What the LLM Should Not Say: Boundary-Aware Context Grounding for A Seven-Channel EEG Agent
Pith reviewed 2026-06-29 05:19 UTC · model grok-4.3
The pith
Hardware-aware context packs let an EEG agent refuse unsupported interpretations while keeping raw data local.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that hardware- and implementation-aware grounding, delivered through an allowlisted summary and versioned context pack, serves as a practical mechanism for calibrating what an EEG agent accepts, qualifies, or refuses on seven-channel recordings; the numerical engine produces identical structured outputs and hashes across repetitions, local artifacts survive network and malformed-output failures, and LLM responses to the boundary-awareness benchmark vary with context ablations.
What carries the argument
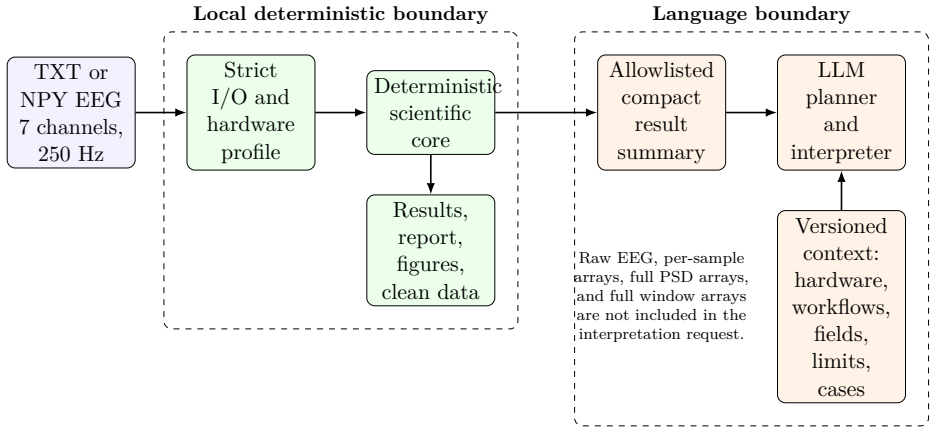
The versioned context pack that encodes the seven-channel hardware specifications, reviewed spectral workflows, result fields, implementation boundaries, scientific limits, and reference cases, restricting the LLM input to prevent unsupported interpretations.
If this is right
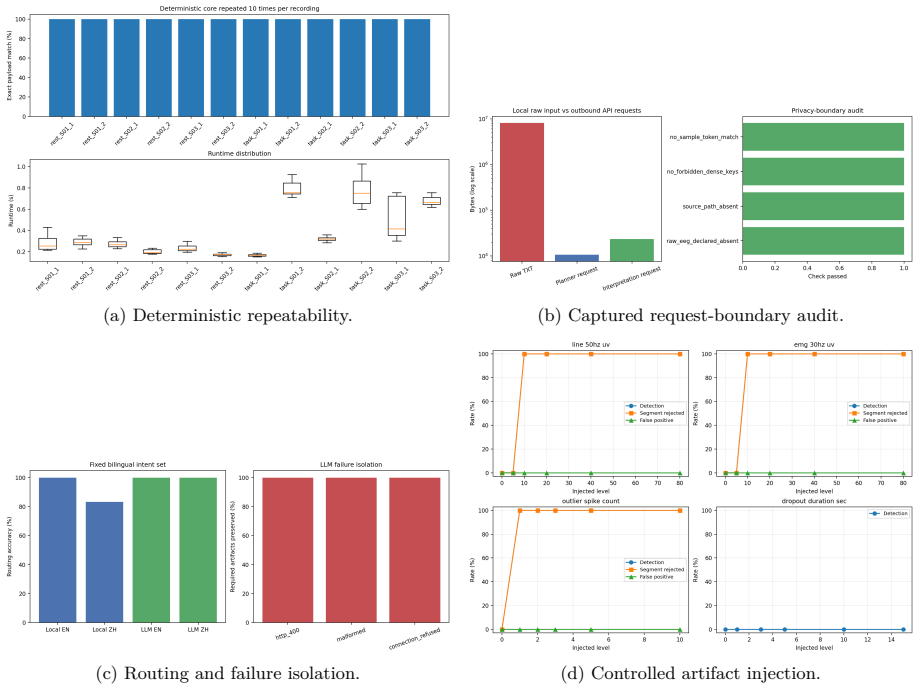
- Numerical results from the local engine remain identical across ten repetitions of the same 12 recordings.
- Complete Rest/Task runs produce matching result, report, and figure hashes across three repetitions.
- Local artifacts stay intact under HTTP, malformed-output, and connection failures.
