SurgAtlas: A Large-Scale Surgical Video-Language Dataset with 2,391 Hours of Open and Minimally Invasive Surgery
Pith reviewed 2026-06-25 20:37 UTC · model grok-4.3
The pith
SurgAtlas supplies 2,391 hours of public surgical video with layered language annotations to train multimodal models for surgery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
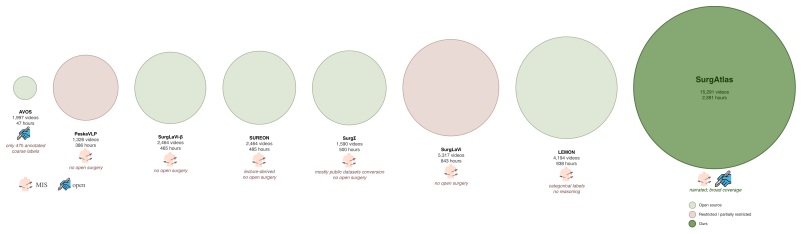
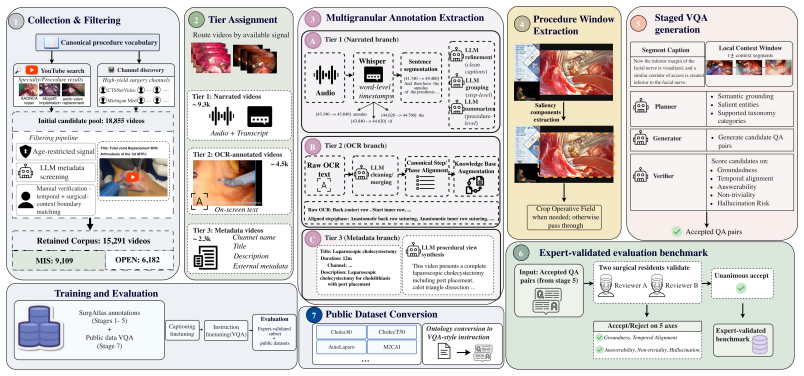
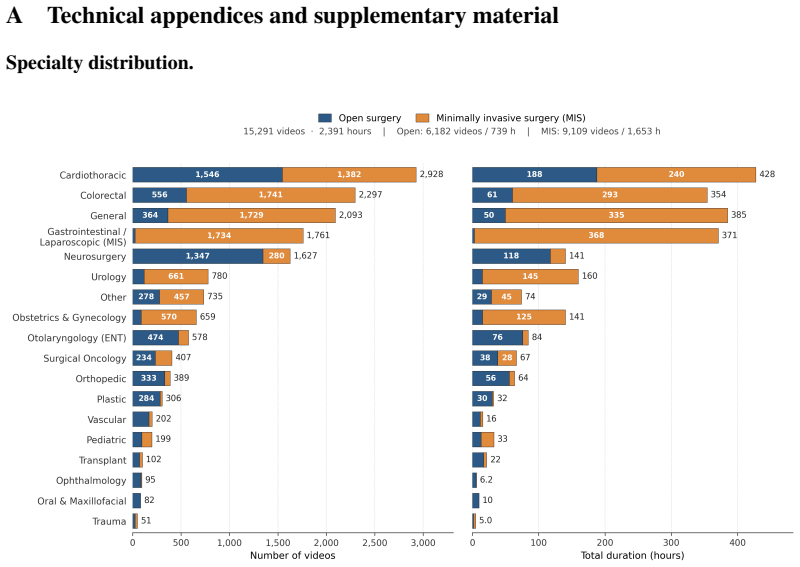
SurgAtlas is the largest surgical video-language dataset to date, comprising 15,291 videos (2,391 hours) spanning 18 specialties and over 5,000 procedure types, with 6,182 open-procedure videos alongside more than 9,000 minimally invasive recordings. It supplies one of the most diverse annotation schemas through an automated multi-tier pipeline with LLM-based enrichment and a staged VQA generation framework, plus an expert-validated subset of verified visual question-answer pairs. Fine-tuning Qwen3-VL-8B via a two-stage captioning-then-instruction pipeline on this data produces competitive or state-of-the-art results on multiple surgical benchmarks including phase recognition, triplet detect
What carries the argument
The automated multi-tier pipeline with LLM-based enrichment and staged VQA generation framework that creates segment-level captions, phase and step descriptions, video-level summaries, and grounded reasoning question-answer pairs at scale.
