GEOALIGN: Geometric Rollout Curation for Robust LLM Reinforcement Learning
Pith reviewed 2026-06-26 04:46 UTC · model grok-4.3
The pith
Geoalign curates LLM rollouts by angular deviation from batch consensus to reduce training instability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
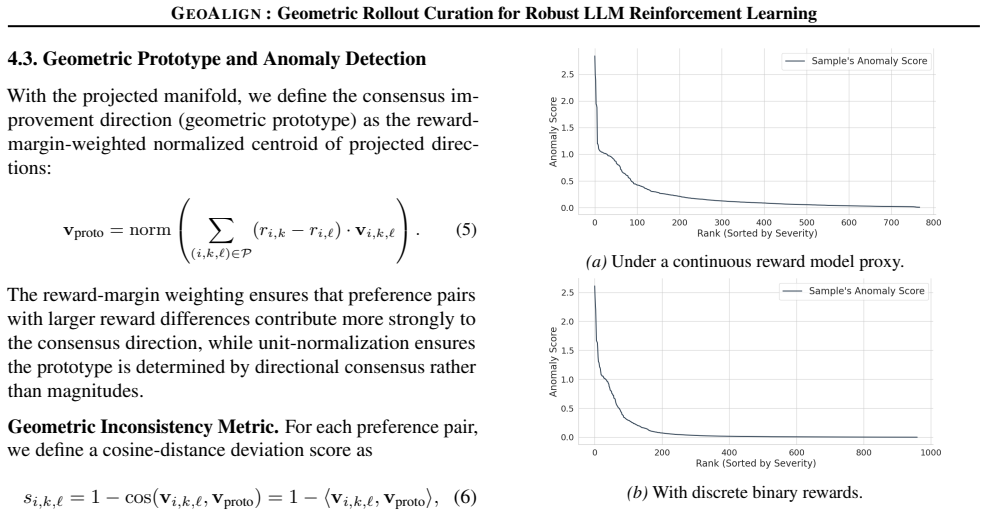
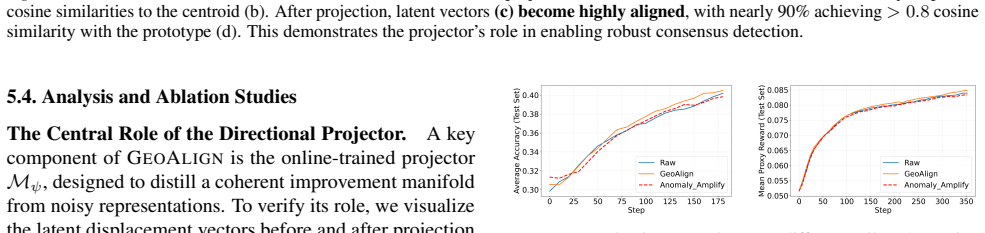
Within each batch a small set of high-reward rollouts can induce representation-space directions that sharply disagree with the majority, producing destabilizing updates; Geoalign forms within-prompt pairs, learns an online projector on hidden states to concentrate reward-ordered displacements, and replaces directionally inconsistent rollouts with within-prompt alternatives whose angle to the batch consensus prototype is smaller.
What carries the argument
The batch consensus prototype formed as the average direction in the learned projector space, used to measure angular deviation and thereby identify and replace destabilizing rollouts.
If this is right
- Final performance rises on both dialogue alignment with learned reward models and mathematical reasoning with verified binary rewards.
- Training oscillation decreases relative to standard online policy optimization.
- The method outperforms PF-PPO, PAR, PODS, and Seed-GRPO on the reported tasks.
- The curation adds negligible compute because it requires only forward passes.
Where Pith is reading between the lines
- The same geometric test might be tried in non-LLM online RL settings where batch-internal rollout quality varies.
- If the learned projector is essential, a follow-up could check whether a fixed linear projector works equally well.
- Directional consensus could be explored as a filtering signal during supervised stages that precede RL.
