin Cong, Zhong Zhang, Yaxi Lu, Yankai Lin, Zhiyuan Liu, and Maosong Sun. 2025. AgentRM : Enhancing agent generalization with reward modeling. arXiv preprint arXiv:2502.18407
arXiv 2025
-
[39]
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. 2022. WebShop : Towards scalable real-world web interaction with grounded language agents. In Advances in Neural Information Processing Systems (NeurIPS)
2022
-
[40]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct : Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR)
2023
-
[41]
Qiying Yu and 1 others. 2025. DAPO : An open-source LLM reinforcement learning system at scale. arXiv preprint arXiv:2503.14476
Pith/arXiv arXiv 2025
-
[42]
Jiazheng Zhang, Ziche Fu, Zhiheng Xi, Wenqing Jing, Mingxu Chai, Wei He, Guoqiang Zhang, Chenghao Fan, Chenxin An, Wenxiang Chen, and 1 others. 2026. AgentV-RL : Scaling reward modeling with agentic verifier. arXiv preprint arXiv:2604.16004
Pith/arXiv arXiv 2026
-
[43]
Weinberger, and Yoav Artzi
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020. BERTS core: Evaluating text generation with BERT . In International Conference on Learning Representations (ICLR)
2020
-
[44]
Zijing Zhang, Ziyang Chen, Mingxiao Li, Zhaopeng Tu, and Xiaolong Li. 2025. RLVMR : Reinforcement learning with verifiable meta-reasoning rewards for robust long-horizon agents. arXiv preprint arXiv:2507.22844
arXiv 2025
-
[45]
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, and 1 others. 2023. PyTorch FSDP : Experiences on scaling fully sharded data parallel. Proceedings of the VLDB Endowment, 16(12):3848--3860
2023
-
[46]
Siyu Zhu, Yanbin Jiang, Hejian Sang, Shao Tang, Qingquan Song, Biao He, Rohit Jain, Zhipeng Wang, and Alborz Geramifard. 2025. Planner- R1 : Reward shaping enables efficient agentic RL with smaller LLMs . arXiv preprint arXiv:2509.25779
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.