Scene and Human in One World: Reconstruction in a Feedforward Pass
Pith reviewed 2026-06-29 04:44 UTC · model grok-4.3
The pith
SHOW unifies monocular scene reconstruction and human mesh recovery by letting each supply the scale and alignment the other lacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
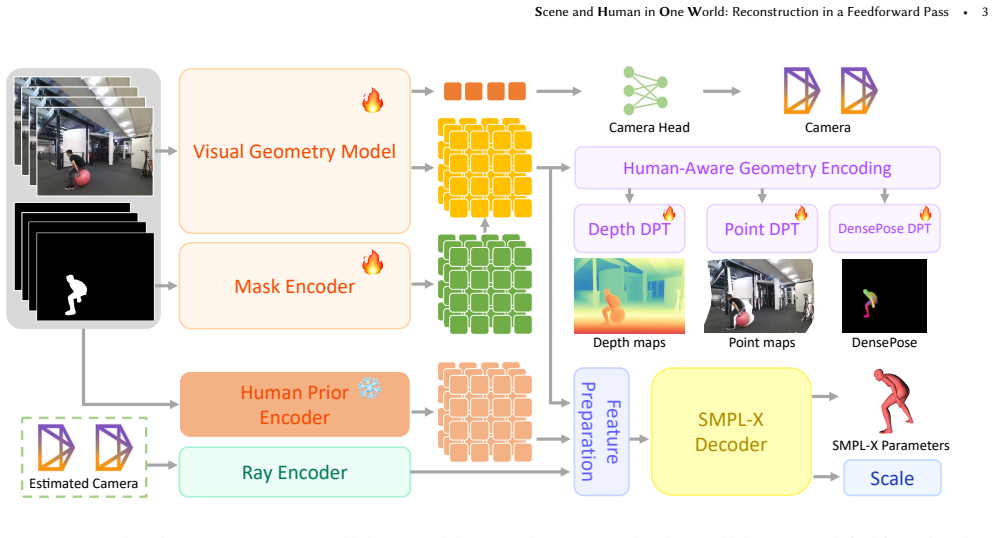
SHOW couples feed-forward 3D scene reconstruction with Human Mesh Recovery in a unified metric space. It injects human semantics and scale priors from parametric human models into normalized point-map prediction, enabling metric-scale scene reconstruction from monocular input. In turn the recovered scene geometry constrains human mesh estimation, encouraging spatially consistent human placement and improved human-scene alignment. A promptable masking mechanism handles complex multi-person and cluttered scenes by allowing flexible target selection while suppressing background and occlusion interference. Joint training produces both human-aware geometric features and geometry-constrained human
What carries the argument
SHOW, the mask-promptable framework that injects human semantics and scale priors into normalized point-map prediction while using recovered scene geometry to constrain human meshes.
If this is right
- Metric-scale scene reconstruction becomes possible from inherently scale-ambiguous monocular input.
- Human mesh estimation gains spatial consistency and improved alignment through scene-geometry constraints.
- Promptable masking enables flexible target-human selection in multi-person scenes while reducing occlusion interference.
- Joint training produces human-aware geometric features and geometry-constrained human features that support aligned output.
Where Pith is reading between the lines
- The mutual constraint could reduce reliance on post-hoc alignment steps in video-based 3D pipelines.
- If the coupling holds, the method may support downstream tasks such as navigation that need humans and environment in one consistent metric frame.
- Testing the same joint-training pattern on other parametric object classes would show whether the scale-and-alignment exchange generalizes beyond humans.
Load-bearing premise
Parametric human models supply reliable semantic structure and metric-scale priors that can be injected into point-map prediction without introducing systematic bias or instability during joint training on complex multi-person scenes.
What would settle it
Ablating the human-prior injection on monocular videos that have independent ground-truth metric scales and observing whether scene point maps retain correct scale and whether human placements lose alignment with the environment.