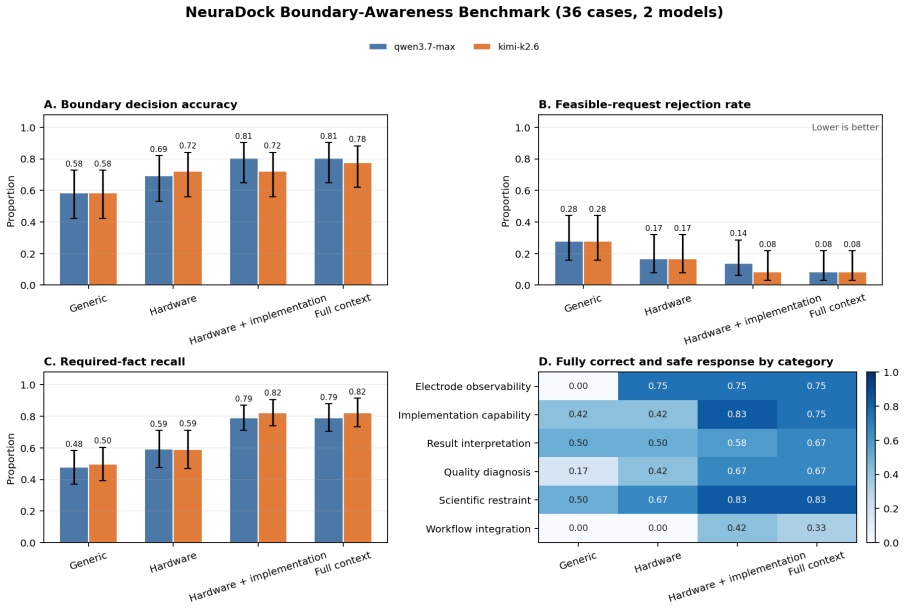
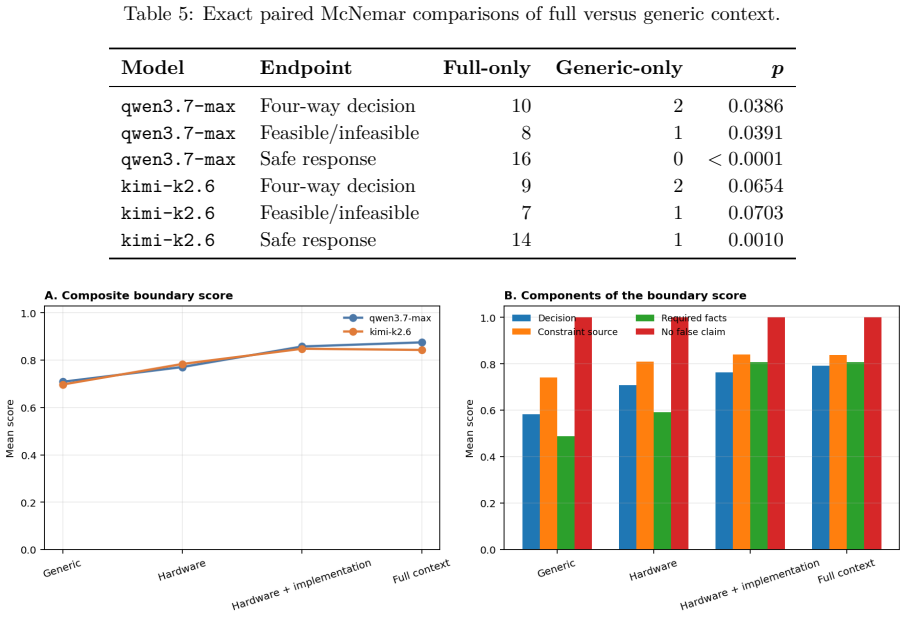
- LLM answers to ordinary and adversarial questions change when boundary information is ablated from the context pack.
Where Pith is reading between the lines
- The same separation of local engine and restricted context could extend to other sparse-sensor domains where misinterpretation risk is high.
- Versioning the context pack allows updates to scientific limits without changing the underlying language model.
- Expanding the benchmark beyond the current question set would test coverage of open-ended user inputs.
- Pairing the approach with on-device execution could further limit exposure of raw recordings.
Load-bearing premise
The allowlisted summary and versioned context pack together with the tested 36-question set are sufficient to block plausible but unsupported interpretations across the full range of real user queries.
What would settle it
An LLM given the complete context pack still produces a detailed but hardware-incompatible interpretation of a seven-channel recording on a query type not covered in the 36-question benchmark.