If this is right
- The dataset enables training of models with broad procedural coverage across open and minimally invasive surgery.
- It establishes the first standardized benchmarks specifically for open-surgery video understanding.
- The public corpus supports large-scale pretraining of multimodal surgical AI systems.
- Hierarchical annotations allow models to learn at multiple levels of temporal granularity.
- The expert-validated subset serves as a clinically grounded testbed for surgical reasoning tasks.
Where Pith is reading between the lines
- Public sourcing from YouTube may allow repeated updates as new surgical videos appear online.
- The combination of open and minimally invasive data could help models handle the wider range of visual conditions encountered in real operating rooms.
- The scale may reduce dependence on limited private hospital datasets for surgical AI development.
- The annotation taxonomy could be reused to label new videos from robotic surgery platforms.
Load-bearing premise
The automated multi-tier pipeline with LLM-based enrichment produces accurate, clinically grounded annotations at scale without introducing significant errors or biases.
What would settle it
A random sample of several hundred generated question-answer pairs or captions reviewed by multiple surgeons showing a high rate of clinically inaccurate or ungrounded content.
Figures

read the original abstract
We introduce SurgAtlas, the largest surgical video-language dataset to date, comprising 15,291 videos (2,391 hours) spanning 18 surgical specialties and over 5,000 procedure types, sourced entirely from publicly available YouTube content. SurgAtlas is also the first surgical video-language dataset to include open surgery at scale, with 6,182 open procedure videos alongside over 9,000 minimally invasive recordings, and the first to establish standardized benchmarks for open-surgery video understanding. We additionally provide an expert-validated subset with verified visual question-answer pairs across diverse open and minimally invasive procedures, serving as a clinically grounded benchmark for surgical reasoning. Compared with existing surgical video-language datasets, SurgAtlas provides one of the most diverse annotation schemas, combining segment-level captions, step- and phase-level descriptions, video-level surgical descriptions, and reasoning-oriented question-answer pairs organized within a hierarchical taxonomy. These annotations are constructed through an automated multi-tier pipeline with LLM-based enrichment and a staged VQA generation framework with explicit groundedness verification. The scale and diversity of SurgAtlas enable training surgical foundation models with broad procedural coverage: we finetune Qwen3-VL-8B through a two-stage captioning-then-instruction pipeline and achieve competitive or state-of-the-art results on multiple established surgical benchmarks, including phase recognition, triplet detection, and reasoning question answering. More broadly, SurgAtlas provides a large native public video corpus that can support future large-scale pretraining of multimodal surgical AI systems and contribute to the development of next-generation foundation models for surgery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SurgAtlas, the largest surgical video-language dataset to date, comprising 15,291 YouTube-sourced videos (2,391 hours) across 18 specialties and >5,000 procedure types, with substantial open-surgery coverage (6,182 videos). Annotations follow a hierarchical schema (segment captions, phase/step descriptions, video-level summaries, and VQA pairs) generated by an automated multi-tier LLM pipeline with groundedness verification; an expert-validated VQA subset is provided as a benchmark. The authors demonstrate utility by finetuning Qwen3-VL-8B via a two-stage captioning-then-instruction process, reporting competitive or state-of-the-art results on phase recognition, triplet detection, and reasoning QA benchmarks.
Significance. If the central claims hold, SurgAtlas would be a significant contribution as the first large-scale public resource explicitly including open surgery at this volume and the first to define standardized open-surgery benchmarks. The scale, diversity of specialties/procedures, and hierarchical annotation schema are clear strengths that could support broader pretraining of surgical foundation models. The release of a native public video corpus and an expert-validated VQA subset are also positive.
major comments (2)
- [Section 3] Section 3 (Dataset Construction and Annotation Pipeline): Expert validation with quantitative statistics (accuracy, agreement rates, or error analysis) is reported only for the VQA subset. The bulk annotations—segment-level captions, step/phase descriptions, and video-level summaries generated by the automated LLM pipeline—are used for the two-stage finetuning that underpins the benchmark results, yet no validation metrics or bias assessment (e.g., for open-surgery visuals or rare procedures) are provided. This directly affects whether the reported gains can be attributed to data quality.