Load-bearing premise
Angular deviation from the batch consensus prototype in the learned projector space reliably marks rollouts that cause destabilizing updates rather than merely reflecting reward noise or prompt difficulty.
What would settle it
An experiment in which the same RL training runs are repeated with and without Geoalign curation, and the policy-update variance remains unchanged after the curation step or the flagged rollouts prove unrelated to the observed instability when isolated.
Figures










read the original abstract
Online reinforcement learning is widely used to align large language models (LLMs) with reward signals, yet training can be unstable under noisy or misspecified rewards. We identify a failure mode we call directional inconsistency: within a batch, a small set of high-reward rollouts induces representation-space preference directions that sharply disagree with the batch majority, resulting in high-variance and destabilizing updates. We propose geoalign, a lightweight plug-in for rollout curation in iterative policy optimization. Geoalign (i) forms within-prompt preference pairs, (ii) learns an online projector on per-rollout hidden states to concentrate reward-ordered displacement directions, and (iii) detects directionally inconsistent rollouts via their angular deviation from a batch consensus prototype and rectifies them with within-prompt stable alternatives. Geoalign is forward-pass only and adds negligible overhead. Across dialogue alignment with a learned reward model and mathematical reasoning with binary verified rewards, Geoalign improves final performance and reduces training oscillation, outperforming PF-PPO, PAR, PODS, and Seed-GRPO. These results suggest latent directional consensus as an effective reliability signal for online LLM RL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that online RL for LLMs suffers from 'directional inconsistency' where a minority of high-reward rollouts induce disagreeing preference directions in hidden-state space, causing high-variance updates. It proposes Geoalign as a plug-in that (i) forms within-prompt pairs, (ii) trains an online projector on hidden states to concentrate reward-ordered displacements, and (iii) culls high angular-deviation rollouts from a batch consensus prototype, replacing them with stable alternatives. Experiments on dialogue alignment (learned RM) and math reasoning (binary verified rewards) report improved final performance and reduced oscillation versus PF-PPO, PAR, PODS, and Seed-GRPO.
Significance. If the geometric filter is shown to specifically target variance-inducing directions rather than acting as a proxy for reward magnitude or prompt difficulty, the approach would supply a lightweight, forward-pass-only curation signal that could stabilize iterative LLM policy optimization across reward types without extra models or heavy computation.
major comments (2)
- [Section 3 (Method)] The core claim that angular deviation from the batch consensus prototype isolates destabilizing rollouts (rather than reward noise or prompt difficulty) lacks a derivation relating the projector angles to the policy-gradient variance term. The method description shows how the projector is fit and how deviation is measured, but provides no analysis or bound connecting the geometric test to update variance.
- [Section 4 (Experiments)] Because the projector is trained online on the same rollouts it later filters, the reported gains are compatible with simpler curation heuristics; an ablation that removes the geometric component (or replaces it with reward-based or random selection) while keeping the within-prompt pairing is needed to establish that the angular test is load-bearing.
minor comments (2)
- [Section 3] Notation for the projector and consensus prototype should be introduced with explicit equations rather than prose descriptions to allow readers to verify the forward-pass claim.
- [Abstract / Section 4] The abstract states 'negligible overhead' but the paper would benefit from a short table or sentence reporting wall-clock or FLOPs added per iteration.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and commit to revisions that strengthen the theoretical motivation and experimental validation of Geoalign.
read point-by-point responses
-
Referee: [Section 3 (Method)] The core claim that angular deviation from the batch consensus prototype isolates destabilizing rollouts (rather than reward noise or prompt difficulty) lacks a derivation relating the projector angles to the policy-gradient variance term. The method description shows how the projector is fit and how deviation is measured, but provides no analysis or bound connecting the geometric test to update variance.
