At the Edge of Understanding: Sparse Autoencoders Trace The Limits of Transformer Generalization
Pith reviewed 2026-06-26 01:25 UTC · model grok-4.3
The pith
Out-of-distribution inputs increase the number of fallacious concepts activated inside transformer language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
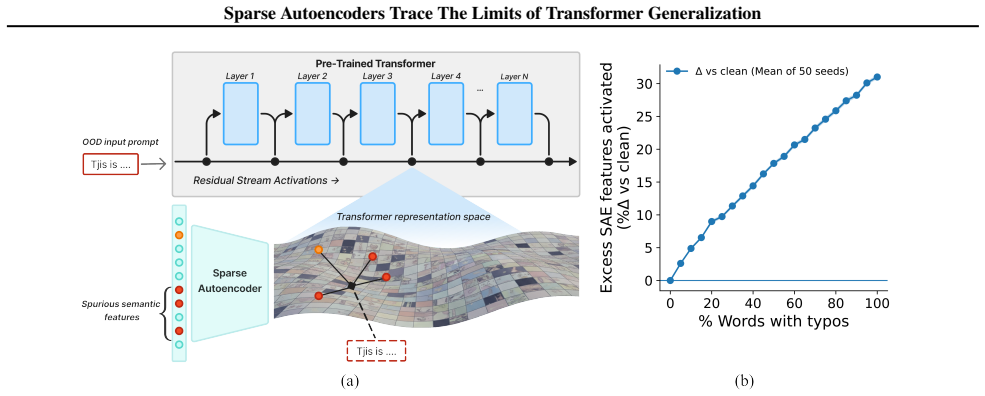
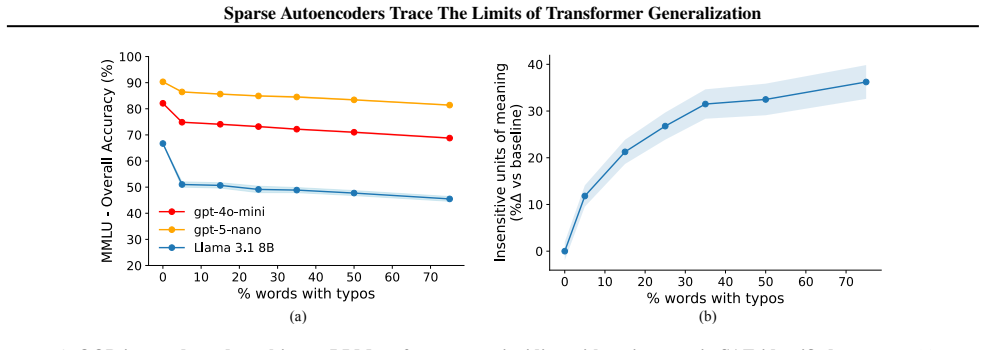
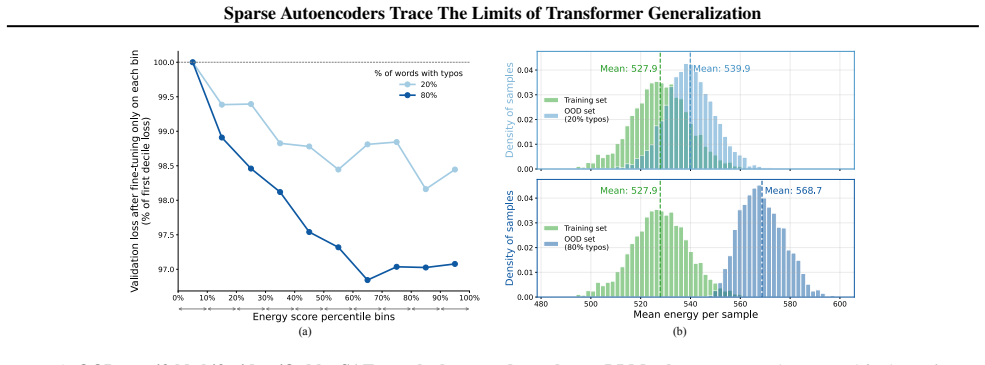
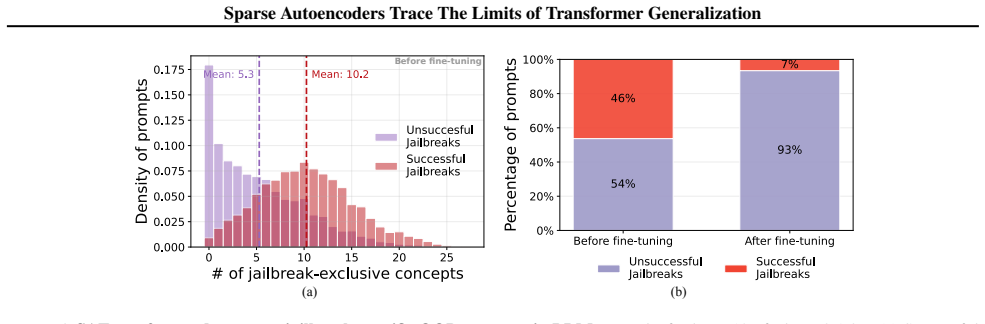
Out-of-distribution inputs drive language models to operate on an increased number of fallacious concepts in their internals. Sparse autoencoders isolate and count these concepts, providing a direct internal measure of distributional shift that supports a mechanistically grounded fine-tuning strategy for making models more robust to unexpected or adversarial prompts.
What carries the argument
Sparse autoencoders that isolate and count fallacious concepts activated in model internals during processing of OOD inputs.
If this is right
- The count of fallacious concepts supplies a scalar measure of distributional shift at inference time.
- Fine-tuning guided by this internal count produces models that maintain performance under typos and jailbreaks.
- Out-of-distribution behavior can be diagnosed from the model's private activations rather than from input statistics alone.
- A new inference-time diagnostic becomes available for assessing model safety before deployment.
Where Pith is reading between the lines
- The same counting method could be tested on non-text modalities to check whether increased erroneous internal features mark distributional shift more generally.
- If the count rises on prompts that later produce factual errors, the method might serve as an early-warning signal for hallucination risk.
- Interventions that reduce the count of fallacious concepts during generation could be compared against standard safety fine-tuning to measure relative gains in robustness.
Load-bearing premise
Sparse autoencoders isolate and count fallacious concepts in a manner that tracks distributional shift causally rather than merely correlating with it.
What would settle it
An experiment in which the SAE-derived count of fallacious concepts fails to predict performance degradation on held-out OOD tasks or fails to improve robustness when used to select fine-tuning examples.