- [Section 5] Section 5 (Experiments and Results): The competitive/SOTA claims on phase recognition, triplet detection, and reasoning QA are presented without ablations that isolate the effect of SurgAtlas annotations versus potential label noise or biases introduced by the LLM pipeline. No comparison is shown to models trained on prior datasets using the identical pipeline, making it impossible to confirm that the improvements stem from the new data rather than the training procedure itself.
minor comments (2)
- [Abstract] Abstract and Section 2: The exact count of procedure types (stated as 'over 5,000') should be reported precisely in the main text or a table for reproducibility.
- Figure captions and tables summarizing dataset statistics should include explicit definitions of all categories (e.g., what constitutes a 'step' versus 'phase') to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments. We address each major point below and outline revisions to strengthen the manuscript's claims on data quality and experimental rigor.
read point-by-point responses
-
Referee: [Section 3] Section 3 (Dataset Construction and Annotation Pipeline): Expert validation with quantitative statistics (accuracy, agreement rates, or error analysis) is reported only for the VQA subset. The bulk annotations—segment-level captions, step/phase descriptions, and video-level summaries generated by the automated LLM pipeline—are used for the two-stage finetuning that underpins the benchmark results, yet no validation metrics or bias assessment (e.g., for open-surgery visuals or rare procedures) are provided. This directly affects whether the reported gains can be attributed to data quality.
Authors: We acknowledge that expert validation is provided only for the VQA subset, as full manual review of 15,291 videos is not feasible. The bulk annotations rely on the multi-tier LLM pipeline with explicit groundedness verification. In the revision, we will expand Section 3 with additional details on the verification process and include a quantitative error analysis on a sampled subset (e.g., 500 annotations stratified by open vs. MIS and procedure rarity), reporting agreement metrics and bias observations where available. This addresses the concern without overclaiming full expert coverage. revision: partial
-
Referee: [Section 5] Section 5 (Experiments and Results): The competitive/SOTA claims on phase recognition, triplet detection, and reasoning QA are presented without ablations that isolate the effect of SurgAtlas annotations versus potential label noise or biases introduced by the LLM pipeline. No comparison is shown to models trained on prior datasets using the identical pipeline, making it impossible to confirm that the improvements stem from the new data rather than the training procedure itself.
Authors: We agree that the current experiments do not isolate the contribution of SurgAtlas annotations from the training procedure or potential pipeline noise. In the revised manuscript, we will add the requested ablations: retraining Qwen3-VL-8B on prior datasets using the identical two-stage captioning-then-instruction pipeline and directly comparing results to the SurgAtlas-trained model on the same benchmarks. This will clarify the source of performance gains. revision: yes
Circularity Check
No circularity; dataset paper with no derivations or self-referential predictions
full rationale
