Spectral phase transitions and trainability in neural network learning dynamics
Pith reviewed 2026-06-30 01:18 UTC · model grok-4.3
The pith
SGD training induces a Baik-Ben Arous-Péchè transition that detaches isolated eigenvalues from the spectral bulk of neural network weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
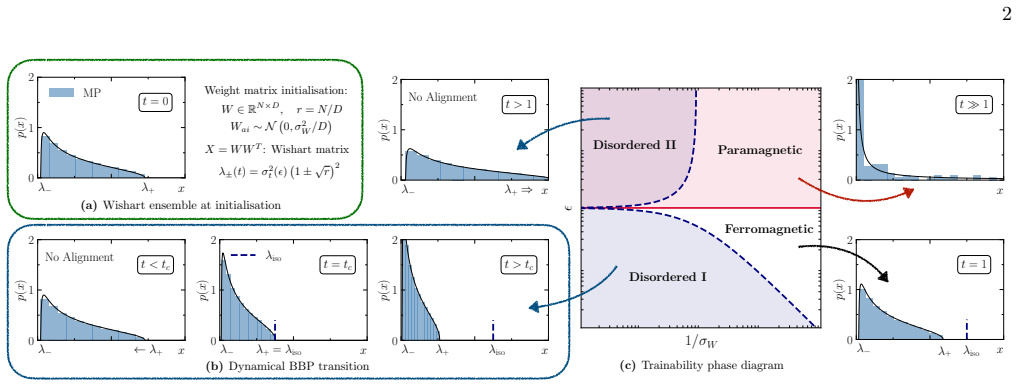
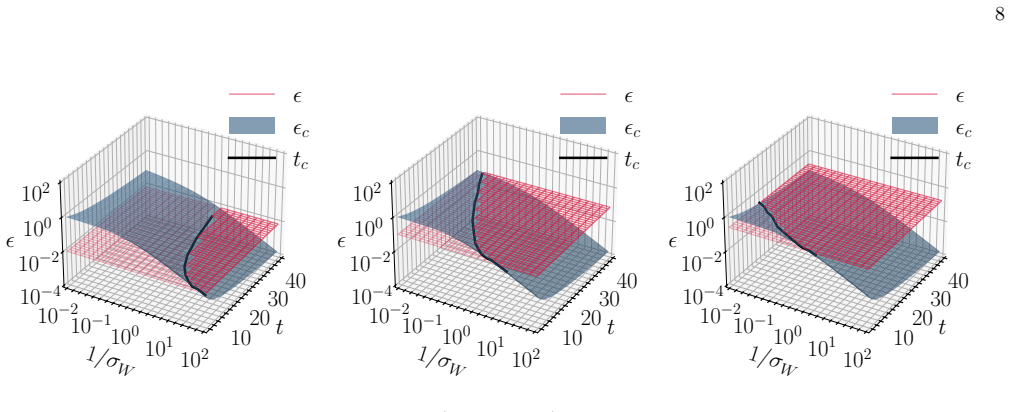
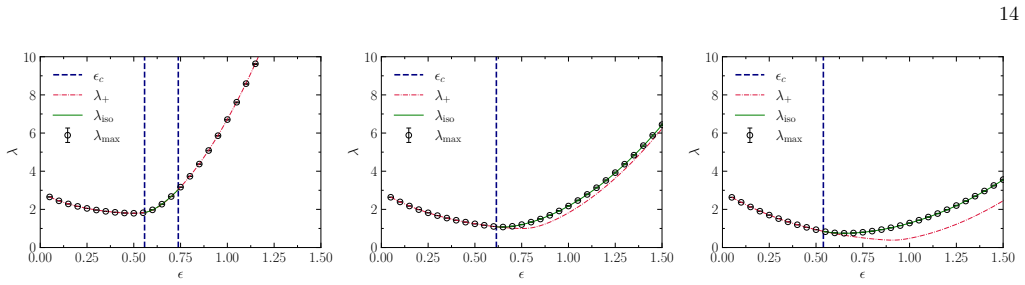
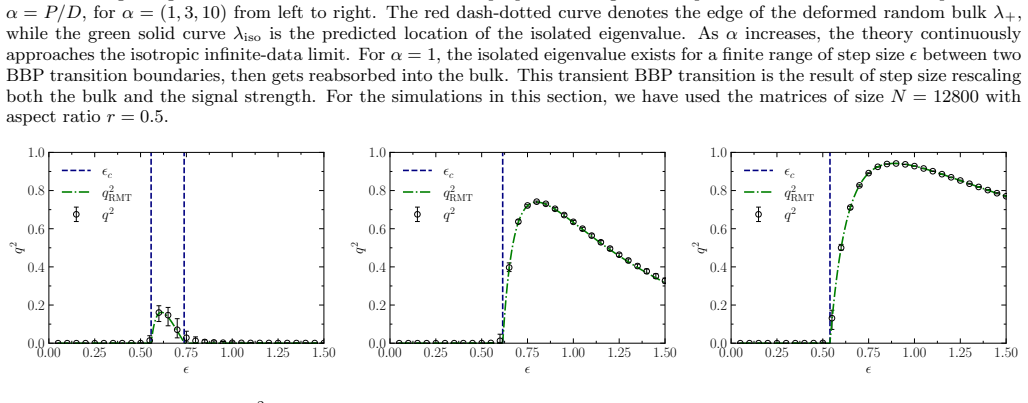
Neural network training is formulated as the stochastic evolution of an initially random matrix ensemble driven by SGD updates that reshape the spectral bulk while amplifying signal strength. This induces a Baik-Ben Arous-Péchè transition during training where isolated eigenvalues detach from the random bulk distribution, providing a dynamical framework for representation formation in high-dimensional learning dynamics. The claim is demonstrated analytically in a solvable linear teacher-student model and supported by simulations in nonlinear settings.