Authors: We agree that the manuscript does not contain a formal derivation or bound explicitly linking angular deviation in the projected hidden-state space to the variance of the policy-gradient updates. The approach is motivated by the observation that directionally inconsistent high-reward rollouts produce opposing preference signals, which empirically manifests as training oscillation; however, this connection is currently supported only by the reported stability improvements rather than by a direct variance analysis. In the revision we will expand Section 3 with a discussion that relates the learned projector (which concentrates reward-ordered displacements) to gradient variance, including an illustrative derivation under simplified assumptions on the geometry of the hidden-state representations and how deviations from the batch consensus prototype increase the magnitude of conflicting update directions. revision: yes
-
Referee: [Section 4 (Experiments)] Because the projector is trained online on the same rollouts it later filters, the reported gains are compatible with simpler curation heuristics; an ablation that removes the geometric component (or replaces it with reward-based or random selection) while keeping the within-prompt pairing is needed to establish that the angular test is load-bearing.
Authors: We acknowledge that the current experimental section does not contain an internal ablation that retains the within-prompt pairing mechanism while replacing the angular-deviation filter with reward-magnitude or random selection. Such a control is necessary to isolate the contribution of the geometric test. We will add this ablation to Section 4 in the revised manuscript, evaluating the full Geoalign pipeline against variants that use reward-based or random replacement on both the dialogue-alignment and math-reasoning tasks, thereby demonstrating that the angular test is the load-bearing component of the observed gains in final performance and reduced oscillation. revision: yes
Circularity Check
No circularity: empirical curation method with no self-referential derivation or fitted prediction presented as first-principles result
full rationale
The paper describes an online projector learned from rollout hidden states to filter via angular deviation from batch consensus, followed by empirical gains on dialogue and math tasks. No equations, uniqueness theorems, or self-citations are shown that would reduce the claimed causal link or performance improvement to the fitting process itself by construction. The projector and filter are presented as a plug-in heuristic whose value is assessed via external benchmarks (PF-PPO, PAR, etc.), satisfying the self-contained criterion. No load-bearing step equates the geometric test to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, Y ., Jones, A., Ndousse, K., Askell, A., Chen, A., Das- Sarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., et al. Training a helpful and harmless assistant with rein- forcement learning from human feedback.arXiv preprint arXiv:2204.05862,
-
[2]
Chen, M., Chen, G., Wang, W., and Yang, Y . Seed-grpo: Semantic entropy enhanced grpo for uncertainty-aware policy optimization.arXiv preprint arXiv:2505.12346,
-
[3]
Cheng, J., Xiong, G., Qiao, R., Li, L., Guo, C., Wang, J., Lv, Y ., and Wang, F.-Y . Stop summation: Min-form credit assignment is all process reward model needs for reasoning.arXiv preprint arXiv:2504.15275, 2025a. Cheng, Z., Hao, S., Liu, T., Zhou, F., Xie, Y ., Yao, F., Bian, Y ., Zhuang, Y ., Dey, N., Zha, Y ., et al. Revisiting reinforcement learning...
-
[4]
Dao, T., Fu, D., Ermon, S., Rudra, A., and R´e, C
URL https://arxiv.org/ abs/2506.21545. Dao, T., Fu, D., Ermon, S., Rudra, A., and R´e, C. Flashat- tention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359,
-
[5]
Reward shaping to mitigate reward hacking in rlhf
Fu, J., Zhao, X., Yao, C., Wang, H., Han, Q., and Xiao, Y . Reward shaping to mitigate reward hacking in rlhf. InICML 2025 Workshop on Reliable and Responsible Foundation Models,
2025
-
[6]
Measuring math- ematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring math- ematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
-
[7]
Hu, Y ., Wu, F., Ye, H., Forsyth, D., Zou, J., Jiang, N., Ma, J. W., and Zhao, H. A snapshot of influence: A local data attribution framework for online reinforcement learning. arXiv preprint arXiv:2505.19281,
-
[8]
Regularized best-of-n sampling with minimum bayes risk objective for language model alignment
Jinnai, Y ., Morimura, T., Ariu, K., and Abe, K. Regularized best-of-n sampling with minimum bayes risk objective for language model alignment. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 9321–9347,
2025
-
[9]
Li, S., Li, S., Yang, Z., Zhang, X., Chen, G., Xia, X., Liu, H., and Peng, Z. Learnalign: Reasoning data selec- tion for reinforcement learning in large language models based on improved gradient alignment.arXiv preprint arXiv:2506.11480, 2025a. Li, X., Zou, H., and Liu, P. Limr: Less is more for rl scaling. arXiv preprint arXiv:2502.11886, 2025b. Li, Y ....
