A Shared IPTC Topic Space for Cross-Source Topic Modelling
Pith reviewed 2026-06-26 02:37 UTC · model grok-4.3
The pith
A fixed taxonomy creates one shared topic space that aligns models fitted to separate corpora.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
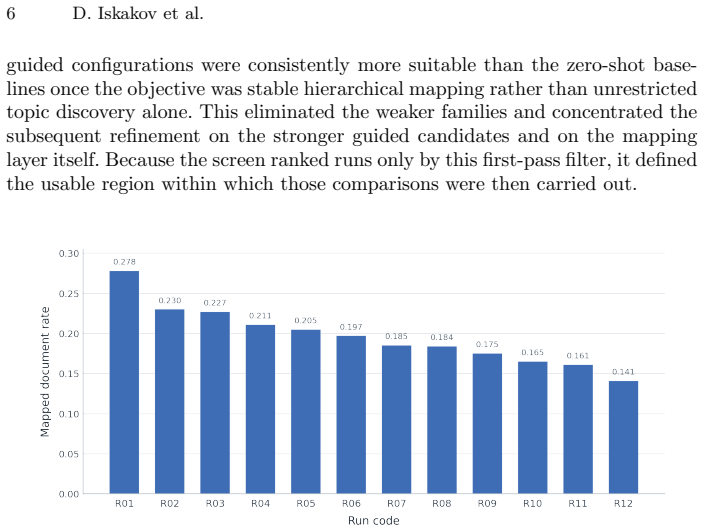
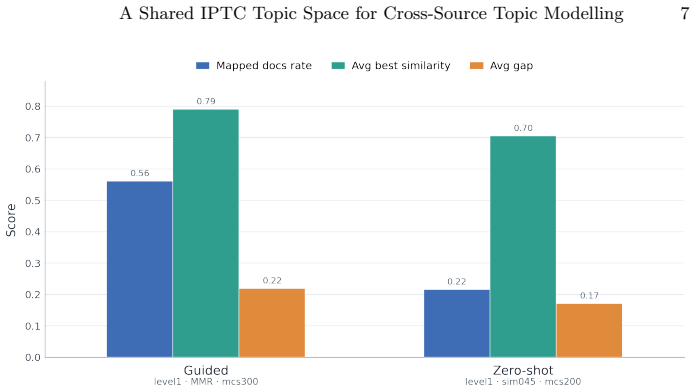
The paper claims that corpora can be placed in a single shared topic space defined by the IPTC taxonomy. Topics are obtained with guided BERTopic, scored against the ninety-four IPTC Media Topics through weighted keyword and target centroids, and collapsed upward to seventeen IPTC parent topics by a maximum-similarity rule. The framework supplies an externally anchored method that enables reproducible cross-source topic comparison.
What carries the argument
The shared IPTC topic space, which supplies fixed external labels that discovered topics from any corpus are scored against and assigned to.
If this is right
- Topics discovered in any number of separate corpora become directly comparable through their common taxonomy assignments.
- The parent-level collapse produces consistent category assignments under a range of similarity thresholds.
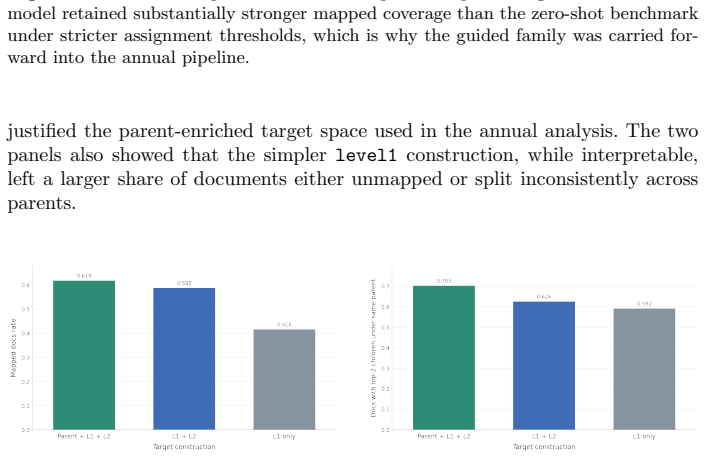
- Enriching the target construction with parent information improves both coverage and assignment stability.
- Coverage declines gradually rather than collapsing when stricter assignment thresholds are applied.
Where Pith is reading between the lines
- The same anchoring procedure could be used to compare topic attention in news sources over successive time periods without re-fitting alignment each year.
- Replacing the media taxonomy with a different domain-specific taxonomy would allow the method to be tested on scientific literature or social media.
