Don't Settle at the Mode! Mitigating Diversity Collapse in Pretrained Flow Models via Feature Self-Guidance
Pith reviewed 2026-06-26 05:05 UTC · model grok-4.3
The pith
Flow models recover sample diversity by dispersing internal features during batch generation and projecting them back onto the data manifold.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
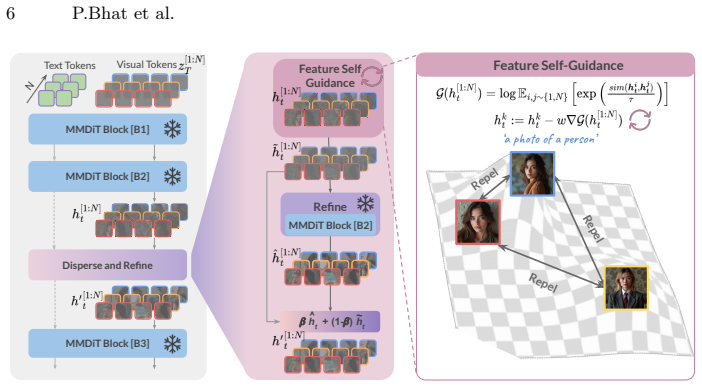
The paper claims that dispersing the internal features of a flow model during batch generation via feature self-guidance, followed by a manifold regularization step that projects the dispersed features back onto the data manifold, mitigates diversity collapse. This produces more varied outputs while preserving fidelity to the input conditions and without requiring additional reward models or training. The approach integrates as a plug-and-play module into pretrained flow models with only marginal inference overhead and shows improvements across multi-step and few-step models for text-to-image, depth-to-image, and reference image tasks.
What carries the argument
Feature self-guidance mechanism that disperses internal features in a batch, paired with manifold regularization that projects the result back onto the learned data manifold.
If this is right
- Diversity metrics improve across several conditional flow models without loss of fidelity.
- The method requires no extra reward models or retraining and adds only marginal inference cost.
- It works for both multi-step and few-step generation pipelines.
- It applies to text-to-image, depth-to-image, and reference-image conditional tasks.
Where Pith is reading between the lines
- The same dispersion-plus-projection idea might extend to other generative architectures that exhibit mode collapse.
- It could reduce dependence on post-hoc sample selection techniques that rely on external scorers.
- Varying the strength of feature dispersion per task or model layer might yield further gains in specific domains.
Load-bearing premise
Dispersing internal features and then projecting them back onto the manifold will increase output diversity while keeping fidelity and condition alignment intact.
What would settle it
Apply the method to a standard pretrained flow model and compare diversity, fidelity, and alignment metrics against ordinary sampling; if diversity metrics show no gain or fidelity drops substantially, the central claim does not hold.
Figures











read the original abstract
State-of-the-art flow models generate stunning images from text or image prompts. However, they suffer from diversity collapse when generating multiple samples under the same conditioning. Existing methods address this issue via either latent guidance, which has limited effectiveness, or sample selection, which relies on external reward models that incur significant inference-time overhead. In this work, we introduce an efficient, training-free self-guidance mechanism to mitigate diversity collapse without requiring additional reward models. Specifically, we disperse the internal features of the flow model during batch generation with feature self-guidance. Further, to keep the features close to the manifold, we introduce a manifold regularization step that projects these dispersed features back onto the data manifold, ensuring diverse generation without sacrificing alignment with the input conditions. Our method integrates seamlessly as a plug-and-play module into pretrained flow models, adding only a marginal inference cost. Experiments demonstrate significant improvements in diversity while preserving fidelity across several conditional flow models, including multi-step and few-step text-to-image, depth-to-image, and reference image generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that pretrained flow models suffer from diversity collapse under repeated conditioning, and introduces a training-free 'feature self-guidance' mechanism that disperses internal features during batch generation together with a manifold-regularization projection step that returns the dispersed features to the learned data manifold. This is asserted to increase sample diversity while preserving both fidelity and condition alignment, at only marginal extra inference cost, and to integrate as a plug-and-play module into existing multi-step and few-step conditional flow models (text-to-image, depth-to-image, reference-image). Experiments are said to demonstrate significant improvements across these settings without external reward models.
