auto-psych: Automating the science of mind using agent-driven theory discovery and experimentation
Pith reviewed 2026-06-26 01:06 UTC · model grok-4.3
The pith
An agent system discovers cognitive models of human randomness judgments that fit experimental data better than models drawn from the scientific literature.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
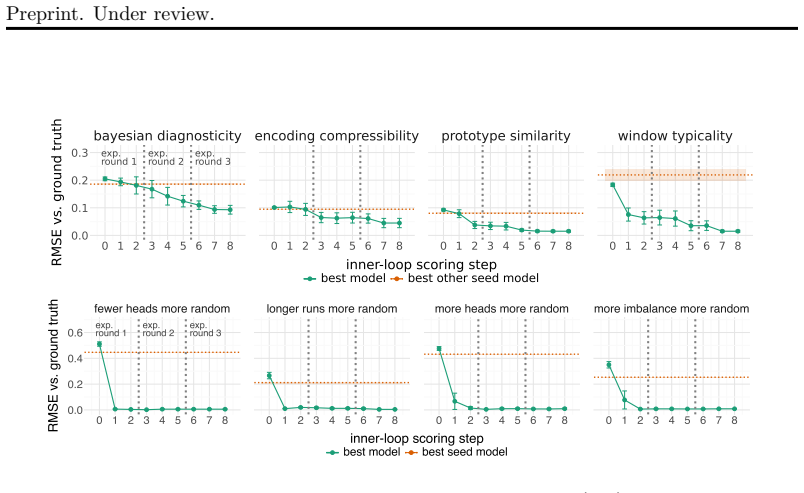
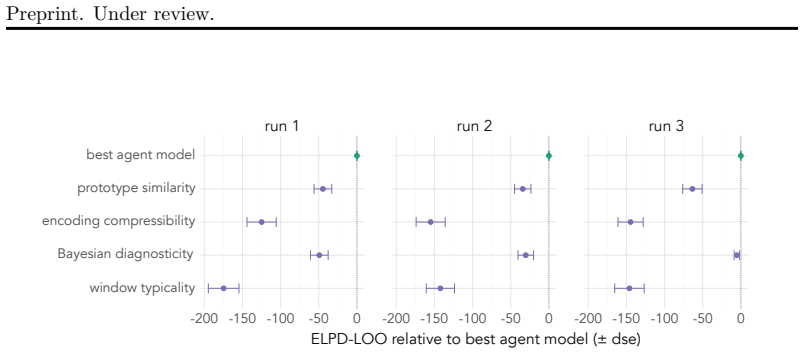
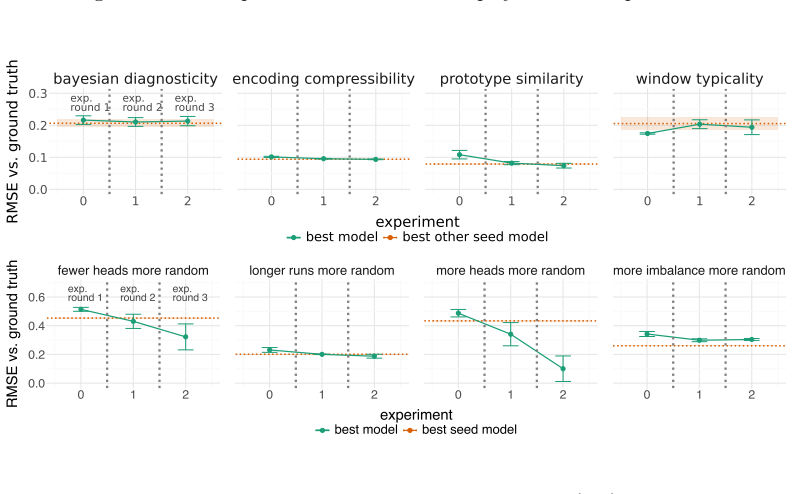
The central claim is that a nested agent architecture can autonomously recover explanatory probabilistic cognitive models for human sequence-randomness judgments, and that these models achieve better fit to newly collected human data than models constructed from the existing literature. The architecture separates model invention and critique (inner loop) from experiment design, data gathering via crowdsourcing, and analysis (outer loop). When run on synthetic data with known ground-truth models, the nested structure recovers the correct models; on human data it yields superior explanatory theories.
What carries the argument
Nested agent-based discovery loops: the inner loop conjectures, fits, and critiques probabilistic cognitive models; the outer loop designs experiments, launches them on crowdsourcing platforms, and analyzes the returned human responses.
If this is right
- The nested loop structure is required for reliable recovery of ground-truth models from synthetic data.
- The same architecture can be applied to other domains in computational cognitive science where theories are expressible as code.
- Automated data collection through crowdsourcing removes a major bottleneck in scaling theory discovery.
