Orchestrating Black-Box Schema Converters: An Empirical Study of Automated, Quality-Ranked Conversion Across Heterogeneous Schema Languages
Pith reviewed 2026-06-26 01:36 UTC · model grok-4.3
The pith
Orchestrating black-box schema converters delivers usable results for 43 of 60 real-world tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating schema languages as nodes and converters as directed edges in a graph, conversion tasks become path-finding problems that can be solved by discovering, executing, ranking, and reporting paths with provenance, achieving usable results for 43 of 60 evaluated tasks built from real-world schemas.
What carries the argument
The Schema Conversion Orchestrator, which discovers, executes, ranks, and reports conversion paths using black-box converters as edges between schema language nodes.
If this is right
- Usable conversions are possible for most tasks despite individual converter limitations.
- Failures point to concrete missing converters or quality issues in the landscape.
- Full provenance allows reproduction and debugging of the conversion process.
- The system can be integrated into tools like MetaConfigurator for practical use.
Where Pith is reading between the lines
- Tool developers could prioritize creating converters for the identified gap languages or pairs.
- Standard benchmarks for schema conversion quality could be developed based on this task set.
- Extending the graph with more schema languages would increase coverage.
Load-bearing premise
The 60 conversion tasks from real-world schemas are representative of practical needs and the agent-assisted human-reviewed quality annotations provide reliable ground truth.
What would settle it
A larger or different collection of real-world schema conversion tasks where the orchestrator finds usable results for substantially fewer than 43 cases, or where independent experts disagree with the quality rankings.
Figures

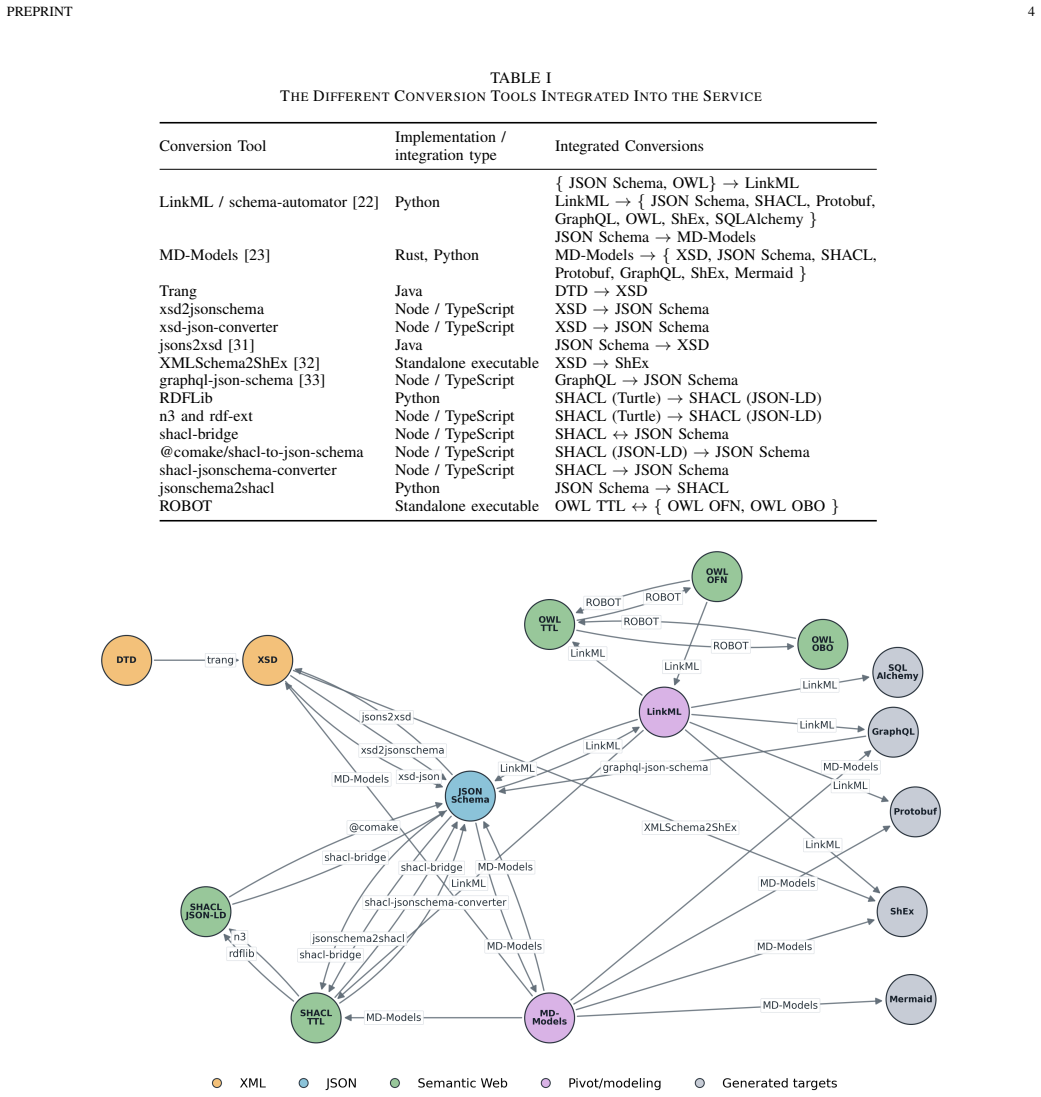
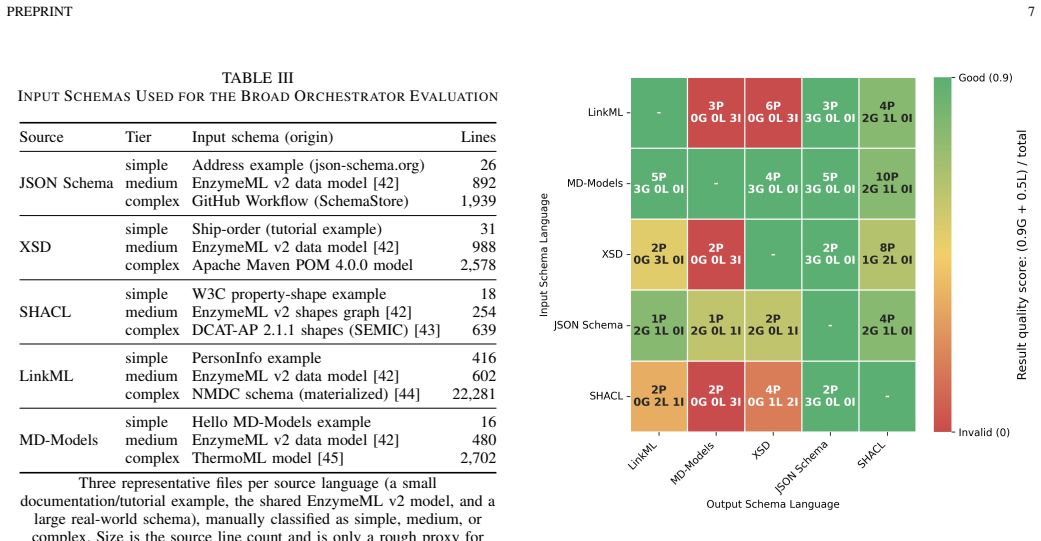