What carries the argument
The stochastic evolution of an initially random matrix ensemble under SGD updates, which produces a Baik-Ben Arous-Péchè transition in the eigenvalue spectrum.
If this is right
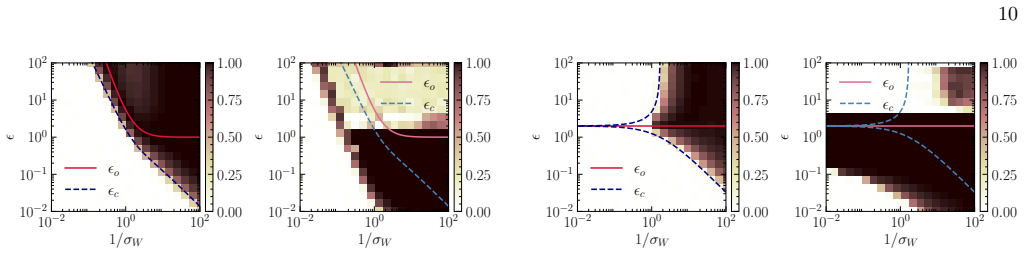
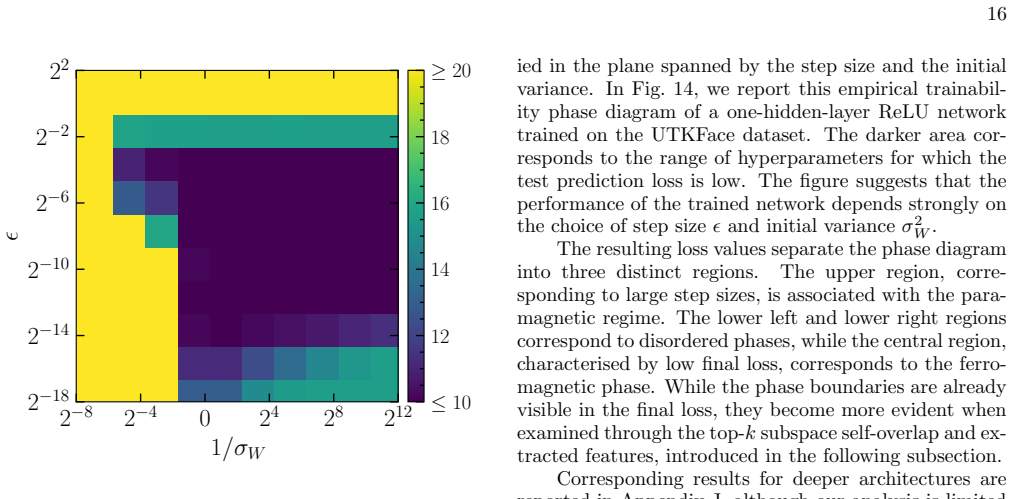
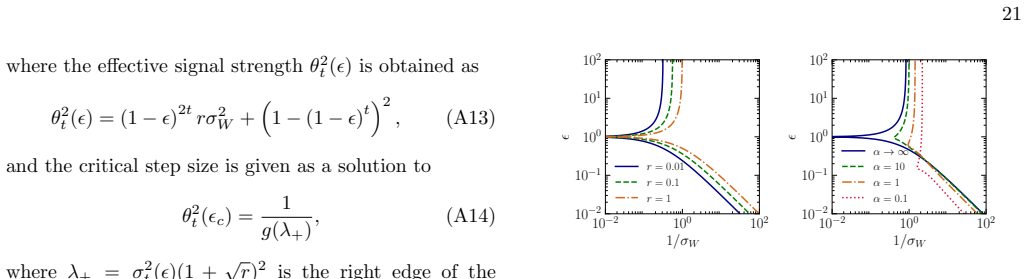
- In the linear teacher-student model the spectral evolution is analytically tractable and produces an explicit phase diagram of trainability governed by learning rate and initial weight variance.
- The same formalism extends beyond the linear regime to nonlinear and stochastic networks.
- Numerical simulations in realistic settings show robust emergence of spectral alignment during training.
- Spectral analysis supplies a unified perspective linking trainability, optimisation hyperparameters, spectral phase transitions and representation learning.
Where Pith is reading between the lines
