Can AI Draw Science? A Benchmark for Evaluating Scientific Figure Generation by Text-to-Image and Multimodal Models
Pith reviewed 2026-06-30 01:03 UTC · model grok-4.3
The pith
A domain-specific system outperforms general text-to-image models at generating usable scientific figures across eight types.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A domain-specific system for scientific figure generation substantially outperforms general-purpose text-to-image and multimodal models on every dimension and figure type in the SciDraw-Bench pilot, with the largest gaps on semantic correctness and convention adherence.
What carries the argument
SciDraw-Bench, a benchmark of structured tasks each pairing a natural-language prompt with a machine-checkable specification of labels, relations, components, conventions, and negative constraints, evaluated through a four-dimensional protocol including OCR text fidelity and VLM semantic correctness.
If this is right
- Text fidelity measured by OCR-based label recall and character error rate remains the hardest dimension for all systems evaluated.
- The domain-specific system shows its strongest advantages on semantic correctness and convention adherence.
- The benchmark covers eight figure types including mechanism diagrams, experimental-design schematics, conceptual frameworks, and graphical abstracts across ten disciplines.
- A code-to-figure baseline is outlined as a planned extension for future comparison.
Where Pith is reading between the lines
- Adoption of the benchmark could allow targeted improvement of models by identifying specific failure modes in relations and conventions.
- The ongoing human validation could either confirm or require revision of the VLM judging protocol for semantic correctness.
- Similar machine-checkable specification approaches might extend to evaluating generated diagrams in engineering or medical domains.
Load-bearing premise
The machine-checkable specifications paired with each prompt, combined with VLM-based semantic correctness judgments, accurately reflect what makes a generated scientific figure usable.
What would settle it
Completion of the planned human-rating validation in which expert usability ratings fail to correlate with the automated scores on semantic correctness or convention adherence.
Figures

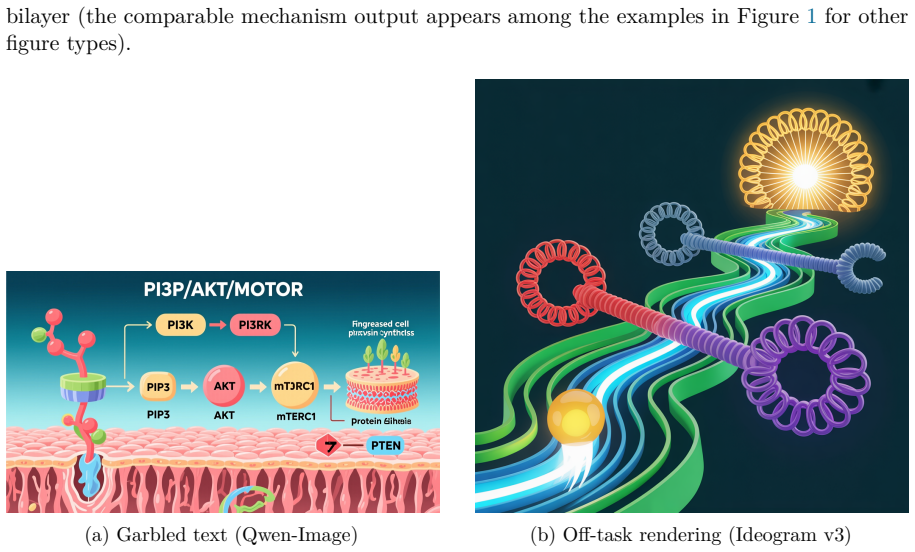
read the original abstract
Text-to-image and multimodal generative models are increasingly used to produce scientific figures such as mechanism diagrams, experimental-design schematics, conceptual frameworks, and graphical abstracts. Yet existing image-generation benchmarks (e.g., GenEval, T2I-CompBench, DPG-Bench) evaluate natural images and measure compositionality, object counting, or photorealism. None of them measure what makes a generated scientific figure usable: correct and legible text labels, faithful depiction of entities and their relations, coherent diagrammatic structure, and adherence to disciplinary drawing conventions. We introduce SciDraw-Bench, a benchmark of 32 structured scientific-figure generation tasks spanning eight figure types and ten disciplines, where each task pairs a natural-language prompt with a machine-checkable specification of required labels, relations, components, conventions, and negative constraints. We propose a four-dimensional evaluation protocol: Text Fidelity (OCR-based label recall and character error rate), Semantic Correctness (vision-language-model judging against the specification), Structural Quality, and Convention Adherence, together with a meta-evaluation protocol and a preliminary inter-judge reliability analysis (human-rating validation is ongoing). We evaluate a domain-specific system, SciDraw AI, against