An Empirical Analysis of Factual Errors in Human-Written Text and its Application
Pith reviewed 2026-06-29 04:39 UTC · model grok-4.3
The pith
Newspaper corrections yield a taxonomy of human factual errors on which even top LLMs reach only 52% F1.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
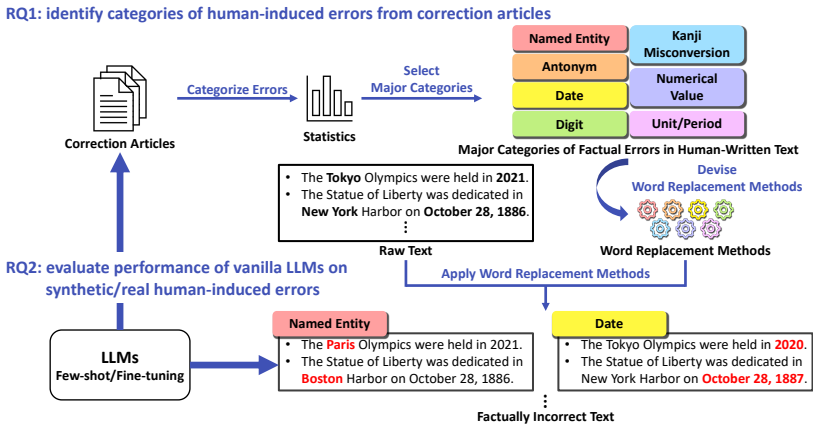
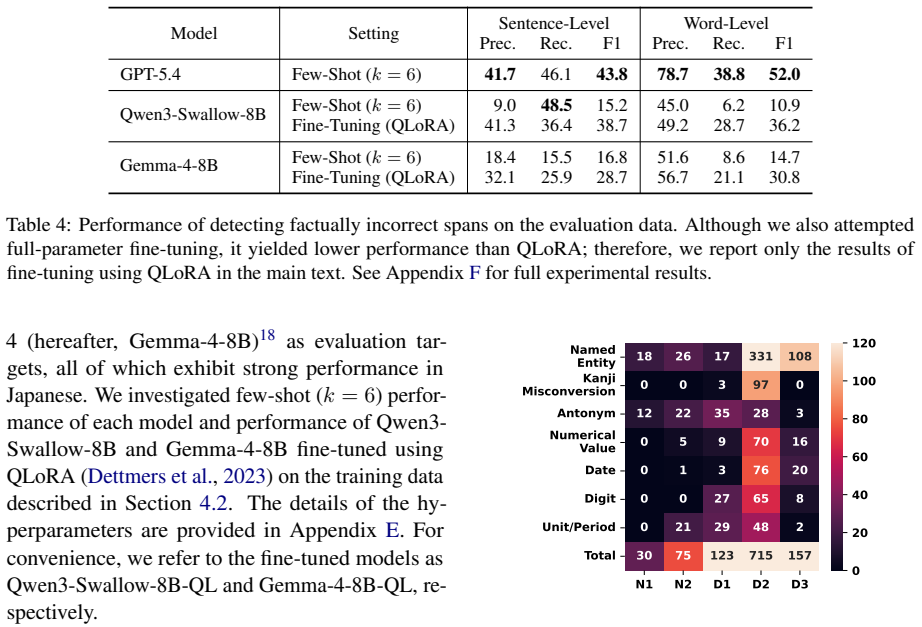
By analyzing corrections of newspaper articles, the authors distill a taxonomy of human-induced factual errors that includes characteristic categories such as kanji misconversions and numeral classifier errors not emphasized in hallucination benchmarks. They generate synthesized realistic test cases from this taxonomy and evaluate vanilla LLMs on both the synthetic data and real corrections. Even high-performance models such as GPT-5.4 reach only 52% word-level F1 on the synthetic evaluation data, and further analysis by detection difficulty reveals the present limits of factual error detection for human-written text.
What carries the argument
Taxonomy of human-induced factual errors distilled from newspaper article corrections, which supplies the categories and patterns used to synthesize realistic test cases for LLM evaluation.
If this is right
- Existing hallucination benchmarks miss error types that appear in human text.
- Vanilla LLMs have limited ability to detect factual errors in human-written material.
- Detection performance varies systematically with difficulty, indicating where targeted improvements are needed.
- The taxonomy supplies a concrete method for constructing realistic evaluation data for factual error detection.
Where Pith is reading between the lines
- Writing-assistance tools could embed the identified error patterns to flag likely factual slips before publication.
- The same correction-analysis method could be applied to other human text domains such as academic papers or legal documents.
- Low baseline performance may motivate training specialized detectors rather than relying on general-purpose LLMs.