Figures







read the original abstract
Reconstructing humans in dynamic scenes from moving monocular cameras remains challenging due to scale ambiguity, human-scene misalignment, and occlusion interference. Rather than treating human mesh recovery and scene reconstruction as separate tasks, we believe that accurate human-scene reconstruction requires the two tasks to mutually inform each other: parametric human models offer semantic structure and metric-scale priors, while scene geometry provides spatial context for human localization and alignment. Built on this insight, we introduce SHOW, a mask-promptable human mesh recovery framework that couples feed-forward 3D scene reconstruction with Human Mesh Recovery in a unified metric space. SHOW injects human semantics and scale priors from parametric human models into normalized point-map prediction, enabling metric-scale scene reconstruction from inherently scale-ambiguous monocular input. In turn, the recovered scene geometry constrains human mesh estimation, encouraging spatially consistent human placement and improved human-scene alignment. To handle complex multi-person and cluttered scenes, SHOW further incorporates a promptable masking mechanism that enables flexible target-human selection while suppressing background distractions and occlusion interference. Through joint training, the model learns both human-aware geometric features and geometry-constrained human features, producing aligned metric-scale reconstructions from monocular human-centric videos. Extensive experiments demonstrate that SHOW improves metric-scale consistency, human-scene alignment, and reconstruction accuracy under challenging camera motion, occlusion, and cluttered backgrounds.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SHOW, a mask-promptable framework that couples feed-forward 3D scene reconstruction with human mesh recovery in a unified metric space from monocular human-centric videos. Parametric human models supply semantic structure and scale priors that are injected into normalized point-map prediction to resolve scale ambiguity, while recovered scene geometry in turn constrains human mesh estimation for spatial consistency and alignment. A promptable masking mechanism handles target selection in multi-person and cluttered scenes, with joint training claimed to yield aligned human-aware geometric features and improved reconstruction accuracy under occlusion and camera motion.
Significance. If the mutual constraint mechanism proves stable, the work could meaningfully advance monocular 3D reconstruction by achieving metric scale and human-scene alignment without multi-view input or external depth sensors. The feed-forward design and promptable masking address practical challenges in dynamic scenes. No machine-checked proofs, parameter-free derivations, or open reproducible code are mentioned.
major comments (2)
- [Method] Method section: the description of the injection operator that fuses human semantics and scale priors from parametric models (e.g., SMPL) into normalized point-map prediction is absent, preventing assessment of whether this step supplies absolute scale without systematic bias or instability during joint training on occluded multi-person data.
- [Experiments] Experiments section: no ablation results, loss-weighting details, regularization terms, or quantitative metrics (e.g., scale error, alignment error, or stability under noisy initial human fits) are provided to verify that the mutual constraint remains stable when the human branch is trained jointly with the geometry branch.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments on our manuscript. We address each major comment below and outline the revisions we will make to improve clarity and completeness.
read point-by-point responses
-
Referee: [Method] Method section: the description of the injection operator that fuses human semantics and scale priors from parametric models (e.g., SMPL) into normalized point-map prediction is absent, preventing assessment of whether this step supplies absolute scale without systematic bias or instability during joint training on occluded multi-person data.
Authors: We agree that the method section lacks a sufficiently explicit description of the injection operator. In the revised manuscript we will add a dedicated subsection that formally defines the operator, specifies how SMPL-derived semantics and scale priors are fused into the normalized point-map prediction, and discusses its design choices with respect to scale consistency and training stability on occluded multi-person scenes. revision: yes
-
Referee: [Experiments] Experiments section: no ablation results, loss-weighting details, regularization terms, or quantitative metrics (e.g., scale error, alignment error, or stability under noisy initial human fits) are provided to verify that the mutual constraint remains stable when the human branch is trained jointly with the geometry branch.
Authors: We acknowledge that the current experiments section does not include the requested ablations, loss-weighting schedules, regularization details, or quantitative stability metrics. In the revision we will add these elements, including ablation tables on loss weights and regularization, plus reported scale and alignment errors together with results under noisy initial human fits to demonstrate stability of the joint training procedure. revision: yes
Circularity Check
No circularity; architectural design is self-contained.