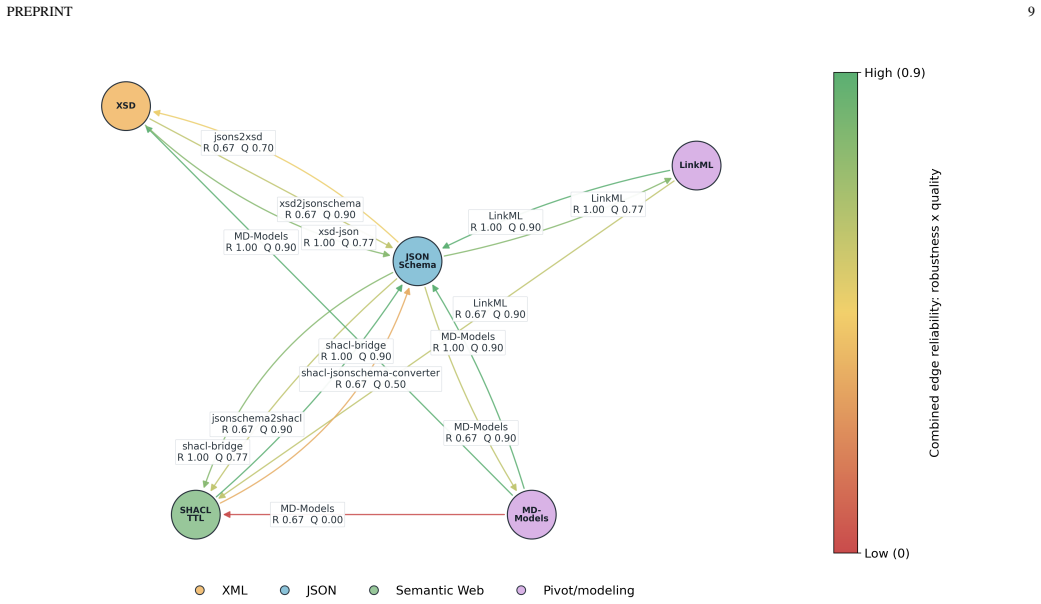

read the original abstract
Modern software systems routinely need the same data model in several schema languages: a model may exist as JSON Schema for a web API, as XSD for data exchange, and as SHACL for a knowledge graph. Keeping these representations consistent as the model evolves is a recurring construction and maintenance burden, because converters between schema languages are hard to find, scattered across ecosystems, of uneven quality, and frequently lossy. We study, empirically, to what extent such imperfect, heterogeneous converters can be orchestrated into automated, reproducible, and quality-ranked conversions, and where the current converter landscape reaches its limits. Our approach models schema languages as nodes and converters, treated as black boxes, as directed edges, so that conversions become paths that are discovered, executed, ranked, and reported with full per-step provenance, with failures handled by trying alternatives. We realize it as the open-source Schema Conversion Orchestrator, integrate it into MetaConfigurator, and evaluate it on 60 conversion tasks built from real-world schemas across five schema languages, using agent-assisted, human-reviewed quality annotations. Orchestration surfaces a usable result for 43 of 60 tasks; the remaining failures localize concrete gaps in the converter landscape. We discuss implications for tool builders and for measuring conversion quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study of orchestrating black-box converters between heterogeneous schema languages (modeled as nodes and directed edges) to discover executable paths, execute conversions with full provenance, rank outputs by quality, and handle failures via alternatives. It evaluates the approach via the open-source Schema Conversion Orchestrator (integrated into MetaConfigurator) on 60 conversion tasks built from real-world schemas across five languages, using agent-assisted human-reviewed annotations, and reports usable results for 43 tasks while localizing remaining gaps in the converter landscape.
