Text as Illumination: Spatial Contrastive Retinex Learning for Language-guided Medical Image Segmentation
Pith reviewed 2026-06-29 04:57 UTC · model grok-4.3
The pith
Treating text embeddings as semantic illumination in a Retinex-inspired network improves semantic consistency in language-guided medical image segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
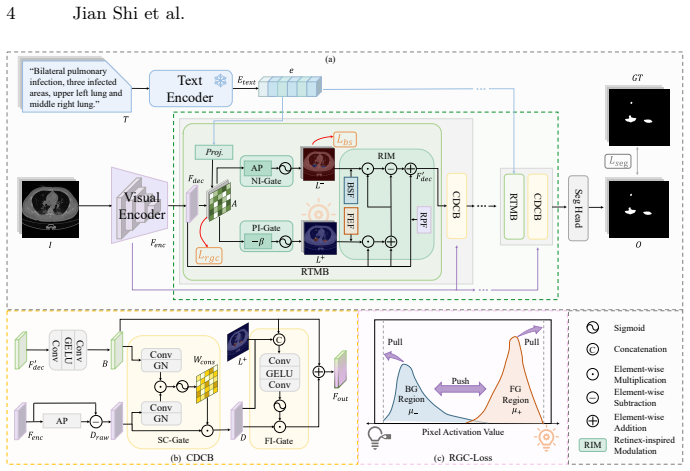
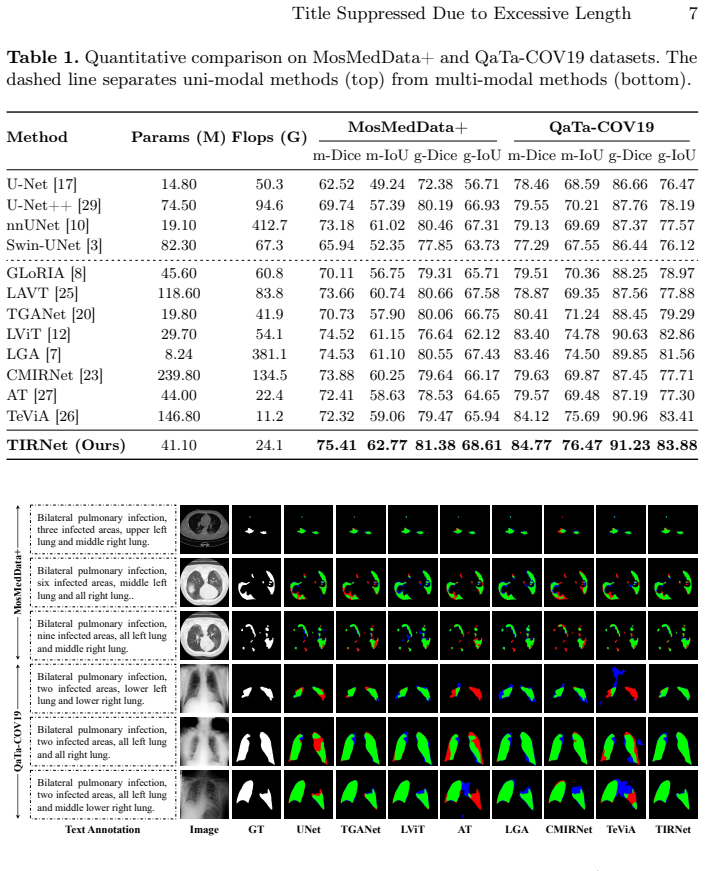
The central claim is that by treating text embeddings as semantic illumination for feature modulation via the Retinex-inspired Text Modulation Block and Consistent Detail Compensation Block, along with the Multi-Scale Illumination Supervision Loss, the TIRNet framework ensures precise cross-modal alignment and achieves state-of-the-art performance in language-guided medical image segmentation on the MosMedData+ and QaTa-COV19 datasets.
What carries the argument
The Retinex-inspired Text Modulation Block (RTMB), which employs positive and negative illumination maps to enhance text-relevant foreground features and suppress background interference.
If this is right
- Semantic consistency is enforced at each decoder stage through illumination maps.
- Region-Grounded Contrastive Loss concentrates cross-modal similarity in text-relevant regions.
- Background Suppression Loss provides pixel-level supervision for negative maps.
- High-frequency details are recovered via consistency-gated mechanism.
- State-of-the-art results are demonstrated on two medical segmentation datasets.
Where Pith is reading between the lines
- The modulation blocks could be tested for transfer to non-medical vision-language segmentation tasks.