- The system produces models that outperform literature baselines across multiple independent human-experiment sequences.
Where Pith is reading between the lines
- If the inner-loop agents can be prevented from simply re-expressing known models, the approach could be extended to problems where no strong literature baseline exists.
- Replacing the current model class with richer formalisms (for example, hierarchical or resource-rational models) would test whether the performance advantage scales with model complexity.
- Connecting the outer loop to real-time adaptive experiment design could further reduce the number of participants needed to distinguish competing theories.
Load-bearing premise
The agent-generated models are meaningfully different from and better than those already present in the published literature rather than rediscovering or overfitting to patterns already captured by existing accounts.
What would settle it
Run the system on a new set of human participants judging coin-flip sequences and find that a literature-derived model fits the data at least as well as the agent-generated model.
Figures


read the original abstract
AI-based scientific automation is increasingly possible by using agents to generate hypotheses, design experiments, and analyze data. Data collection is a major bottleneck in this pipeline, however. Psychology, and computational cognitive science in particular, is well-positioned to benefit from AI experimentation because theories are often represented as code and crowdsourcing platforms enable programmatic human data collection at scale. Here, we apply automated discovery techniques to the project of generating theories in computational cognitive science, with an agent-based system collecting human data independently through crowdsourced survey experiments. As a testbed, we use a classic case study from cognitive psychology: judging which sequences of coin flips seem subjectively more random. Our system, auto-psych, uses nested agent-based discovery loops to generate explanatory theories of human behavior. The inner loop conjectures, fits, and critiques probabilistic cognitive models; the outer loop designs experiments to test these models, launches them online, and analyzes the data. This system can quickly and reliably recover ground-truth theories from synthetic data via systematic experimentation, but the nested structure is critical to model performance. Further, in three independent sequences of human experiments, the system finds theories that fit the data better than theories generated from the scientific literature. This work thus demonstrates the feasibility of automated data collection and theory discovery in computational cognitive science.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces auto-psych, an agent-based system with nested loops for automated theory discovery in computational cognitive science. The inner loop uses agents to conjecture, fit, and critique probabilistic cognitive models; the outer loop designs experiments, collects human data via crowdsourced platforms, and analyzes results. Applied to the classic task of judging subjective randomness in coin-flip sequences, the system claims to recover ground-truth models from synthetic data (with the nested structure being critical) and, across three independent sequences of human experiments, to discover models that fit the data better than theories derived from the scientific literature.
Significance. If the empirical claims hold under rigorous controls, the work demonstrates the feasibility of closing the loop between automated hypothesis generation, online experimentation, and model refinement in psychology, addressing the data-collection bottleneck. The use of programmatic crowdsourcing and agent-driven search is a concrete strength that could scale theory development; credit is due for testing on both synthetic recovery and multiple human datasets. Significance is tempered by the need to confirm that performance gains reflect genuine discovery rather than uncontrolled differences in model expressivity or fitting effort.
major comments (3)
- [Abstract / Results (human experiments)] Abstract and Results sections on human experiments: the central claim that auto-psych models fit the three human datasets better than literature-derived theories supplies no details on the comparison metrics (e.g., log-likelihood, BIC), statistical significance tests, data-exclusion rules, or cross-validation protocols used to guard against overfitting; these omissions are load-bearing because the outperformance result is the primary empirical contribution.
- [Methods (inner loop) / Results (human experiments)] Methods (inner-loop description) and Results (comparison to literature): the manuscript does not specify how literature theories were selected and encoded as probabilistic programs, whether the agent's hypothesis space can rediscover the same functional forms, or whether parameter counts, optimization budgets, and fitting procedures were matched between auto-psych and literature models; without these controls, superior fit may arise from greater search effort or expressivity rather than discovery.
- [Results (synthetic data)] Results (synthetic data recovery): the claim that the nested structure is critical to recovering ground-truth models lacks an explicit ablation (e.g., inner-loop-only vs. full nested performance) or quantitative metrics showing how much the outer loop contributes beyond the inner loop alone; this is load-bearing for the architectural argument.
minor comments (2)
- [Figure 1 / System overview] Figure 1 or system diagram: the distinction between inner- and outer-loop agent roles and information flow could be clarified with explicit labels or pseudocode to aid reproducibility.
- [References / Methods] References: ensure that all literature-derived theories used for comparison are cited with their original sources and that any probabilistic-program encodings are described or linked.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas where additional rigor will strengthen the manuscript. We address each point below and will incorporate the requested details and analyses.
read point-by-point responses
-
Referee: Abstract and Results sections on human experiments: the central claim that auto-psych models fit the three human datasets better than literature-derived theories supplies no details on the comparison metrics (e.g., log-likelihood, BIC), statistical significance tests, data-exclusion rules, or cross-validation protocols used to guard against overfitting; these omissions are load-bearing because the outperformance result is the primary empirical contribution.
