A Unified Framework for Vision Transformers Equivariant to Discrete Subgroups of O(2)
Pith reviewed 2026-06-29 04:34 UTC · model grok-4.3
The pith
Vision transformers can be made equivariant to arbitrary discrete subgroups of O(2) with natural embeddings between symmetry groups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a family of vision transformers equivariant to arbitrary discrete subgroups of O(2), yielding equivariant analogues of the core transformer components. Whenever H ≤ G, the class of G-equivariant ViTs embeds naturally into the class of H-equivariant ViTs. In the single-head setting, the corresponding equivariant self-attention layer realizes every G-equivariant self-attention map representable by ordinary self-attention. We further construct a D6-equivariant model based on hexagonal patches.
What carries the argument
Equivariant self-attention layers built from group actions on homogeneous spaces, together with the embedding map that sends G-equivariant parameters into H-equivariant ones when H is a subgroup of G.
If this is right
- The same transformer weights can serve as both G-equivariant and H-equivariant models whenever H is contained in G.
- A single-head equivariant attention layer is fully expressive for the space of G-equivariant attention maps.
- Hexagonal patches allow a D6-equivariant transformer compatible with six-fold rotational symmetry.
- Equivariant models can be compared directly across different discrete subgroups on the same dataset.
Where Pith is reading between the lines
- The embedding result suggests a systematic way to study how increasing the enforced symmetry group trades off model capacity against data efficiency.
- The hexagonal construction opens the possibility of equivariant transformers on non-Cartesian grids without first resampling the input.
- Performance differences across homogeneous-space choices in the nonlinearities point to a tunable design knob that may be optimized per dataset.
Load-bearing premise
Equivariant layers and nonlinearities can be realized by choosing homogeneous-space configurations that are compatible with the chosen discrete subgroup action.
What would settle it
An explicit G-equivariant attention map that can be written with ordinary self-attention but cannot be reproduced by the constructed equivariant layer, or a concrete pair H ≤ G for which no embedding of the full G-equivariant ViT class into the H-equivariant class exists.
Figures

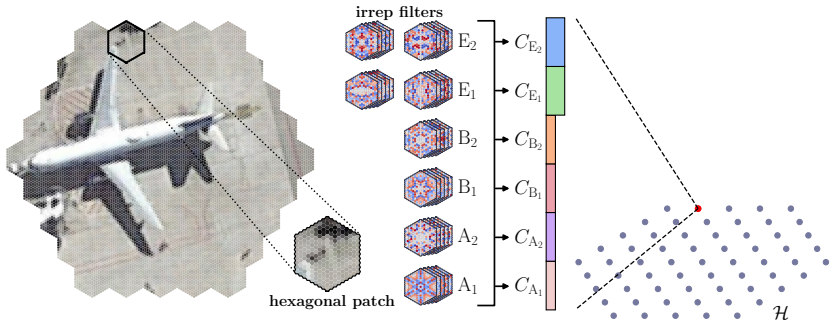
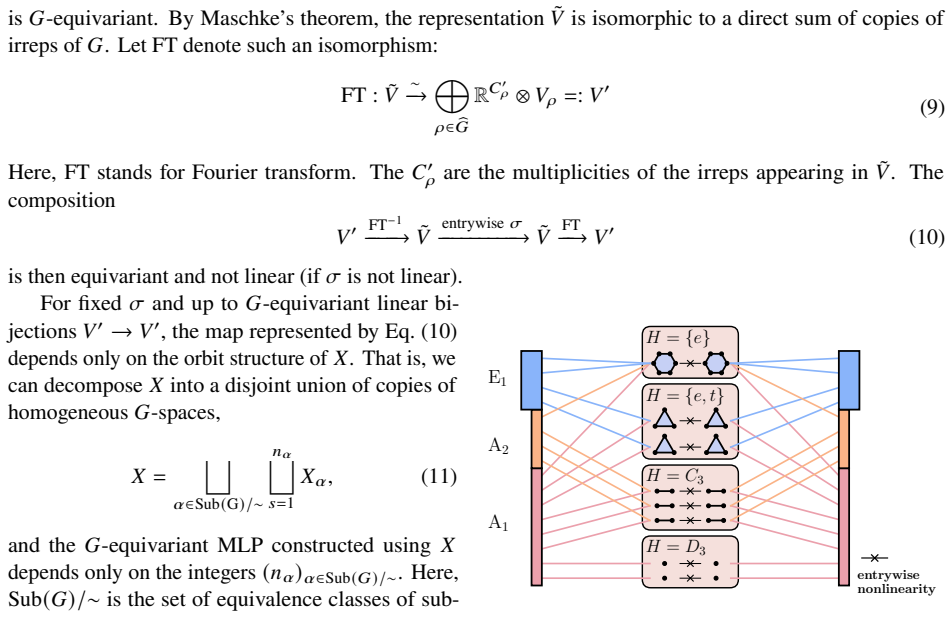



read the original abstract
Vision transformers have become a dominant architecture for visual recognition. However, standard models do not explicitly encode the planar symmetries that arise in many vision domains. We introduce a family of vision transformers equivariant to arbitrary discrete subgroups of $\mathrm{O}(2)$, providing a unified framework that generalizes prior flipping- and $D_4$-equivariant transformer architectures. Our construction yields equivariant analogues of the core transformer components, together with expressivity guarantees for the resulting layers. In particular, we show that whenever $H \le