PhysRAG: Enhancing Physics-Awareness in Video Generation via Retrieval-Augmented Generation
Pith reviewed 2026-06-26 05:14 UTC · model grok-4.3
The pith
PhysRAG retrieves examples from a curated 7K-video physics database to correct diffusion-model violations of physical rules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
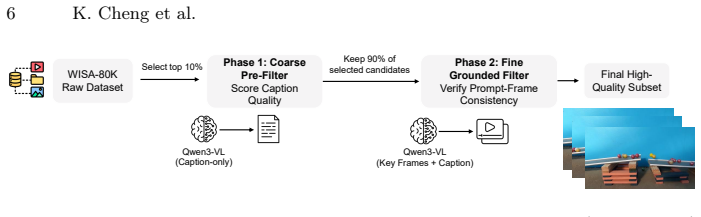
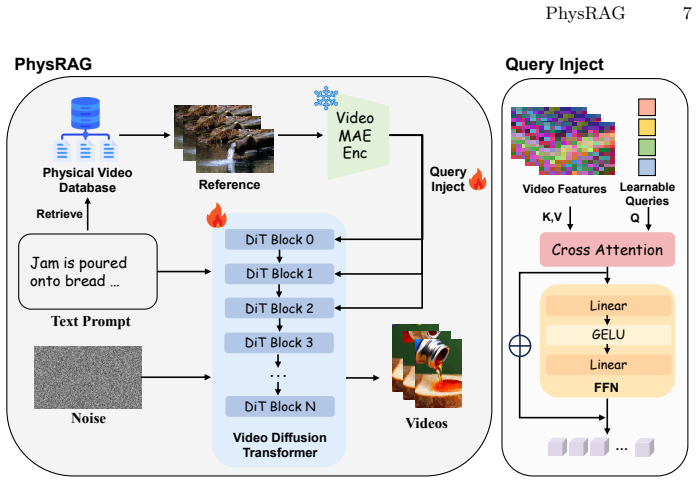
PhysRAG constructs a physical video database from a two-stage filtered subset of WISA-80K, then uses a retrieval mechanism with learnable queries to inject physical knowledge directly into a video diffusion model, producing state-of-the-art results on PhyGenBench and VBench for both visual fidelity and adherence to mechanics, optics, and thermal dynamics.
What carries the argument
The RAG pipeline that retrieves from the 7K-video physical database and injects the information via learnable queries into the diffusion process.
If this is right
- Video diffusion models can be made more physically consistent without retraining the entire network from scratch.
- A modest curated database suffices to supply the missing physical priors that large-scale web video data alone do not provide.
- Learnable queries offer a modular way to condition generation on retrieved physical examples across different motion categories.
- Ablation results indicate that both the data-filtering stage and the retrieval injection step are necessary for the reported gains.
Where Pith is reading between the lines
- The same retrieval-plus-query pattern could be tested on domains that also suffer from sparse rule-following data, such as biological motion or fluid simulation.
- If the filtered set proves biased toward certain object scales or lighting conditions, future work could add explicit diversity constraints during the second filtering stage.
- The approach leaves open whether the retrieved clips are used only at inference or could also be mixed into continued training of the base diffusion model.
Load-bearing premise
The 7K filtered videos contain physical phenomena that are both accurate and sufficiently diverse that retrieval will correct rather than reinforce model errors.
What would settle it
A controlled test in which the retrieval step is disabled and physical-compliance scores on PhyGenBench fall to or below the scores of the strongest non-RAG baseline.