Significance. If the method and its empirical support hold, the contribution would be practically useful: an efficient, training-free, reward-model-free way to mitigate a known failure mode of flow-based generators. The plug-and-play character and low overhead distinguish it from latent-guidance or post-hoc selection baselines.
major comments (1)
- [Abstract and Method] Abstract / Method description: the central claim that 'the manifold regularization step ... projects these dispersed features back onto the data manifold, ensuring diverse generation without sacrificing alignment with the input conditions' is load-bearing yet unsupported. No explicit form of the projection operator is supplied, no analysis shows that the projected features remain on the learned manifold or preserve conditional alignment, and no quantitative conditional metrics (e.g., CLIP-score, FID conditioned on prompt, or before/after ablation) are referenced to verify the 'without sacrificing alignment' guarantee.
minor comments (1)
- [Abstract] The abstract states 'significant improvements in diversity while preserving fidelity' but supplies neither the concrete metrics, baselines, nor experimental protocol; these details should appear in the abstract or a summary table for immediate verifiability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract and Method] Abstract / Method description: the central claim that 'the manifold regularization step ... projects these dispersed features back onto the data manifold, ensuring diverse generation without sacrificing alignment with the input conditions' is load-bearing yet unsupported. No explicit form of the projection operator is supplied, no analysis shows that the projected features remain on the learned manifold or preserve conditional alignment, and no quantitative conditional metrics (e.g., CLIP-score, FID conditioned on prompt, or before/after ablation) are referenced to verify the 'without sacrificing alignment' guarantee.
Authors: We agree that the claim regarding the manifold regularization step is central to the contribution and that the current manuscript provides insufficient support for it. The abstract and method description state the intended effect but do not supply an explicit mathematical form for the projection operator, nor do they include a dedicated analysis or before/after quantitative metrics (such as CLIP-score or conditioned FID) to verify preservation of conditional alignment. We will revise the method section to include the explicit definition of the operator, add a short analysis of its effect on the learned manifold, and incorporate the requested quantitative conditional metrics and ablations in the experiments. revision: yes
Circularity Check
No circularity: method is introduced as new plug-and-play components without reduction to fitted inputs or self-citations.
full rationale
The paper presents feature self-guidance and manifold regularization as newly introduced mechanisms for dispersing features and projecting back to the manifold. The abstract and description contain no equations, no fitted parameters renamed as predictions, and no load-bearing self-citations or uniqueness theorems that reduce the central claim to prior inputs by construction. The approach is described as training-free and plug-and-play, with claimed benefits supported by experiments rather than any self-referential derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alaluf, Y., Richardson, E., Metzer, G., Cohen-Or, D.: A neural space-time repre- sentationfortext-to-imagepersonalization.ACMTransactionsonGraphics(TOG) 42(6), 1–10 (2023)
2023
-
[2]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Avrahami, O., Patashnik, O., Fried, O., Nemchinov, E., Aberman, K., Lischin- ski, D., Cohen-Or, D.: Stable flow: Vital layers for training-free image editing. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 7877–7888 (2025)
2025
-
[3]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Bansal, A., Chu, H.M., Schwarzschild, A., Sengupta, S., Goldblum, M., Geiping, J., Goldstein, T.: Universal guidance for diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 843–852 (2023)
2023
-
[4]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025),https: //openreview.net/forum?id=RjN1LYymST
Berrada, T., Romero-Soriano, A., Drozdzal, M., Verbeek, J., Alahari, K.: En- tropy rectifying guidance for diffusion and flow models. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025),https: //openreview.net/forum?id=RjN1LYymST
2025
-
[5]
In: Proceedings of the IEEE/CVF international conference on computer vision
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9650–9660 (2021)
2021
-
[6]
arXiv preprint arXiv:2310.13102 (2023)
Corso, G., Xu, Y., De Bortoli, V., Barzilay, R., Jaakkola, T.: Particle guidance: non-iid diverse sampling with diffusion models. arXiv preprint arXiv:2310.13102 (2023)
arXiv 2023
-
[7]
Advances in neural information processing systems34, 8780–8794 (2021)
Dhariwal, P., Nichol, A.: Diffusion models beat gans on image synthesis. Advances in neural information processing systems34, 8780–8794 (2021)
2021
-
[8]
Transformer Circuits Thread (2021), https://transformer-circuits.pub/2021/framework/index.html
Elhage, N., Nanda, N., Olsson, C., Henighan, T., Joseph, N., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., DasSarma, N., Drain, D., Ganguli, D., Hatfield- Dodds, Z., Hernandez, D., Jones, A., Kernion, J., Lovitt, L., Ndousse, K., Amodei, D., Brown, T., Clark, J., Kaplan, J., McCandlish, S., Olah, C.: A mathemat- ical framework for transformer circ...