Figures
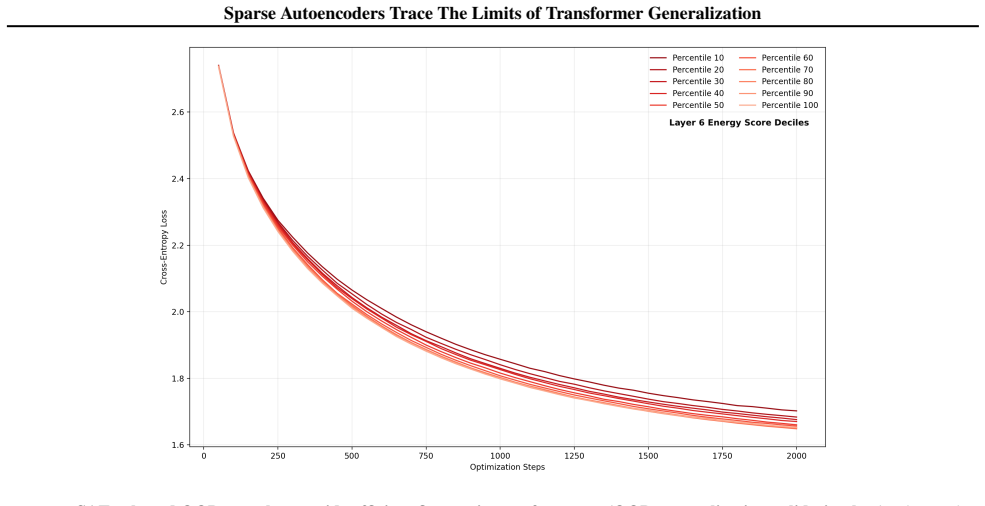
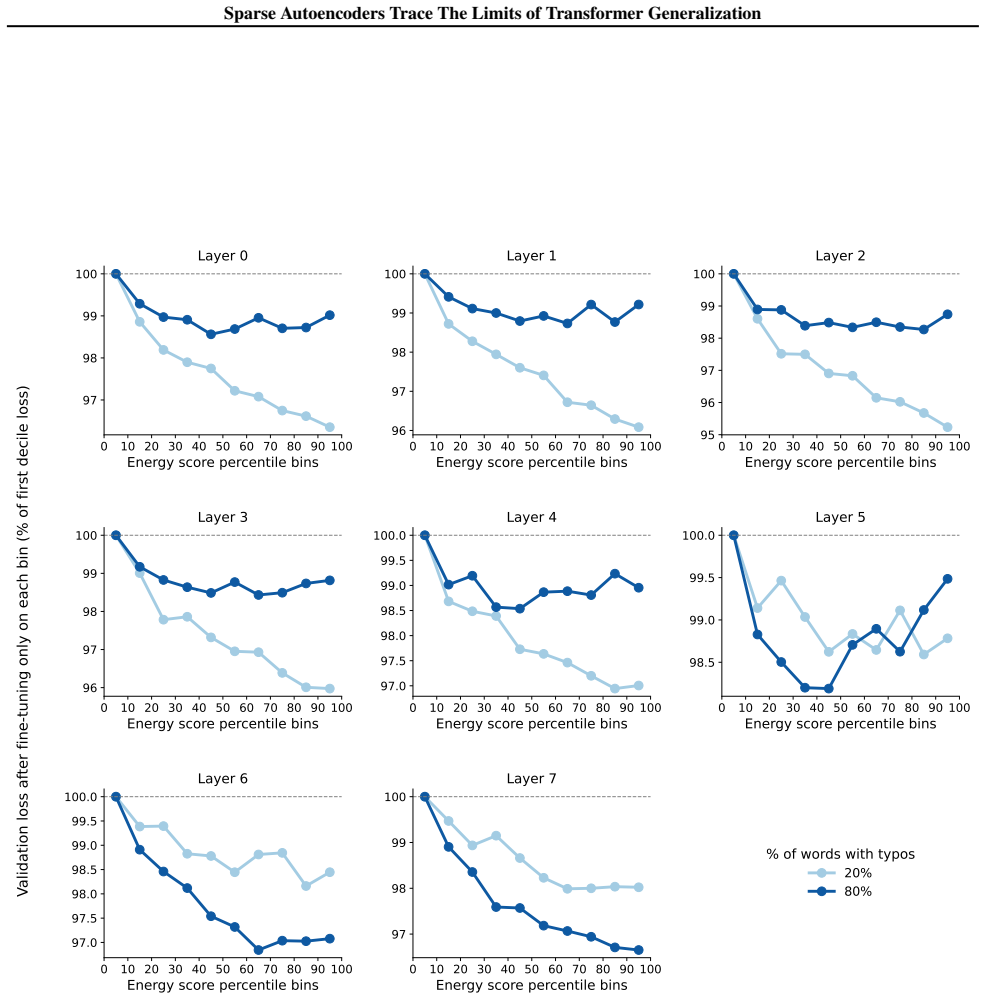
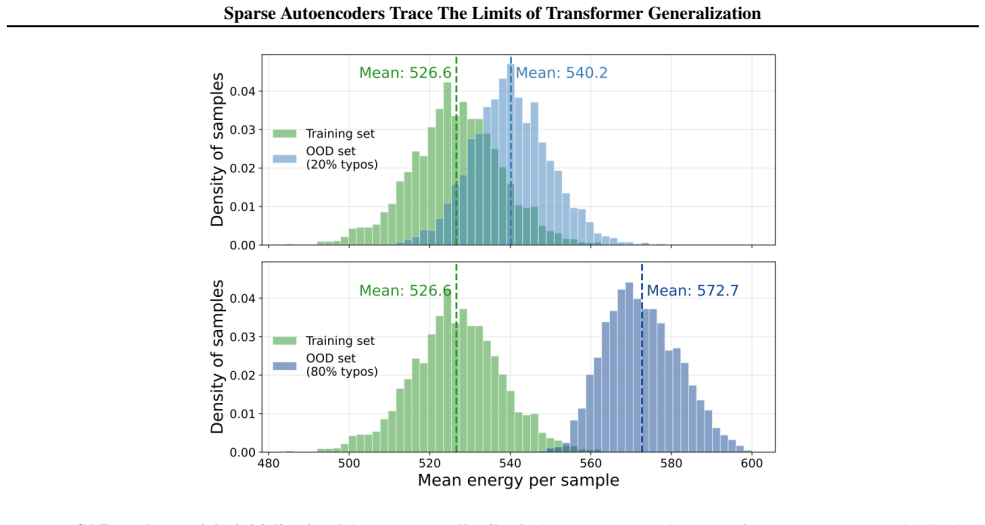
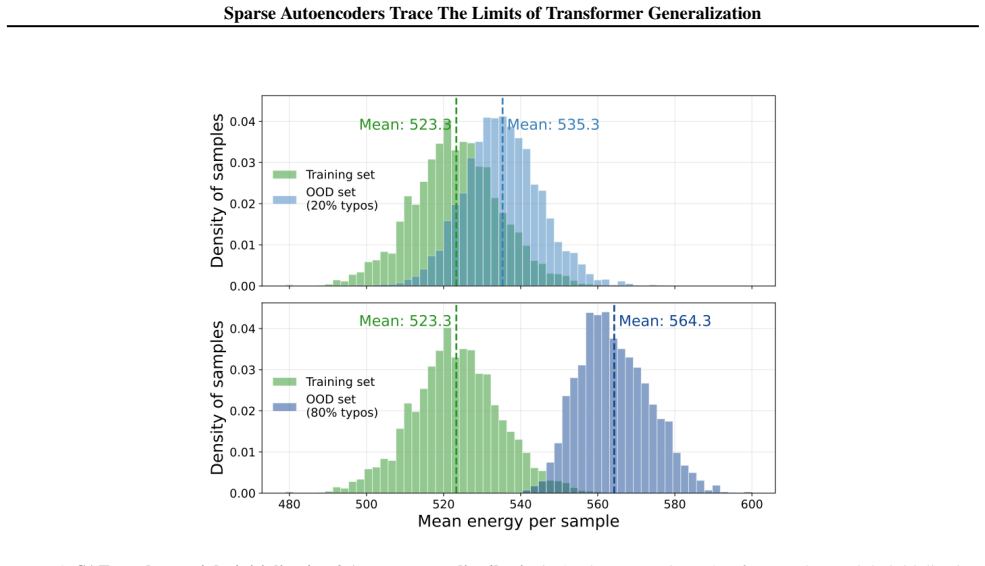



read the original abstract
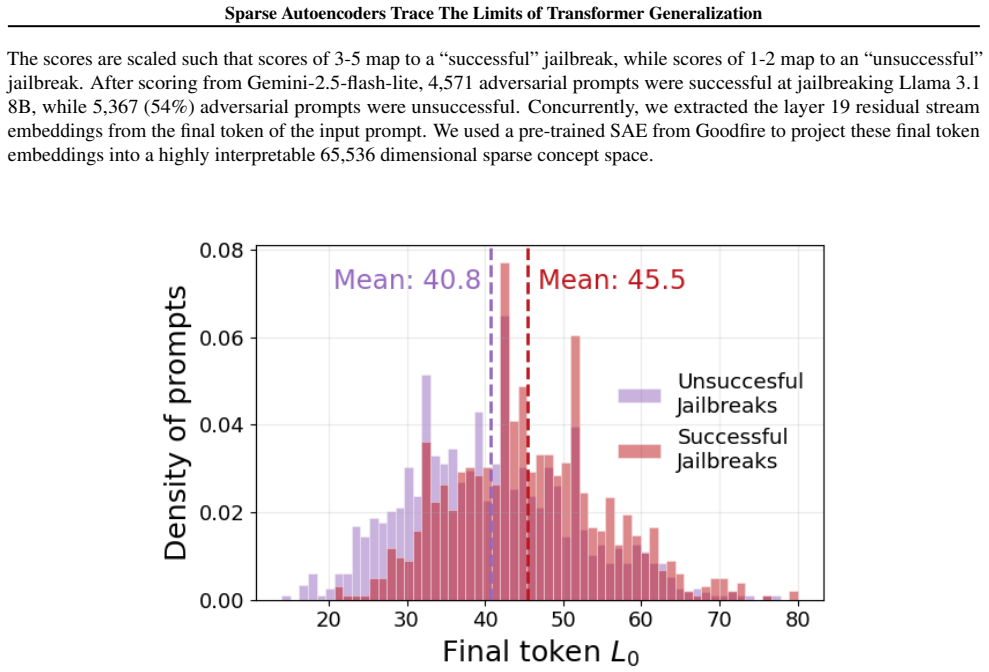
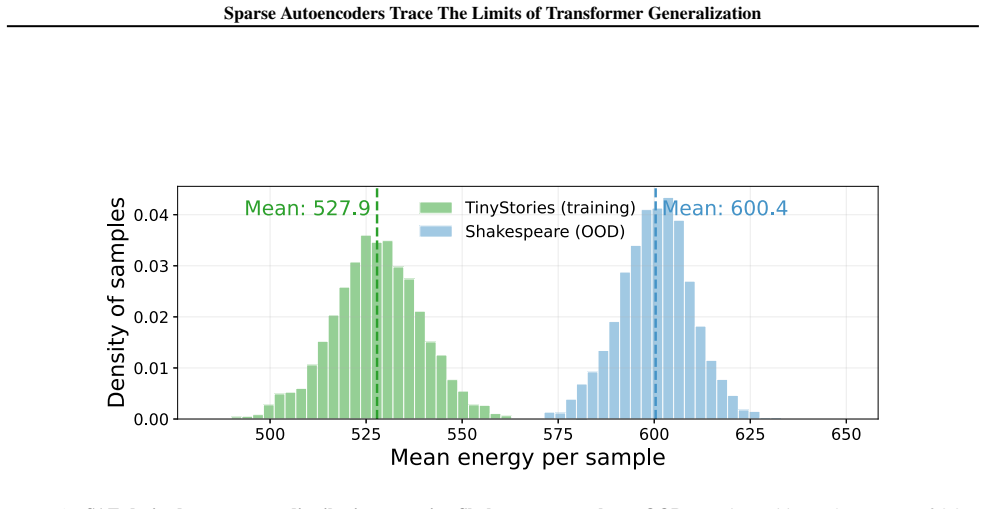
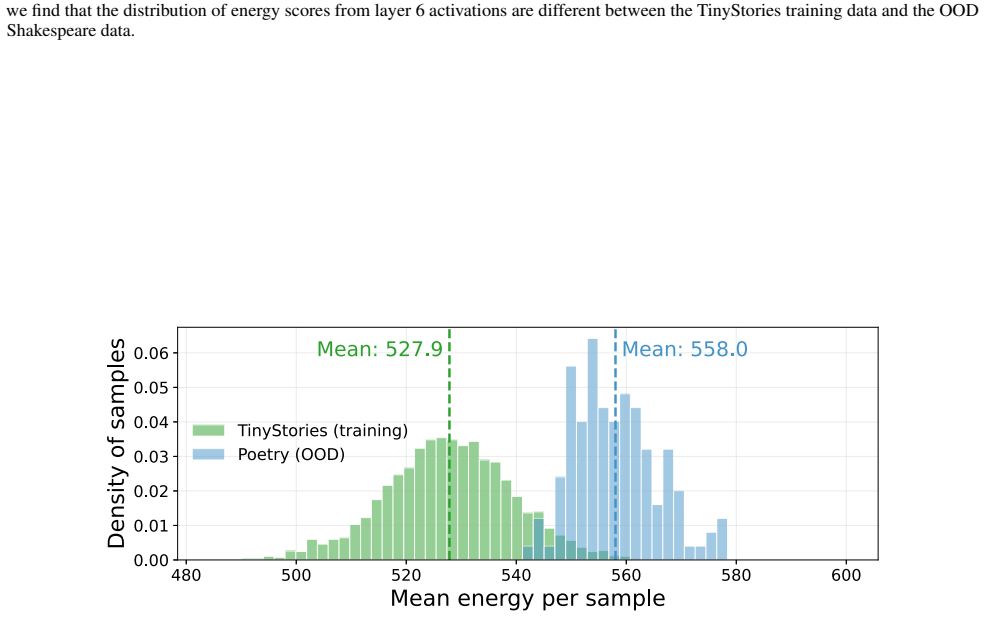
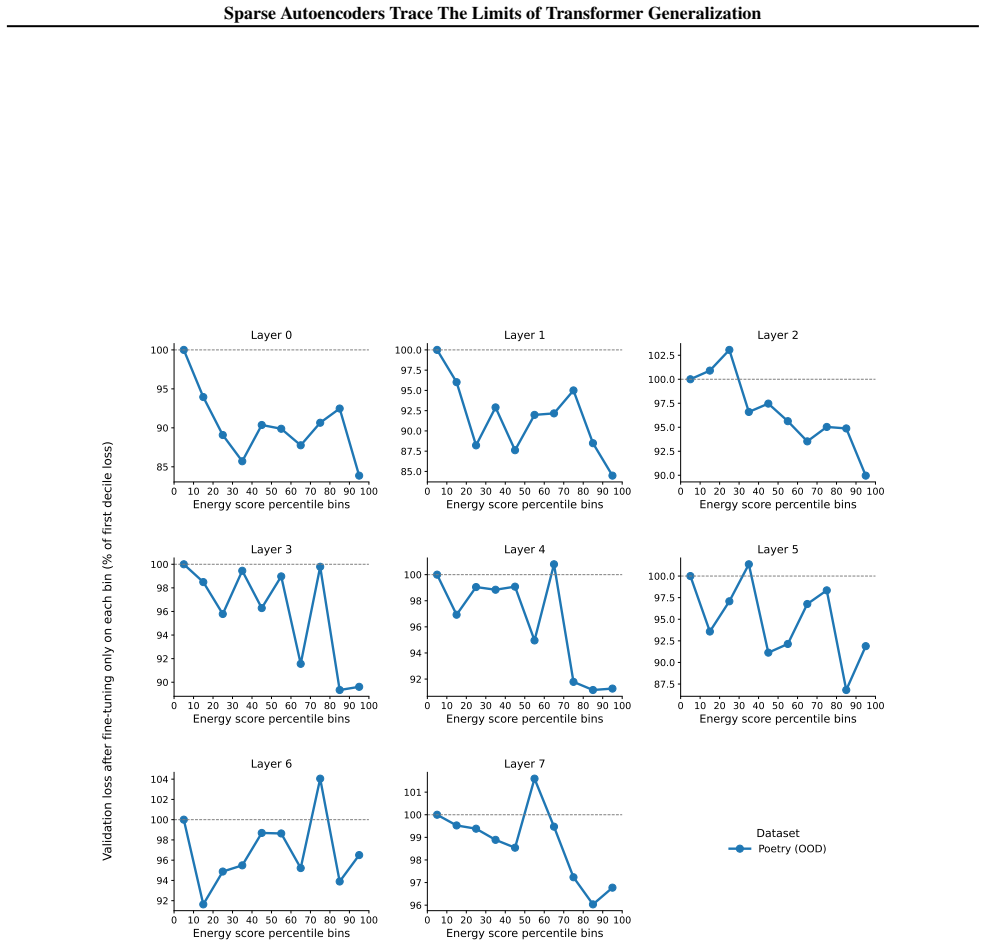
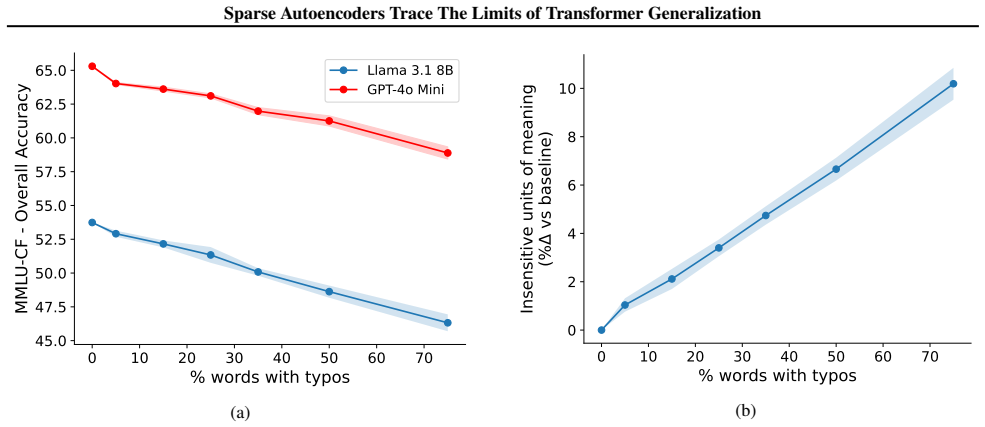
Pre-trained transformers have demonstrated remarkable generalization abilities, at times extending beyond the scope of their training data. Yet, real-world deployments often face unexpected or adversarial data that diverges from training data distributions. Without explicit mechanisms for handling such shifts, model reliability and safety degrade, urging more disciplined study of out-of-distribution (OOD) settings for transformers. By systematic experiments, we present a mechanistic framework for delineating the precise contours of transformer model robustness. We find that OOD inputs, including subtle typos and jailbreak prompts, drive language models to operate on an increased number of fallacious concepts in their internals. We leverage this device to quantify and understand the degree of distributional shift in prompts, enabling a mechanistically grounded fine-tuning strategy to robustify LLMs. Expanding the very notion of OOD from input data to a model's private computational processes, a new transformer diagnostic at inference time is a critical step toward making AI systems safe for deployment across science, business, and government.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that out-of-distribution (OOD) inputs such as subtle typos and jailbreak prompts cause pre-trained transformers to activate an increased number of 'fallacious concepts' in their internal representations, as detected via sparse autoencoders (SAEs). This increase is positioned as a quantifiable measure of distributional shift that enables a mechanistically grounded fine-tuning strategy to improve robustness, expanding the notion of OOD from input data to the model's private computational processes.
