Towards Reliable and Robust LLM Planning: Symbolic Feedback-Driven Iterative Self-Refinement Framework
Pith reviewed 2026-06-29 04:50 UTC · model grok-4.3
The pith
A symbolic feedback-driven iterative self-refinement framework improves feasibility and correctness of LLM plans in long-horizon tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
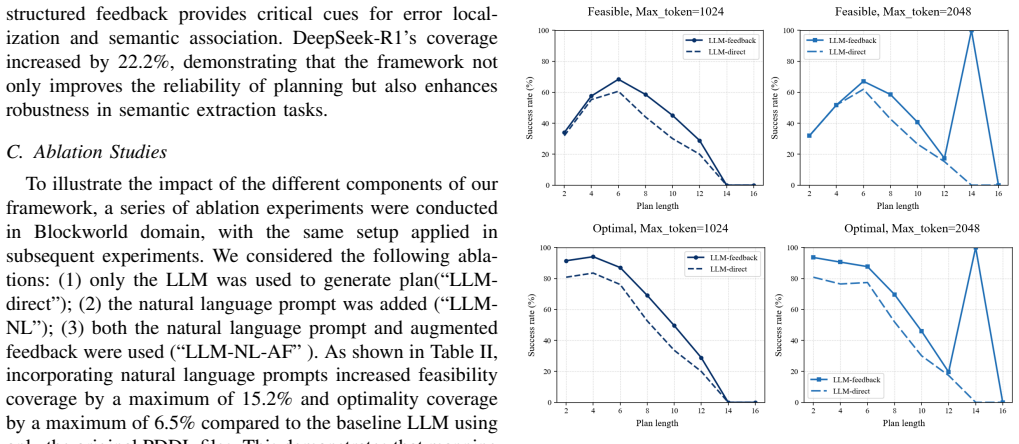
The central claim is that a symbolic feedback-driven iterative self-refinement framework, consisting of natural language prompting to convey task constraints, a symbolic verifier that detects plan errors and translates them into LLM-interpretable corrective instructions, and a plan recognizer that infers goal reachability, enables LLMs to produce more feasible and correct plans in long-horizon tasks through guided self-refinement.
What carries the argument
The symbolic feedback-driven iterative self-refinement framework, which maps symbols to natural language, uses a symbolic verifier for error detection and corrective instructions, and employs a plan recognizer for goal reachability inference.
If this is right
- LLMs generate plans with higher feasibility rates in long-horizon decision-making tasks.
- Plan correctness improves consistently through iterative self-refinement guided by symbolic feedback.
- The framework reduces the occurrence of infeasible or incorrect solutions without external intervention.
- LLM-based planning systems become more reliable for deployment in complex environments.
Where Pith is reading between the lines
- The method could extend to domains like robotics task sequencing where symbolic constraints are already formalized.
- If the verifier scales, it might reduce reliance on post-hoc human review for AI-generated plans.
- Comparing performance across different LLM sizes could reveal whether the framework compensates for smaller models' weaknesses.
Load-bearing premise
The symbolic verifier can reliably detect plan errors and translate them into corrective instructions that the LLM can effectively use for self-refinement.
What would settle it
A controlled test set of long-horizon planning problems where known invalid plans are fed to the framework but the verifier fails to identify errors or the LLM shows no measurable gain in feasibility or correctness metrics after refinement iterations.
Figures




read the original abstract
Large language models (LLMs) have attracted widespread attention from academia and industry, yet their deployment raises critical security concerns regarding robustness and reliability. Planning, a core component of intelligent behavior, remains challenging for LLMs, which often produce infeasible or incorrect solutions in long-horizon decision-making tasks due to inherent complexity. In this paper, we propose a symbolic feedback-driven iterative self-refinement framework to enhance the robustness and reliability of LLMs in long-horizon planning. Specifically, a natural language prompting mechanism is introduced to map logical symbols into natural language descriptions, enabling LLMs to better capture task constraints and semantics. We further design a symbolic verifier that identifies errors and converts them into corrective instructions interpretable by the LLM, thereby guiding self-refinement. In addition, we leverage a plan recognizer to infer goal reachability, facilitating more effective guidance toward desired goals. Empirical results demonstrate that the proposed framework consistently improves both feasibility and correctness in long-horizon planning tasks. This highlights its effectiveness in enhancing the reliability of LLM-based planning and potential to enable more trustworthy AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a symbolic feedback-driven iterative self-refinement framework for enhancing LLM robustness in long-horizon planning. It introduces natural-language prompting to map logical symbols to descriptions, a symbolic verifier that detects plan errors and generates corrective instructions for LLM self-refinement, and a plan recognizer to assess goal reachability. The central claim is that this framework yields consistent empirical improvements in plan feasibility and correctness.