Pith/arXiv arXiv 2024
-
[10]
Pan, X., Chen, Y ., Chen, Y ., Sun, Y ., Chen, D., Zhang, W., Xie, Y ., Huang, Y ., Zhang, Y ., Gao, D., et al. Trinity-rft: A general-purpose and unified framework for reinforcement fine-tuning of large language models.arXiv preprint arXiv:2505.17826,
-
[11]
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Zhang, M., Li, Y . K., Wu, Y ., and Guo, D. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.CoRR, abs/2402.03300,
-
[12]
Shihab, I. F., Akter, S., and Sharma, A. Detecting and mitigating reward hacking in reinforcement learning sys- tems: A comprehensive empirical study.arXiv preprint arXiv:2507.05619,
-
[13]
Wang, H., Xiong, W., Xie, T., Zhao, H., and Zhang, T. Inter- pretable preferences via multi-objective reward modeling and mixture-of-experts.arXiv preprint arXiv:2406.12845,
-
[14]
E., Savani, Y ., Fang, F., and Kolter, J
Xu, Y . E., Savani, Y ., Fang, F., and Kolter, J. Z. Not all rollouts are useful: Down-sampling rollouts in llm rein- forcement learning.arXiv preprint arXiv:2504.13818,
-
[15]
Yang, A., Zhang, B., Hui, B., Gao, B., Yu, B., Li, C., Liu, D., Tu, J., Zhou, J., Lin, J., et al. Qwen2. 5-math techni- cal report: Toward mathematical expert model via self- improvement.arXiv preprint arXiv:2409.12122, 2024a. 10 GEOALIGN: Geometric Rollout Curation for Robust LLM Reinforcement Learning Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zhen...
-
[16]
Yang, R., Ding, R., Lin, Y ., Zhang, H., and Zhang, T. Reg- ularizing hidden states enables learning generalizable reward model for llms.Advances in Neural Information Processing Systems, 37:62279–62309, 2024b. Yu, Q., Zhang, Z., Zhu, R., Yuan, Y ., Zuo, X., Yue, Y ., Dai, W., Fan, T., Liu, G., Liu, L., et al. Dapo: An open-source llm reinforcement learni...
-
[17]
Policy filtration for rlhf to mitigate noise in reward models
Zhang, C., Shen, W., Zhao, L., Zhang, X., Xu, X., Dou, W., and Bian, J. Policy filtration for rlhf to mitigate noise in reward models. InForty-second International Conference on Machine Learning, 2025a. Zhang, C., Shen, W., Zhao, L., Zhang, X., Xu, X., Dou, W., and Bian, J. Policy filtration for RLHF to mitigate noise in reward models. InForty-second Inte...
-
[18]
This dataset consists of 17,398 problems, primarily from competitive mathematics, with integer-based answers
for training. This dataset consists of 17,398 problems, primarily from competitive mathematics, with integer-based answers. The verified and binary reward structure (1.0 for a correct answer, 0.0 12 GEOALIGN: Geometric Rollout Curation for Robust LLM Reinforcement Learning otherwise) provides a clear, objective signal for improving logical and computation...
2022
-
[19]
We utilize GRPO (Shao et al.,
via flash-attention (Dao et al., 2022). We utilize GRPO (Shao et al.,
2022
-
[20]
Tie" should be extremely rare. Return ONLY a JSON object: {
( 1.7B-Base and 4B-Base) undergo supervised fine-tuning (SFT) on the HH-RLHF dataset to align with the desired conversational style. Subsequently, these SFT models are further optimized using RL. The reward signal is continuous, obtained by querying an external reward modelArmoRM(Wang et al., 2024). Given the rich, continuous feedback from the reward mode...