Significance. If the evaluation is robust, the work offers a practical, reproducible framework for managing schema consistency across ecosystems, with explicit credit for the open-source implementation, per-step provenance reporting, and alternative-path failure handling. It could inform tool builders on gaps and provide a basis for standardized quality measurement in schema conversion.
major comments (2)
- [Evaluation (tasks construction and selection)] The central claim that orchestration yields usable results for 43/60 tasks and localizes concrete gaps depends on the 60 tasks being representative; however, the evaluation section provides no explicit sampling method, selection criteria, or justification for how the real-world schemas were chosen across the five languages.
- [Evaluation (annotation process)] The reliability of the agent-assisted human-reviewed quality annotations as ground truth for declaring a result 'usable' is load-bearing, yet no inter-annotator agreement metrics, precise definition of 'usable', or blinding procedures are reported.
minor comments (1)
- [Abstract] The abstract states 'five schema languages' without naming them; adding the names (e.g., JSON Schema, XSD, SHACL) would improve immediate clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our evaluation methodology. These comments identify important areas for strengthening the paper's claims about task representativeness and annotation reliability. We respond to each point below and commit to revisions where appropriate.
read point-by-point responses
-
Referee: [Evaluation (tasks construction and selection)] The central claim that orchestration yields usable results for 43/60 tasks and localizes concrete gaps depends on the 60 tasks being representative; however, the evaluation section provides no explicit sampling method, selection criteria, or justification for how the real-world schemas were chosen across the five languages.