G$, the class of $G$-equivariant ViTs embeds naturally into the class of $H$-equivariant ViTs. We also prove that, in the single-head setting, the corresponding equivariant self-attention layer realizes every $G$-equivariant self-attention map representable by ordinary self-attention. We further construct a $D_6$-equivariant model based on hexagonal patches, making the architecture compatible with six-fold rotational symmetries. We evaluate the resulting models on the PatternNet aerial image dataset in artificially data-scarce regimes across subgroups of $D_4$ and $D_6$. Our experiments compare two equivariant attention mechanisms and analyze how the choice of homogeneous-space configurations used in the nonlinearities affects performance. Preliminary results under matched parameter budgets indicate that equivariance can improve recognition accuracy, motivating further study of how discrete symmetry groups shape transformer-based visual recognition models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a unified framework for vision transformers equivariant to arbitrary discrete subgroups of O(2), generalizing prior flipping- and D4-equivariant architectures. It constructs equivariant versions of core transformer components (including self-attention and nonlinearities via homogeneous spaces) and proves two central results: whenever H ≤ G the class of G-equivariant ViTs embeds naturally into the class of H-equivariant ViTs, and in the single-head setting the equivariant self-attention layer realizes every G-equivariant self-attention map representable by ordinary self-attention. The framework is instantiated for D6 symmetry using hexagonal patches; models are evaluated on PatternNet in data-scarce regimes, comparing two equivariant attention mechanisms and analyzing the effect of homogeneous-space configuration choices.
Significance. If the stated proofs hold, the embedding and expressivity guarantees constitute a substantive theoretical advance that unifies and extends existing equivariant transformer constructions. The D6 hexagonal instantiation and the explicit treatment of homogeneous-space nonlinearities are concrete strengths. The preliminary PatternNet experiments provide initial evidence that equivariance can yield accuracy gains under matched parameter budgets in low-data regimes, though the results remain exploratory.
minor comments (3)
- [§4] §4 (or equivalent): the description of the two equivariant attention mechanisms should include an explicit side-by-side comparison of their computational complexity and parameter counts under the same group action.
- [Experiments] Experiments section, Table 1 or equivalent: report the number of random seeds and any statistical significance tests for the reported accuracy improvements; the current 'preliminary results' phrasing leaves the robustness of the gains unclear.
- The notation for homogeneous-space configurations in the nonlinearity construction is introduced without a dedicated summary table; adding one would improve readability when comparing D4 and D6 cases.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No major comments were raised in the report.