Significance. If the empirical improvements are substantiated and the verifier's feedback is shown to be reliable and independent of LLM memorization, the work could address a key limitation in LLM planning by providing a hybrid symbolic-neural refinement loop. The approach builds on existing ideas in LLM self-correction but adds explicit symbolic components; however, without validation data the significance remains speculative.
major comments (2)
- [Abstract] Abstract: The assertion that 'empirical results demonstrate that the proposed framework consistently improves both feasibility and correctness' supplies no methods, datasets, baselines, quantitative metrics, or controls. This absence makes it impossible to assess whether the data support the central claim of consistent improvement.
- [Abstract] Abstract (symbolic verifier description): The verifier is presented as identifying errors and converting them into corrective instructions, yet no accuracy metrics, false-positive/negative rates, ablation on verifier errors, or comparison to oracle feedback are reported. This is load-bearing because observed gains could arise from LLM adaptation to verifier quirks rather than genuine planning improvement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the abstract should better substantiate its claims and will revise it accordingly. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'empirical results demonstrate that the proposed framework consistently improves both feasibility and correctness' supplies no methods, datasets, baselines, quantitative metrics, or controls. This absence makes it impossible to assess whether the data support the central claim of consistent improvement.
Authors: We acknowledge that the abstract, due to length constraints, omits specific experimental details. The full manuscript (Sections 4 and 5) describes the methods, datasets (Blocksworld, Logistics, and custom long-horizon tasks), baselines (vanilla LLM planning, self-correction baselines), metrics (feasibility rate, correctness rate, success rate), and controls (multiple LLM backbones, temperature settings). To address the concern, we will revise the abstract to include a concise summary of these elements supporting the improvement claim. revision: yes
-
Referee: [Abstract] Abstract (symbolic verifier description): The verifier is presented as identifying errors and converting them into corrective instructions, yet no accuracy metrics, false-positive/negative rates, ablation on verifier errors, or comparison to oracle feedback are reported. This is load-bearing because observed gains could arise from LLM adaptation to verifier quirks rather than genuine planning improvement.
Authors: The verifier is a deterministic, rule-based symbolic component operating on logical symbols (independent of LLM outputs), which by design minimizes false positives/negatives on syntactic and constraint violations. We agree that explicit validation metrics would strengthen the claims. In the revision, we will add a dedicated subsection reporting verifier accuracy, error rates, an ablation on verifier-induced errors, and comparison against oracle feedback to confirm that gains stem from genuine planning refinement. revision: yes
Circularity Check
No circularity: empirical framework with no derivations or self-referential reductions
full rationale
The paper describes an empirical framework for LLM planning that relies on a symbolic verifier and plan recognizer to generate feedback for iterative refinement. No equations, derivations, or mathematical predictions appear in the provided text. The central claims rest on experimental results showing improved feasibility and correctness, which are not reducible to fitted inputs or self-citations by construction. The verifier's design is presented as a contribution rather than justified via load-bearing self-citation or ansatz smuggling. This is a standard empirical AI systems paper whose validation is external to any internal derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Plangenllms: A modern survey of llm planning capabilities,