- If the taxonomy proves stable, it could guide the design of training data that reduces the same error types in generated text.
Load-bearing premise
Corrections printed in newspapers supply a representative sample of human factual errors that can be turned into a general taxonomy and into synthetic test cases.
What would settle it
A new model that scores substantially above 52% word-level F1 on the synthetic cases, or a large corpus of human factual errors whose distribution falls outside the reported taxonomy categories, would falsify the claim that the task is difficult and that the taxonomy is broadly useful.
Figures



read the original abstract
Factual Error Detection (FED), which is the task of identifying factually incorrect spans in a given text, has long been recognized as an important research problem. However, with the rapid rise of large language models (LLMs), research attention has shifted toward factual errors specific to LLM-generated text (hallucinations) and their detection. As a result, the detection of factual errors in human-written text has been relatively neglected. To address this gap, we first distill a taxonomy of human-induced factual errors by analyzing corrections of newspaper articles, a representative source of text that is guaranteed to be human-written and contains few grammatical errors. Our analysis revealed that there are characteristic categories such as kanji misconversions and numeral classifier errors, which are not focused in existing hallucination benchmarks. Based on the taxonomy, we then evaluate the FED capability of vanilla LLMs on synthesized realistic test cases and real corrections. Experimental results demonstrated that even high-performance LLMs such as GPT-5.4 achieved only word-level F1 score of 52% on the synthetic evaluation data, highlighting the task difficulty. Furthermore, a detailed analysis by detection difficulty revealed the current state of FED.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript distills a taxonomy of human-induced factual errors by analyzing corrections from newspaper articles, synthesizes realistic test cases from this taxonomy (including categories such as kanji misconversions and numeral classifier errors), and evaluates vanilla LLMs on factual error detection (FED) for human-written text. It reports that even high-performance models such as GPT-5.4 achieve only 52% word-level F1 on the synthetic evaluation data, and provides a detailed analysis by detection difficulty to highlight the task's inherent challenges relative to LLM hallucination detection.
Significance. If the taxonomy and evaluation hold, the work is significant for filling a gap in FED research by focusing on human-written text rather than LLM hallucinations, introducing language-specific error categories absent from existing benchmarks, and demonstrating a performance ceiling for current models. The use of real newspaper corrections as the basis for synthesis is a concrete strength that enables falsifiable claims about task difficulty.
major comments (3)
- [Abstract] Abstract: The reported word-level F1 score of 52% for GPT-5.4 is presented without any information on the size of the synthetic evaluation dataset, the process used to annotate or verify ground-truth error spans, or statistical significance testing. This omission directly undermines the ability to evaluate the reliability of the central claim that the task is inherently difficult.
- [Taxonomy construction] Taxonomy construction (likely §3): The taxonomy is derived exclusively from newspaper article corrections with no cross-corpus validation or comparison against other human-written domains (e.g., scientific papers, social media, or technical reports). Because the representativeness assumption is load-bearing for the generalizability of the synthesized test cases and the measured 52% F1 ceiling, this requires explicit justification or additional experiments.
- [Evaluation] Evaluation section: The manuscript states that models were evaluated on both synthesized data and real corrections, yet provides insufficient detail on how real corrections were converted into test instances (e.g., span identification protocol) or on the quantitative comparison between synthetic and real performance. This gap affects the detailed analysis by detection difficulty.
minor comments (2)
- [Abstract and §3] Clarify the exact model identifier 'GPT-5.4' (possible typo or internal name) and list all taxonomy categories with at least one concrete example from the newspaper corrections.
- [Synthetic data generation] Ensure that the synthetic data generation procedure is described with sufficient reproducibility details, including any prompting strategies or filtering steps.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond point-by-point to the major comments below, with revisions planned where they strengthen clarity without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported word-level F1 score of 52% for GPT-5.4 is presented without any information on the size of the synthetic evaluation dataset, the process used to annotate or verify ground-truth error spans, or statistical significance testing. This omission directly undermines the ability to evaluate the reliability of the central claim that the task is inherently difficult.
Authors: The abstract summarizes the key result, while the manuscript body details the synthetic dataset construction (§4), the expert annotation and verification protocol for ground-truth spans (§3), and significance testing in the experimental results. We will revise the abstract to include a concise reference to evaluation scale and reliability measures so the central claim is better supported on first reading. revision: yes
-
Referee: [Taxonomy construction] Taxonomy construction (likely §3): The taxonomy is derived exclusively from newspaper article corrections with no cross-corpus validation or comparison against other human-written domains (e.g., scientific papers, social media, or technical reports). Because the representativeness assumption is load-bearing for the generalizability of the synthesized test cases and the measured 52% F1 ceiling, this requires explicit justification or additional experiments.