This is a dataset introduction paper whose central contribution is the construction and release of SurgAtlas via an automated multi-tier LLM pipeline, followed by empirical finetuning of Qwen3-VL-8B on external established benchmarks (phase recognition, triplet detection, reasoning QA). No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The claim of competitive/SOTA results is an empirical outcome on independent benchmarks rather than a reduction to the paper's own inputs by construction. Annotation accuracy is a correctness issue, not a circularity issue.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Publicly available YouTube videos provide representative and high-quality samples of real surgical procedures across specialties
Reference graph
Works this paper leans on
-
[1]
Lavanchy, Jacques Marescaux, Pietro Mascagni, Nassir Navab, and Nicolas Padoy
Kun Yuan, Vinkle Srivastav, Tong Yu, Joël L. Lavanchy, Jacques Marescaux, Pietro Mascagni, Nassir Navab, and Nicolas Padoy. Learning multi-modal representations by watching hundreds of surgical video lectures.Medical Image Analysis, 105:103644, 2025. doi: 10.1016/j.media.2025.103644
-
[2]
Hecvl: Hierarchical video-language pretraining for zero-shot surgical phase recognition
Kun Yuan, Vinkle Srivastav, Nassir Navab, and Nicolas Padoy. Hecvl: Hierarchical video-language pretraining for zero-shot surgical phase recognition. InMedical Image Computing and Computer Assisted Intervention – MICCAI 2024, pages 306–316. Springer, 2024. 11
2024
-
[3]
Procedure-aware surgical video-language pretraining with hierarchical knowledge augmentation
Kun Yuan, Vinkle Srivastav, Nassir Navab, and Nicolas Padoy. Procedure-aware surgical video-language pretraining with hierarchical knowledge augmentation. InAdvances in Neural Information Processing Systems, volume 37, 2024
2024
-
[4]
Surglavi: Large-scale hierarchical dataset for surgical vision-language representation learning
Alejandra Perez, Chinedu Innocent Nwoye, Ramtin Raji Kermani, Omid Mohareri, and Muhammad Abdul- lah Jamal. Surglavi: Large-scale hierarchical dataset for surgical vision-language representation learning. Medical Image Analysis, 107:103825, 2026. doi: 10.1016/j.media.2026.103825
-
[5]
Alejandra Perez, Anita Rau, Lee White, Busisiwe Mlambo, Chinedu Nwoye, Muhammad Abdullah Jamal, and Omid Mohareri. SUREON: A benchmark and vision-language-model for surgical reasoning.arXiv preprint arXiv:2603.06570, 2026
arXiv 2026
-
[6]
Zhitao Zeng, Zhu Zhuo, Xiaojun Jia, Erli Zhang, Junde Wu, Jiaan Zhang, Yuxuan Wang, Chang Han Low, Jian Jiang, Zilong Zheng, Xiaochun Cao, Yutong Ban, Qi Dou, Yang Liu, and Yueming Jin. SurgVLM: A large vision-language model and systematic evaluation benchmark for surgical intelligence.arXiv preprint arXiv:2506.02555, 2025
arXiv 2025
-
[7]
Zhitao Zeng, Mengya Xu, Jian Jiang, Pengfei Guo, Yunqiu Xu, Zhu Zhuo, Chang Han Low, Yufan He, Dong Yang, Chenxi Lin, Yiming Gu, Jiaxin Guo, Yutong Ban, Daguang Xu, Qi Dou, and Yueming Jin. SurgΣ: A spectrum of large-scale multimodal data and foundation models for surgical intelligence.arXiv preprint arXiv:2603.16822, 2026
arXiv 2026
-
[8]
Zhen Chen, Xingjian Luo, Kun Yuan, Jinlin Wu, Danny T. M. Chan, Nassir Navab, Hongbin Liu, Zhen Lei, and Jiebo Luo. SurgLLM: A versatile large multimodal model with spatial focus and temporal awareness for surgical video understanding.arXiv preprint arXiv:2509.00357, 2025
arXiv 2025
-
[9]
Guankun Wang, Long Bai, Junyi Wang, Kun Yuan, Zhen Li, Tianxu Jiang, Xiting He, Jinlin Wu, Zhen Chen, Zhen Lei, Hongbin Liu, Jiazheng Wang, Fan Zhang, Nicolas Padoy, Nassir Navab, and Hongliang Ren. Endochat: Grounded multimodal large language model for endoscopic surgery.Medical Image Analysis, 107:103789, 2026. doi: 10.1016/j.media.2025.103789
-
[10]
Emmett D. Goodman, Krishna K. Patel, Yilun Zhang, William Locke, Chris J. Kennedy, Rohan Mehrotra, Stephen Ren, Melody Guan, Orr Zohar, Maren Downing, Hao Wei Chen, Jevin Z. Clark, Margaret T. Berrigan, Gabriel A. Brat, and Serena Yeung-Levy. Analyzing surgical technique in diverse open surgical videos with multitask machine learning.JAMA Surgery, 159(2):...