Figures



read the original abstract
Developing physically aware video generation models remains a significant challenge due to the difficulty in capturing diverse physical phenomena, such as thermal dynamics, mechanics, and optics. In this work, we introduce PhysRAG, a novel pipeline that enhances physical awareness in video generation through Retrieval-Augmented Generation (RAG). To address the issue of limited high-quality data, we design a two-stage data filtering pipeline based on the WISA-80K dataset, resulting in a curated set of 7K high-quality videos for training. Furthermore, we construct a physical video database and develop a mechanism to inject physical knowledge into a video diffusion model using learnable queries. Our method achieves state-of-the-art performance in both visual quality and physical rule compliance, surpassing existing models in benchmarks such as PhyGenBench and VBench. We conduct extensive ablation studies to validate the effectiveness of our key components, including the data filtering pipeline, RAG mechanism, and method for physical information extraction. To facilitate future research, our code, data, and models are prepared for release at https://github.com/sediment1024/PhysRAG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PhysRAG, a retrieval-augmented generation pipeline for enhancing physical awareness in video diffusion models. It describes a two-stage filtering process applied to the WISA-80K dataset to produce a curated 7K-video database of purported high physical quality, constructs a physical video database, and injects physical knowledge via learnable queries into the diffusion model. The work claims state-of-the-art performance on both visual quality and physical rule compliance on PhyGenBench and VBench, supported by ablation studies on the filtering pipeline, RAG mechanism, and physical information extraction; code, data, and models are slated for release.
Significance. If the empirical gains are shown to be robust under standard controls, the approach could offer a practical route to mitigating physical hallucinations in video generation by leveraging curated retrieval rather than purely parametric learning. The planned artifact release would aid reproducibility in a field where data curation for physics compliance is often opaque.
major comments (2)
- [two-stage data filtering pipeline] The two-stage data filtering pipeline (abstract and methods): the claim that the resulting 7K videos exhibit high physical fidelity sufficient for reliable hallucination correction is unsupported by any reported metrics such as physics-engine error, expert-rated compliance on conservation laws/optics, or inter-annotator agreement. This is load-bearing because the RAG mechanism's value rests on the database improving rather than reinforcing dataset biases.
- [benchmarks and results] Results on PhyGenBench and VBench (abstract): the SOTA claim is asserted without any quantitative tables, baseline comparisons, error bars, or effect sizes in the provided text, preventing assessment of whether reported gains survive standard controls for data leakage or evaluation variance.
minor comments (2)
- [abstract] The abstract states that ablation studies validate the key components but supplies no high-level quantitative outcomes or effect sizes, which would aid immediate assessment of component importance.
- [method for physical information extraction] The number and dimension of learnable queries are described as free parameters without discussion of sensitivity or default choices.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and indicate planned revisions to improve the rigor of the claims.
read point-by-point responses
-
Referee: [two-stage data filtering pipeline] The two-stage data filtering pipeline (abstract and methods): the claim that the resulting 7K videos exhibit high physical fidelity sufficient for reliable hallucination correction is unsupported by any reported metrics such as physics-engine error, expert-rated compliance on conservation laws/optics, or inter-annotator agreement. This is load-bearing because the RAG mechanism's value rests on the database improving rather than reinforcing dataset biases.
Authors: We acknowledge that the manuscript does not report direct quantitative metrics (e.g., physics-engine error or expert-rated compliance scores with inter-annotator agreement) on the physical fidelity of the curated 7K videos. The two-stage pipeline applies automated heuristics based on WISA-80K annotations for visual quality and basic physical plausibility, and its value is supported indirectly via ablation studies showing performance gains on PhyGenBench when the filtered database is used. To strengthen the claim, we will add a new subsection with expert evaluation results on a random subset of the 7K videos, including compliance ratings for conservation laws and optics along with inter-annotator agreement statistics. revision: yes
-
Referee: [benchmarks and results] Results on PhyGenBench and VBench (abstract): the SOTA claim is asserted without any quantitative tables, baseline comparisons, error bars, or effect sizes in the provided text, preventing assessment of whether reported gains survive standard controls for data leakage or evaluation variance.
Authors: The full manuscript (Section 4 and associated tables) contains quantitative comparisons against baselines on both PhyGenBench and VBench, reporting metrics for visual quality and physical compliance. However, the current version lacks error bars from repeated runs and formal analysis of effect sizes or data leakage controls. We will revise the experimental section to include these elements, along with explicit discussion of steps taken to avoid overlap between the physical video database and benchmark evaluation prompts. revision: yes
Circularity Check
No circularity; empirical pipeline with external benchmarks only
full rationale
The paper presents an empirical pipeline: two-stage filtering of WISA-80K to 7K videos, construction of a physical video database, and injection of physical knowledge via learnable queries into a diffusion model. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. SOTA claims rest on external benchmarks (PhyGenBench, VBench) rather than any quantity defined inside the paper. The absence of mathematical structure means none of the six enumerated circularity patterns can be exhibited by quote and reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- number and dimension of learnable queries
axioms (1)
- domain assumption Existing video diffusion models can be conditioned on external retrieved features without destroying their generative capability.
