Language-Based Digital Twins for Elderly Cognitive Assistance
Pith reviewed 2026-06-26 04:12 UTC · model grok-4.3
The pith
Language-based digital twins using LLMs replicate elderly conversations to track cognitive health.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that incorporating stylometric cues and contextual metadata into LLMs produces digital twins that preserve identity-specific conversational characteristics, with reconstruction and MoCA prediction errors comparable to real data and superior to baseline GPT outputs on the I-CONECT dataset.
What carries the argument
The multi-head conditional variational autoencoder (cVAE) that jointly measures reconstruction quality and predicts cognitive scores.
If this is right
- The twins enable continuous personalized monitoring without repeated in-person assessments.
- Identity preservation allows simulation of individual rather than average health trajectories.
- Outperformance over generic GPT indicates value in person-specific fine-tuning for cognitive applications.
- Comparable error rates to real data support use in early detection pipelines for mild cognitive impairment.
Where Pith is reading between the lines
- Integration with longitudinal conversation logs could extend the twins toward forecasting future score changes.
- Pairing the language model output with sensor data from daily devices might create hybrid monitoring systems.
- The framework could be tested on other conversational datasets to check generalization beyond I-CONECT.
Load-bearing premise
Stylometric cues and contextual metadata can be incorporated into LLMs to produce conversational mimics whose fidelity and cognitive consistency can be reliably measured by the multi-head cVAE.
What would settle it
An experiment in which the digital twin responses show significantly higher reconstruction or MoCA prediction errors than real data or fail to preserve measurable identity-specific characteristics.
Figures

read the original abstract
Digital twins have emerged as a promising paradigm for personalized healthcare, enabling modeling of individual behavior and health trajectories. In cognitive health, early detection of Mild Cognitive Impairment (MCI) remains challenging, where language and conversational patterns serve as non-invasive biomarkers. In this work, we propose a language-based digital twin framework that leverages large language models (LLMs) to mimic the conversational behavior of elderly individuals by incorporating stylometric cues and contextual metadata. To evaluate fidelity and cognitive consistency, we introduce a multi-head conditional variational autoencoder (cVAE) that jointly measures reconstruction quality and predicts cognitive scores. Experiments on the I-CONECT dataset show that the digital twin preserves identity-specific characteristics and achieves reconstruction and MoCA prediction errors comparable to real data, while outperforming baseline GPT-generated responses. These results highlight the potential of language-based digital twins as a scalable and non-invasive approach for personalized and continuous cognitive health monitoring.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a language-based digital twin framework that uses LLMs to mimic elderly conversational behavior by incorporating stylometric cues and contextual metadata from the I-CONECT dataset. Fidelity and cognitive consistency are evaluated with a multi-head conditional variational autoencoder (cVAE) that jointly performs reconstruction and predicts MoCA scores; experiments claim the digital twin preserves identity-specific traits, matches real-data reconstruction and prediction errors, and outperforms baseline GPT generations.
Significance. If the central evaluation holds, the work could support scalable, non-invasive cognitive monitoring by combining LLMs with a learned fidelity metric. The approach is novel in its joint use of stylometry-driven generation and multi-head cVAE for identity and cognitive-score preservation, but its impact hinges on whether the cVAE metric generalizes beyond the training distribution.
major comments (2)
- [Experiments / Evaluation] Experiments section (and abstract claim): the assertion that the multi-head cVAE provides an unbiased measure of identity preservation and cognitive consistency is load-bearing for all quantitative results, yet the manuscript supplies no ablation, human correlation study, or out-of-distribution test separating metric artifact from true mimic quality. Because the cVAE is trained on the real I-CONECT distribution, any systematic difference in token statistics or predictability between LLM outputs and human speech could inflate reconstruction error without reflecting loss of identity or cognitive fidelity.