-
[11]
EgoSurgery-Phase: A dataset of surgical phase recognition from egocentric open surgery videos
Ryo Fujii, Masashi Hatano, Hideo Saito, and Hiroki Kajita. EgoSurgery-Phase: A dataset of surgical phase recognition from egocentric open surgery videos. InMedical Image Computing and Computer Assisted Intervention – MICCAI 2024, volume 15006 ofLecture Notes in Computer Science, pages 184–195. Springer Nature Switzerland, 2024. doi: 10.1007/978-3-031-72089-5_18
-
[12]
IEEE Transactions on Medical Imaging36(1), 86–97 (2017).https://doi.org/10.1109/TMI.2016.2593957
Apriyana P. Twinanda, Shekoofeh Shehata, Didier Mutter, Jacques Marescaux, Michel Mathelin, and Nicolas Padoy. Endonet: A deep architecture for recognition tasks on laparoscopic videos.IEEE Transactions on Medical Imaging, 36(1):86–97, 2017. doi: 10.1109/TMI.2016.2593957
-
[13]
Medi- cal Image Analysis88, 102846 (Aug 2023).https://doi.org/10.1016/j.media
Chinedu Innocent Nwoye, Tong Yu, Cristians Gonzalez, Barbara Seeliger, Pietro Mascagni, Didier Mutter, Jacques Marescaux, and Nicolas Padoy. Rendezvous: Attention mechanisms for the recognition of surgical action triplets in endoscopic videos.Medical Image Analysis, 78:102433, 2022. doi: 10.1016/j.media. 2022.102433
-
[14]
Ziyi Wang, Bo Lu, Yonghao Long, Fangxun Zhong, Tak-Hong Cheung, Qi Dou, and Yunhui Liu. Au- tolaparo: A new dataset of integrated multi-tasks for image-guided surgical automation in laparoscopic hysterectomy. InMedical Image Computing and Computer Assisted Intervention – MICCAI 2022, pages 486–496. Springer, 2022. doi: 10.1007/978-3-031-16449-1_46
-
[15]
Lavanchy, Orestis Zisimopoulos, Pietro Mascagni, Didier Mutter, and Nicolas Padoy
Joël L. Lavanchy, Orestis Zisimopoulos, Pietro Mascagni, Didier Mutter, and Nicolas Padoy. Challenges in multi-centric generalization: Phase and step recognition in roux-en-y gastric bypass surgery.International Journal of Computer Assisted Radiology and Surgery, 2024. doi: 10.1007/s11548-024-03166-3
-
[16]
Dimitrios Psychogyios, Emanuele Colleoni, Beatrice Van Amsterdam, Chih-Yang Li, Shu-Yu Huang, Yuchong Li, Fucang Jia, Baosheng Zou, Guotai Wang, Yang Liu, Maxence Boels, Jiayu Huo, Rachel Sparks, Prokar Dasgupta, Alejandro Granados, Sebastien Ourselin, Mengya Xu, An Wang, Yanan Wu, Long Bai, Hongliang Ren, Atsushi Yamada, Yuriko Harai, Yuto Ishikawa, Kazu...
arXiv 2024
-
[17]
Cataract-101: Video dataset of 101 cataract surgeries
Klaus Schoeffmann, Mario Taschwer, Stephanie Sarny, Bernd Münzer, Manfred Jürgen Primus, and Doris Putzgruber. Cataract-101: Video dataset of 101 cataract surgeries. InProceedings of the 9th ACM Multimedia Systems Conference, pages 421–425, 2018. doi: 10.1145/3204949.3208137
-
[18]
Garcia-Peraza-Herrera
Chengan Che, Chao Wang, Tom Vercauteren, Sophia Tsoka, and Luis C. Garcia-Peraza-Herrera. LEMON: A large endoscopic MONocular dataset and foundation model for perception in surgical settings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026
2026
-
[19]
Jianhui Wei, Zikai Xiao, Danyu Sun, Luqi Gong, Zongxin Yang, Zuozhu Liu, and Jian Wu. SurgBench: A unified large-scale benchmark for surgical video analysis.arXiv preprint arXiv:2506.07603, 2025
arXiv 2025
-
[20]
Shu Yang, Fengtao Zhou, Leon Mayer, Fuxiang Huang, Yiliang Chen, Yihui Wang, Sunan He, Yuxi- ang Nie, Xi Wang, Yueming Jin, Huihui Sun, Shuchang Xu, Alex Qinyang Liu, Zheng Li, Jing Qin, Jeremy YuenChun Teoh, Lena Maier-Hein, and Hao Chen. Large-scale self-supervised video foundation model for intelligent surgery.npj Digital Medicine, 9:220, 2026. doi: 10...