Authors: We agree that the manuscript does not include an explicit description of the sampling method or selection criteria. The 60 tasks were assembled from publicly available real-world schemas drawn from documentation, GitHub repositories, and standards bodies for the five languages, chosen to span varying domains and structural complexities. To address the concern, we will add a dedicated subsection to the Evaluation section that lists the schema sources, outlines the informal selection criteria used (e.g., coverage of common conversion patterns and diversity in size), and discusses limitations in representativeness. revision: yes
-
Referee: [Evaluation (annotation process)] The reliability of the agent-assisted human-reviewed quality annotations as ground truth for declaring a result 'usable' is load-bearing, yet no inter-annotator agreement metrics, precise definition of 'usable', or blinding procedures are reported.
Authors: We acknowledge that the current description of the annotation process is insufficient. 'Usable' was operationalized internally as a result that preserves core structure, key constraints, and semantics without major information loss, determined via agent-generated candidates followed by author review. No inter-annotator agreement was computed and no blinding was performed because reviews were conducted internally by the authors. We will revise the manuscript to provide an explicit definition of 'usable', detail the annotation protocol, and state the limitations regarding agreement metrics and blinding. Introducing multiple independent annotators would require additional experiments beyond the current scope. revision: partial
Circularity Check
Empirical evaluation with direct measurements; no derivation reduces to inputs
full rationale
This is an empirical study reporting measured success rates (43/60) on externally sourced real-world schemas using agent-assisted human-reviewed annotations. No equations, fitted parameters, predictions, or uniqueness theorems appear in the described approach or results. The central claim is a direct count from evaluation, not a quantity defined in terms of itself or justified solely by self-citation chains. The paper is self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Converters between schema languages can be treated as black boxes whose internal behavior need not be inspected for orchestration and ranking.
Reference graph
Works this paper leans on
-
[1]
JSON Schema: A media type for describing JSON documents,
A. Wright, H. Andrews, B. Hutton, and G. Dennis, “JSON Schema: A media type for describing JSON documents,” Internet-Draft draft- bhutton-json-schema-01, IETF, 2022, jSON Schema 2020-12. [Online]. Available: https://json-schema.org/draft/2020-12/json-schema-core.html
2022
-
[2]
W3C XML Schema definition language (XSD) 1.1 part 1: Structures,
S. Gao, C. M. Sperberg-McQueen, H. S. Thompson, N. Mendelsohn, D. Beech, and M. Maloney, “W3C XML Schema definition language (XSD) 1.1 part 1: Structures,” World Wide Web Consortium (W3C), W3C Recommendation, 2012. [Online]. Available: https: //www.w3.org/TR/xmlschema11-1/
2012
-
[3]
Shapes constraint language (SHACL),
H. Knublauch and D. Kontokostas, “Shapes constraint language (SHACL),” World Wide Web Consortium (W3C), W3C Recommenda- tion, 2017. [Online]. Available: https://www.w3.org/TR/shacl/
2017
-
[4]
OWL 2 web ontology language primer (second edition),
P. Hitzler, M. Kr ¨otzsch, B. Parsia, P. F. Patel-Schneider, and S. Rudolph, “OWL 2 web ontology language primer (second edition),” World Wide Web Consortium (W3C), W3C Recommendation, 2012. [Online]. Available: https://www.w3.org/TR/owl2-primer/
2012
-
[5]
Model transformations? transformation models!