Figures



read the original abstract
Large language models (LLMs) can make scientific software easier to use. However, a general model does not automatically know which measurements a particular sensor can support, which algorithms are implemented in the current software, or which conclusions are justified by a computed result. These distinctions are especially important for low-channel electroencephalography (EEG), where sparse spatial coverage and variable signal quality make plausible but unsupported interpretations easy to produce. We present NeuraDock Agent, an open-source architecture that separates a deterministic local EEG engine from a hardware-aware language layer. The numerical engine parses recordings, performs quality control, executes reviewed spectral workflows, and writes machine-readable artifacts. The LLM receives only a compact, allowlisted summary and a versioned context pack. The context describes the seven-channel hardware, reviewed workflows, result fields, implementation boundaries, scientific limits, and reference cases. Raw EEG and dense per-sample arrays remain local We evaluate the system at three levels. First, 12 recordings produced identical structured results over ten numerical repetitions, and a complete Rest/Task run produced identical result, report, and figure hashes over three repetitions. Second, request-capture and failure-injection experiments confirmed the tested data boundary and preservation of local artifacts under HTTP, malformed-output, and connection failures. Third, a boundary-awareness benchmark tested 36 ordinary and adversarial questions under four context ablations and two LLMs, yielding 288 outputs.These results support hardware- and implementation-aware grounding as a practical mechanism for calibrating what an EEG agent accepts, qualifies, or refuses; they do not establish clinical validity or a validated absolute cognitive-load index.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents NeuraDock Agent, an open-source architecture separating a deterministic local EEG engine (parsing, QC, spectral workflows, artifact writing) from an LLM layer that receives only an allowlisted summary and versioned context pack describing seven-channel hardware, reviewed workflows, result fields, implementation boundaries, and scientific limits. Raw EEG remains local. Three evaluations are described: (1) identical structured results over ten numerical repetitions on 12 recordings and identical hashes over three full Rest/Task runs; (2) request-capture and failure-injection tests confirming data boundaries under HTTP, malformed-output, and connection failures; (3) a boundary-awareness benchmark with 36 ordinary/adversarial questions, four context ablations, two LLMs, and 288 outputs. The central claim is that hardware- and implementation-aware grounding provides a practical mechanism for calibrating LLM acceptance, qualification, or refusal.
Significance. If the benchmark results establish that the allowlisted summary plus versioned context pack reliably modulates refusal/qualification behavior, the work supplies a concrete, reproducible engineering pattern for reducing plausible-but-unsupported LLM outputs in domain-specific scientific tools. The explicit separation of local numerical engine from LLM, the use of versioned context, and the failure-injection tests are practical strengths that could be adopted in other sensor-software interfaces.
major comments (1)
- [Third evaluation level (boundary-awareness benchmark)] Boundary-awareness benchmark (third evaluation level): the text reports only the experimental counts (36 questions, 4 ablations, 2 LLMs, 288 outputs) and states that raw EEG stays local, but supplies no quantitative breakdown of acceptance/qualification/refusal rates, no scoring rubric or inter-rater procedure, and no argument that the 36 questions sample the space of queries that could elicit unsupported interpretations. This information is load-bearing for the claim that the grounding mechanism calibrates responses.
minor comments (2)
- [Abstract] The abstract states that the context pack describes 'reviewed spectral workflows' but does not list the specific workflows or cite the review process; adding this detail would clarify the scope of the allowlisted summary.
- [First evaluation level] The reproducibility experiments report identical result hashes but do not specify the exact hash algorithm or the precise set of artifacts included in the hash; this would strengthen the claim of deterministic behavior.
Simulated Author's Rebuttal
We thank the referee for the constructive review and positive assessment of the work's practical contributions. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Boundary-awareness benchmark (third evaluation level): the text reports only the experimental counts (36 questions, 4 ablations, 2 LLMs, 288 outputs) and states that raw EEG stays local, but supplies no quantitative breakdown of acceptance/qualification/refusal rates, no scoring rubric or inter-rater procedure, and no argument that the 36 questions sample the space of queries that could elicit unsupported interpretations. This information is load-bearing for the claim that the grounding mechanism calibrates responses.