Reference graph
Works this paper leans on
-
[1]
In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Men- sch, A., Millican, K., Reynolds, M., Ring, R., Rutherford, E., Cabi, S., Han, T., Gong, Z., Samangooei, S., Monteiro, M., Menick, J.L., Borgeaud, S., Brock, A., Nematzadeh, A., Sharifzadeh, S., Bińkowski, M.a., Barreira, R., Vinyals, O., Zisser- man, A., Simonyan, K.: Fla...
2022
-
[2]
arXiv preprint arXiv:2511.21631 (2025)
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
Pith/arXiv arXiv 2025
-
[3]
arXiv preprint arXiv:2503.06800 (2025)
Bansal, H., Peng, C., Bitton, Y., Goldenberg, R., Grover, A., Chang, K.W.: Videophy-2: A challenging action-centric physical commonsense evaluation in video generation. arXiv preprint arXiv:2503.06800 (2025)
arXiv 2025
-
[4]
In: SIGGRAPH Asia 2024 Conference Papers
Bar-Tal, O., Chefer, H., Tov, O., Herrmann, C., Paiss, R., Zada, S., Ephrat, A., Hur, J., Liu, G., Raj, A., et al.: Lumiere: A space-time diffusion model for video generation. In: SIGGRAPH Asia 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[5]
Advances in neural infor- mation processing systems29(2016)
Battaglia, P., Pascanu, R., Lai, M., Jimenez Rezende, D., et al.: Interaction net- works for learning about objects, relations and physics. Advances in neural infor- mation processing systems29(2016)
2016
-
[6]
arXiv preprint arXiv:2106.08261 (2021)
Bear, D.M., Wang, E., Mrowca, D., Binder, F.J., Tung, H.Y.F., Pramod, R., Hold- away, C., Tao, S., Smith, K., Sun, F.Y., et al.: Physion: Evaluating physical predic- tion from vision in humans and machines. arXiv preprint arXiv:2106.08261 (2021)
arXiv 2021
-
[7]
arXiv preprint arXiv:2410.24164 (2024)
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al.:π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164 (2024)
Pith/arXiv arXiv 2024
-
[8]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Blattmann, A., Rombach, R., Ling, H., Dockhorn, T., Kim, S.W., Fidler, S., Kreis, K.: Align your latents: High-resolution video synthesis with latent diffusion mod- els. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 22563–22575 (2023)
2023
-
[9]
Advances in Neural Information Processing Systems 35, 15309–15324 (2022)
Blattmann, A., Rombach, R., Oktay, K., Müller, J., Ommer, B.: Retrieval- augmented diffusion models. Advances in Neural Information Processing Systems 35, 15309–15324 (2022)
2022
-
[10]
OpenAI Blog1(8), 1 (2024)
Brooks, T., Peebles, B., Holmes, C., DePue, W., Guo, Y., Jing, L., Schnurr, D., Taylor, J., Luhman, T., Luhman, E., et al.: Video generation models as world simulators. OpenAI Blog1(8), 1 (2024)
2024
-
[11]
arXiv preprint arXiv:2512.24551 (2025)
Cai, Y., Li, K., Jia, M., Wang, J., Sun, J., Liang, F., Chen, W., Juefei-Xu, F., Wang, C., Thabet, A., et al.: Phygdpo: Physics-aware groupwise direct prefer- ence optimization for physically consistent text-to-video generation. arXiv preprint arXiv:2512.24551 (2025)
Pith/arXiv arXiv 2025
-
[12]
arXiv preprint arXiv:1612.00341 (2016) 18 K
Chang, M.B., Ullman, T., Torralba, A., Tenenbaum, J.B.: A compositional object- based approach to learning physical dynamics. arXiv preprint arXiv:1612.00341 (2016) 18 K. Cheng et al
Pith/arXiv arXiv 2016
-
[13]
arXiv preprint arXiv:2310.19512 (2023)
Chen, H., Xia, M., He, Y., Zhang, Y., Cun, X., Yang, S., Xing, J., Liu, Y., Chen, Q., Wang, X., et al.: Videocrafter1: Open diffusion models for high-quality video generation. arXiv preprint arXiv:2310.19512 (2023)
Pith/arXiv arXiv 2023
-