Circularity Check
No significant circularity; derivations are self-contained mathematical constructions
full rationale
The central claims consist of explicit constructions of equivariant ViT components (layers, nonlinearities via homogeneous spaces) together with stated proofs of the natural embedding of G-equivariant ViTs into H-equivariant ones whenever H ≤ G, and of the expressivity result for single-head equivariant self-attention. These steps are derived directly from the definitions of group actions, equivariance, and standard transformer blocks; they do not reduce to fitted quantities, self-citations that carry the load of the result, or ansatzes smuggled from prior work by the same authors. Experiments on PatternNet are presented separately as empirical support and do not enter the derivation chain. The paper is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard facts from finite group representation theory and equivariant function spaces on homogeneous spaces
Reference graph
Works this paper leans on
-
[1]
URLhttp://arxiv.org/abs/1906.04015
BrandonAnderson,Truong-SonHy,andRisiKondor.Cormorant: CovariantMolecularNeuralNetworks, November 2019. URLhttp://arxiv.org/abs/1906.04015. arXiv:1906.04015 [physics]
arXiv 2019
-
[2]
VN-Transformer: Rotation-Equivariant Attention for Vector Neurons, January 2023
Serge Assaad, Carlton Downey, Rami Al-Rfou, Nigamaa Nayakanti, and Ben Sapp. VN-Transformer: Rotation-Equivariant Attention for Vector Neurons, January 2023. URLhttp://arxiv.org/abs/ 2206.04176. arXiv:2206.04176 [cs]
arXiv 2023
-
[3]
Ilyes Batatia, Dávid Péter Kovács, Gregor N. C. Simm, Christoph Ortner, and Gábor Csányi. MACE: HigherOrderEquivariantMessagePassingNeuralNetworksforFastandAccurateForceFields,January
- [4]
-
[5]
Mailoa, Mordechai Kornbluth, Nicola Molinari, Tess E
Simon Batzner, Albert Musaelian, Lixin Sun, Mario Geiger, Jonathan P. Mailoa, Mordechai Kornbluth, Nicola Molinari, Tess E. Smidt, and Boris Kozinsky. E(3)-equivariant graph neural networks for data-efficient and accurate interatomic potentials.Nature Communications, 13(1):2453, May 2022. ISSN 2041-1723. doi: 10.1038/s41467-022-29939-5. URLhttps://www.nat...
-
[6]
Erik J. Bekkers, Maxime W. Lafarge, Mitko Veta, Koen AJ Eppenhof, Josien PW Pluim, and Remco Duits. Roto-Translation Covariant Convolutional Networks for Medical Image Analysis, April 2018. URLhttps://arxiv.org/abs/1804.03393v3. 13
Pith/arXiv arXiv 2018
-
[7]
GeometricDeepLearning: Grids, Groups, Graphs, Geodesics, and Gauges, May 2021
MichaelM.Bronstein,JoanBruna,TacoCohen,andPetarVeličković. GeometricDeepLearning: Grids, Groups, Graphs, Geodesics, and Gauges, May 2021. URLhttp://arxiv.org/abs/2104.13478. arXiv:2104.13478 [cs]
Pith/arXiv arXiv 2021
-
[8]
Flopping for FLOPs: Leveraging equivariance for computationalefficiency,June2025
Georg Bökman, David Nordström, and Fredrik Kahl. Flopping for FLOPs: Leveraging equivariance for computationalefficiency,June2025. URL http://arxiv.org/abs/2502.05169. arXiv:2502.05169 [cs]
-
[9]
SE(3)- Equivariant Attention Networks for Shape Reconstruction in Function Space, February 2023
Evangelos Chatzipantazis, Stefanos Pertigkiozoglou, Edgar Dobriban, and Kostas Daniilidis. SE(3)- Equivariant Attention Networks for Shape Reconstruction in Function Space, February 2023. URL http://arxiv.org/abs/2204.02394. arXiv:2204.02394 [cs]