2021
-
[9]
Advances in Neural Information Processing Systems 36, 16222–16239 (2023)
Epstein, D., Jabri, A., Poole, B., Efros, A., Holynski, A.: Diffusion self-guidance for controllable image generation. Advances in Neural Information Processing Systems 36, 16222–16239 (2023)
2023
-
[10]
In: Forty-first international conference on machine learning (2024) Don’t Settle at the Mode! 17
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024) Don’t Settle at the Mode! 17
2024
-
[11]
Eyring, L., Karthik, S., Dosovitskiy, A., Ruiz, N., Akata, Z.: Noise hypernetworks: Amortizingtest-timecomputeindiffusionmodels.arXivpreprintarXiv:2508.09968 (2025)
arXiv 2025
-
[12]
Advances in Neural Information Processing Systems37, 125487–125519 (2024)
Eyring, L., Karthik, S., Roth, K., Dosovitskiy, A., Akata, Z.: Reno: Enhancing one-step text-to-image models through reward-based noise optimization. Advances in Neural Information Processing Systems37, 125487–125519 (2024)
2024
-
[13]
arXiv preprint arXiv:2210.02410 (2022)
Friedman, D., Dieng, A.B.: The vendi score: A diversity evaluation metric for machine learning. arXiv preprint arXiv:2210.02410 (2022)
arXiv 2022
-
[14]
arXiv preprint arXiv:2306.09344 (2023)
Fu,S.,Tamir,N.,Sundaram,S.,Chai,L.,Zhang,R.,Dekel,T.,Isola,P.:Dreamsim: Learning new dimensions of human visual similarity using synthetic data. arXiv preprint arXiv:2306.09344 (2023)
Pith/arXiv arXiv 2023
-
[15]
Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A.H., Chechik, G., Cohen-Or, D.: An image is worth one word: Personalizing text-to-image genera- tionusingtextualinversion.In:TheEleventhInternationalConferenceonLearning Representations (2023),https://openreview.net/forum?id=NAQvF08TcyG
2023
-
[16]
ACM Transactions on Graphics (TOG)42(4), 1–13 (2023)
Gal, R., Arar, M., Atzmon, Y., Bermano, A.H., Chechik, G., Cohen-Or, D.: Encoder-based domain tuning for fast personalization of text-to-image models. ACM Transactions on Graphics (TOG)42(4), 1–13 (2023)
2023
-
[17]
Advances in Neural Information Processing Systems36, 52132–52152 (2023)
Ghosh, D., Hajishirzi, H., Schmidt, L.: Geneval: An object-focused framework for evaluating text-to-image alignment. Advances in Neural Information Processing Systems36, 52132–52152 (2023)
2023
-
[18]
arXiv preprint arXiv:2601.00090 (2025)
Harrington, A., Koepke, A., Karthik, S., Darrell, T., Efros, A.A.: It’s never too late: Noise optimization for collapse recovery in trained diffusion models. arXiv preprint arXiv:2601.00090 (2025)
Pith/arXiv arXiv 2025
-
[19]
In: Proceedings of the 2021 conference on empirical methods in natural language processing
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., Choi, Y.: Clipscore: A reference- free evaluation metric for image captioning. In: Proceedings of the 2021 conference on empirical methods in natural language processing. pp. 7514–7528 (2021)
2021
-
[20]
Advances in neural information processing systems30(2017)
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017)
2017
-
[21]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[22]
arXiv preprint arXiv:2207.12598 (2022)
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022)
Pith/arXiv arXiv 2022
-
[23]
arXiv preprint arXiv:2403.05135 (2024)
Hu, X., Wang, R., Fang, Y., Fu, B., Cheng, P., Yu, G.: Ella: Equip diffusion models with llm for enhanced semantic alignment. arXiv preprint arXiv:2403.05135 (2024)