- [Experiments] Evaluation methodology: the paper reports that digital-twin outputs achieve 'comparable' reconstruction and MoCA errors to real data, but provides no statistical tests, error bars, or baseline controls that would establish whether the observed differences are significant or merely within the variance of the cVAE itself.
minor comments (1)
- The abstract and methods description should explicitly state the training/test split of the cVAE and whether any generated samples were held out from cVAE training.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. Below we provide point-by-point responses to the major comments and indicate planned revisions to the evaluation section.
read point-by-point responses
-
Referee: [Experiments / Evaluation] Experiments section (and abstract claim): the assertion that the multi-head cVAE provides an unbiased measure of identity preservation and cognitive consistency is load-bearing for all quantitative results, yet the manuscript supplies no ablation, human correlation study, or out-of-distribution test separating metric artifact from true mimic quality. Because the cVAE is trained on the real I-CONECT distribution, any systematic difference in token statistics or predictability between LLM outputs and human speech could inflate reconstruction error without reflecting loss of identity or cognitive fidelity.
Authors: We agree that the cVAE's validity as a fidelity metric requires further support. The multi-head architecture jointly optimizes reconstruction and MoCA prediction on the I-CONECT distribution to capture identity-specific and cognitive features, but we acknowledge the risk of distribution-shift artifacts. In revision we will add an ablation that evaluates the trained cVAE on held-out real speech versus LLM-generated speech and report the resulting reconstruction/MoCA errors. We will also expand the limitations section to discuss OOD generalization. A dedicated human correlation study lies outside the present scope; we will note it as future work rather than claim the current metric is fully validated by human judgment. revision: partial
-
Referee: [Experiments] Evaluation methodology: the paper reports that digital-twin outputs achieve 'comparable' reconstruction and MoCA errors to real data, but provides no statistical tests, error bars, or baseline controls that would establish whether the observed differences are significant or merely within the variance of the cVAE itself.
Authors: We will revise the experiments section to report standard deviations across multiple random seeds, include paired t-tests (or Wilcoxon tests where appropriate) comparing digital-twin versus real-data errors, and add baseline controls such as cVAE performance on randomly perturbed real utterances to quantify metric variance. These additions will allow readers to assess whether the observed comparability is statistically meaningful. revision: yes