2024
-
[21]
”Inst.” is an abbreviation for Instruct-tuned models
Table 6.Key hyperparameters for SFT and RL across different models and domains. ”Inst.” is an abbreviation for Instruct-tuned models. RLHF (SFT) RLHF (RL) Mathematics (RL) Hyperparameter 1.7B 4B 1.7B 4B 1.7B 4B Base Model Qwen3-1.7B-Base Qwen3-4B-Base SFT-tuned SFT-tuned Qwen3-1.7B-Inst. Qwen3-4B-Inst. Common Training Parameters Optimizer AdamW AdamW Adam...
2024
-
[22]
aggregates these directions across pairs, so correct but creative solutions naturally shape the consensus. Rollouts are flagged as outliers only when their implied directions contradict this collective flow, typically due to reward hacking or logical inconsistency rather than genuine novelty. To directly test whether GEOALIGNsuppresses solution diversity,...
2024
-
[23]
23.98 19.50 57.75 74.52 20.22 42.90 39.81 PF-PPO (BR) (Zhang et al., 2025a) 22.75 16.87 53.75 73.64 19.1943.50 38.28 PF-PPO (BW) (Zhang et al., 2025a) 22.83 19.38 55.37 73.40 19.41 42.31 38.78 PAR (Fu et al.,
1943
-
[24]
Qwen3-4B23.33 20.42 65.63 77.20 21.32 44.89 42.13 BASE-GRPO (Shao et al.,
23.08 17.0859.7575.16 19.93 42.49 39.58 SEED-GRPO (Chen et al., 2025)24.2519.48 59.62 74.60 19.85 42.99 40.13 GEOALIGN(Ours)24.17 21.6758.5075.28 20.4042.62 40.44 Table 14.Comparison of different methods on 4B-Math BenchmarksAIME24 AIME25 AMC23 MATH500 Minerva Olympiadbench Avg. Qwen3-4B23.33 20.42 65.63 77.20 21.32 44.89 42.13 BASE-GRPO (Shao et al.,
arXiv 2025
-
[25]
41.17 36.67 85.13 83.6826.7655.32 54.79 PF-PPO (BR) (Zhang et al., 2025a) 42.08 34.33 84.25 84.48 26.54 54.84 54.42 PF-PPO (BW) (Zhang et al., 2025a) 39.58 34.42 80.75 83.36 25.00 55.11 53.04 PAR (Fu et al.,
-
[26]
43.00 35.92 85.50 84.52 25.81 56.09 55.14 SEED-GRPO (Chen et al., 2025)44.6737.58 83.75 84.56 26.69 56.18 55.57 GEOALIGN(Ours)43.00 40.33 85.62 84.6825.3756.65 55.94 D.2. Complete Results of Overall Performance on Math We present the complete scores of Qwen3-1.7B and Qwen3-4B on HH-RLHF task in the validation experiments in Tables
arXiv 2025
-
[27]
0.8311 0.8397 0.8354 0.8562 0.8782 0.8672 + PF-PPO (BR) (Zhang et al., 2025a) 0.8630 0.8482 0.8556 0.84720.90690.8771 + PF-PPO (BW) (Zhang et al., 2025a) 0.8409 0.8383 0.8396 0.8462 0.8858 0.8660 + PAR (Fu et al.,
-
[28]
0.8330 0.8518 0.8424 0.8622 0.8864 0.8743 + GEOALIGN(Ours) 0.8806 0.8963 0.8885 0.87210.9067 0.8894 Table 16.Evaluation win-rate of different models on the HH-rlhf dataset Models Qwen3-1.7B Qwen3-4B GEOALIGNvs Baselines Win Lose Tie Win Lose Tie + BASE-GRPO (Shao et al.,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.