Pith/arXiv arXiv 2024
-
[24]
arXiv preprint arXiv:2506.10173 (2025), https://arxiv.org/abs/2506.10173
Jalali, M., Lei, H., Gohari, A., Farnia, F.: Sparke: Scalable prompt-aware diversity guidance in diffusion models via rke score. arXiv preprint arXiv:2506.10173 (2025), https://arxiv.org/abs/2506.10173
arXiv 2025
-
[25]
arXiv preprint arXiv:1710.10196 (2017)
Karras, T., Aila, T., Laine, S., Lehtinen, J.: Progressive growing of gans for im- proved quality, stability, and variation. arXiv preprint arXiv:1710.10196 (2017)
Pith/arXiv arXiv 2017
-
[26]
arXiv preprint arXiv:2511.20647 (2025)
Kazimi, T., Dunlop, C., Yanardag, P.: Diverse video generation with determinantal point process-guided policy optimization. arXiv preprint arXiv:2511.20647 (2025)
arXiv 2025
-
[27]
In: Proceedings of the IEEE/CVF International ConferenceonComputerVision(ICCV)Workshops.pp.6506–6516(October2025)
Khan, M.A.H., Jain, Y., Bhattacharyya, S., Vineet, V.: Test-time prompt refine- ment for text-to-image models. In: Proceedings of the IEEE/CVF International ConferenceonComputerVision(ICCV)Workshops.pp.6506–6516(October2025)
-
[28]
arXiv preprint arXiv:2510.03813 (2025)
Kim, B., Um, S., Ye, J.C.: Diverse text-to-image generation via contrastive noise optimization. arXiv preprint arXiv:2510.03813 (2025)
arXiv 2025
-
[29]
arXiv preprint arXiv:2503.19385 (2025) 18 P.Bhat et al
Kim, J., Yoon, T., Hwang, J., Sung, M.: Inference-time scaling for flow models via stochastic generation and rollover budget forcing. arXiv preprint arXiv:2503.19385 (2025) 18 P.Bhat et al
arXiv 2025
-
[30]
arXiv preprint arXiv:2410.06025 (2024)
Kirchhof, M., Thornton, J., Béthune, L., Ablin, P., Ndiaye, E., Cuturi, M.: Shielded diffusion: Generating novel and diverse images using sparse repellency. arXiv preprint arXiv:2410.06025 (2024)
arXiv 2024
-
[31]
Advances in neural information processing systems36, 36652–36663 (2023)
Kirstain,Y.,Polyak,A.,Singer,U.,Matiana,S.,Penna,J.,Levy,O.:Pick-a-pic:An open dataset of user preferences for text-to-image generation. Advances in neural information processing systems36, 36652–36663 (2023)
2023
-
[32]
arXiv preprint arXiv:2210.10960 (2022)
Kwon, M., Jeong, J., Uh, Y.: Diffusion models already have a semantic latent space. arXiv preprint arXiv:2210.10960 (2022)
arXiv 2022
-
[33]
Advances in Neural Information Processing Systems37, 122458– 122483 (2024)
Kynkäänniemi, T., Aittala, M., Karras, T., Laine, S., Aila, T., Lehtinen, J.: Ap- plying guidance in a limited interval improves sample and distribution quality in diffusion models. Advances in Neural Information Processing Systems37, 122458– 122483 (2024)
2024
-
[34]
Labs, B.F.: Flux.https://github.com/black-forest-labs/flux(2024)
2024
-
[35]
Labs, B.F.: FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2 (2025)
2025
-
[36]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
2014
-
[37]
arXiv preprint arXiv:2210.02747 (2022)
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
Pith/arXiv arXiv 2022
-
[38]
arXiv preprint arXiv:2209.03003 (2022)
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022)
Pith/arXiv arXiv 2022
-
[39]
In: Proceedings of International Conference on Computer Vision (ICCV) (December 2015)
Liu, Z., Luo, P., Wang, X., Tang, X.: Deep learning face attributes in the wild. In: Proceedings of International Conference on Computer Vision (ICCV) (December 2015)