[14]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, H., Zhang, Y., Cun, X., Xia, M., Wang, X., Weng, C., Shan, Y.: Videocrafter2: Overcoming data limitations for high-quality video diffusion mod- els. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7310–7320 (2024)
2024
-
[15]
arXiv preprint arXiv:2508.10858 (2025)
Chen, H.H., Huang, H., Chen, Q., Yang, H., Lim, S.N.: Hierarchical fine-grained preference optimization for physically plausible video generation. arXiv preprint arXiv:2508.10858 (2025)
arXiv 2025
-
[16]
In: Pro- ceedings of the 2022 Conference on Empirical Methods in Natural Language Pro- cessing
Chen, W., Hu, H., Chen, X., Verga, P., Cohen, W.: Murag: Multimodal retrieval- augmented generator for open question answering over images and text. In: Pro- ceedings of the 2022 Conference on Empirical Methods in Natural Language Pro- cessing. pp. 5558–5570 (2022)
2022
-
[17]
arXiv preprint arXiv:2209.14491 (2022)
Chen, W., Hu, H., Saharia, C., Cohen, W.W.: Re-imagen: Retrieval-augmented text-to-image generator. arXiv preprint arXiv:2209.14491 (2022)
arXiv 2022
-
[18]
Douze, M., Guzhva, A., Deng, C., Johnson, J., Szilvasy, G., Mazaré, P.E., Lomeli, M., Hosseini, L., Jégou, H.: The faiss library (2025),https://arxiv.org/abs/ 2401.08281
Pith/arXiv arXiv 2025
-
[19]
arXiv preprint arXiv:2501.08453 (2025)
Fan, W., Si, C., Song, J., Yang, Z., He, Y., Zhuo, L., Huang, Z., Dong, Z., He, J., Pan, D., et al.: Vchitect-2.0: Parallel transformer for scaling up video diffusion models. arXiv preprint arXiv:2501.08453 (2025)
arXiv 2025
-
[20]
arXiv preprint arXiv:2506.09113 (2025)
Gao, Y., Guo, H., Hoang, T., Huang, W., Jiang, L., Kong, F., Li, H., Li, J., Li, L., Li, X., et al.: Seedance 1.0: Exploring the boundaries of video generation models. arXiv preprint arXiv:2506.09113 (2025)
Pith/arXiv arXiv 2025
-
[21]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Greff, K., Belletti, F., Beyer, L., Doersch, C., Du, Y., Duckworth, D., Fleet, D.J., Gnanapragasam, D., Golemo, F., Herrmann, C., et al.: Kubric: A scalable dataset generator. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3749–3761 (2022)
2022
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Guen, V.L., Thome, N.: Disentangling physical dynamics from unknown factors for unsupervised video prediction. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11474–11484 (2020)
2020
-
[23]
Hao, Y., Chen, C., Mian, A.S., Xu, C., Liu, D.: Enhancing physical plausibility in video generation by reasoning the implausibility (2025),https://arxiv.org/abs/ 2509.24702
Pith/arXiv arXiv 2025
-
[24]
arXiv preprint arXiv:2210.02303 (2022)
Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Gritsenko, A., Kingma, D.P., Poole, B., Norouzi, M., Fleet, D.J., et al.: Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303 (2022)
Pith/arXiv arXiv 2022
-
[25]
Advances in neural information processing systems35, 8633– 8646 (2022)
Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M., Fleet, D.J.: Video diffusion models. Advances in neural information processing systems35, 8633– 8646 (2022)
2022
-
[26]
arXiv preprint arXiv:2205.15868 (2022)
Hong, W., Ding, M., Zheng, W., Liu, X., Tang, J.: Cogvideo: Large-scale pretrain- ing for text-to-video generation via transformers. arXiv preprint arXiv:2205.15868 (2022)
Pith/arXiv arXiv 2022
-
[27]
Huang, Y., Lv, X., Xu, J., Yu, Z., Zhang, J., Hu, R., Feng, W., Zou, S., Xiao, H., Zhou, Z., Huang, K., Peng, Z., Xu, J., Zhao, H., Zhu, C., Yi, R., Huang, Y., Wu, D., Zhang, Y., Cheng, K., Song, C., Xue, Y., Zhang, X., Guo, L., Chen, Y., Wu, B., Yu, H., Xu, K.: Paiworld: A 3d-consistent world foundation model for robotic manipulation (2026),https://arxiv...