H. Wei, Z. Zhang, S. He, T. Xia, S. Pan, and F. Liu, “Plangenllms: A modern survey of llm planning capabilities,” inProceedings of the Annual Meeting of the Association for Computational Linguistics, vol. 1, 2025, pp. 19 497–19 521
2025
-
[2]
Training large language models on narrow tasks can lead to broad misalignment,
J. Betley, N. Warncke, A. Sztyber-Betley, D. Tan, X. Bao, M. Soto, M. Srivastava, N. Labenz, and O. Evans, “Training large language models on narrow tasks can lead to broad misalignment,”Nature, vol. 649, no. 8097, pp. 584–589, 2026
2026
-
[3]
J. Duan, R. Zhang, J. Diffenderfer, B. Kailkhura, L. Sun, E. Stengel- Eskin, M. Bansal, T. Chen, and K. Xu, “Gtbench: Uncovering the strategic reasoning limitations of llms via game-theoretic evaluations,” arXiv preprint arXiv:2402.12348, 2024
-
[4]
The computational complexity of propositional strips planning,
T. Bylander, “The computational complexity of propositional strips planning,”Artificial Intelligence, vol. 69, no. 1, pp. 165–204, 1994
1994
-
[5]
Isr-llm: Iterative self- refined large language model for long-horizon sequential task plan- ning,
Z. Zhou, J. Song, K. Yao, Z. Shu, and L. Ma, “Isr-llm: Iterative self- refined large language model for long-horizon sequential task plan- ning,” inIEEE International Conference on Robotics and Automation. IEEE, 2024, pp. 2081–2088
2024
-
[6]
On the complexity of blocks-world plan- ning,
N. Gupta and D. S. Nau, “On the complexity of blocks-world plan- ning,”Artificial Intelligence, vol. 56, no. 2, pp. 223–254, 1992
1992
-
[7]
Long-horizon multi-robot rearrangement planning for construction assembly,
V . N. Hartmann, A. Orthey, D. Driess, O. S. Oguz, and M. Toussaint, “Long-horizon multi-robot rearrangement planning for construction assembly,”IEEE Transactions on Robotics, vol. 39, no. 1, pp. 239–252, 2022
2022
-
[8]
Llms still can’t plan; can lrms? a preliminary evaluation of openai’s o1 on planbench,
K. Valmeekam, K. Stechly, and S. Kambhampati, “Llms still can’t plan; can lrms? a preliminary evaluation of openai’s o1 on planbench,” in NeurIPS 2024 Workshop on Open-World Agents, 2024
2024
-
[9]
Can large language models reason and plan?
S. Kambhampati, “Can large language models reason and plan?” Annals of the New York Academy of Sciences, vol. 1534, no. 1, pp. 15–18, 2024
2024
-
[10]
Z. Wang, F. Wu, H. Wang, X. Tang, B. Li, Z. Yin, Y . Ma, Y . Li, W. Sun, X. Chenet al., “Why reasoning fails to plan: A planning- centric analysis of long-horizon decision making in llm agents,”arXiv preprint arXiv:2601.22311, 2026
-
[11]
Toward large reasoning models: A survey of reinforced reasoning with large language models,
F. Xu, Q. Hao, C. Shao, Z. Zong, Y . Li, J. Wang, Y . Zhang, J. Wang, X. Lan, J. Gong, T. Ouyang, F. Meng, and Y . Y . et al., “Toward large reasoning models: A survey of reinforced reasoning with large language models,”Patterns, vol. 6, no. 10, p. 101370, 2025
2025
-
[12]
Fast planning through planning graph analysis,
A. L. Blum and M. L. Furst, “Fast planning through planning graph analysis,”Artificial Intelligence, vol. 90, no. 1-2, pp. 281–300, 1997
1997
-
[13]
A survey on neural- symbolic learning systems,
D. Yu, B. Yang, D. Liu, H. Wang, and S. Pan, “A survey on neural- symbolic learning systems,”Neural Networks, vol. 166, pp. 105–126, 2023
2023
-
[14]
Planning as heuristic search,
B. Bonet and H. Geffner, “Planning as heuristic search,”Artificial Intelligence, vol. 129, no. 1-2, pp. 5–33, 2001
2001
-
[15]
Fast downward scorpion,
S. Jendrik, “Fast downward scorpion,” inProceedings of the Interna- tional Planning Competition, 2018
2018
-
[16]
Sr-llm: An incremental symbolic regression framework driven by llm-based retrieval-augmented generation,