Significance. If the core empirical claims hold with proper controls, the work would offer a concrete SAE-based diagnostic for monitoring internal distributional shift at inference time and a corresponding fine-tuning approach, which could meaningfully advance mechanistic interpretability applications to LLM safety and reliability.
major comments (3)
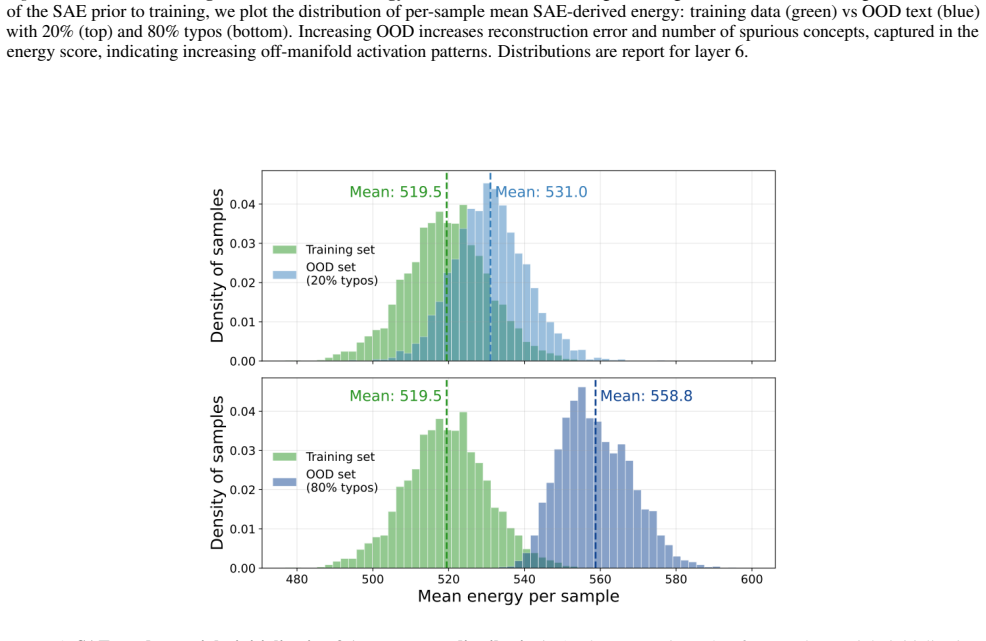
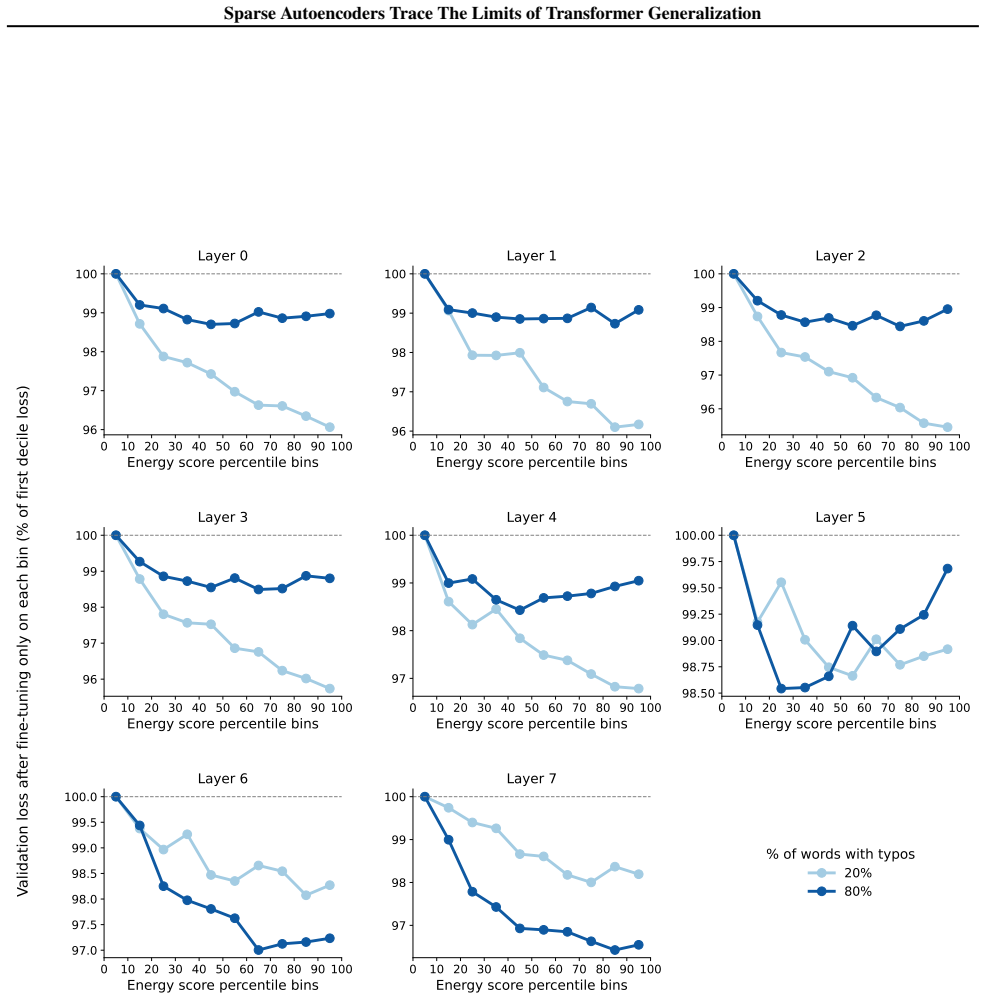
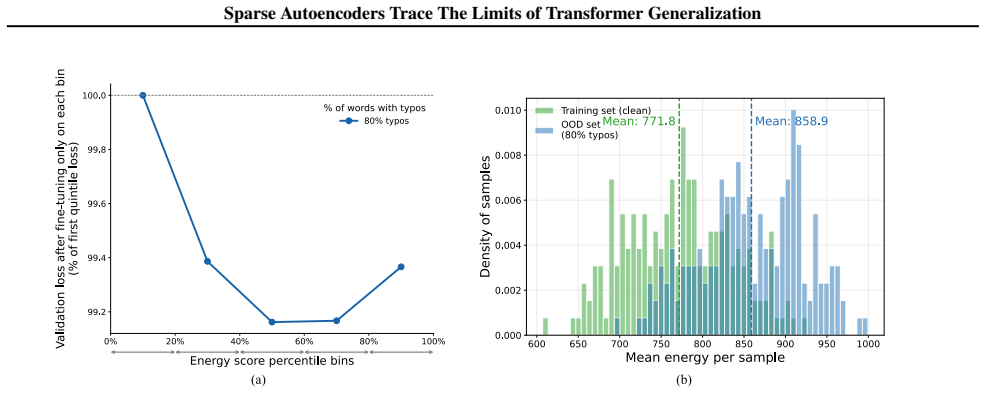
- [§4 and §5] §4 and §5: The claim that SAE feature count serves as a proxy for an increased number of distinct 'fallacious concepts' under OOD inputs (typos, jailbreaks) lacks reported controls for polysemanticity, reconstruction error on OOD data, or comparisons to in-distribution adversarial examples; without these, the metric may simply reflect poorer reconstruction rather than a causal increase in fallacious concepts.
- [§5] §5: The proposed mechanistically grounded fine-tuning strategy is described at a high level but provides no ablation results demonstrating that suppressing the identified SAE features restores in-distribution behavior, nor quantitative comparisons showing improvement over standard fine-tuning baselines.