Authors: We agree these details are essential. The revised manuscript will report the exact metrics (log-likelihood and BIC), include statistical significance tests on the fit differences, specify data-exclusion rules for the crowdsourced responses, and describe the cross-validation protocols used. revision: yes
-
Referee: Methods (inner-loop description) and Results (comparison to literature): the manuscript does not specify how literature theories were selected and encoded as probabilistic programs, whether the agent's hypothesis space can rediscover the same functional forms, or whether parameter counts, optimization budgets, and fitting procedures were matched between auto-psych and literature models; without these controls, superior fit may arise from greater search effort or expressivity rather than discovery.
Authors: We will expand the Methods section to detail the selection of literature theories from key papers on randomness perception and their encoding as probabilistic programs. We will add evidence that the hypothesis space can rediscover those functional forms and will report parameter counts along with a description of how fitting procedures and optimization were aligned for the comparison. revision: yes
-
Referee: Results (synthetic data recovery): the claim that the nested structure is critical to recovering ground-truth models lacks an explicit ablation (e.g., inner-loop-only vs. full nested performance) or quantitative metrics showing how much the outer loop contributes beyond the inner loop alone; this is load-bearing for the architectural argument.
Authors: We will add an explicit ablation subsection to the Results on synthetic recovery. It will include quantitative metrics (recovery accuracy and model fit) comparing inner-loop-only performance against the full nested system, quantifying the outer loop's contribution. revision: yes
Circularity Check
No significant circularity detected
full rationale
The available text describes a nested agent system for generating and testing probabilistic cognitive models against human data, with empirical claims of recovering ground-truth models from synthetic data and outperforming literature-derived theories in three human experiment sequences. No equations, parameter-fitting procedures, or self-citations are quoted that reduce any prediction or central result to its inputs by construction, nor is there evidence of self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations. The derivation chain for the system's performance is presented as an independent empirical outcome rather than a tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
It contains: − Paths to the problem definition, `cognitive_models/` dir, and previous ,→ experiment dirs − The current experiment number
∗∗Read CONTEXT.md∗∗ (path given below). It contains: − Paths to the problem definition, `cognitive_models/` dir, and previous ,→ experiment dirs − The current experiment number
-
[2]
Note the ,→ stimulus schema and the ∗∗feature columns∗∗ available in the responses CSV ( ,→ these are the names your `pm.Data` containers must match)
∗∗Read the problem definition∗∗ at the path given in CONTEXT.md. Note the ,→ stimulus schema and the ∗∗feature columns∗∗ available in the responses CSV ( ,→ these are the names your `pm.Data` containers must match). 17 Preprint. Under review
-
[3]
PDFs or papers in `references/` may be consulted for ,→ scientific background
∗∗If this is experiment 1∗∗: Propose 2−3 cognitive models, each a single ,→ distinct hypothesis. PDFs or papers in `references/` may be consulted for ,→ scientific background. ∗∗If this is experiment 2+∗∗: − Copy all `.py` files from the previous experiment ' s `cognitive_models/` ,→ directory into this experiment ' s `cognitive_models/` directory. This d...
-
[4]
∗∗For each new model∗∗, state the hypothesis first, then implement only it: − In `models_manifest.yaml`, add an entry whose ∗∗`rationale` is the one− ,→ sentence hypothesis∗∗ the model embodies, in plain English. − Write `<model_name>.py` in `cognitive_models/` (a module−level PyMC model −− ,→ see format below) whose ∗∗module docstring restates that hypot...
-
[5]
chose_left
∗∗Write `cognitive_models/theory_report.md`∗∗ with a short entry for each ∗∗new ,→ ∗∗ model: ```markdown # Theory Report −− Experiment N ## [model_name] ∗∗Hypothesis:∗∗ [The single claim about what people are doing, in one or two ,→ plain sentences.] ∗∗Motivation:∗∗ [Why add this hypothesis now? Reference specific findings from ,→ the model−loop report −−...
-
[6]
It contains paths to the problem ,→ definition, cognitive models, and output directories
∗∗Read CONTEXT.md∗∗ (path given below). It contains paths to the problem ,→ definition, cognitive models, and output directories
-
[7]
∗∗Read the problem definition∗∗ to understand the task and stimulus schema
-
[8]
sequence_a
∗∗Generate candidate stimuli∗∗ according to the problem definition ' s stimulus ,→ schema. Write them to `design/candidates.json` as a JSON list of `{"sequence_a": 20 Preprint. Under review. ,→ ..., "sequence_b": ...}` dicts. Keep the pool ∗∗tractable (roughly 100−300 ,→ pairs)∗∗: every candidate is scored by EIG, so a huge pool only makes the next ,→ step slow
-
[9]
EIG is computed over the theorist ' s PyMC models from their ∗∗prior−predictive∗∗ `p_left` (no MCMC fit needed at design time)
∗∗Score by EIG∗∗ using the pipeline helper. EIG is computed over the theorist ' s PyMC models from their ∗∗prior−predictive∗∗ `p_left` (no MCMC fit needed at design time). Run this command in the ∗∗foreground and wait for it to finish∗∗ −− do not background it and end your turn before `stimuli.json` exists. Pass `−−featurize` so raw stimuli are turned int...