arXiv 2023
-
[10]
URLhttp://arxiv.org/abs/1811.02017
TacoCohen,MarioGeiger,andMauriceWeiler.AGeneralTheoryofEquivariantCNNsonHomogeneous Spaces, January 2020. URLhttp://arxiv.org/abs/1811.02017. arXiv:1811.02017 [cs]
arXiv 2020
-
[11]
Taco S. Cohen and Max Welling. Group Equivariant Convolutional Networks, February 2016. URL https://arxiv.org/abs/1602.07576v3
Pith/arXiv arXiv 2016
-
[12]
Taco S. Cohen and Max Welling. Steerable CNNs, December 2016. URLhttp://arxiv.org/abs/ 1612.08498. arXiv:1612.08498 [cs]
Pith/arXiv arXiv 2016
-
[13]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, June
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, June
-
[14]
URLhttp://arxiv.org/abs/2010.11929. arXiv:2010.11929 [cs]
Pith/arXiv arXiv 2010
-
[15]
E(n) Equivariant Message Passing Simplicial Networks, October 2023
Floor Eijkelboom, Rob Hesselink, and Erik Bekkers. E(n) Equivariant Message Passing Simplicial Networks, October 2023. URLhttp://arxiv.org/abs/2305.07100. arXiv:2305.07100 [cs]
arXiv 2023
-
[16]
Fabian B. Fuchs, Daniel E. Worrall, Volker Fischer, and Max Welling. SE(3)-Transformers: 3D Roto-Translation Equivariant Attention Networks, November 2020. URLhttp://arxiv.org/abs/ 2006.10503. arXiv:2006.10503 [cs]
arXiv 2020
-
[17]
JanE.Gerken,JimmyAronsson,OscarCarlsson,HampusLinander,FredrikOhlsson,ChristofferPeters- son,andDanielPersson. Geometricdeeplearningandequivariantneuralnetworks.ArtificialIntelligence Review, 56(12):14605–14662, December 2023. ISSN 1573-7462. doi: 10.1007/s10462-023-10502-7. URLhttps://doi.org/10.1007/s10462-023-10502-7
-
[18]
Onthesymmetriesofdeeplearning models and their internal representations
CharlesGodfrey, DavisBrown, TeganEmerson, andHenryKvinge. Onthesymmetriesofdeeplearning models and their internal representations. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, andA.Oh,editors,AdvancesinNeuralInformationProcessingSystems,volume35,pages11893–11905. Curran Associates, Inc., 2022. URLhttps://proceedings.neurips.cc/paper_files/pa...
2022
-
[19]
Efficient Equivariant Network
Lingshen He, Yuxuan Chen, zhengyang shen, Yiming Dong, Yisen Wang, and Zhouchen Lin. Efficient Equivariant Network. InAdvances in Neural Information Processing Systems, volume 34, pages 5290–5302. Curran Associates, Inc., 2021. URLhttps://proceedings.neurips.cc/paper/ 2021/hash/2a79ea27c279e471f4d180b08d62b00a-Abstract.html
2021
-
[20]
Emiel Hoogeboom, Jorn W. T. Peters, Taco S. Cohen, and Max Welling. HexaConv, March 2018. URL http://arxiv.org/abs/1803.02108. arXiv:1803.02108 [cs]. 14
Pith/arXiv arXiv 2018
-
[21]
PlatonicTransformers: A Solid Choice For Equivariance, October 2025
MohammadMohaiminulIslam,RishabhAnand,DavidR.Wessels,FrisodeKruiff,ThijsP.Kuipers,Rex Ying,ClaraI.Sánchez,SharvareeVadgama,GeorgBökman,andErikJ.Bekkers. PlatonicTransformers: A Solid Choice For Equivariance, October 2025. URL http://arxiv.org/abs/2510.03511. arXiv:2510.03511 [cs]
Pith/arXiv arXiv 2025
-
[22]
Spatial Transformer Networks, February 2016
Max Jaderberg, Karen Simonyan, Andrew Zisserman, and Koray Kavukcuoglu. Spatial Transformer Networks, February 2016. URLhttp://arxiv.org/abs/1506.02025. arXiv:1506.02025 [cs]