Circularity Check
No significant circularity; evaluation metrics applied independently to generated outputs
full rationale
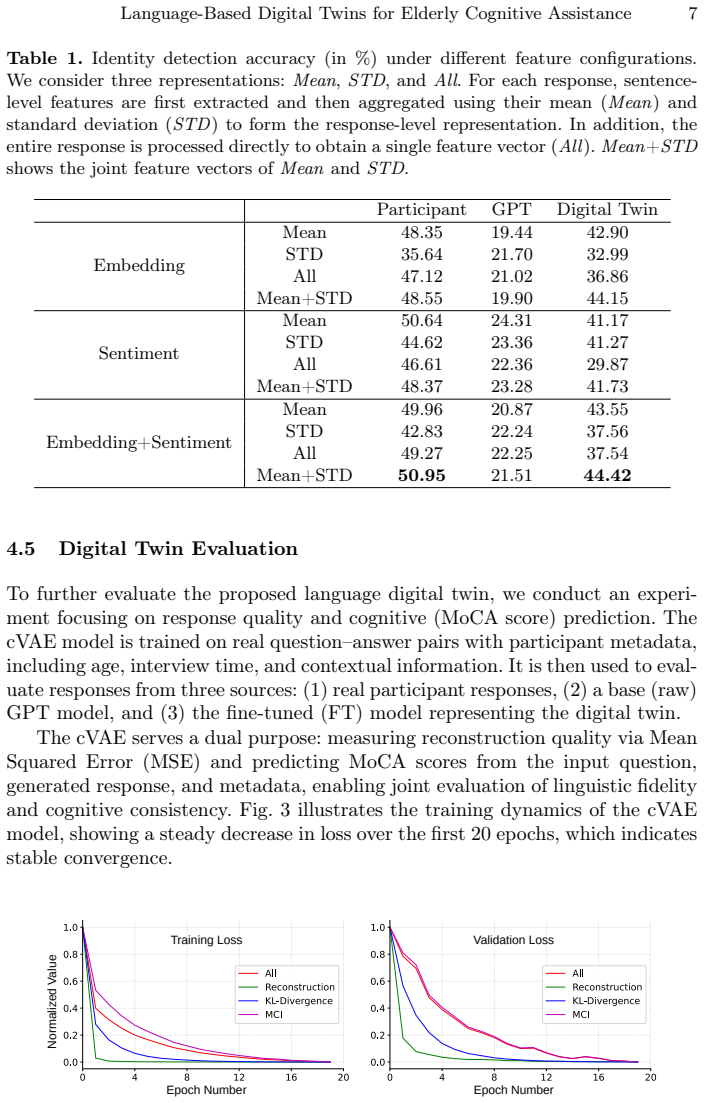
The paper describes an empirical framework that trains a multi-head cVAE on the I-CONECT real-data distribution and then applies it to measure reconstruction error and MoCA prediction on LLM-generated conversational mimics. No equations, self-citations, or derivation steps are present in the abstract or described claims that reduce the reported fidelity results to a fitted parameter renamed as a prediction or to a self-definitional loop. The central experimental claim (comparable errors to real data, outperforming GPT baselines) rests on external dataset splits and out-of-sample generation rather than on any load-bearing self-citation or ansatz smuggled from prior author work. This is the most common honest non-finding for an applied ML paper whose validity can be checked against held-out data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Archives of neurology51(6), 585–594 (1994)
Becker, J.T., Boiler, F., Lopez, O.L., Saxton, J., McGonigle, K.L.: The natural historyofalzheimer’sdisease:descriptionofstudycohortandaccuracyofdiagnosis. Archives of neurology51(6), 585–594 (1994)
1994
-
[2]
Genome medicine12(1), 4 (2019)
Björnsson, B., Borrebaeck, C., Elander, N., Gasslander, T., Gawel, D.R., Gustafs- son, M., Jörnsten, R., Lee, E.J., Li, X., Lilja, S., et al.: Digital twins to personalize medicine. Genome medicine12(1), 4 (2019)
2019
-
[3]
audio: neural building blocks for speaker diarization
Bredin, H., Yin, R., Coria, J.M., Gelly, G., Korshunov, P., Lavechin, M., Fustes, D., Titeux, H., Bouaziz, W., Gill, M.P.: Pyannote. audio: neural building blocks for speaker diarization. In: ICASSP 2020-2020 IEEE International conference on acoustics, speech and signal processing (ICASSP). pp. 7124–7128. IEEE (2020)
2020
-
[4]
European heart journal41(48), 4556–4564 (2020)
Corral-Acero, J., Margara, F., Marciniak, M., Rodero, C., Loncaric, F., Feng, Y., Gilbert, A., Fernandes, J.F., Bukhari, H.A., Wajdan, A., et al.: The ‘digital twin’to enable the vision of precision cardiology. European heart journal41(48), 4556–4564 (2020)
2020
-
[5]
The Gerontologist64(4), gnad147 (2024)
Dodge, H.H., Yu, K., Wu, C.Y., Pruitt, P.J., Asgari, M., Kaye, J.A., Hampstead, B.M., Struble, L., Potempa, K., Lichtenberg, P., et al.: Internet-based conversa- tional engagement randomized controlled clinical trial (i-conect) among socially isolated adults 75+ years old with normal cognition or mild cognitive impairment: topline results. The Gerontologi...