2015
-
[40]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Luo, G., Granskog, J., Holynski, A., Darrell, T.: Dual-process image generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17972–17983 (2025)
2025
-
[41]
arXiv preprint arXiv:2501.09732 (2025)
Ma, N., Tong, S., Jia, H., Hu, H., Su, Y.C., Zhang, M., Yang, X., Li, Y., Jaakkola, T., Jia, X., et al.: Inference-time scaling for diffusion models beyond scaling de- noising steps. arXiv preprint arXiv:2501.09732 (2025)
Pith/arXiv arXiv 2025
-
[42]
arXiv preprint arXiv:2304.07193 (2023)
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
Pith/arXiv arXiv 2023
-
[43]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Parihar, R., Bhat, A., Basu, A., Mallick, S., Kundu, J.N., Babu, R.V.: Balanc- ing act: Distribution-guided debiasing in diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6668–6678 (2024)
2024
-
[44]
arXiv preprint arXiv:2508.15773 (2025)
Parmar, G., Patashnik, O., Ostashev, D., Wang, K.C., Aberman, K., Narasimhan, S., Zhu, J.Y.: Scaling group inference for diverse and high-quality generation. arXiv preprint arXiv:2508.15773 (2025)
arXiv 2025
-
[45]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Parmar, G., Zhang, R., Zhu, J.Y.: On aliased resizing and surprising subtleties in gan evaluation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11410–11420 (2022)
2022
-
[46]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Pizzi, E., Roy, S.D., Ravindra, S.N., Goyal, P., Douze, M.: A self-supervised de- scriptor for image copy detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14532–14542 (2022)
2022
-
[47]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) Don’t Settle at the Mode! 19
2021
-
[48]
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., Aberman, K.: Dream- booth:Finetuningtext-to-imagediffusionmodelsforsubject-drivengeneration.In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 22500–22510 (2023)
2023
-
[49]
arXiv preprint arXiv:2310.17347 (2023)
Sadat, S., Buhmann, J., Bradley, D., Hilliges, O., Weber, R.M.: Cads: Unleash- ing the diversity of diffusion models through condition-annealed sampling. arXiv preprint arXiv:2310.17347 (2023)
arXiv 2023
-
[50]
Singh, J., Leng, X., Wu, Z., Zheng, L., Zhang, R., Shechtman, E., Xie, S.: What matters for representation alignment: Global information or spatial structure? arXiv preprint arXiv:2512.10794 (2025)
arXiv 2025
-
[51]
arXiv preprint arXiv:2408.03314 (2024)
Snell, C., Lee, J., Xu, K., Kumar, A.: Scaling llm test-time compute optimally can be more effective than scaling model parameters. arXiv preprint arXiv:2408.03314 (2024)
Pith/arXiv arXiv 2024
-
[52]
arXiv preprint arXiv:2010.02502 (2020)
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020)
Pith/arXiv arXiv 2010
-
[53]
arXiv preprint arXiv:2011.13456 (2020)
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 (2020)
Pith/arXiv arXiv 2011
-
[54]
arXiv preprint arXiv:2405.18881 (2024)
Tang, Z., Peng, J., Tang, J., Hong, M., Wang, F., Chang, T.H.: Inference- time alignment of diffusion models with direct noise optimization. arXiv preprint arXiv:2405.18881 (2024)
arXiv 2024
-
[55]
arXiv preprint arXiv:2601.16208 (2026)
Tong, S., Zheng, B., Wang, Z., Tang, B., Ma, N., Brown, E., Yang, J., Fergus, R., LeCun,Y.,Xie,S.:Scalingtext-to-imagediffusiontransformerswithrepresentation autoencoders. arXiv preprint arXiv:2601.16208 (2026)