- Varying the number of decoder stages where the blocks are applied might reveal optimal placement for different image resolutions.
- The approach may require additional checks when clinical text contains ambiguous or conflicting descriptions.
Load-bearing premise
The Retinex model can be directly adapted to text-visual feature interaction in medical images to ensure semantic consistency without introducing artifacts or requiring extensive hyperparameter tuning.
What would settle it
Performance that drops or introduces visible artifacts when the illumination maps are removed or when tested on datasets with mismatched text-image pairs would falsify the claim.
Figures


read the original abstract
Language-guided Medical Image Segmentation (LMIS) has shown great potential to improve the delineation of anatomical structures and lesions by integrating clinical textual information. Existing methods generally rely on either implicit interaction between textual and visual features or auxiliary coarse-grained supervision for cross-modal alignment. However, these methods lack explicit and fine-grained constraints to ensure semantic consistency, causing a mismatch between language and the segmentation outputs. To address this issue, we propose Text-as-Illumination Retinex Network (TIRNet), a novel Retinex-inspired framework that treats text embeddings as semantic illumination for feature modulation, thereby improving semantic consistency in LMIS. TIRNet introduces two key blocks integrated at each decoder stage: (1) the Retinex-inspired Text Modulation Block (RTMB), which employs positive and negative illumination maps to enhance text-relevant foreground features and suppress background interference; and (2) the Consistent Detail Compensation Block (CDCB), which selectively recovers high-frequency details via a consistency-gated mechanism conditioned on illumination reliability. Furthermore, we propose a Multi-Scale Illumination Supervision Loss (MSIS-Loss), comprising a Region-Grounded Contrastive Loss (RGC-Loss) that enforces cross-modal similarity to be concentrated in text-relevant foreground regions and suppressed in background regions, and a Background Suppression Loss (BS-Loss) that provides pixel-level supervision for negative illumination maps, jointly ensuring a precise cross-modal alignment at each decoder stage. Extensive experiments on the MosMedData+ and QaTa-COV19 datasets demonstrate that TIRNet achieves state-of-the-art performance in LMIS. The code is available at: https://github.com/anaanaa/TIRNet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TIRNet, a Retinex-inspired framework for language-guided medical image segmentation (LMIS). Text embeddings are treated as semantic illumination to modulate features via the Retinex-inspired Text Modulation Block (RTMB) and Consistent Detail Compensation Block (CDCB) integrated at each decoder stage. A Multi-Scale Illumination Supervision Loss (MSIS-Loss) is introduced, consisting of Region-Grounded Contrastive Loss (RGC-Loss) and Background Suppression Loss (BS-Loss) to enforce cross-modal alignment. Experiments on MosMedData+ and QaTa-COV19 datasets claim state-of-the-art performance, with code released at https://github.com/anaanaa/TIRNet.
Significance. If the empirical SOTA results hold under rigorous validation, the work offers a concrete mechanism for explicit fine-grained text-visual alignment in LMIS via positive/negative illumination maps and region-grounded contrastive supervision. Credit is due for the public code release, which enables direct reproducibility of the reported performance on the two cited datasets.
minor comments (3)
- Abstract: the SOTA claim would be strengthened by explicit mention of the evaluation metrics (e.g., Dice, IoU), number of runs, and whether error bars or statistical tests accompany the reported gains over prior LMIS methods.
- The Retinex analogy is used to motivate the positive/negative illumination maps in RTMB and the consistency-gated recovery in CDCB; a brief discussion of how the medical-image domain differs from classical Retinex assumptions (e.g., illumination smoothness) would improve clarity without altering the central claim.
- Section describing MSIS-Loss: the interaction between RGC-Loss and BS-Loss at multiple decoder scales is central to the alignment argument; a single consolidated equation or pseudocode block would make the joint supervision easier to follow.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work on TIRNet and the recommendation for minor revision. The referee's summary correctly reflects the core contributions, including the Retinex-inspired design with RTMB, CDCB, and MSIS-Loss for explicit cross-modal alignment in LMIS. No major comments were provided in the report.