J. B ´ezivin, F. B¨uttner, M. Gogolla, F. Jouault, I. Kurtev, and A. Lindow, “Model transformations? transformation models!” inModel Driven Engineering Languages and Systems, O. Nierstrasz, J. Whittle, D. Harel, and G. Reggio, Eds. Springer Berlin Heidelberg, 2006, pp. 440–453
2006
-
[6]
First experiments with the atl model transformation language: Transforming xslt into xquery,
J. B ´ezivin, G. Dup ´e, F. Jouault, G. M. Pitette, and J. E. Rougui, “First experiments with the atl model transformation language: Transforming xslt into xquery,” inOOPSLA 2003 Workshop on Generative Techniques in the Context of the Model Driven Architecture, 2003
2003
-
[7]
Towards a megamodel to model software evolution through transformations,
J.-M. Favre and T. Nguyen, “Towards a megamodel to model software evolution through transformations,”Electronic Notes in Theoretical Computer Science, vol. 127, no. 3, pp. 59–74, 2005
2005
-
[8]
Orchestrating atl model transformations,
J. Rivera, D. Ruiz-Gonz ´alez, F. L ´opez-Romero, J. Bautista, and A. Val- lecillo, “Orchestrating atl model transformations,” inProceedings of the 1st International Workshop on Model Transformation with ATL (MtATL 2009), 2009, pp. 34–46
2009
-
[9]
Fact or fiction – reuse in rule-based model-to- model transformation languages,
M. Wimmer, G. Kappel, A. Kusel, W. Retschitzegger, J. Sch ¨onb¨ock, and W. Schwinger, “Fact or fiction – reuse in rule-based model-to- model transformation languages,” inTheory and Practice of Model Transformations, Z. Hu and J. de Lara, Eds. Springer Berlin Heidelberg, 2012, pp. 280–295
2012
-
[10]
Polyglot software development: Wait, what?
G. Mussbacher, B. Combemale, J. Kienzle, L. Burgue ˜no, A. Garc ´ıa- Dom´ınguez, J.-M. J ´ez´equel, G. Jouneaux, D.-E. Khelladi, S. Mosser, C. Pulgar, H. Sahraoui, M. Schiedermeier, and T. van der Storm, “Polyglot software development: Wait, what?”Software, vol. PP, pp. 1–8, 07 2024
2024
-
[11]
MetaConfigurator: A User-Friendly Tool for Editing Structured Data Files,
F. Neubauer, P. Bredl, M. Xu, K. Patel, J. Pleiss, and B. Uekermann, “MetaConfigurator: A User-Friendly Tool for Editing Structured Data Files,”Datenbank-Spektrum, pp. 1–9, 2024
2024
-
[12]
Data model creation with metaconfigurator,
F. Neubauer, J. Pleiss, and B. Uekermann, “Data model creation with metaconfigurator,” 2025. [Online]. Available: https://dl.gi.de/handle/20. 500.12116/45927
2025
-
[13]
Ai-assisted json schema creation and mapping,
F. Neubauer, B. Uekermann, and J. Pleiss, “Ai-assisted json schema creation and mapping,” in2025 28th International Conference on Model Driven Engineering Languages and Systems Companion (MODELS-C), Oct 2025, pp. 79–83
2025
-
[14]
Replication dataset for: Orchestrating Schema Conver- sions Across Heterogeneous Schema Languages: A Graph-Based, Black- Box Approach,
F. Neubauer, “Replication dataset for: Orchestrating Schema Conver- sions Across Heterogeneous Schema Languages: A Graph-Based, Black- Box Approach,” 2026. 6Schema Conversion Orchestrator: https://github.com/MetaConfigurator/ schema-conversion-orchestrator; MetaConfigurator: https://github.com/ MetaConfigurator/meta-configurator
2026
-
[15]
Atl: A model transformation tool,
F. Jouault, F. Allilaire, J. B ´ezivin, and I. Kurtev, “Atl: A model transformation tool,”Science of Computer Programming, vol. 72, no. 1, pp. 31–39, 2008, special Issue on Second issue of experimental software and toolkits (EST). [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0167642308000439
2008
-
[16]
Modularization of model transfor- mations through a phasing mechanism,
J. S. Cuadrado and J. G. Molina, “Modularization of model transfor- mations through a phasing mechanism,”Software & Systems Modeling, vol. 8, no. 3, pp. 325–345, 2009
2009
-
[17]