Authors: We agree that the current description of the boundary-awareness benchmark is insufficient to support the central claim. In the revised manuscript we will add: (1) quantitative results (tables or figures) reporting acceptance/qualification/refusal rates broken down by context ablation, LLM, and question type (ordinary vs. adversarial); (2) the explicit scoring rubric with definitions and examples for each category; (3) details of the rating procedure (single annotator or inter-rater agreement if multiple); and (4) a justification of the 36-question set, including how the questions were chosen to cover the space of queries likely to elicit unsupported interpretations of seven-channel EEG data. These additions will be placed in a dedicated subsection of the evaluation section. revision: yes
Circularity Check
No circularity: engineering description with empirical repetition tests
full rationale
The manuscript describes an open-source architecture separating a local EEG engine from an LLM layer, then reports three levels of empirical evaluation (numerical repetition identity, failure-injection boundary tests, and a 36-question benchmark across ablations). No equations, fitted parameters, derivations, or self-citation chains appear that would reduce any claim to its own inputs by construction. The central claim rests on experimental counts rather than a mathematical reduction, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Adrian, E. D., and Matthews, B. H. C. (1934). The Berger rhythm: potential changes from the occipital lobes in man.Brain, 57(4), 355–385.https://doi.org/10.1093/brain/57 .4.355
-
[2]
Arias-Cabarcos, P., Habrich, T., Becker, K., Becker, C., and Strufe, T. (2021). Inexpensive brainwave authentication: new techniques and insights on user acceptance. In30th USENIX 23 Security Symposium, 55–72.https://www.usenix.org/conference/usenixsecurity21 /presentation/arias-cabarcos
2021
-
[3]
Delorme, A., and Makeig, S. (2004). EEGLAB: an open source toolbox for analysis of single- trial EEG dynamics including independent component analysis.Journal of Neuroscience Methods, 134(1), 9–21.https://doi.org/10.1016/j.jneumeth.2003.10.009
-
[4]
Gramfort, A., et al. (2013). MEG and EEG data analysis with MNE-Python.Frontiers in Neuroscience, 7, 267.https://doi.org/10.3389/fnins.2013.00267
-
[5]
Hager, P., et al. (2024). Evaluation and mitigation of the limitations of large language models in clinical decision-making.Nature Medicine, 30, 2613–2622.https://doi.org/10 .1038/s41591-024-03097-1
2024
-
[6]
Ji, Z., etal. (2023). Survey of hallucination innatural language generation.ACM Computing Surveys, 55(12), Article 248.https://doi.org/10.1145/3571730
-
[7]
Klimesch, W. (1999). EEG alpha and theta oscillations reflect cognitive and memory performance: a review and analysis.Brain Research Reviews, 29(2–3), 169–195.https: //doi.org/10.1016/S0165-0173(98)00056-3
-
[8]
Lewis, P., et al. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems, 33, 9459–9474.https://proceedi ngs.neurips.cc/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.ht ml
2020
-
[9]
Lin, J., Chen, W.-M., Lin, Y., Cohn, J., Gan, C., and Han, S. (2020). MCUNet: tiny deep learning on IoT devices. InAdvances in Neural Information Processing Systems, 33, 11711–11722.https://proceedings.neurips.cc/paper/2020/hash/86c51678350f656 dcc7f490a43946ee5-Abstract.html
2020
-
[10]
Martinovic, I., et al. (2012). On the feasibility of side-channel attacks with brain-computer interfaces. In21st USENIX Security Symposium, 143–158.https://www.usenix.org/con ference/usenixsecurity12/technical-sessions/presentation/martinovic
2012
-
[11]
NeuraDock: open source EEG sensing platform
NeuraDock (2026). NeuraDock: open source EEG sensing platform. Hardware overview and technical specifications.https://www.crowdsupply.com/shinwe-tech/neuradock
2026
-
[12]
Rocher, L., Hendrickx, J. M., and de Montjoye, Y.-A. (2019). Estimating the success of re-identifications in incomplete datasets using generative models.Nature Communications, 10, 3069.https://doi.org/10.1038/s41467-019-10933-3
-
[13]
Schick, T., et al. (2023). Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems, 36.https://arxiv.org/abs/23 02.04761
2023
-
[14]
Simmons, J. P., Nelson, L. D., and Simonsohn, U. (2011). False-positive psychology: undis- closed flexibility in data collection and analysis allows presenting anything as significant. Psychological Science, 22(11), 1359–1366.https://doi.org/10.1177/0956797611417632
-
[15]
Singhal, K., et al. (2023). Large language models encode clinical knowledge.Nature, 620, 172–180.https://doi.org/10.1038/s41586-023-06291-2
-
[16]
Thut, G., Nietzel, A., Brandt, S. A., and Pascual-Leone, A. (2006). Alpha-band elec- troencephalographic activity over occipital cortex indexes visuospatial attention bias and predicts visual target detection.Journal of Neuroscience, 26(37), 9494–9502.https: //doi.org/10.1523/JNEUROSCI.0875-06.2006. 24
-
[17]
Wilkinson, M.D., etal.(2016).TheFAIRGuidingPrinciplesforscientificdatamanagement and stewardship.Scientific Data, 3, 160018.https://doi.org/10.1038/sdata.2016.18
-
[18]
Yao, S., et al. (2023). ReAct: Synergizing reasoning and acting in language models. In International Conference on Learning Representations.https://openreview.net/forum ?id=WE_vluYUL-X. 25
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.