-
[10]
∗∗Write `design/design_rationale.md`∗∗: brief rationale −− how many stimuli, EIG ,→ range, how the design discriminates between models. ## Self−validation checklist Before finishing, verify: − [ ] `design/stimuli.json` exists and contains a JSON list − [ ] Each stimulus has `sequence_a`, `sequence_b`, and `eig` (numeric) − [ ] At least one stimulus has `e...
-
[11]
I agree"∗∗ −− a full−screen page showing the IRB−approved consent text with an ∗∗
∗∗Consent + "I agree"∗∗ −− a full−screen page showing the IRB−approved consent text with an ∗∗"I agree"∗∗ button. ∗∗You do NOT build this.∗∗ The deployment step injects it automatically, using the approved verbatim wording, as a gate in front of your experiment; clicking ∗∗"I agree"∗∗ reveals whatever your timeline shows first. Do ∗∗not∗∗ write your own c...
-
[12]
consent" /
∗∗Instructions∗∗ −− the ∗∗first screen of your jsPsych timeline MUST be an instructions page∗∗ that tells the participant what the task is, what they will see, and how to respond. No trial may appear before it. This page is ∗∗purely task instructions∗∗ −− it must ∗∗not∗∗ look like a second consent form: do not title it "consent" / "Research Study Consent"...
-
[13]
In short: the consent gate is added for you, so your timeline begins with the ∗∗instructions page∗∗ and then the trials −− never a trial first
∗∗Trials∗∗ −− one stimulus per trial, as described in the problem definition. In short: the consent gate is added for you, so your timeline begins with the ∗∗instructions page∗∗ and then the trials −− never a trial first. ## Your task
-
[14]
∗∗Read CONTEXT.md∗∗ (path below) −− it has the paths to the problem definition, `design/stimuli.json`, and the `experiment/` output directory
-
[15]
Experiment presentation
∗∗Read the problem definition∗∗, especially its ∗∗"Experiment presentation"∗∗ section. Use that instructions / choice−label / debrief wording ∗∗verbatim∗∗ −− do not paraphrase. If the project does not specify wording, use the defaults in the skeleton below unchanged
-
[16]
∗∗Read `design/stimuli.json`∗∗ −− embed ∗∗every∗∗ stimulus, verbatim
-
[17]
∗∗Write `experiment/index.html`∗∗ following the FIXED structure below
-
[18]
experiment_url
∗∗Write `experiment/config.json`∗∗: exactly `{ "experiment_url": null }`
-
[19]
∗∗Write `experiment/stimuli.json`∗∗ as a copy of `design/stimuli.json`. ## FIXED structure (copy this; change only `STIMULI` and the project wording) ```html <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF−8" /> <meta name="viewport" content="width=device−width, initial−scale=1.0" /> <title>Experiment</title> <script src="https://unpkg.com/jsps...
-
[20]
Under review
says what the statistic measures, 26 Preprint. Under review
-
[21]
states the ∗∗direction∗∗ of the discrepancy −− does the model ∗∗under−∗∗ or ∗∗over−∗∗estimate the quantity relative to the humans (compare `t_observed` to `null_mean`)?, and
-
[22]
Treat this as evidence of mismatch, not a null−hypothesis rejection claim
names which assumption in the incumbent ' s single mechanism is likely inadequate, and what a next model could change to close the gap. Treat this as evidence of mismatch, not a null−hypothesis rejection claim. Use this structure: ```markdown # Critique of `<incumbent>` <one line: N significant discrepancies at p <= <alpha>, over <k> test statistics.> ## ...
-
[23]
`CONTEXT.md` −− paths, the responses CSV schema (the feature columns your model may read), and the inner−loop round number
-
[24]
`CANDIDATE_BRIEF.md` −− what kind of hypothesis to attempt this round
-
[25]
chose_left
`existing_hypotheses.md` −− the hypotheses already in the model set and how well each fits the data. Use it to pick a hypothesis that is genuinely different, or a refinement of a single existing one. ## Goal Each model is one specific, falsifiable hypothesis about the cognitive process people use −− ∗∗not∗∗ a fit−maximizing combination of cues. Articulate...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.