- [Abstract and Methods] Abstract and Methods: No details are supplied on model architectures, SAE training hyperparameters, datasets, number of runs, error bars, or statistical tests, preventing evaluation of whether the reported increase in fallacious concepts is supported by evidence rather than post-hoc interpretation.
minor comments (2)
- [Abstract] The abstract presents high-level findings without any methods, data, or controls, which should be expanded in the main text for clarity.
- Notation for 'fallacious concepts' and how they are distinguished from other SAE latents is introduced without a formal definition or labeling protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important areas for strengthening the empirical support of our claims on SAE-based measurement of internal distributional shift. We address each major comment below and commit to revisions that add the requested controls, details, and experiments without altering the core findings.
read point-by-point responses
-
Referee: [§4 and §5] §4 and §5: The claim that SAE feature count serves as a proxy for an increased number of distinct 'fallacious concepts' under OOD inputs (typos, jailbreaks) lacks reported controls for polysemanticity, reconstruction error on OOD data, or comparisons to in-distribution adversarial examples; without these, the metric may simply reflect poorer reconstruction rather than a causal increase in fallacious concepts.
Authors: We agree that these controls are essential to distinguish increased fallacious concept activation from reconstruction artifacts. In the revised manuscript we will report reconstruction error statistics for OOD versus in-distribution inputs, include comparisons against in-distribution adversarial examples, and add analysis addressing polysemanticity (e.g., via feature activation sparsity and manual inspection of top features). revision: yes
-
Referee: [§5] §5: The proposed mechanistically grounded fine-tuning strategy is described at a high level but provides no ablation results demonstrating that suppressing the identified SAE features restores in-distribution behavior, nor quantitative comparisons showing improvement over standard fine-tuning baselines.
Authors: We will expand §5 with new ablation experiments that suppress the flagged SAE features during fine-tuning and quantify restoration of in-distribution behavior. We will also add direct quantitative comparisons against standard fine-tuning baselines, reporting metrics such as accuracy and robustness on held-out OOD sets. revision: yes
-
Referee: [Abstract and Methods] Abstract and Methods: No details are supplied on model architectures, SAE training hyperparameters, datasets, number of runs, error bars, or statistical tests, preventing evaluation of whether the reported increase in fallacious concepts is supported by evidence rather than post-hoc interpretation.
Authors: We will revise the Abstract and Methods to include complete specifications of model architectures, SAE training hyperparameters, datasets, number of runs, error bars, and statistical tests used. These additions will allow readers to assess the statistical support for the reported increases in feature activation. revision: yes
Circularity Check
No derivation chain or equations present; circularity cannot be assessed
full rationale
The provided abstract and context contain no equations, formal derivations, fitted parameters, or self-citations that could reduce to inputs by construction. Claims about SAE feature counts tracking 'fallacious concepts' under OOD are stated qualitatively without mathematical steps that could exhibit self-definition, fitted-input-as-prediction, or load-bearing self-citation. This is the normal case of a paper whose central assertions rest on experimental description rather than a closed derivation loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
Which of These Best Describes Multiple Choice Evaluation with LLMs? A) Forced B) Flawed C) Fixable D) All of the Above , author=. 2025 , eprint=
2025
-
[2]
arXiv preprint arXiv:2405.20947 , year=
OR-Bench: An Over-Refusal Benchmark for Large Language Models , author=. arXiv preprint arXiv:2405.20947 , year=
-
[3]
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy. SQ u AD : 100,000+ Questions for Machine Comprehension of Text. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1264
-
[4]
Spoken SQuAD: A Study of Mitigating the Impact of Speech Recognition Errors on Listening Comprehension , author=. Proc. Interspeech 2018 , pages=
2018
-
[5]
Joseph, Sonia and Suresh, Praneet and Goldfarb, Ethan and Hufe, Lorenz and Gandelsman, Yossi and Graham, Robert and Bzdok, Danilo and Samek, Wojciech and Richards, Blake Aaron , month = apr, year =. Steering. doi:10.48550/arXiv.2504.08729 , abstract =
-
[6]
2023 , journal=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , journal=
2023
-
[7]
2024 , journal=
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet , author=. 2024 , journal=
2024
-
[8]
Scaling and evaluating sparse autoencoders
Gao, Leo and Tour, Tom Dupré la and Tillman, Henk and Goh, Gabriel and Troll, Rajan and Radford, Alec and Sutskever, Ilya and Leike, Jan and Wu, Jeffrey , month = jun, year =. Scaling and evaluating sparse autoencoders , url =. doi:10.48550/arXiv.2406.04093 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.04093
-
[9]
Elhage, Nelson and Hume, Tristan and Olsson, Catherine and Schiefer, Nicholas and Henighan, Tom and Kravec, Shauna and Hatfield-Dodds, Zac and Lasenby, Robert and Drain, Dawn and Chen, Carol and Grosse, Roger and McCandlish, Sam and Kaplan, Jared and Amodei, Dario and Wattenberg, Martin and Olah, Christopher , month = sep, year =. Toy. doi:10.48550/arXiv....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2209.10652
-
[10]
Joseph, Sonia and Suresh, Praneet and Hufe, Lorenz and Stevinson, Edward and Graham, Robert and Vadi, Yash and Bzdok, Danilo and Lapuschkin, Sebastian and Sharkey, Lee and Richards, Blake Aaron , month = apr, year =. Prisma:. doi:10.48550/arXiv.2504.19475 , abstract =
-
[11]
, year =
Bishop, Christopher M. , year =. Pattern recognition and machine learning , isbn =
-
[12]
Maynez, Joshua and Narayan, Shashi and Bohnet, Bernd and McDonald, Ryan , month = may, year =. On. doi:10.48550/arXiv.2005.00661 , abstract =
-
[13]
Survey of Hallucination in Natural Language Generation , volume=
Survey of. ACM Comput. Surv. , author =. 2023 , pages =. doi:10.1145/3571730 , abstract =
-
[14]
Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L. and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul and Leike, Jan and Lowe, R...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.02155
-
[15]
Training Compute-Optimal Large Language Models
Hoffmann, Jordan and Borgeaud, Sebastian and Mensch, Arthur and Buchatskaya, Elena and Cai, Trevor and Rutherford, Eliza and Casas, Diego de Las and Hendricks, Lisa Anne and Welbl, Johannes and Clark, Aidan and Hennigan, Tom and Noland, Eric and Millican, Katie and Driessche, George van den and Damoc, Bogdan and Guy, Aurelia and Osindero, Simon and Simony...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.15556