Model transformation modularization as a many-objective optimization problem,
M. Fleck, J. Troya, M. Kessentini, M. Wimmer, and B. Alkhazi, “Model transformation modularization as a many-objective optimization problem,”Trans. Softw. Eng., vol. 43, no. 11, pp. 1009–1032, 2017
2017
-
[18]
Traceability and reuse mechanisms, the most important properties of model transformation languages,
S. H ¨oppner and M. Tichy, “Traceability and reuse mechanisms, the most important properties of model transformation languages,” Empirical Softw. Engg., vol. 29, no. 2, Feb. 2024. [Online]. Available: https://doi.org/10.1007/s10664-023-10428-2
-
[19]
Tractable model transformation testing,
M. Gogolla and A. Vallecillo, “Tractable model transformation testing,” inModelling Foundations and Applications, R. B. France, J. M. Kuester, B. Bordbar, and R. F. Paige, Eds. Springer Berlin Heidelberg, 2011, pp. 221–235
2011
-
[20]
Static fault localization in model transformations,
L. Burgue ˜no, J. Troya, M. Wimmer, and A. Vallecillo, “Static fault localization in model transformations,”Trans. Softw. Eng., vol. 41, no. 5, pp. 490–506, 2015
2015
-
[21]
Multi-objective model transformation chain exploration with momot,
M. Eisenberg, A. Sahay, D. Di Ruscio, L. Iovino, M. Wimmer, and A. Pierantonio, “Multi-objective model transformation chain exploration with momot,”Information and Software Technology, vol. 174, p. 107500, 2024. [Online]. Available: https://www.sciencedirect. com/science/article/pii/S0950584924001058
2024
-
[22]
Linkml: An open data modeling framework,
S. A. T. Moxon, H. Solbrig, N. L. Harris, P. Kalita, M. A. Miller, S. Patil, K. Schaper, C. Bizon, J. H. Caufield, S. C. Cuesta, C. Cox, F. Dekervel, D. M. Dooley, W. D. Duncan, T. Fliss, S. Gehrke, A. S. L. Graefe, H. Hegde, A. Ireland, J. O. B. Jacobsen, M. Krishnamurthy, C. Kroll, D. Linke, R. Ly, N. Matentzoglu, J. A. Overton, J. L. Saunders, D. R. Un...
arXiv 2025
-
[23]
MD-Models: Human-Readable, Model-Driven Specifications for FAIR and AI-Ready Research Data,
J. Range and J. Pleiss, “MD-Models: Human-Readable, Model-Driven Specifications for FAIR and AI-Ready Research Data,” 2026
2026
-
[24]
Large language models for json schema discovery,
M. J. Mior, “Large language models for json schema discovery,” 2024. [Online]. Available: https://arxiv.org/abs/2407.03286
arXiv 2024
-
[25]
Large language models can be easily distracted by irrelevant context,
F. Shi, X. Chen, K. Misra, N. Scales, D. Dohan, E. Chi, N. Sch ¨arli, and D. Zhou, “Large language models can be easily distracted by irrelevant context,” inProceedings of the 40th International Conference on Machine Learning, ser. ICML’23. JMLR.org, 2023, pp. 31 210– 31 227
2023
-
[26]
R. T. McCoy, S. Yao, D. Friedman, M. D. Hardy, and T. L. Griffiths, “Embers of autoregression show how large language models are shaped by the problem they are trained to solve,”Proceedings of the National Academy of Sciences, vol. 121, no. 41, p. e2322420121, 2024. [Online]. Available: https://www.pnas.org/doi/abs/10.1073/pnas.2322420121
-
[27]
Same task, more tokens: the impact of input length on the reasoning performance of large language models,
M. Levy, A. Jacoby, and Y . Goldberg, “Same task, more tokens: the impact of input length on the reasoning performance of large language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2024, pp. 15 339–15 353
2024
-
[28]
Modular monolith architecture in cloud environments: A systematic literature review,
L. F. Al-Qora’n and A. Al-Said Ahmad, “Modular monolith architecture in cloud environments: A systematic literature review,” Future Internet, vol. 17, no. 11, 2025. [Online]. Available: https: //www.mdpi.com/1999-5903/17/11/496
2025
-
[29]
Modular monolith: Is this the trend in software architecture?