Pith/arXiv arXiv 2016
-
[23]
Equivariance with Learned Canonicalization Functions, July 2023
Sékou-Oumar Kaba, Arnab Kumar Mondal, Yan Zhang, Yoshua Bengio, and Siamak Ravanbakhsh. Equivariance with Learned Canonicalization Functions, July 2023. URLhttp://arxiv.org/abs/ 2211.06489. arXiv:2211.06489 [cs]
arXiv 2023
-
[24]
Risi Kondor and Shubhendu Trivedi. On the Generalization of Equivariance and Convolution in Neural Networks to the Action of Compact Groups, November 2018. URLhttp://arxiv.org/abs/1802. 03690. arXiv:1802.03690 [stat]
Pith/arXiv arXiv 2018
-
[25]
Clebsch-Gordan Nets: a Fully Fourier Space Spherical Convolutional Neural Network, November 2018
Risi Kondor, Zhen Lin, and Shubhendu Trivedi. Clebsch-Gordan Nets: a Fully Fourier Space Spherical Convolutional Neural Network, November 2018. URLhttp://arxiv.org/abs/1806. 09231. arXiv:1806.09231 [stat]
Pith/arXiv arXiv 2018
-
[26]
A Geometric Approach to Steerable Convolutions, October 2025
Soumyabrata Kundu and Risi Kondor. A Geometric Approach to Steerable Convolutions, October 2025. URLhttp://arxiv.org/abs/2510.18813. arXiv:2510.18813 [cs]
arXiv 2025
-
[27]
Steerable Transformers for Volumetric Data, October 2025
Soumyabrata Kundu and Risi Kondor. Steerable Transformers for Volumetric Data, October 2025. URL http://arxiv.org/abs/2405.15932. arXiv:2405.15932 [cs]
arXiv 2025
-
[28]
Invariant and Equivariant Graph Networks, April 2019
Haggai Maron, Heli Ben-Hamu, Nadav Shamir, and Yaron Lipman. Invariant and Equivariant Graph Networks, April 2019. URLhttp://arxiv.org/abs/1812.09902. arXiv:1812.09902 [cs]
Pith/arXiv arXiv 2019
-
[29]
Octic Vision Transformers: Quicker ViTs Through Equivariance, September 2025
David Nordström, Johan Edstedt, Fredrik Kahl, and Georg Bökman. Octic Vision Transformers: Quicker ViTs Through Equivariance, September 2025. URLhttp://arxiv.org/abs/2505.15441. arXiv:2505.15441 [cs]
arXiv 2025
-
[30]
DINOv2: Learning Robust Visual Features without Supervision, February 2024
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Lab...
Pith/arXiv arXiv 2024
-
[31]
A characterization theorem for equivariant networks with point-wise activations
Marco Pacini, Xiaowen Dong, Bruno Lepri, and Gabriele Santin. A characterization theorem for equivariant networks with point-wise activations. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=79FVDdfoSR
2024
-
[32]
On universality classes of equivariantnetworks
Marco Pacini, Gabriele Santin, Bruno Lepri, and Shubhendu Trivedi. On universality classes of equivariantnetworks. InTheThirty-ninthAnnualConferenceonNeuralInformationProcessingSystems,
-
[33]
URLhttps://openreview.net/forum?id=V4YAS7NLXi
-
[34]
Universal Equivariant Multilayer Perceptrons
Siamak Ravanbakhsh. Universal Equivariant Multilayer Perceptrons. InProceedings of the 37th International Conference on Machine Learning, pages 7996–8006. PMLR, November 2020. URL https://proceedings.mlr.press/v119/ravanbakhsh20a.html. 15
2020
-
[35]
E(n) Equivariant Graph Neural Networks, February 2022
Victor Garcia Satorras, Emiel Hoogeboom, and Max Welling. E(n) Equivariant Graph Neural Networks, February 2022. URLhttp://arxiv.org/abs/2102.09844. arXiv:2102.09844 [cs]
arXiv 2022
-
[36]
Graduate Texts in Mathematics