representative general-purpose text-to-image models, and outline a code-to-figure baseline as a planned extension. In a pilot over all eight figure types, the domain-specific system substantially outperforms the general-purpose baselines on every dimension and figure type, with the largest gaps on semantic correctness and convention adherence; text fidelity remains the hardest dimension for all systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SciDraw-Bench, a benchmark of 32 structured scientific-figure generation tasks spanning eight figure types and ten disciplines. Each task pairs a natural-language prompt with a machine-checkable specification of required labels, relations, components, conventions, and negative constraints. It defines a four-dimensional evaluation protocol (Text Fidelity via OCR, Semantic Correctness via VLM judgment against the spec, Structural Quality, and Convention Adherence) together with a meta-evaluation protocol. A pilot evaluation over all eight figure types reports that a domain-specific system (SciDraw AI) substantially outperforms representative general-purpose text-to-image models on every dimension and figure type, with the largest gaps on semantic correctness and convention adherence; text fidelity is identified as the hardest dimension for all systems.
Significance. If the empirical claims hold after validation, the benchmark fills a documented gap left by existing compositionality and photorealism benchmarks (GenEval, T2I-CompBench, DPG-Bench) by targeting the specific requirements of usable scientific figures. The machine-checkable specifications paired with each prompt constitute a concrete, reproducible strength that could support future automated evaluation. The work is therefore potentially significant for the growing use of generative models in scientific communication, provided the VLM-based scores are shown to track human assessments of usability.
major comments (1)
- [Abstract / Evaluation Protocol] Abstract and Evaluation Protocol section: the central claim that the domain-specific system 'substantially outperforms' the baselines on semantic correctness (and that this is the largest gap) rests on VLM judgments against the machine-checkable specifications. The abstract explicitly states that 'human-rating validation is ongoing,' so the reported performance differences on the 32 tasks have not yet been shown to reflect actual scientific usability. This is load-bearing for the benchmark's claimed value and for the pilot results.
minor comments (2)
- The manuscript would benefit from an explicit statement of how the 32 tasks were sampled to ensure coverage across the ten disciplines and eight figure types; a table or appendix listing the distribution would improve reproducibility.
- The planned code-to-figure baseline is mentioned only as a future extension; adding even preliminary numbers for it in the current pilot would make the comparison more complete without changing the scope.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation protocol and its implications for the pilot results. We address the major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [Abstract / Evaluation Protocol] Abstract and Evaluation Protocol section: the central claim that the domain-specific system 'substantially outperforms' the baselines on semantic correctness (and that this is the largest gap) rests on VLM judgments against the machine-checkable specifications. The abstract explicitly states that 'human-rating validation is ongoing,' so the reported performance differences on the 32 tasks have not yet been shown to reflect actual scientific usability. This is load-bearing for the benchmark's claimed value and for the pilot results.