Authors: Newspapers were chosen because they supply verified human-written corrections with minimal grammatical noise, as stated in the introduction and §2. We will add an explicit limitations subsection acknowledging the single-source derivation and discussing why many error categories (e.g., numeral classifier mistakes) plausibly generalize, while noting that cross-domain experiments would require new correction corpora that are not currently available. revision: partial
-
Referee: [Evaluation] Evaluation section: The manuscript states that models were evaluated on both synthesized data and real corrections, yet provides insufficient detail on how real corrections were converted into test instances (e.g., span identification protocol) or on the quantitative comparison between synthetic and real performance. This gap affects the detailed analysis by detection difficulty.
Authors: Section 4.2 already outlines the conversion of real corrections via direct span extraction from published notices. We will expand this description with the exact span identification steps and add a side-by-side quantitative comparison of model performance on synthetic versus real instances to better support the difficulty analysis. revision: yes
Circularity Check
No circularity: purely empirical analysis without derivation or self-referential reduction
full rationale
The paper conducts an empirical study: it analyzes newspaper corrections to extract error categories, builds a taxonomy from that source, synthesizes test cases, and reports LLM performance (e.g., 52% F1). No equations, fitted parameters renamed as predictions, self-citation load-bearing premises, or ansatzes appear. The central claims rest on direct observation and external evaluation rather than reducing to the paper's own inputs by construction. Representativeness of newspaper data is an external-validity assumption, not a circularity pattern.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Newspaper article corrections are representative of human-written factual errors with few grammatical errors.
Reference graph
Works this paper leans on
-
[1]
Zeyuan Allen-Zhu and Yuanzhi Li. 2024. https://dl.acm.org/doi/10.5555/3692070.3692115 Physics of language models: part 3.1, knowledge storage and extraction . In Proceedings of the 41st International Conference on Machine Learning, ICML'24. JMLR.org
-
[2]
Isabelle Augenstein, Christina Lioma, Dongsheng Wang, Lucas Chaves Lima, Casper Hansen, Christian Hansen, and Jakob Grue Simonsen. 2019. https://doi.org/10.18653/v1/D19-1475 M ulti FC : A real-world multi-domain dataset for evidence-based fact checking of claims . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing an...
-
[3]
Christopher Bryant, Zheng Yuan, Muhammad Reza Qorib, Hannan Cao, Hwee Tou Ng, and Ted Briscoe. 2023. https://doi.org/10.1162/coli_a_00478 Grammatical error correction: A survey of the state of the art . Computational Linguistics, pages 643--701
-
[4]
Jiangjie Chen, Rui Xu, Wenxuan Zeng, Changzhi Sun, Lei Li, and Yanghua Xiao. 2023. https://doi.org/10.1609/aaai.v37i11.26485 Converge to the truth: factual error correction via iterative constrained editing . In Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial...
-
[5]
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/file/1feb87871436031bdc0f2beaa62a049b-Paper-Conference.pdf QL o RA : E fficient F inetuning of Q uantized LLM s . In Advances in Neural Information Processing Systems, volume 36, pages 10088--10115. Curran Associates, Inc
2023
-
[6]
Wanyu Du, Vipul Raheja, Dhruv Kumar, Zae Myung Kim, Melissa Lopez, and Dongyeop Kang. 2022. https://doi.org/10.18653/v1/2022.acl-long.250 Understanding iterative revision from human-written text . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3573--3590, Dublin, Ireland. Associati...
-
[7]
Farima Fatahi Bayat, Kun Qian, Benjamin Han, Yisi Sang, Anton Belyy, Samira Khorshidi, Fei Wu, Ihab Ilyas, and Yunyao Li. 2023. https://doi.org/10.18653/v1/2023.emnlp-demo.10 FLEEK : Factual error detection and correction with evidence retrieved from external knowledge . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Proces...
-
[8]
Kazuki Fujii, Taishi Nakamura, Mengsay Loem, Hiroki Iida, Masanari Ohi, Kakeru Hattori, Hirai Shota, Sakae Mizuki, Rio Yokota, and Naoaki Okazaki. 2024. https://openreview.net/forum?id=TQdd1VhWbe Continual pre-training for cross-lingual LLM adaptation: Enhancing japanese language capabilities . In First Conference on Language Modeling
2024
-
[9]
Xingwei He, Qianru Zhang, A-Long Jin, Jun Ma, Yuan Yuan, and Siu Ming Yiu. 2024. https://doi.org/10.1609/aaai.v38i16.29778 Improving factual error correction by learning to inject factual errors . Proceedings of the AAAI Conference on Artificial Intelligence, 38(16):18197--18205
-
[10]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. 2025. https://doi.org/10.1145/3703155 A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions . ACM Trans. Inf. Syst., 43(2)
-
[11]
Yichen Jiang, Shikha Bordia, Zheng Zhong, Charles Dognin, Maneesh Singh, and Mohit Bansal. 2020. https://doi.org/10.18653/v1/2020.findings-emnlp.309 H o V er: A dataset for many-hop fact extraction and claim verification . In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3441--3460, Online. Association for Computational Linguistics
-
[12]
Neema Kotonya and Francesca Toni. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.623 Explainable automated fact-checking for public health claims . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 7740--7754, Online. Association for Computational Linguistics
-
[13]
Junyi Li, Jie Chen, Ruiyang Ren, Xiaoxue Cheng, Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. 2024. https://doi.org/10.18653/v1/2024.acl-long.586 The dawn after the dark: An empirical study on factuality hallucination in large language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), p...