- Running the framework on additional corpora beyond the development set would reveal whether the shared space remains stable when content types vary.
Load-bearing premise
The IPTC taxonomy supplies a sufficiently universal and stable topic space so that topics discovered independently in different corpora can be aligned to the same labels without corpus-specific distortion.
What would settle it
Apply the full mapping procedure to two separate corpora, then check whether topics assigned the same IPTC label actually address the same underlying subject when read by independent judges; systematic mismatch would falsify the alignment claim.
Figures


read the original abstract
Comparing topic attention across different media is hindered by a fundamental modelling problem: topic models fitted separately to each corpus produce corpus-specific topic spaces that cannot be aligned directly. This paper presents a reproducible framework that places corpora in a single shared topic space defined by a taxonomy. Discovered topics are obtained with guided BERTopic, scored against the ninety-four IPTC Media Topics' taxonomy topics (level-1) through weighted keyword and target centroids, and then collapsed upward to seventeen IPTC parent topics by a maximum-similarity rule. The framework was developed and selected on a controlled New York Times 2011 corpus through a narrowing sequence: a broad model screen, a focused mapping refinement, a strict finalist comparison, a target-construction ablation, and a threshold calibration. In this corpus, the guided family retained substantially stronger mapped coverage than a zero-shot benchmark under stricter assignment thresholds, a parent-enriched target construction improved both coverage and parent consistency, and coverage declined gradually rather than collapsing as the assignment threshold was tightened. The contribution is an externally anchored method for constructing a shared topic space that enables reproducible cross-source topic comparison.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a reproducible framework for aligning topics from different corpora into a single shared space anchored by the IPTC Media Topics taxonomy. Topics are discovered via guided BERTopic, scored against the 94 level-1 IPTC topics using weighted keyword and target centroids, and collapsed to 17 parent topics by a maximum-similarity rule. The method is developed and selected through a controlled sequence of broad model screening, mapping refinement, finalist comparison, target-construction ablation, and threshold calibration, all performed on the New York Times 2011 corpus; qualitative observations include stronger mapped coverage than zero-shot baselines under stricter thresholds and gradual rather than abrupt coverage decline with tightening thresholds.
Significance. If the cross-corpus stability of the IPTC-anchored mapping holds, the framework would supply an externally referenced, reproducible method for direct topic-attention comparison across media sources, addressing a recognized alignment problem in cross-corpus topic modeling. The controlled, multi-stage development process with explicit ablations and threshold tests is a methodological strength that supports reproducibility claims.
major comments (1)
- [Abstract] Abstract (development sequence paragraph): every stage of framework selection and calibration (broad screen, mapping refinement, finalist comparison, target ablation, threshold calibration) was executed exclusively on the single NYT 2011 corpus. Because the central claim is that the resulting weighted-centroid scoring and max-similarity collapse produce a corpus-independent shared space, the absence of any second corpus test leaves the cross-source alignment unverified and is load-bearing for the contribution.
minor comments (1)
- [Abstract] Abstract: improvements are stated only qualitatively (“substantially stronger mapped coverage”, “improved both coverage and parent consistency”) with no numeric values, tables, or error bars, which makes the magnitude and reliability of the reported effects difficult to evaluate.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the methodological strengths of the controlled development process. We respond to the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (development sequence paragraph): every stage of framework selection and calibration (broad screen, mapping refinement, finalist comparison, target ablation, threshold calibration) was executed exclusively on the single NYT 2011 corpus. Because the central claim is that the resulting weighted-centroid scoring and max-similarity collapse produce a corpus-independent shared space, the absence of any second corpus test leaves the cross-source alignment unverified and is load-bearing for the contribution.
Authors: We agree that all stages of model selection and calibration were performed exclusively on the NYT 2011 corpus, as already stated in the abstract. The shared topic space is defined by the external IPTC taxonomy rather than being learned from any corpus; the weighted-centroid scoring and maximum-similarity collapse rules are formulated without corpus-specific parameters and are therefore corpus-agnostic by construction. The single-corpus development sequence was deliberately chosen to enable a controlled, reproducible selection among modeling variants. At the same time, we acknowledge that empirical verification of mapping stability on at least one additional corpus would provide stronger support for the cross-source claim. We will revise the abstract and add an explicit limitations paragraph to clarify this point and to outline future multi-corpus validation. revision: yes
Circularity Check
External IPTC taxonomy anchors alignment; no self-referential reductions
full rationale
The framework maps BERTopic outputs to IPTC level-1 topics via weighted keyword/target centroids then max-similarity collapse to 17 parents. IPTC taxonomy is an independent external reference, not derived from or fitted to the NYT corpus. No equations, parameters, or predictions are shown to equal their own inputs by construction. Development steps (screening, ablation, calibration) on a single corpus constitute method tuning, not circularity. The shared space claim rests on the external taxonomy rather than self-citation chains or renamed fits.