Circularity Check
No significant circularity; derivation is self-contained empirical construction
full rationale
The paper introduces TIRNet as a Retinex-inspired architecture with explicitly defined components (RTMB, CDCB, MSIS-Loss with RGC-Loss and BS-Loss) whose purpose is to enforce cross-modal alignment via positive/negative illumination maps and region-grounded contrastive supervision. These are presented as design choices motivated by the Retinex analogy rather than derived from prior results by the same authors. No equations reduce a prediction to a fitted input by construction, no uniqueness theorem is imported via self-citation, and the central claim (SOTA on MosMedData+ and QaTa-COV19) rests on experimental outcomes with released code. The method is therefore externally falsifiable and does not collapse to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: International Con- ference on Medical Image Computing and Computer-Assisted Intervention
Bozorgpour, A., Kolahi, S.G., Azad, R., Hacihaliloglu, I., Merhof, D.: CENet: Con- text enhancement network for medical image segmentation. In: International Con- ference on Medical Image Computing and Computer-Assisted Intervention. pp. 120–129 (2025)
2025
-
[2]
In: IEEE/CVF International Conference on Computer Vision
Cai, Y., Bian, H., Lin, J., Wang, H., Timofte, R., Zhang, Y.: Retinexformer: One- stage Retinex-based Transformer for low-light image enhancement. In: IEEE/CVF International Conference on Computer Vision. pp. 12504–12513 (2023)
2023
-
[3]
In: European Conference on Computer Vision Workshops
Cao, H., Wang, Y., Chen, J., Jiang, D., Zhang, X., Tian, Q., Wang, M.: Swin- Unet: Unet-like pure Transformer for medical image segmentation. In: European Conference on Computer Vision Workshops. pp. 205–218 (2022)
2022
-
[4]
In: International Conference on Machine Learning
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for con- trastive learning of visual representations. In: International Conference on Machine Learning. pp. 1597–1607 (2020)
2020
-
[5]
In: IEEE International Conference on Image Processing
Degerli, A., Kiranyaz, S., Chowdhury, M.E., Gabbouj, M.: Osegnet: Operational segmentation network for Covid-19 detection using chest X-Ray images. In: IEEE International Conference on Image Processing. pp. 2306–2310 (2022)
2022
-
[6]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Guo, Y., Zeng, X., Zeng, P., Fei, Y., Wen, L., Zhou, J., Wang, Y.: Common vision- language attention for text-guided medical image segmentation of pneumonia. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 192–201 (2024)
2024
-
[7]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Hu, J., Li, Y., Sun, H., Song, Y., Zhang, C., Lin, L., Chen, Y.W.: LGA: A lan- guage guide adapter for advancing the SAM model’s capabilities in medical im- age segmentation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 610–620 (2024)
2024
-
[8]
In: IEEE/CVF International Conference on Computer Vision
Huang, S.C., Shen, L., Lungren, M.P., Yeung, S.: GLoRIA: A multimodal global- local representation learning framework for label-efficient medical image recogni- tion. In: IEEE/CVF International Conference on Computer Vision. pp. 3942–3951 (2021) 10 Jian Shi et al
2021
-
[9]
IEEE Transactions on Medical Imaging44(4), 1821–1835 (2024)
Huang, X., Li, H., Cao, M., Chen, L., You, C., An, D.: Cross-modal conditioned re- construction for language-guided medical image segmentation. IEEE Transactions on Medical Imaging44(4), 1821–1835 (2024)
2024
-
[10]
Nature Methods18(2), 203–211 (2021)
Isensee, F., Jaeger, P.F., Kohl, S.A., Petersen, J., Maier-Hein, K.H.: nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation. Nature Methods18(2), 203–211 (2021)
2021
-
[11]
Scientific American237(6), 108– 129 (1977)
Land, E.H.: The Retinex theory of color vision. Scientific American237(6), 108– 129 (1977)
1977
-
[12]
IEEE Transactions on Medical Imaging43(1), 96–107 (2023)
Li, Z., Li, Y., Li, Q., Wang, P., Guo, D., Lu, L., Jin, D., Zhang, Y., Hong, Q.: LViT: Language meets Vision Transformer in medical image segmentation. IEEE Transactions on Medical Imaging43(1), 96–107 (2023)
2023
-
[13]
IEEE Transactions on Industrial Informatics 21(12), 9619–9630 (2025)
Liu, Z., Geng, K., Cheng, X., Wang, Z., Yin, G., Sun, Y., Ma, T.: RetinexDet: En- hancing multispectral object detection via retinex state space duality and wavelet- based frequency adaptive fusion. IEEE Transactions on Industrial Informatics 21(12), 9619–9630 (2025)
2025
-
[14]