full rationale
The paper presents SHOW as an architectural integration of feed-forward scene reconstruction and human mesh recovery, with human priors injected into point-map prediction and scene geometry used to constrain meshes. This is framed as a joint training design choice with promptable masking, not as any derived quantity, fitted parameter, or prediction that reduces by construction to its own inputs. No equations, self-citations, or uniqueness theorems are invoked in the provided text to force the result; the claims rest on empirical outcomes of the proposed model rather than definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Parametric human models provide reliable semantic structure and metric-scale priors suitable for injection into normalized point-map prediction
Reference graph
Works this paper leans on
-
[1]
Proceedings of the European Conference on Computer Vision (ECCV) , year =
Yufu Wang and Ziyun Wang and Lingjie Liu and Kostas Daniilidis , title =. Proceedings of the European Conference on Computer Vision (ECCV) , year =
-
[2]
Computer Vision and Pattern Recognition (CVPR) , year=
WHAM: Reconstructing World-grounded Humans with Accurate 3D Motion , author=. Computer Vision and Pattern Recognition (CVPR) , year=
-
[3]
Humans in 4
Goel, Shubham and Pavlakos, Georgios and Rajasegaran, Jathushan and Kanazawa*, Angjoo and Malik*, Jitendra , booktitle=. Humans in 4
-
[4]
Computer Vision and Pattern Recognition (CVPR) , year=
End-to-end Recovery of Human Shape and Pose , author =. Computer Vision and Pattern Recognition (CVPR) , year=
-
[5]
Computer Vision and Pattern Recognition (CVPR) , year=
Learning 3D Human Dynamics from Video , author =. Computer Vision and Pattern Recognition (CVPR) , year=
-
[6]
The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
VIBE: Video Inference for Human Body Pose and Shape Estimation , author=. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[7]
arXiv preprint arXiv:2602.15989 , year=
SAM 3D Body: Robust Full-Body Human Mesh Recovery , author=. arXiv preprint arXiv:2602.15989 , year=
-
[8]
, booktitle=
Patel, Priyanka and Black, Michael J. , booktitle=
-
[9]
arXiv , year =
Feng, Qiao and Huang, Yiming and Wang, Yufu and Gu, Jiatao and Liu, Lingjie , title =. arXiv , year =
-
[10]
arXiv preprint arXiv:2510.11072 , year =
PhysHSI: Towards a Real-World Generalizable and Natural Humanoid-Scene Interaction System , author =. arXiv preprint arXiv:2510.11072 , year =
-
[11]
Proceedings of the Conference on Robot Learning (CoRL) , year =
Visual imitation enables contextual humanoid control , author =. Proceedings of the Conference on Robot Learning (CoRL) , year =
-
[12]
Yukang Cao and Haozhe Xie and Fangzhou Hong and Long Zhuo and Zhaoxi Chen and Liang Pan and Ziwei Liu , journal =
-
[13]
ACM SIGGRAPH 2024 Conference Papers , pages=
Physics-based Scene Layout Generation from Human Motion , author=. ACM SIGGRAPH 2024 Conference Papers , pages=
2024
-
[14]
and Peng, Xue Bin and Rempe, Davis , title=
Yi, Hongwei and Thies, Justus and Black, Michael J. and Peng, Xue Bin and Rempe, Davis , title=. ECCV , year=
-
[15]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Scene-aware Egocentric 3D Human Pose Estimation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[16]
European Conference on Computer Vision (ECCV) , year=
Xue, Lixin and Guo, Chen and Zheng, Chengwei and Wang, Fangjinhua and Jiang, Tianjian and Ho, Hsuan-I and Kaufmann, Manuel and Song, Jie and Hilliges Otmar , title=. European Conference on Computer Vision (ECCV) , year=
-
[17]
arXiv preprint arXiv:2112.03030 , year=
Pose2Room: Understanding 3D Scenes from Human Activities , author=. arXiv preprint arXiv:2112.03030 , year=
-
[18]
, booktitle =
Hassan, Mohamed and Ghosh, Partha and Tesch, Joachim and Tzionas, Dimitrios and Black, Michael J. , booktitle =. Populating
-
[19]
Proceedings of the International Conference on Computer Vision 2021 , month = oct, year =
Stochastic Scene-Aware Motion Prediction , author =. Proceedings of the International Conference on Computer Vision 2021 , month = oct, year =
2021
-
[20]
2025 , eprint=
SAM 3: Segment Anything with Concepts , author=. 2025 , eprint=
2025
-
[21]
SAM 2: Segment Anything in Images and Videos