-
[16]
Park, Kiho and Choe, Yo Joong and Veitch, Victor , month = jul, year =. The. doi:10.48550/arXiv.2311.03658 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2311.03658
-
[17]
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser, Lukasz and Polosukhin, Illia , month = aug, year =. Attention. doi:10.48550/arXiv.1706.03762 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.03762
-
[18]
Cunningham, Hoagy and Ewart, Aidan and Riggs, Logan and Huben, Robert and Sharkey, Lee , month = oct, year =. Sparse. doi:10.48550/arXiv.2309.08600 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.08600
-
[19]
Zhang, Chiyuan and Bengio, Samy and Hardt, Moritz , year =
-
[20]
Arjovsky, Martin and Bottou, Léon and Gulrajani, Ishaan and Lopez-Paz, David , month = mar, year =. Invariant. doi:10.48550/arXiv.1907.02893 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1907.02893 1907
-
[21]
Exploring the Limits of Weakly Supervised Pretraining
Mahajan, Dhruv and Girshick, Ross and Ramanathan, Vignesh and He, Kaiming and Paluri, Manohar and Li, Yixuan and Bharambe, Ashwin and Maaten, Laurens van der , month = may, year =. Exploring the. doi:10.48550/arXiv.1805.00932 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1805.00932
-
[22]
Hendrycks, Dan and Gimpel, Kevin , month = oct, year =. A. doi:10.48550/arXiv.1610.02136 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1610.02136
-
[23]
Lee, Kimin and Lee, Kibok and Lee, Honglak and Shin, Jinwoo , month = oct, year =. A. doi:10.48550/arXiv.1807.03888 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1807.03888
-
[24]
Hendrycks, Dan and Mazeika, Mantas and Dietterich, Thomas , month = jan, year =. Deep. doi:10.48550/arXiv.1812.04606 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1812.04606
-
[25]
Energy-based
Liu, Weitang and Wang, Xiaoyun and Owens, John and Li, Yixuan , year =. Energy-based. Advances in
-
[26]
Learning Transferable Visual Models From Natural Language Supervision
Radford, Alec and Kim, Jong Wook and Hallacy, Chris and Ramesh, Aditya and Goh, Gabriel and Agarwal, Sandhini and Sastry, Girish and Askell, Amanda and Mishkin, Pamela and Clark, Jack and Krueger, Gretchen and Sutskever, Ilya , month = feb, year =. Learning. doi:10.48550/arXiv.2103.00020 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2103.00020
-
[27]
Brown, Tom B. and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel M. and Wu, Jeffrey and W...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2005.14165 2005
-
[28]
Scaling Laws for Neural Language Models
Kaplan, Jared and McCandlish, Sam and Henighan, Tom and Brown, Tom B. and Chess, Benjamin and Child, Rewon and Gray, Scott and Radford, Alec and Wu, Jeffrey and Amodei, Dario , month = jan, year =. Scaling. doi:10.48550/arXiv.2001.08361 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2001.08361 2001
-
[29]
Suresh, Praneet and Stanley, Jack and Joseph, Sonia and Scimeca, Luca and Bzdok, Danilo , month = sep, year =. From. doi:10.48550/arXiv.2509.06938 , abstract =
-
[30]
Souly, Alexandra and Lu, Qingyuan and Bowen, Dillon and Trinh, Tu and Hsieh, Elvis and Pandey, Sana and Abbeel, Pieter and Svegliato, Justin and Emmons, Scott and Watkins, Olivia and Toyer, Sam , month = aug, year =. A. doi:10.48550/arXiv.2402.10260 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.10260
-
[31]
Jailbreak Attacks and Defenses Against Large Language Models: A Survey
Yi, Sibo and Liu, Yule and Sun, Zhen and Cong, Tianshuo and He, Xinlei and Song, Jiaxing and Xu, Ke and Li, Qi , month = aug, year =. Jailbreak. doi:10.48550/arXiv.2407.04295 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.04295
-
[32]
Why Language Models Hallucinate
Kalai, Adam Tauman and Nachum, Ofir and Vempala, Santosh S. and Zhang, Edwin , month = sep, year =. Why. doi:10.48550/arXiv.2509.04664 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.04664
-
[33]
Gan, Esther and Zhao, Yiran and Cheng, Liying and Mao, Yancan and Goyal, Anirudh and Kawaguchi, Kenji and Kan, Min-Yen and Shieh, Michael , month = nov, year =. Reasoning. doi:10.48550/arXiv.2411.05345 , abstract =
-
[34]
doi:10.48550/arXiv.2402.18216 , abstract =
Gupta, Akash and Sheth, Ivaxi and Raina, Vyas and Gales, Mark and Fritz, Mario , month = oct, year =. doi:10.48550/arXiv.2402.18216 , abstract =
-
[35]
Jailbroken: How Does LLM Safety Training Fail?
Wei, Alexander and Haghtalab, Nika and Steinhardt, Jacob , month = jul, year =. Jailbroken:. doi:10.48550/arXiv.2307.02483 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.02483
-
[36]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Zou, Andy and Wang, Zifan and Carlini, Nicholas and Nasr, Milad and Kolter, J. Zico and Fredrikson, Matt , month = dec, year =. Universal and. doi:10.48550/arXiv.2307.15043 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.15043
-
[37]
O'Brien, Kyle and Majercak, David and Fernandes, Xavier and Edgar, Richard and Bullwinkel, Blake and Chen, Jingya and Nori, Harsha and Carignan, Dean and Horvitz, Eric and Poursabzi-Sangdeh, Forough , month = may, year =. Steering. doi:10.48550/arXiv.2411.11296 , abstract =
-
[38]
Lieberum, Tom and Rajamanoharan, Senthooran and Conmy, Arthur and Smith, Lewis and Sonnerat, Nicolas and Varma, Vikrant and Kramár, János and Dragan, Anca and Shah, Rohin and Nanda, Neel , month = aug, year =. Gemma. doi:10.48550/arXiv.2408.05147 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.05147
-
[39]
Modell, Alexander and Rubin-Delanchy, Patrick and Whiteley, Nick , month = may, year =. The. doi:10.48550/arXiv.2505.18235 , abstract =
-
[40]
Emergent Abilities of Large Language Models
Wei, Jason and Tay, Yi and Bommasani, Rishi and Raffel, Colin and Zoph, Barret and Borgeaud, Sebastian and Yogatama, Dani and Bosma, Maarten and Zhou, Denny and Metzler, Donald and Chi, Ed H. and Hashimoto, Tatsunori and Vinyals, Oriol and Liang, Percy and Dean, Jeff and Fedus, William , month = oct, year =. Emergent. doi:10.48550/arXiv.2206.07682 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2206.07682
-
[41]
and Liao, Isaac and Gurnee, Wes and Tegmark, Max , month = feb, year =
Engels, Joshua and Michaud, Eric J. and Liao, Isaac and Gurnee, Wes and Tegmark, Max , month = feb, year =. Not. doi:10.48550/arXiv.2405.14860 , abstract =
-
[42]
Engels, Joshua and Riggs, Logan and Tegmark, Max , month = mar, year =. Decomposing. doi:10.48550/arXiv.2410.14670 , abstract =
-
[43]
Ameisen, Emmanuel and Lindsey, Jack and Pearce, Adam and Gurnee, Wes and Turner, Nicholas L. and Chen, Brian and Citro, Craig and Abrahams, David and Carter, Shan and Hosmer, Basil and Marcus, Jonathan and Sklar, Michael and Templeton, Adly and Bricken, Trenton and McDougall, Callum and Cunningham, Hoagy and Henighan, Thomas and Jermyn, Adam and Jones, An...