-
[21]
Samuel Schmidgall, Ji Woong Kim, Jeffrey Jopling, and Axel Krieger. General surgery vision transformer: A video pre-trained foundation model for general surgery.arXiv preprint arXiv:2403.05949, 2024
arXiv 2024
-
[22]
CPT® (Current Procedural Terminology)
American Medical Association. CPT® (Current Procedural Terminology). https://www.ama-assn. org/practice-management/cpt, 2026
2026
-
[23]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 28492–28518. PMLR, 2023
2023
-
[24]
Müller-Stich, Anastasia Kisilenko, Danail Tran, Philipp Heger, Maximilian Müller, Hannes G
Martin Wagner, Beat P. Müller-Stich, Anastasia Kisilenko, Danail Tran, Philipp Heger, Maximilian Müller, Hannes G. Kenngott, Felix Nickel, and Stefanie Speidel. Comparative validation of machine learning algorithms for surgical workflow and skill analysis with the heichole benchmark.Medical Image Analysis, 86:102770, 2023. doi: 10.1016/j.media.2023.102770
-
[25]
The TUM LapChole dataset for the M2CAI 2016 workflow challenge.arXiv preprint arXiv:1610.09278, 2016
Ralf Stauder, Daniel Ostler, Michael Kranzfelder, Sebastian Koller, Hubertus Feußner, and Nassir Navab. The TUM LapChole dataset for the M2CAI 2016 workflow challenge.arXiv preprint arXiv:1610.09278, 2016
Pith/arXiv arXiv 2016
-
[26]
Negin Ghamsarian, Yosuf El-Shabrawi, Sahar Nasirihaghighi, Doris Putzgruber-Adamitsch, Martin Zinkernagel, Sebastian Wolf, Klaus Schoeffmann, and Raphael Sznitman. Cataract-1K dataset for deep-learning-assisted analysis of cataract surgery videos.Scientific Data, 11(1):373, 2024. doi: 10.1038/s41597-024-03193-4
-
[27]
2017 robotic instrument segmentation challenge.arXiv preprint arXiv:1902.06426, 2019
Max Allan, Alex Shvets, Thomas Kurmann, Zichen Zhang, Rahul Duggal, Yun-Hsuan Su, Nicola Rieke, Iro Laina, Niveditha Kalavakonda, Sebastian Bodenstedt, Luis Herrera, Wenqi Li, Vladimir Iglovikov, Huoling Luo, Jian Yang, Danail Stoyanov, Lena Maier-Hein, Stefanie Speidel, and Mahdi Azizian. 2017 robotic instrument segmentation challenge.arXiv preprint arXi...
Pith/arXiv arXiv 2017
-
[28]
2018 robotic scene segmentation challenge.arXiv preprint arXiv:2001.11190, 2020
Max Allan, Satoshi Kondo, Sebastian Bodenstedt, Stefan Leger, Rahim Kadkhodamohammadi, Imanol Lu- engo, Felix Fuentes, Evangello Flouty, Ahmed Mohammed, Marius Pedersen, Avinash Kori, Varghese Alex, Ganapathy Krishnamurthi, David Rauber, Robert Mendel, Christoph Palm, Sophia Bano, Guinther Saibro, Chi-Sheng Shih, Hsun-An Chiang, Juntang Zhuang, Junlin Yan...