SAM 2: Segment Anything in Images and Videos , author=. arXiv preprint arXiv:2408.00714 , url=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Wang, Yifan and Zhou, Jianjun and Zhu, Haoyi and Chang, Wenzheng and Zhou, Yang and Li, Zizun and Chen, Junyi and Pang, Jiangmiao and Shen, Chunhua and He, Tong , journal=. ^
-
[23]
Black , booktitle=
Joachim Tesch and Giorgio Becherini and Prerana Achar and Anastasios Yiannakidis and Muhammed Kocabas and Priyanka Patel and Michael J. Black , booktitle=
-
[24]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
GLAMR: Global Occlusion-Aware Human Mesh Recovery with Dynamic Cameras , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[25]
SIGGRAPH Asia Conference Proceedings , year=
World-Grounded Human Motion Recovery via Gravity-View Coordinates , author=. SIGGRAPH Asia Conference Proceedings , year=
-
[26]
European Conference on Computer Vision (
CHORE: Contact, Human and Object REconstruction from a single RGB image , author =. European Conference on Computer Vision (
-
[27]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month=
Visibility Aware Human-Object Interaction Tracking from Single RGB Camera , author =. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month=
-
[28]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Template Free Reconstruction of Human-object Interaction with Procedural Interaction Generation , author =. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[29]
2024 , eprint=
InterTrack: Tracking Human Object Interaction without Object Templates , author=. 2024 , eprint=
2024
-
[30]
Conference on Computer Vision and Pattern Recognition (
CARI4D: Category Agnostic 4D Reconstruction of Human-Object Interaction , author =. Conference on Computer Vision and Pattern Recognition (
-
[31]
Efros and Angjoo Kanazawa , Title =
Qianqian Wang* and Yifei Zhang* and Aleksander Holynski and Alexei A. Efros and Angjoo Kanazawa , Title =. 2025 , booktitle=
2025
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
VGGT: Visual Geometry Grounded Transformer , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[33]
arXiv preprint arXiv:2510.06219 , year=
Human3R: Everyone Everywhere All at Once , author=. arXiv preprint arXiv:2510.06219 , year=
-
[34]
The Fourteenth International Conference on Learning Representations , year=
Joint Optimization for 4D Human-Scene Reconstruction in the Wild , author=. The Fourteenth International Conference on Learning Representations , year=
-
[35]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month=
Decoupling Human and Camera Motion from Videos in the Wild , author=. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month=
-
[36]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-Shot Cross-Dataset Transfer , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =. 2022 , doi =
2022
-
[37]
, title =
Sun, Yu and Bao, Qian and Liu, Wu and Mei, Tao and Black, Michael J. , title =. IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR) , month =
-
[38]
2026 , eprint=
UniSH: Unifying Scene and Human Reconstruction in a Feed-Forward Pass , author=. 2026 , eprint=
2026
-
[39]
ECCV , Year =
CLIFF: Carrying Location Information in Full Frames into Human Pose and Shape Estimation , Author =. ECCV , Year =
-
[40]
, booktitle=
Dwivedi, Sai Kumar and Sun, Yu and Patel, Priyanka and Feng, Yao and Black, Michael J. , booktitle=
-
[41]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Neural Localizer Fields for Continuous 3D Human Pose and Shape Estimation , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[42]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
PromptHMR: Promptable Human Mesh Recovery , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[43]
Pavlakos, Georgios and Choutas, Vasileios and Ghorbani, Nima and Bolkart, Timo and Osman, Ahmed A. A. and Tzionas, Dimitrios and Black, Michael J. , booktitle =. Expressive Body Capture:
-
[44]
, title =
Loper, Matthew and Mahmood, Naureen and Romero, Javier and Pons-Moll, Gerard and Black, Michael J. , title =. ACM Trans. Graphics (Proc. SIGGRAPH Asia) , month = oct, number =
-
[45]
ICLR , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. ICLR , year=
-
[46]
DINOv2: Learning Robust Visual Features without Supervision
DINOv2: Learning Robust Visual Features without Supervision , author=. arXiv:2304.07193 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.