R. Su and X. Li, “Modular monolith: Is this the trend in software architecture?” inProceedings of the 1st International Workshop on New Trends in Software Architecture, ser. SATrends ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 10–13. [Online]. Available: https://doi.org/10.1145/3643657.3643911
-
[30]
Microservices vs. monoliths: Comparative analysis for scal- able software architecture design,
A. Kamisetty, D. Narsina, M. Rodriguez, S. Kothapalli, and J. C. S. Gummadi, “Microservices vs. monoliths: Comparative analysis for scal- able software architecture design,”Engineering International, vol. 11, no. 2, pp. 99–112, 2023
2023
-
[31]
jsons2xsd,
ethlo, “jsons2xsd,” https://github.com/ethlo/jsons2xsd, 2026, java/Maven library (version 2.3.0) converting JSON Schema to XSD; accessed June 2026
2026
-
[32]
XMLSchema2ShEx: Con- verting XML validation to RDF validation,
H. Garc ´ıa-Gonz´alez and J. E. Labra Gayo, “XMLSchema2ShEx: Con- verting XML validation to RDF validation,”Semantic Web, vol. 11, pp. 235–253, 2018
2018
-
[33]
graphql-json-schema,
graphql-json-schema, “graphql-json-schema,” https://www.npmjs.com/ package/graphql-json-schema, 2026, typeScript library (version 0.1.2) converting GraphQL to JSON Schema; accessed June 2026. PREPRINT 12
2026
-
[34]
Bridging SHACL and JSON Schema: Design, Implementation, and Evaluation of Bidirectional Con- versions for JSON and JSON-LD Documents,
G. Chinnikkaramadom Govindan, “Bridging SHACL and JSON Schema: Design, Implementation, and Evaluation of Bidirectional Con- versions for JSON and JSON-LD Documents,” Master’s Thesis, Univer- sity of Stuttgart, Institute for Parallel and Distributed Systems, 2026
2026
-
[35]
@comake/shacl-to-json-schema,
Comake, “@comake/shacl-to-json-schema,” https://github.com/comake/ shacl-to-json-schema, 2026, software library in TypeScript (version 1.0.3) converting SHACL (JSON-LD) to JSON Schema; accessed June 2026
2026
-
[36]
shacl-jsonschema-converter,
R. Siqueira, “shacl-jsonschema-converter,” https://github.com/ siqueirarenan/shacl-jsonschema-converter, 2026, software library in TypeScript (version 0.1.3) converting SHACL to JSON Schema; accessed June 2026
2026
-
[37]
jsonschema2shacl,
CiTIUS, “jsonschema2shacl,” https://github.com/citiususc/ jsonschema2shacl, 2026, python library converting JSON Schema to SHACL shape graphs; accessed June 2026
2026
-
[38]
JS2SHACL: JSON Schema to SHACL Conversor,
JS2SHACL, “JS2SHACL: JSON Schema to SHACL Conversor,” https: //github.com/gbd-ufsc/JS2SHACL, 2026, web application converting JSON Schema to SHACL in Turtle; accessed June 2026
2026
-
[39]
Combining graph and tree: writing SHAX, obtaining SHACL, XSD and more,
H.-J. Rennau, “Combining graph and tree: writing SHAX, obtaining SHACL, XSD and more,” inProceedings of Balisage: The Markup Conference 2019, Balisage Series on Markup Technologies, Vol. 23, 2019, sHAX: an abstract XML syntax compiled into SHACL, XSD, and JSON Schema
2019
-
[40]
Mapping Relational Database Constraints to SHACL,
R. B. Thapa and M. Giese, “Mapping Relational Database Constraints to SHACL,” inThe Semantic Web – ISWC 2022, ser. Lecture Notes in Computer Science, vol. 13489, 2022, pp. 214–230
2022
-
[41]