In: International Conference on Learning Representations (2019)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (2019)
2019
-
[15]
Digital Diagnostics1(1), 49–59 (2020)
Morozov, S.P., Andreychenko, A.E., Blokhin, I.A., Gelezhe, P.B., Gonchar, A.P., Nikolaev, A.E., Pavlov, N.A., Chernina, V.Y., Gombolevskiy, V.A.: MosMedData: data set of 1110 chest CT scans performed during the COVID-19 epidemic. Digital Diagnostics1(1), 49–59 (2020)
2020
-
[16]
In: International Conference on Machine Learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning. pp. 8748–8763 (2021)
2021
-
[17]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Ronneberger, O., Fischer, P., Brox, T.: U-Net: Convolutional networks for biomedi- cal image segmentation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 234–241 (2015)
2015
-
[18]
In: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Rui, S., Chen, L., Tang, Z., Wang, L., Liu, M., Zhang, S., Wang, X.: Multi-modal vision pre-training for medical image analysis. In: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 5164–5174 (2025)
2025
-
[19]
IEEE Transactions on Medical Imaging42(4), 935–946 (2022)
Shi, J., Sun, B., Ye, X., Wang, Z., Luo, X., Liu, J., Gao, H., Li, H.: Semantic de- composition network with contrastive and structural constraints for dental plaque segmentation. IEEE Transactions on Medical Imaging42(4), 935–946 (2022)
2022
-
[20]
In: International Conference on Medical Image Com- puting and Computer-Assisted Intervention
Tomar, N.K., Jha, D., Bagci, U., Ali, S.: TGANet: Text-guided attention for im- proved polyp segmentation. In: International Conference on Medical Image Com- puting and Computer-Assisted Intervention. pp. 151–160 (2022)
2022
-
[21]
In: IEEE/CVF International Conference on Computer Vision
Wang, W., Zhou, T., Yu, F., Dai, J., Konukoglu, E., Van Gool, L.: Exploring cross-image pixel contrast for semantic segmentation. In: IEEE/CVF International Conference on Computer Vision. pp. 7303–7313 (2021)
2021
-
[22]
In: European Conference on Computer Vi- sion
Wu, Y., He, K.: Group normalization. In: European Conference on Computer Vi- sion. pp. 3–19 (2018)
2018
-
[23]
IEEE Transactions on Circuits and Systems for Video Technology35(4), 3234–3249 (2024)
Xu, M., Xiao, T., Liu, Y., Tang, H., Hu, Y., Nie, L.: CMIRNet: Cross-modal interactive reasoning network for referring image segmentation. IEEE Transactions on Circuits and Systems for Video Technology35(4), 3234–3249 (2024)
2024
-
[24]
IEEE Transactions on Geoscience and Remote Sensing61, 1–12 (2023)
Yan, T., Wan, Z., Zhang, P., Cheng, G., Lu, H.: TransY-Net: Learning fully trans- former networks for change detection of remote sensing images. IEEE Transactions on Geoscience and Remote Sensing61, 1–12 (2023)
2023
-
[25]
In: IEEE/CVF Con- ference on Computer Vision and Pattern Recognition
Yang, Z., Wang, J., Tang, Y., Chen, K., Zhao, H., Torr, P.H.: LAVT: Language- aware Vision Transformer for referring image segmentation. In: IEEE/CVF Con- ference on Computer Vision and Pattern Recognition. pp. 18155–18165 (2022) Title Suppressed Due to Excessive Length 11
2022
-
[26]
IEEE Transactions on Medical Imaging45(2), 477–489 (2026)
Zeng, Q., Luo, H., Lu, Z., Xie, Y., Wang, Z., Zhang, Y., Xia, Y.: Harnessing text insights with visual alignment for medical image segmentation. IEEE Transactions on Medical Imaging45(2), 477–489 (2026)
2026
-
[27]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Zhong, Y., Xu, M., Liang, K., Chen, K., Wu, M.: Ariadne’s thread: Using text prompts to improve segmentation of infected areas from chest X-ray images. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 724–733 (2023)
2023
-
[28]
Engineering Applications of Artificial Intelligence144, 110073 (2025)
Zhou, X., Song, Q., Nie, J., Feng, Y., Liu, H., Liang, F., Chen, L., Xie, J.: Hybrid cross-modality fusion network for medical image segmentation with contrastive learning. Engineering Applications of Artificial Intelligence144, 110073 (2025)
2025
-
[29]
In: International Workshop on Deep Learning in Medical Image Analysis
Zhou, Z., Rahman Siddiquee, M.M., Tajbakhsh, N., Liang, J.: UNet++: A nested U-Net architecture for medical image segmentation. In: International Workshop on Deep Learning in Medical Image Analysis. pp. 3–11 (2018)
2018
-
[30]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Zhu, W., Chen, X., Qiu, P., Farazi, M., Sotiras, A., Razi, A., Wang, Y.: SelfReg- UNet: Self-regularized UNet for medical image segmentation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 601–611 (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.