-
[44]
TinyStories: How Small Can Language Models Be and Still Speak Coherent English?
Eldan, Ronen and Li, Yuanzhi , month = may, year =. doi:10.48550/arXiv.2305.07759 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.07759
-
[45]
OpenAI and Achiam, Josh and Adler, Steven and Agarwal, Sandhini and Ahmad, Lama and Akkaya, Ilge and Aleman, Florencia Leoni and Almeida, Diogo and Altenschmidt, Janko and Altman, Sam and Anadkat, Shyamal and Avila, Red and Babuschkin, Igor and Balaji, Suchir and Balcom, Valerie and Baltescu, Paul and Bao, Haiming and Bavarian, Mohammad and Belgum, Jeff a...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774
-
[46]
On the Opportunities and Risks of Foundation Models
Bommasani, Rishi and Hudson, Drew A. and Adeli, Ehsan and Altman, Russ and Arora, Simran and Arx, Sydney von and Bernstein, Michael S. and Bohg, Jeannette and Bosselut, Antoine and Brunskill, Emma and Brynjolfsson, Erik and Buch, Shyamal and Card, Dallas and Castellon, Rodrigo and Chatterji, Niladri and Chen, Annie and Creel, Kathleen and Davis, Jared Qui...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2108.07258
-
[47]
Transactions on Machine Learning Research , author =
Holistic. Transactions on Machine Learning Research , author =. 2023 , file =
2023
-
[48]
Leask, Patrick and Bussmann, Bart and Pearce, Michael and Bloom, Joseph and Tigges, Curt and Moubayed, Noura Al and Sharkey, Lee and Nanda, Neel , month = feb, year =. Sparse. doi:10.48550/arXiv.2502.04878 , abstract =
-
[49]
Paulo, Gonçalo and Belrose, Nora , month = jan, year =. Sparse. doi:10.48550/arXiv.2501.16615 , abstract =
-
[50]
doi:10.48550/arXiv.2406.18510 , abstract =
Jiang, Liwei and Rao, Kavel and Han, Seungju and Ettinger, Allyson and Brahman, Faeze and Kumar, Sachin and Mireshghallah, Niloofar and Lu, Ximing and Sap, Maarten and Choi, Yejin and Dziri, Nouha , month = jun, year =. doi:10.48550/arXiv.2406.18510 , abstract =
-
[51]
Language
Radford, Alec and Wu, Jeffrey and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya , file =. Language
-
[52]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and Yang, Amy and Fan, Angela and Goyal, Anirudh and Hartshorn, Anthony and Yang, Aobo and Mitra, Archi and Sravankumar, Archie and Korenev, Artem and Hinsvark, A...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783
-
[53]
Team, Gemini and Anil, Rohan and Borgeaud, Sebastian and Alayrac, Jean-Baptiste and Yu, Jiahui and Soricut, Radu and Schalkwyk, Johan and Dai, Andrew M. and Hauth, Anja and Millican, Katie and Silver, David and Johnson, Melvin and Antonoglou, Ioannis and Schrittwieser, Julian and Glaese, Amelia and Chen, Jilin and Pitler, Emily and Lillicrap, Timothy and ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.11805
-
[54]
and McGrath, T
Balsam, D. and McGrath, T. and Gorton, L. and Nguyen, N. and Deng, M. and Ho, E. , month = jan, year =. Announcing open-source saes for llama 3.3
-
[55]
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Li, Tianle and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Li, Zhuohan and Lin, Zi and Xing, Eric P. and Gonzalez, Joseph E. and Stoica, Ion and Zhang, Hao , month = mar, year =. doi:10.48550/arXiv.2309.11998 , abstract =
-
[56]
Bloom, Joseph and Tigges, Curt and Duong, Anthony and Chanin, David , year =
-
[57]
Measuring Massive Multitask Language Understanding
Hendrycks, Dan and Burns, Collin and Basart, Steven and Zou, Andy and Mazeika, Mantas and Song, Dawn and Steinhardt, Jacob , month = jan, year =. Measuring. doi:10.48550/arXiv.2009.03300 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2009.03300 2009
-
[58]
2025 , eprint=
Quantifying Feature Space Universality Across Large Language Models via Sparse Autoencoders , author=. 2025 , eprint=
2025
-
[59]
Convergent Learning: Do different neural networks learn the same representations?
Li, Yixuan and Yosinski, Jason and Clune, Jeff and Lipson, Hod and Hopcroft, John , month = feb, year =. Convergent. doi:10.48550/arXiv.1511.07543 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1511.07543
-
[60]
LoRA: Low-Rank Adaptation of Large Language Models
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , month = oct, year =. doi:10.48550/arXiv.2106.09685 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2106.09685
-
[61]
Recht, Benjamin and Roelofs, Rebecca and Schmidt, Ludwig and Shankar, Vaishaal , month = jun, year =. Do. doi:10.48550/arXiv.1902.10811 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1902.10811 1902
-
[62]
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Han, Zeyu and Gao, Chao and Liu, Jinyang and Zhang, Jeff and Zhang, Sai Qian , month = sep, year =. Parameter-. doi:10.48550/arXiv.2403.14608 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.14608
-
[63]
Steering Language Models With Activation Engineering
Turner, Alexander Matt and Thiergart, Lisa and Leech, Gavin and Udell, David and Vazquez, Juan J. and Mini, Ulisse and MacDiarmid, Monte , month = oct, year =. Steering. doi:10.48550/arXiv.2308.10248 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.10248
-
[64]
and Potts, Christopher , month = may, year =
Wu, Zhengxuan and Arora, Aryaman and Wang, Zheng and Geiger, Atticus and Jurafsky, Dan and Manning, Christopher D. and Potts, Christopher , month = may, year =. doi:10.48550/arXiv.2404.03592 , abstract =
-
[65]
doi:10.48550/arXiv.2412.15194 , abstract =
Zhao, Qihao and Huang, Yangyu and Lv, Tengchao and Cui, Lei and Sun, Qinzheng and Mao, Shaoguang and Zhang, Xin and Xin, Ying and Yin, Qiufeng and Li, Scarlett and Wei, Furu , month = dec, year =. doi:10.48550/arXiv.2412.15194 , abstract =
-
[66]
2025 , annote =
karpathy/tiny\_shakespeare ·. 2025 , annote =
2025
-
[67]
project-gutenberg-poetry-corpus , language =
Parrish, Allison , file =. project-gutenberg-poetry-corpus , language =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.