arXiv 2018
-
[29]
Andreas Leibetseder, Stefan Petscharnig, Manfred Jürgen Primus, Sabrina Kletz, Bernd Münzer, Klaus Schoeffmann, and Jörg Keckstein. LapGyn4: A dataset for 4 automatic content analysis problems in the domain of laparoscopic gynecology. InProceedings of the 9th ACM Multimedia Systems Conference, pages 357–362, 2018. doi: 10.1145/3204949.3208127
-
[30]
Nicolás Ayobi, Santiago Rodríguez, Alejandra Pérez, Isabela Hernández, Nicolás Aparicio, Eugénie Dessevres, Sebastián Peña, Jessica Santander, Juan Ignacio Caicedo, Nicolás Fernández, and Pablo Arbeláez. Pixel-wise recognition for holistic surgical scene understanding.Medical Image Analysis, 106: 103726, 2025. doi: 10.1016/j.media.2025.103726. 13
-
[31]
W.-Y . Hong, C.-L. Kao, Y .-H. Kuo, J.-R. Wang, W.-L. Chang, and C.-S. Shih. CholecSeg8k: A semantic seg- mentation dataset for laparoscopic cholecystectomy based on Cholec80.arXiv preprint arXiv:2012.12453, 2020
arXiv 2012
-
[32]
Scientific Data12(1), 331 (2025).https://doi.org/ 10.1038/s41597-025-04642-4
Pietro Mascagni, Deepak Alapatt, Aditya Murali, Armine Vardazaryan, Alain Garcia, Nariaki Okamoto, Guido Costamagna, Didier Mutter, Jacques Marescaux, Bernard Dallemagne, and Nicolas Padoy. En- doscapes, a critical view of safety and surgical scene segmentation dataset for laparoscopic cholecystectomy. Scientific Data, 12:331, 2025. doi: 10.1038/s41597-02...
-
[33]
Runlong He, Mengya Xu, Adrito Das, Danyal Z. Khan, Sophia Bano, Hani J. Marcus, Danail Stoyanov, Matthew J. Clarkson, and Mobarakol Islam. PitVQA: Image-grounded text embedding LLM for visual question answering in pituitary surgery. InMedical Image Computing and Computer Assisted Intervention – MICCAI 2024, volume 15006 ofLecture Notes in Computer Science...
-
[34]
Tobias Rueckert, Raphaela Maerkl, David Rauber, Leonard Klausmann, Max Gutbrod, Daniel Rueckert, Hubertus Feussner, Dirk Wilhelm, and Christoph Palm. Video dataset for surgical phase, keypoint, and instrument recognition in laparoscopic surgery (PhaKIR).arXiv preprint arXiv:2511.06549, 2025
arXiv 2025
-
[35]
Scientific Data 10(1), 3 (2023).https://doi.org/10.1038/s41597-022-01719-2
Matthias Carstens, Franziska Maria Rinner, Sebastian Bodenstedt, Andreas C. Jenke, Jürgen Weitz, Marius Distler, Stefanie Speidel, and Felix R. Kolbinger. The dresden surgical anatomy dataset for abdominal organ segmentation in surgical data science.Scientific Data, 10(1):3, 2023. doi: 10.1038/s41597-022-01719-2
-
[36]
Surgical visual understanding (SurgVU) dataset
Aneeq Zia, Max Berniker, Rogerio Nespolo, Conor Perreault, Ziheng Wang, Benjamin Mueller, Ryan Schmidt, Kiran Bhattacharyya, Xi Liu, and Anthony Jarc. Surgical visual understanding (SurgVU) dataset. arXiv preprint arXiv:2501.09209, 2025
Pith/arXiv arXiv 2025
-
[37]
Qwen3-VL Technical Report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
Pith/arXiv arXiv 2025
-
[38]
GPT-5 System Card.https://cdn.openai.com/gpt-5-system-card.pdf, August 2025
OpenAI. GPT-5 System Card.https://cdn.openai.com/gpt-5-system-card.pdf, August 2025
2025
-
[39]
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities, 2025
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, et al. Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities, 2025. URLhttps://arxiv.org/abs/2507. 06261. 14 A Technical appendices and supplementary material...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.