shacl-bridge: Bidirectional Con- version between SHACL and JSON Schema,
G. Chinnikkaramadom Govindan, “shacl-bridge: Bidirectional Con- version between SHACL and JSON Schema,” https://github.com/ MetaConfigurator/shacl-bridge, 2026
2026
-
[42]
EnzymeML: seamless data flow and modeling of enzymatic data,
S. Lauterbach, H. Dienhart, J. Range, S. Malzacher, J.-D. Sp ¨oringet al., “EnzymeML: seamless data flow and modeling of enzymatic data,” Nature Methods, vol. 20, no. 3, pp. 400–402, 2023
2023
-
[43]
DCAT Application Profile for Data Portals in Europe (DCAT-AP),
Publications Office of the European Union, “DCAT Application Profile for Data Portals in Europe (DCAT-AP),” https://op.europa.eu/en/web/ eu-vocabularies/dcat-ap, 2021, specification, version 2.1.1 shapes used for the evaluation; accessed June 2026
2021
-
[44]
The National Microbiome Data Collaborative Data Portal: an integrated multi-omics microbiome data resource,
E. A. Eloe-Fadrosh, F. Ahmed, Anubhav, M. Babinski, J. Baumes, M. Borkumet al., “The National Microbiome Data Collaborative Data Portal: an integrated multi-omics microbiome data resource,”Nucleic Acids Research, vol. 50, no. D1, pp. D828–D836, 2022
2022
-
[45]
ThermoML—An XML-Based Approach for Storage and Exchange of Experimental and Critically Evaluated Thermophysical and Thermochemical Property Data. 1. Experimental Data,
M. Frenkel, R. D. Chirico, V . V . Diky, Q. Dong, S. Frenkel, P. R. Franchoiset al., “ThermoML—An XML-Based Approach for Storage and Exchange of Experimental and Critically Evaluated Thermophysical and Thermochemical Property Data. 1. Experimental Data,”Journal of Chemical & Engineering Data, vol. 48, no. 1, pp. 2–13, 2003
2003
-
[46]
The FAIR guiding principles for scientific data management and stewardship,
M. D. Wilkinson, M. Dumontier, I. J. Aalbersberg, G. Appletonet al., “The FAIR guiding principles for scientific data management and stewardship,”Scientific Data, vol. 3, no. 1, p. 160018, 2016
2016
-
[47]
Introducing the FAIR principles for research software,
M. Barker, N. P. Chue Hong, D. S. Katz, A.-L. Lamprecht, C. Mart ´ınez- Ortiz, F. Psomopoulos, J. Harrow, L. J. Castro, M. Gruenpeter, P. A. Mart´ınez, and T. Honeyman, “Introducing the FAIR principles for research software,”Scientific Data, vol. 9, no. 1, p. 622, 2022
2022
-
[48]
Automated chaining of model transformations with incompatible metamodels,
F. Basciani, D. Di Ruscio, L. Iovino, and A. Pierantonio, “Automated chaining of model transformations with incompatible metamodels,” in Model-Driven Engineering Languages and Systems (MODELS 2014), ser. Lecture Notes in Computer Science, vol. 8767. Springer, 2014, pp. 602–618
2014
-
[49]
Witness generation for JSON Schema,
L. Attouche, M.-A. Baazizi, D. Colazzo, G. Ghelli, C. Sartiani, and S. Scherzinger, “Witness generation for JSON Schema,”Proceedings of the VLDB Endowment, vol. 15, no. 13, pp. 4002–4014, 2022
2022
-
[50]
JEDI: These aren’t the JSON documents you’re looking for?
T. H ¨utter, N. Augsten, C. M. Kirsch, M. J. Carey, and C. Li, “JEDI: These aren’t the JSON documents you’re looking for?” inProceedings of the 2022 International Conference on Management of Data (SIGMOD ’22). ACM, 2022, pp. 1584–1597
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.