Pith/arXiv arXiv 2026
-
[28]
arXiv preprint arXiv:2505.11528 (2025)
Huang, Y., Zhang, J., Zou, S., Liu, X., Hu, R., Xu, K.: Ladi-wm: A latent diffusion- based world model for predictive manipulation. arXiv preprint arXiv:2505.11528 (2025)
arXiv 2025
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video gener- ative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21807–21818 (2024)
2024
-
[30]
arXiv preprint arXiv:2410.21276 (2024)
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
Pith/arXiv arXiv 2024
-
[31]
Intelligence, P., Amin, A., Aniceto, R., Balakrishna, A., Black, K., Conley, K., Connors, G., Darpinian, J., Dhabalia, K., DiCarlo, J., Driess, D., Equi, M., Es- mail, A., Fang, Y., Finn, C., Glossop, C., Godden, T., Goryachev, I., Groom, L., Hancock, H., Hausman, K., Hussein, G., Ichter, B., Jakubczak, S., Jen, R., Jones, T., Katz, B., Ke, L., Kuchi, C.,...
Pith/arXiv arXiv 2025
-
[32]
Intelligence, P., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Galliker, M.Y., Ghosh, D., Groom, L., Hausman, K., Ichter, B., Jakubczak, S., Jones, T., Ke, L., LeBlanc, D., Levine, S., Li-Bell, A., Mothukuri, M., Nair, S., Pertsch, K., Ren, A.Z., Shi, L.X., Smith, L., Springenberg, J.T., Stachow...
Pith/arXiv arXiv 2025
-
[33]
arXiv preprint arXiv:2510.13809 (2025)
Ji, S., Chen, X., Tao, X., Wan, P., Zhao, H.: Physmaster: Mastering physical representation for video generation via reinforcement learning. arXiv preprint arXiv:2510.13809 (2025)
arXiv 2025
-
[34]
arXiv preprint arXiv:2411.02385 (2024)
Kang, B.,Yue,Y.,Lu, R.,Lin, Z.,Zhao,Y., Wang, K.,Huang,G., Feng,J.: Howfar is video generation from world model: A physical law perspective. arXiv preprint arXiv:2411.02385 (2024)
Pith/arXiv arXiv 2024
-
[35]
arXiv preprint arXiv:2412.03603 (2024)
Kong, W., Tian, Q., Zhang, Z., Min, R., Dai, Z., Zhou, J., Xiong, J., Li, X., Wu, B., Zhang, J., et al.: Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603 (2024)
Pith/arXiv arXiv 2024
-
[36]
Kuaishou Technology: Kling ai: High-fidelity text-to-video generation.https:// www.kuaishou.com/kling(2024)
2024
-
[37]
Advances in neural information processing systems 33, 9459–9474 (2020)
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., et al.: Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems 33, 9459–9474 (2020)
2020
-
[38]
arXiv preprint arXiv:2503.09595 (2025)
Li, C., Michel, O., Pan, X., Liu, S., Roberts, M., Xie, S.: Pisa experiments: Explor- ing physics post-training for video diffusion models by watching stuff drop. arXiv preprint arXiv:2503.09595 (2025)
arXiv 2025
-
[39]
In: Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., Scarlett, J
Li, J., Li, D., Savarese, S., Hoi, S.: BLIP-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., Scarlett, J. (eds.) Proceedings of the 40th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 202, pp....