Z. Guo, S. Wang, Y . Tian, J. Yang, H. Yu, X. Na, L. Kov´acs, L. Li, P. A. Ioannou, and F.-Y . Wang, “Sr-llm: An incremental symbolic regression framework driven by llm-based retrieval-augmented generation,”Pro- ceedings of the National Academy of Sciences, vol. 122, p. 52, 2025
2025
-
[17]
A closed-loop architecture with knowledge-of-results feedback for neural-symbolic planning,
J. Zhang, J. Jiang, L. Li, C. Zhang, J. Shi, and D. Zeng, “A closed-loop architecture with knowledge-of-results feedback for neural-symbolic planning,”Knowledge-Based Systems, p. 114041, 2025
2025
-
[18]
Neuro-symbolic artificial intelligence: towards improving the reasoning abilities of large language models,
X.-W. Yang, J.-J. Shao, L.-Z. Guo, B.-W. Zhang, Z. Zhou, L.-H. Jia, W.-Z. Dai, and Y .-F. Li, “Neuro-symbolic artificial intelligence: towards improving the reasoning abilities of large language models,” inProceedings of the International Joint Conference on Artificial Intelligence, 2025
2025
-
[19]
Ghallab, D
M. Ghallab, D. Nau, and P. Traverso,Automated planning: theory and practice. Morgan Kaufmann, 2004
2004
-
[20]
Allmendinger,Planning theory
P. Allmendinger,Planning theory. Bloomsbury Publishing, 2017
2017
-
[21]
Haslum, N
P. Haslum, N. Lipovetzky, D. Magazzeni, C. Muise, R. Brachman, F. Rossi, and P. Stone,An introduction to the planning domain definition language. Springer, 2019, vol. 13
2019
-
[22]
Pddl—the planning domain definition language,
C. Aeronautiques, A. Howe, C. Knoblock, I. D. McDermott, A. Ram, M. Veloso, D. Weld, D. W. Sri, A. Barrett, D. Christiansonet al., “Pddl—the planning domain definition language,”Technical Report, Tech. Rep., 1998
1998
-
[23]
Adaplanner: Adaptive planning from feedback with language models,
H. Sun, Y . Zhuang, L. Kong, B. Dai, and C. Zhang, “Adaplanner: Adaptive planning from feedback with language models,”Advances in neural information processing systems, vol. 36, pp. 202–245, 2023
2023
-
[24]
Automating the generation of prompts for llm-based action choice in pddl planning,
K. Stein, D. Fi ˇser, J. Hoffmann, and A. Koller, “Automating the generation of prompts for llm-based action choice in pddl planning,” in Proceedings of the International Conference on Automated Planning and Scheduling, vol. 35, no. 1, 2025, pp. 250–259
2025
-
[25]
Hddl: An extension to pddl for expressing hierarchi- cal planning problems,
D. H ¨oller, G. Behnke, P. Bercher, S. Biundo, H. Fiorino, D. Pellier, and R. Alford, “Hddl: An extension to pddl for expressing hierarchi- cal planning problems,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 06, 2020, pp. 9883–9891
2020
-
[26]
Val: Automatic plan validation, continuous effects and mixed initiative planning using pddl,
R. Howey, D. Long, and M. Fox, “Val: Automatic plan validation, continuous effects and mixed initiative planning using pddl,” inIEEE International Conference on Tools with Artificial Intelligence, 2004, pp. 294–301
2004
-
[27]
Landmark-based heuristics for goal recognition,
R. Pereira, N. Oren, and F. Meneguzzi, “Landmark-based heuristics for goal recognition,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 31, 2017
2017
-
[28]
Plan recognition as planning,
M. Ram ´ırez and H. Geffner, “Plan recognition as planning,” inPro- ceedings of the International Joint Conference on Artificial Intelli- gence, San Francisco, CA, USA, 2009, p. 1778–1783
2009
-
[29]
Planbench: an extensible benchmark for evaluating large language models on planning and reasoning about change,
K. Valmeekam, M. Marquez, A. Olmo, S. Sreedharan, and S. Kamb- hampati, “Planbench: an extensible benchmark for evaluating large language models on planning and reasoning about change,” inProceed- ings of the International Conference on Neural Information Processing Systems, vol. 36, 2024, p. 13
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.