Jean-Pierre Serre.Linear representations of finite groups. Graduate Texts in Mathematics. Springer, New York, NY, September 1977
1977
-
[37]
Shawe-Taylor
J. Shawe-Taylor. Building symmetries into feedforward networks. In1989 First IEE International Conference on Artificial Neural Networks, (Conf. Publ. No. 313), pages 158–162, October 1989. URL https://ieeexplore.ieee.org/document/51951
1989
-
[38]
Equivariant Transformer Networks, May 2019
Kai Sheng Tai, Peter Bailis, and Gregory Valiant. Equivariant Transformer Networks, May 2019. URL http://arxiv.org/abs/1901.11399. arXiv:1901.11399 [cs]
Pith/arXiv arXiv 2019
-
[39]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention Is All You Need, December 2017. URLhttp: //arxiv.org/abs/1706.03762. arXiv:1706.03762 [cs]
Pith/arXiv arXiv 2017
-
[40]
Veeling, Jasper Linmans, Jim Winkens, Taco Cohen, and Max Welling
Bastiaan S. Veeling, Jasper Linmans, Jim Winkens, Taco Cohen, and Max Welling. Rotation Equivariant CNNs for Digital Pathology, June 2018. URLhttp://arxiv.org/abs/1806.03962. arXiv:1806.03962 [cs]
Pith/arXiv arXiv 2018
-
[41]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5294–5306, June 2025
2025
-
[42]
General $E(2)$-Equivariant Steerable CNNs, April 2021
Maurice Weiler and Gabriele Cesa. General $E(2)$-Equivariant Steerable CNNs, April 2021. URL http://arxiv.org/abs/1911.08251. arXiv:1911.08251 [cs]
arXiv 2021
-
[43]
3D Steerable CNNs: Learning Rotationally Equivariant Features in Volumetric Data, October 2018
Maurice Weiler, Mario Geiger, Max Welling, Wouter Boomsma, and Taco Cohen. 3D Steerable CNNs: Learning Rotationally Equivariant Features in Volumetric Data, October 2018. URLhttp: //arxiv.org/abs/1807.02547. arXiv:1807.02547 [cs]
Pith/arXiv arXiv 2018
-
[44]
Representation theory and invariant neural networks
Jeffrey Wood and John Shawe-Taylor. Representation theory and invariant neural networks. Discrete Applied Mathematics, 69(1):33–60, 1996. ISSN 0166-218X. doi: https://doi.org/10. 1016/0166-218X(95)00075-3. URL https://www.sciencedirect.com/science/article/pii/ 0166218X95000753
1996
-
[45]
$E(2)$-EquivariantVisionTransformer,July2023
RenjunXu,KaifanYang,KeLiu,andFengxiangHe. $E(2)$-EquivariantVisionTransformer,July2023. URLhttp://arxiv.org/abs/2306.06722. arXiv:2306.06722 [cs]
-
[46]
Xuan Zhang, Limei Wang, Jacob Helwig, Youzhi Luo, Cong Fu, Yaochen Xie, Meng Liu, Yuchao Lin, Zhao Xu, Keqiang Yan, Keir Adams, Maurice Weiler, Xiner Li, Tianfan Fu, Yucheng Wang, Alex Strasser, Haiyang Yu, YuQing Xie, Xiang Fu, Shenglong Xu, Yi Liu, Yuanqi Du, Alexandra Saxton, Hongyi Ling, Hannah Lawrence, Hannes Stärk, Shurui Gui, Carl Edwards, Nichola...
-
[47]
PatternNet: A Benchmark Dataset for Performance Evaluation of Remote Sensing Image Retrieval
Weixun Zhou, Shawn Newsam, Congmin Li, and Zhenfeng Shao. PatternNet: A Benchmark Dataset for Performance Evaluation of Remote Sensing Image Retrieval.ISPRS Journal of Photogrammetry and Remote Sensing, 145:197–209, November 2018. ISSN 09242716. doi: 10.1016/j.isprsjprs.2018.01.004. URLhttp://arxiv.org/abs/1706.03424. arXiv:1706.03424 [cs]. A Discrete sub...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/j.isprsjprs.2018.01.004 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.