2023
-
[40]
IEEE Robotics and Automation Letters9(6), 6012–6019 (2024)
Liu, C., Shi, K., Zhou, K., Wang, H., Zhang, J., Dong, H.: Rgbgrasp: Image-based object grasping by capturing multiple views during robot arm movement with neural radiance fields. IEEE Robotics and Automation Letters9(6), 6012–6019 (2024)
2024
-
[41]
arXiv preprint arXiv:2501.10928 (2025)
Liu, D., Zhang, J., Dinh, A.D., Park, E., Zhang, S., Mian, A., Shah, M., Xu, C.: Generative physical ai in vision: A survey. arXiv preprint arXiv:2501.10928 (2025)
arXiv 2025
-
[42]
arXiv preprint arXiv:2501.13918 (2025)
Liu, J., Liu, G., Liang, J., Yuan, Z., Liu, X., Zheng, M., Wu, X., Wang, Q., Xia, M., Wang, X., et al.: Improving video generation with human feedback. arXiv preprint arXiv:2501.13918 (2025)
Pith/arXiv arXiv 2025
-
[43]
In: Proceedings of the Com- puter Vision and Pattern Recognition Conference
Liu, R., Wu, H., Zheng, Z., Wei, C., He, Y., Pi, R., Chen, Q.: Videodpo: Omni- preference alignment for video diffusion generation. In: Proceedings of the Com- puter Vision and Pattern Recognition Conference. pp. 8009–8019 (2025)
2025
-
[44]
arXiv preprint arXiv:2402.17177 (2024)
Liu, Y., Zhang, K., Li, Y., Yan, Z., Gao, C., Chen, R., Yuan, Z., Huang, Y., Sun, H., Gao, J., et al.: Sora: A review on background, technology, limitations, and opportunities of large vision models. arXiv preprint arXiv:2402.17177 (2024)
Pith/arXiv arXiv 2024
-
[45]
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization (2019),https: //arxiv.org/abs/1711.05101
Pith/arXiv arXiv 2019
-
[46]
Ma, G., Huang, H., Yan, K., Chen, L., Duan, N., Yin, S., Wan, C., Ming, R., Song, X., Chen, X., Zhou, Y., Sun, D., Zhou, D., Zhou, J., Tan, K., An, K., Chen, M., Ji, W., Wu, Q., Sun, W., Han, X., Wei, Y., Ge, Z., Li, A., Wang, B., Huang, B., Wang, B., Li, B., Miao, C., Xu, C., Wu, C., Yu, C., Shi, D., Hu, D., Liu, E., Yu, G., Yang, G., Huang, G., Yan, G.,...
Pith/arXiv arXiv 2025
-
[47]
arXiv preprint arXiv:2410.05363 (2024)
Meng, F., Liao, J., Tan, X., Shao, W., Lu, Q., Zhang, K., Cheng, Y., Li, D., Qiao, Y., Luo, P.: Towards world simulator: Crafting physical commonsense-based benchmark for video generation. arXiv preprint arXiv:2410.05363 (2024)
Pith/arXiv arXiv 2024
-
[48]
arXiv preprint arXiv:2502.07007 (2025)
Meng, S., Luo, Y., Liu, P.: Grounding creativity in physics: A brief survey of physical priors in aigc. arXiv preprint arXiv:2502.07007 (2025)
arXiv 2025
-
[49]
In: Proceedings of the AAAI conference on artificial intelligence
Mou, C., Wang, X., Xie, L., Wu, Y., Zhang, J., Qi, Z., Shan, Y.: T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. In: Proceedings of the AAAI conference on artificial intelligence. vol. 38, pp. 4296–4304 (2024)
2024
-
[50]
In: Proceedings of the 2025 International Conference on Multimedia Retrieval
Peruzzo, E., Xu, D., Xu, X., Shi, H., Sebe, N.: Ragme: Retrieval augmented video generation for enhanced motion realism. In: Proceedings of the 2025 International Conference on Multimedia Retrieval. p. 1081–1090. ICMR ’25, Association for Computing Machinery, New York, NY, USA (2025).https://doi.org/10.1145/ 3731715.3733417,https://doi.org/10.1145/3731715.3733417
-
[51]
Pika Labs: Pika: Text-to-video generation platform.https://pika.art(2024)
2024
-
[52]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022) PhysRAG 21
2022
-
[53]
arXiv preprint arXiv:2510.02284 (2025)
Romero, D., Bermudez, A., Li, H., Pizzati, F., Laptev, I.: Learning to generate rigid body interactions with video diffusion models. arXiv preprint arXiv:2510.02284 (2025)