arXiv 2026
-
[56]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Um, S., Ye, J.C.: Minority-focused text-to-image generation via prompt optimiza- tion. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 20926–20936 (2025)
2025
-
[57]
In: ACM SIGGRAPH 2023 conference proceedings
Voynov, A., Aberman, K., Cohen-Or, D.: Sketch-guided text-to-image diffusion models. In: ACM SIGGRAPH 2023 conference proceedings. pp. 1–11 (2023)
2023
-
[58]
arXiv preprint arXiv:2506.09027 (2025)
Wang, R., He, K.: Diffuse and disperse: Image generation with representation reg- ularization. arXiv preprint arXiv:2506.09027 (2025)
arXiv 2025
-
[59]
Advances in neural information processing systems35, 24824–24837 (2022)
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems35, 24824–24837 (2022)
2022
-
[60]
arXiv preprint arXiv:2508.02324 (2025)
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025)
Pith/arXiv arXiv 2025
-
[61]
arXiv preprint arXiv:2306.09341 (2023)
Wu, X., Hao, Y., Sun, K., Chen, Y., Zhu, F., Zhao, R., Li, H.: Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341 (2023)
Pith/arXiv arXiv 2023
-
[62]
arXiv preprint arXiv:2501.18427 (2025)
Xie,E.,Chen,J.,Zhao,Y.,Yu,J.,Zhu,L.,Wu,C.,Lin,Y.,Zhang,Z.,Li,M.,Chen, J., et al.: Sana 1.5: Efficient scaling of training-time and inference-time compute in linear diffusion transformer. arXiv preprint arXiv:2501.18427 (2025)
arXiv 2025
-
[63]
Advances in Neural Information Processing Systems37, 21875–21911 (2024)
Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., Zhao, H.: Depth anything v2. Advances in Neural Information Processing Systems37, 21875–21911 (2024)
2024
-
[64]
arXiv preprint arXiv:2410.06940 (2024)
Yu, S., Kwak, S., Jang, H., Jeong, J., Huang, J., Shin, J., Xie, S.: Representation alignment for generation: Training diffusion transformers is easier than you think. arXiv preprint arXiv:2410.06940 (2024)
Pith/arXiv arXiv 2024
-
[65]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yun, T., Zhang, D., Park, J., Pan, L.: Learning to sample effective and diverse prompts for text-to-image generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 23625–23635 (2025) 20 P.Bhat et al
2025
-
[66]
In: The Thirteenth International Conference on Learning Representations (2025)
Zhao, B.N., Xiao, Y., Xu, J., Jiang, X., Yang, Y., Li, D., Itti, L., Vineet, V., Ge, Y.: Dreamdistribution: Learning prompt distribution for diverse in-distribution gen- eration. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[67]
arXiv preprint arXiv:2510.11690 (2025)
Zheng, B., Ma, N., Tong, S., Xie, S.: Diffusion transformers with representation autoencoders. arXiv preprint arXiv:2510.11690 (2025)
Pith/arXiv arXiv 2025
-
[68]
arXiv preprint arXiv:2512.24176 (2025)
Zhou, X., Li, Q., Hu, X., Chen, H., Gu, S.: Guiding a diffusion transformer with the internal dynamics of itself. arXiv preprint arXiv:2512.24176 (2025)
arXiv 2025
-
[69]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Zhuo, L., Zhao, L., Paul, S., Liao, Y., Zhang, R., Xin, Y., Gao, P., Elhoseiny, M., Li, H.: From reflection to perfection: Scaling inference-time optimization for text- to-image diffusion models via reflection tuning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 15329–15339 (October 2025) Don’t Settle at the Mode...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.