2024
-
[6]
Computers in Biology and Medicine176, 108606 (2024) 10 M
Fard, A.P., Mahoor, M.H., Alsuhaibani, M., Dodge, H.H.: Linguistic-based mild cognitive impairment detection using informative loss. Computers in Biology and Medicine176, 108606 (2024) 10 M. Hosseini et al
2024
-
[7]
In: ICLR 2024 Workshop on Large Language Model (LLM) Agents (2024)
Hong, J., Zheng, W., Meng, H., Liang, S., Chen, A., Dodge, H.H., Zhou, J., Wang, Z.: A-conect: Designing ai-based conversational chatbot for early dementia inter- vention. In: ICLR 2024 Workshop on Large Language Model (LLM) Agents (2024)
2024
-
[8]
Alzheimer’s & dementia14(4), 535–562 (2018)
Jack Jr, C.R., Bennett, D.A., Blennow, K., Carrillo, M.C., Dunn, B., Haeberlein, S.B., Holtzman, D.M., Jagust, W., Jessen, F., Karlawish, J., et al.: Nia-aa research framework: toward a biological definition of alzheimer’s disease. Alzheimer’s & dementia14(4), 535–562 (2018)
2018
-
[9]
Frontiers in Digital Health7, 1633539 (2025)
Khoshfekr Rudsari, H., Tseng, B., Zhu, H., Song, L., Gu, C., Roy, A., Irajizad, E., Butner, J., Long, J., Do, K.A.: Digital twins in healthcare: a comprehensive review and future directions. Frontiers in Digital Health7, 1633539 (2025)
2025
-
[10]
NPJ Digital Medicine8(1), 420 (2025)
Lammert, J., Pfarr, N., Kuligin, L., Mathes, S., Dreyer, T., Modersohn, L., Met- zger, P., Ferber, D., Kather, J.N., Truhn, D., et al.: Large language models-enabled digital twins for precision medicine in rare gynecological tumors. NPJ Digital Medicine8(1), 420 (2025)
2025
-
[11]
Communications Medicine (2025)
Lima, M.R., Capstick, A., Geranmayeh, F., Nilforooshan, R., Matarić, M., Vaidyanathan, R., Barnaghi, P.: Evaluating spoken language as a biomarker for automated screening of cognitive impairment. Communications Medicine (2025)
2025
-
[12]
Luz, S., Haider, F., De La Fuente, S., Fromm, D., MacWhinney, B.: Detecting cog- nitive decline using speech only: The adresso challenge. arxiv 2021. arXiv preprint arXiv:2104.09356
arXiv 2021
-
[13]
Luz, S., Haider, F., de la Fuente Garcia, S., Fromm, D., MacWhinney, B.: Alzheimer’s dementia recognition through spontaneous speech (2021)
2021
-
[14]
Frontiers in Psychology12, 620251 (2021)
Martínez-Nicolás, I., Llorente, T.E., Martínez-Sánchez, F., Meilán, J.J.G.: Ten years of research on automatic voice and speech analysis of people with alzheimer’s disease and mild cognitive impairment: a systematic review article. Frontiers in Psychology12, 620251 (2021)
2021
-
[15]
Digital Health11, 20552076241304078 (2025)
Nadeem, M., Kostic, S., Dornhöfer, M., Weber, C., Fathi, M.: A comprehensive review of digital twin in healthcare in the scope of simulative health-monitoring. Digital Health11, 20552076241304078 (2025)
2025
-
[16]
Journal of internal medicine 275(3), 214–228 (2014)
Petersen, R.C., Caracciolo, B., Brayne, C., Gauthier, S., Jelic, V., Fratiglioni, L.: Mild cognitive impairment: a concept in evolution. Journal of internal medicine 275(3), 214–228 (2014)
2014
-
[17]
In: International conference on machine learning
Radford,A.,Kim,J.W.,Xu,T.,Brockman,G.,McLeavey,C.,Sutskever,I.:Robust speech recognition via large-scale weak supervision. In: International conference on machine learning. pp. 28492–28518. PMLR (2023)
2023
-
[18]
In: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP)
Reimers, N., Gurevych, I.: Sentence-bert: Sentence embeddings using siamese bert- networks. In: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). pp. 3982–3992 (2019)
2019
-
[19]
arXiv preprint arXiv:1910.01108 (2019)
Sanh, V., Debut, L., Chaumond, J., Wolf, T.: Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108 (2019)
Pith/arXiv arXiv 1910
-
[20]
Advances in neural information processing systems 28(2015)
Sohn, K., Lee, H., Yan, X.: Learning structured output representation using deep conditional generative models. Advances in neural information processing systems 28(2015)
2015
-
[21]
JMIR Formative Research8, e63866 (2024)
Sprint, G., Schmitter-Edgecombe, M., Cook, D.: Building a human digital twin (hdtwin) using large language models for cognitive diagnosis: Algorithm develop- ment and validation. JMIR Formative Research8, e63866 (2024)
2024
-
[22]
npj Digital Medicine8(1), 587 (2025)
Tudor, B.H., Shargo, R., Gray, G.M., Fierstein, J.L., Kuo, F.H., Burton, R., John- son, J.T., Scully, B.B., Asante-Korang, A., Rehman, M.A., et al.: A scoping review of human digital twins in healthcare applications and usage patterns. npj Digital Medicine8(1), 587 (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.