arXiv 2025
-
[54]
Runway ML: Runway gen-3 alpha.https://research.runwayml.com/gen3(2024)
2024
-
[55]
arXiv preprint arXiv:2209.14792 (2022)
Singer, U., Polyak, A., Hayes, T., Yin, X., An, J., Zhang, S., Hu, Q., Yang, H., Ashual, O., Gafni, O., et al.: Make-a-video: Text-to-video generation without text- video data. arXiv preprint arXiv:2209.14792 (2022)
Pith/arXiv arXiv 2022
-
[56]
Song, S., Xu, Z., Zhang, Z., Zhou, K., Guo, J., Qin, L., Huang, B.: Learning plug- and-play memory for guiding video diffusion models (2025),https://arxiv.org/ abs/2511.19229
arXiv 2025
-
[57]
arXiv preprint arXiv:2605.23345 (2026)
Tong, Z., Lai, H., Wang, Z., Xing, Z., Cheng, K., Xu, H., Pu, Z., Zhu, S., Feng, R., Zhao, J., et al.: Scope: Simulating cross-game operations in playable environments for fps world models. arXiv preprint arXiv:2605.23345 (2026)
Pith/arXiv arXiv 2026
-
[58]
arXiv preprint arXiv:1909.13789 (2019)
Toth, P., Rezende, D.J., Jaegle, A., Racanière, S., Botev, A., Higgins, I.: Hamilto- nian generative networks. arXiv preprint arXiv:1909.13789 (2019)
arXiv 1909
-
[59]
Advances in Neural Information Processing Systems36, 67048–67068 (2023)
Tung,H.Y.,Ding,M.,Chen,Z.,Bear,D.,Gan,C.,Tenenbaum,J.,Yamins,D.,Fan, J., Smith, K.: Physion++: Evaluating physical scene understanding that requires online inference of different physical properties. Advances in Neural Information Processing Systems36, 67048–67068 (2023)
2023
-
[60]
arXiv preprint arXiv:2503.20314 (2025)
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
Pith/arXiv arXiv 2025
-
[61]
arXiv preprint arXiv:2509.20358 (2025)
Wang, C., Chen, C., Huang, Y., Dou, Z., Liu, Y., Gu, J., Liu, L.: Physctrl: Genera- tive physics for controllable and physics-grounded video generation. arXiv preprint arXiv:2509.20358 (2025)
arXiv 2025
-
[62]
arXiv preprint arXiv:2604.24575 (2026)
Wang, H., Xiang, A., Sun, H., Sun, P., Pan, C., Chen, Y., Hong, M., Wang, W., Chen, S., Chen, Y., et al.: Diffusion model as a generalist segmentation learner. arXiv preprint arXiv:2604.24575 (2026)
Pith/arXiv arXiv 2026
-
[63]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
Wang, H., Zhou, K., Gu, B., Feng, Z., Wang, W., Sun, P., Xiao, Y., Zhang, J., Dong, H.: Transdiff: Diffusion-based method for manipulating transparent objects using a single rgb-d image. In: 2025 IEEE International Conference on Robotics and Automation (ICRA). pp. 7277–7283. IEEE (2025)
2025
-
[64]
In: Proceedings of the 2024 Con- ference on Empirical Methods in Natural Language Processing
Wang, J., Wang, C., Huang, K., Huang, J., Jin, L.: Videoclip-xl: Advancing long description understanding for video clip models. In: Proceedings of the 2024 Con- ference on Empirical Methods in Natural Language Processing. pp. 16061–16075 (2024)
2024
-
[65]
arXiv preprint arXiv:2503.08153 (2025)
Wang, J., Ma, A., Cao, K., Zheng, J., Zhang, Z., Feng, J., Liu, S., Ma, Y., Cheng, B., Leng, D., et al.: Wisa: World simulator assistant for physics-aware text-to-video generation. arXiv preprint arXiv:2503.08153 (2025)
arXiv 2025
-
[66]
arXiv preprint arXiv:2308.06571 (2023)
Wang, J., Yuan, H., Chen, D., Zhang, Y., Wang, X., Zhang, S.: Modelscope text- to-video technical report. arXiv preprint arXiv:2308.06571 (2023)
Pith/arXiv arXiv 2023
-
[67]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wang, L., Huang, B., Zhao, Z., Tong, Z., He, Y., Wang, Y., Wang, Y., Qiao, Y.: Videomae v2: Scaling video masked autoencoders with dual masking. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 14549–14560 (June 2023)