Authors: We agree that the human-rating validation is essential to establish that VLM judgments against the machine-checkable specifications align with human assessments of scientific usability, and that the abstract's statement that this validation is ongoing correctly signals the preliminary nature of the pilot. The manuscript already includes a preliminary inter-judge reliability analysis as part of the meta-evaluation protocol. To address this concern directly, we will revise the abstract to qualify the performance claims as preliminary and contingent on completion of the human validation study. We will also expand the Evaluation Protocol section with a dedicated limitations subsection that discusses the current reliance on VLM-based scoring, the design of the meta-evaluation, and the specific steps for the ongoing human study. These changes will ensure the claims are appropriately caveated while retaining the benchmark's core strength in providing reproducible, machine-checkable task specifications. revision: yes
Circularity Check
No circularity: benchmark introduction with empirical pilot evaluation
full rationale
The paper introduces SciDraw-Bench as a set of 32 tasks with machine-checkable specifications and evaluates models on four dimensions using OCR and VLM judgments. No mathematical derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text or abstract. The central claim of outperformance is presented as a preliminary empirical result (human validation ongoing), not as a derivation that reduces to its own inputs by construction. This matches the default expectation of no significant circularity for a benchmark paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-language models can serve as reliable judges of semantic correctness against the machine-checkable specifications
Reference graph
Works this paper leans on
-
[1]
Betker, J., Goh, G., Jing, L., et al. (2023). Improving image generation with better captions (DALL·E 3). OpenAI technical report
2023
-
[2]
Chen, J., Huang, Y., Lv, T., Cui, L., Chen, Q., and Wei, F. (2023). TextDiffuser: Diffusion models as text painters. InAdvances in Neural Information Processing Systems (NeurIPS)
2023
-
[3]
Chen, D. (2026). AI-generated figures in academic publishing: Policies, tools, and practical guidelines. Preprint
2026
- [4]
-
[5]
Ghosh, D., Hajishirzi, H., and Schmidt, L. (2023). GenEval: An object-focused framework for evaluating text-to-image alignment. InAdvances in Neural Information Processing Systems (NeurIPS). 9
2023
-
[6]
Hessel, J., Holtzman, A., Forbes, M., Le Bras, R., and Choi, Y. (2021). CLIPScore: A reference-free evaluation metric for image captioning. InProceedings of EMNLP
2021
-
[7]
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., and Hochreiter, S. (2017). GANs trained by a two time-scale update rule converge to a local Nash equilibrium. InAdvances in Neural Information Processing Systems (NeurIPS)
2017
-
[8]
Hu, X., Wang, R., Fang, Y., et al. (2024). ELLA: Equip diffusion models with LLM for enhanced semantic alignment (DPG-Bench).arXiv preprint arXiv:2403.05135
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Huang, K., Sun, K., Xie, E., Li, Z., and Liu, X. (2023). T2I-CompBench: A comprehensive benchmark for open-world compositional text-to-image generation. InAdvances in Neural Information Processing Systems (NeurIPS)
2023
-
[10]
Lee, T., Yasunaga, M., Meng, C., et al. (2023). Holistic evaluation of text-to-image models (HEIM). InAdvances in Neural Information Processing Systems (NeurIPS)
2023
-
[11]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF CVPR, pages 10684–10695
2022
-
[12]
P., Droettboom, M., and Bourne, P
Rougier, N. P., Droettboom, M., and Bourne, P. E. (2014). Ten simple rules for better figures. PLoS Computational Biology, 10(9):e1003833
2014
-
[13]
Saharia, C., Chan, W., Saxena, S., et al. (2022). Photorealistic text-to-image diffusion models with deep language understanding (Imagen). InAdvances in Neural Information Processing Systems (NeurIPS). SciDraw AI (2025). SciDraw AI: An AI-powered scientific illustration platform. https:// sci-draw.com
2022
-
[14]
Team, G., Anil, R., Borgeaud, S., Wu, Y., et al. (2023). Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Tufte, E. R. (2001).The Visual Display of Quantitative Information. Graphics Press, 2nd edition
2001
-
[16]
Yang, Y., Gui, D., Yuan, Y., et al. (2023). GlyphControl: Glyph conditional control for visual text generation. InAdvances in Neural Information Processing Systems (NeurIPS)
2023
-
[17]
Y., et al
Yu, J., Xu, Y., Koh, J. Y., et al. (2022). Scaling autoregressive models for content-rich text-to-image generation (Parti).Transactions on Machine Learning Research
2022
-
[18]
Zheng, L., Chiang, W.-L., Sheng, Y., et al. (2023). Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems (NeurIPS). A Weight sensitivity We recompute the composite under alternative weightings to confirm that conclusions are not arti- facts of the default weights(0.30, 0.30, 0.20, 0.20). SciDraw AI sc...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.