-
[14]
Junyi Li, Xiaoxue Cheng, Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.397 H alu E val: A large-scale hallucination evaluation benchmark for large language models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6449--6464, Singapore. Association for Computation...
-
[15]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. https://doi.org/10.18653/v1/2022.acl-long.229 T ruthful QA : Measuring how models mimic human falsehoods . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214--3252, Dublin, Ireland. Association for Computational Linguistics
-
[16]
Huanhuan Ma, Weizhi Xu, Yifan Wei, Liuji Chen, Liang Wang, Qiang Liu, Shu Wu, and Liang Wang. 2024. https://doi.org/10.18653/v1/2024.findings-acl.556 EX - FEVER : A dataset for multi-hop explainable fact verification . In Findings of the Association for Computational Linguistics: ACL 2024, pages 9340--9353, Bangkok, Thailand. Association for Computational...
-
[17]
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. https://proceedings.neurips.cc/paper_files/paper/2013/file/9aa42b31882ec039965f3c4923ce901b-Paper.pdf D istributed R epresentations of W ords and P hrases and their C ompositionality . In Advances in Neural Information Processing Systems, volume 26. Curran Associates, Inc
2013
-
[18]
Abhika Mishra, Akari Asai, Vidhisha Balachandran, Yizhong Wang, Graham Neubig, Yulia Tsvetkov, and Hannaneh Hajishirzi. 2024. https://openreview.net/forum?id=dJMTn3QOWO Fine-grained hallucination detection and editing for language models . In First Conference on Language Modeling
2024
-
[19]
Rojas-Barahona, Pei-Hao Su, David Vandyke, Tsung-Hsien Wen, and Steve Young
Nikola Mrk s i \'c , Diarmuid \'O S \'e aghdha, Blaise Thomson, Milica Ga s i \'c , Lina M. Rojas-Barahona, Pei-Hao Su, David Vandyke, Tsung-Hsien Wen, and Steve Young. 2016. https://doi.org/10.18653/v1/N16-1018 Counter-fitting word vectors to linguistic constraints . In Proceedings of the 2016 Conference of the North A merican Chapter of the Association ...
-
[20]
Fabio Petroni, Tim Rockt \"a schel, Sebastian Riedel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, and Alexander Miller. 2019. https://doi.org/10.18653/v1/D19-1250 Language models as knowledge bases? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Process...
-
[21]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. https://dl.acm.org/doi/abs/10.5555/3455716.3455856 Exploring the limits of transfer learning with a unified text-to-text transformer . Journal of Machine Learning Research, 21(140):1--67
-
[22]
Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. 2020. https://doi.org/10.18653/v1/2020.acl-main.442 Beyond accuracy: Behavioral testing of NLP models with C heck L ist . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4902--4912, Online. Association for Computational Linguistics
-
[23]
Adam Roberts, Colin Raffel, and Noam Shazeer. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.437 How much knowledge can you pack into the parameters of a language model? In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 5418--5426, Online. Association for Computational Linguistics
-
[24]
James Thorne and Andreas Vlachos. 2021. https://doi.org/10.18653/v1/2021.acl-long.256 Evidence-based factual error correction . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 3298--3309, Online. Association ...
-
[25]
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. 2018. https://doi.org/10.18653/v1/N18-1074 FEVER : a large-scale dataset for fact extraction and VER ification . In Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Pap...
work page internal anchor Pith review doi:10.18653/v1/n18-1074 2018
-
[26]
David Wadden, Shanchuan Lin, Kyle Lo, Lucy Lu Wang, Madeleine van Zuylen, Arman Cohan, and Hannaneh Hajishirzi. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.609 Fact or fiction: Verifying scientific claims . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 7534--7550, Online. Association for Com...
-
[27]
Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. 2021. https://doi.org/10.18653/v1/2021.naacl-main.41 m T 5: A massively multilingual pre-trained text-to-text transformer . In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.