2023
-
[68]
arXiv preprint arXiv:2511.03997 (2025)
Wang, P., Wang, W., Li, Q.: Physcorr: Dual-reward dpo for physics-constrained text-to-video generation with automated preference selection. arXiv preprint arXiv:2511.03997 (2025)
arXiv 2025
-
[69]
arXiv preprint arXiv:2509.19297 (2025) 22 K
Wang, W., Chen, Y., Zhang, Z., Liu, H., Wang, H., Feng, Z., Qin, W., Chen, F., Zhu, Z., Chen, D.Y., et al.: Volsplat: Rethinking feed-forward 3d gaussian splatting with voxel-aligned prediction. arXiv preprint arXiv:2509.19297 (2025) 22 K. Cheng et al
Pith/arXiv arXiv 2025
-
[70]
arXiv preprint arXiv:2604.24764 (2026)
Wang, W., He, X., Gu, Y., Yang, Y., Zhang, Z., He, Y., Ding, Y., Hu, X., Chen, D.Y., He, Z., et al.: World-r1: Reinforcing 3d constraints for text-to-video genera- tion. arXiv preprint arXiv:2604.24764 (2026)
Pith/arXiv arXiv 2026
-
[71]
In: European conference on computer vision
Wang, X., Zhu, Z., Huang, G., Chen, X., Zhu, J., Lu, J.: Drivedreamer: Towards real-world-drive world models for autonomous driving. In: European conference on computer vision. pp. 55–72. Springer (2024)
2024
-
[72]
International Journal of Computer Vision133(5), 3059–3078 (2025)
Wang, Y., Chen, X., Ma, X., Zhou, S., Huang, Z., Wang, Y., Yang, C., He, Y., Yu, J., Yang, P., et al.: Lavie: High-quality video generation with cascaded latent diffu- sion models. International Journal of Computer Vision133(5), 3059–3078 (2025)
2025
-
[73]
Advances in neural information processing systems30(2017)
Watters, N., Zoran, D., Weber, T., Battaglia, P., Pascanu, R., Tacchetti, A.: Visual interaction networks: Learning a physics simulator from video. Advances in neural information processing systems30(2017)
2017
-
[74]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wen, Y., Zhao, Y., Liu, Y., Jia, F., Wang, Y., Luo, C., Zhang, C., Wang, T., Sun, X., Zhang, X.: Panacea: Panoramic and controllable video generation for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6902–6912 (2024)
2024
-
[75]
arXiv preprint arXiv:2509.20328 (2025)
Wiedemer, T., Li, Y., Vicol, P., Gu, S.S., Matarese, N., Swersky, K., Kim, B., Jaini, P., Geirhos, R.: Video models are zero-shot learners and reasoners. arXiv preprint arXiv:2509.20328 (2025)
Pith/arXiv arXiv 2025
-
[76]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Wu, J.Z., Ge, Y., Wang, X., Lei, S.W., Gu, Y., Shi, Y., Hsu, W., Shan, Y., Qie, X., Shou, M.Z.: Tune-a-video: One-shot tuning of image diffusion models for text- to-video generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 7623–7633 (October 2023)
2023
-
[77]
arXiv preprint arXiv:2605.01896 (2026)
Xiao,J.,Liang,D.,Zhou,X.,Ye,Y.,Su,T.,Yi,G.,Xia,B.,Lyu,Q.,Shi,S.,Huang, J., et al.: Divide and conquer: Decoupled representation alignment for multimodal world models. arXiv preprint arXiv:2605.01896 (2026)
Pith/arXiv arXiv 2026
-
[78]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xue, Q., Yin, X., Yang, B., Gao, W.: Phyt2v: Llm-guided iterative self-refinement for physics-grounded text-to-video generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18826–18836 (2025)
2025
-
[79]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Yang, X., Li, B., Zhang, Y., Yin, Z., Bai, L., Ma, L., Wang, Z., Cai, J., Wong, T.T., Lu, H., et al.: Vlipp: Towards physically plausible video generation with vision and language informed physical prior. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 12360–12370 (2025)
2025
-
[80]
arXiv preprint arXiv:2408.06072 (2024)
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.