Axiom & Free-Parameter Ledger
free parameters (2)
- assignment threshold
- weights for keyword and target centroids
axioms (1)
- domain assumption IPTC Media Topics taxonomy supplies a stable, corpus-independent topic space suitable for aligning independently discovered topics
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2008.09470 (2020)
Angelov, D.: Top2Vec: Distributed representations of topics. arXiv preprint arXiv:2008.09470 (2020)
arXiv 2008
-
[2]
Advances in neural infor- mation processing systems14(2001)
Blei, D., Ng, A., Jordan, M.: Latent Dirichlet allocation. Advances in neural infor- mation processing systems14(2001)
2001
-
[3]
In: Proceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval
Carbonell, J., Goldstein, J.: The use of mmr, diversity-based reranking for re- ordering documents and producing summaries. In: Proceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval. pp. 335–336 (1998)
1998
-
[4]
Frontiers in Sociology7, 886498 (2022)
Egger, R., Yu, J.: A topic modeling comparison between LDA, NMF, Top2Vec, and BERTopic to demystify Twitter posts. Frontiers in Sociology7, 886498 (2022)
2022
-
[5]
Nature595(7866), 214–222 (2021)
Galesic, M., Bruine de Bruin, W., Dalege, J., Feld, S.L., Kreuter, F., Olsson, H., Prelec, D., Stein, D.L., van Der Does, T.: Human social sensing is an untapped resource for computational social science. Nature595(7866), 214–222 (2021)
2021
-
[6]
arXiv preprint arXiv:2203.05794 (2022)
Grootendorst, M.: BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv preprint arXiv:2203.05794 (2022)
Pith/arXiv arXiv 2022
-
[7]
https://maartengr.github.io/BERTopic/getting started/guided/guided.html (2022), accessed: 2025-02-20
Grootendorst, M.: Guided bertopic: Using seed words to steer topic modelling. https://maartengr.github.io/BERTopic/getting started/guided/guided.html (2022), accessed: 2025-02-20
2022
-
[8]
Neurocomputing628, 129638 (2025)
Hankar, M., Kasri, M., Beni-Hssane, A.: A comprehensive overview of topic model- ing: Techniques, applications and challenges. Neurocomputing628, 129638 (2025)
2025
-
[9]
Nature401(6755), 788–791 (1999)
Lee, D.D., Seung, H.S.: Learning the parts of objects by non-negative matrix fac- torization. Nature401(6755), 788–791 (1999)
1999
-
[10]
McInnes, L., Healy, J., Astels, S.: hdbscan: Hierarchical density based clustering. J. Open Source Softw.2(11), 205 (2017). https://doi.org/10.21105/joss.00205
-
[11]
arXiv preprint arXiv:1802.03426 (2018), https://arxiv.org/abs/1802.03426
McInnes, L., Healy, J., Melville, J.: UMAP: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426 (2018), https://arxiv.org/abs/1802.03426
Pith/arXiv arXiv 2018
-
[12]
Annals of the International Communication Association44(2), 157–173 (2020)
Tsfati, Y., Boomgaarden, H.G., Str¨ omb¨ ack, J., Vliegenthart, R., Damstra, A., Lindgren, E.: Causes and consequences of mainstream media dissemination of fake news: literature review and synthesis. Annals of the International Communication Association44(2), 157–173 (2020)
2020
-
[13]
Science 359(6380), 1146–1151 (2018)
Vosoughi, S., Roy, D., Aral, S.: The spread of true and false news online. Science 359(6380), 1146–1151 (2018). https://doi.org/10.1126/science.aap9559
-
[14]
In: Clough, P., Foley, C., Gurrin, C., Jones, G.J.F., Kraaij, W., Lee, H., Mudoch, V
Zhao, W.X., Jiang, J., Weng, J., He, J., Lim, E.P., Yan, H., Li, X.: Comparing Twitter and Traditional Media Using Topic Models. In: Clough, P., Foley, C., Gurrin, C., Jones, G.J.F., Kraaij, W., Lee, H., Mudoch, V. (eds.) Advances in Information Retrieval. pp. 338–349. Springer Berlin Heidelberg, Berlin, Heidelberg (2011)
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.