- If the transition is the operative mechanism, then tracking the largest eigenvalue during training could serve as an early indicator of whether representations are forming.
- The modeling choice implies that other first-order optimizers could be studied by replacing the SGD noise term with the appropriate update statistics.
- Initial weight variance appears as a control parameter for the onset of the transition, suggesting it may be tuned deliberately rather than chosen heuristically.
Load-bearing premise
Neural network weight matrices can be faithfully modeled as the stochastic evolution of an initially random matrix ensemble whose updates are driven by SGD.
What would settle it
In the linear teacher-student model, if the largest eigenvalues remain inside the Marchenko-Pastur bulk for all step sizes and initial variances where the phase diagram predicts a transition, the claimed mechanism is falsified.
Figures






read the original abstract
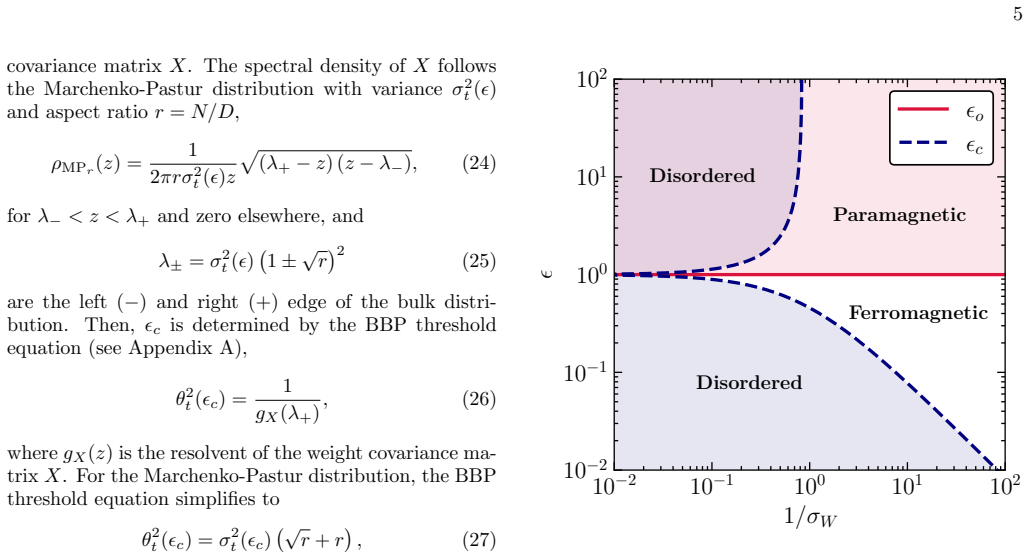
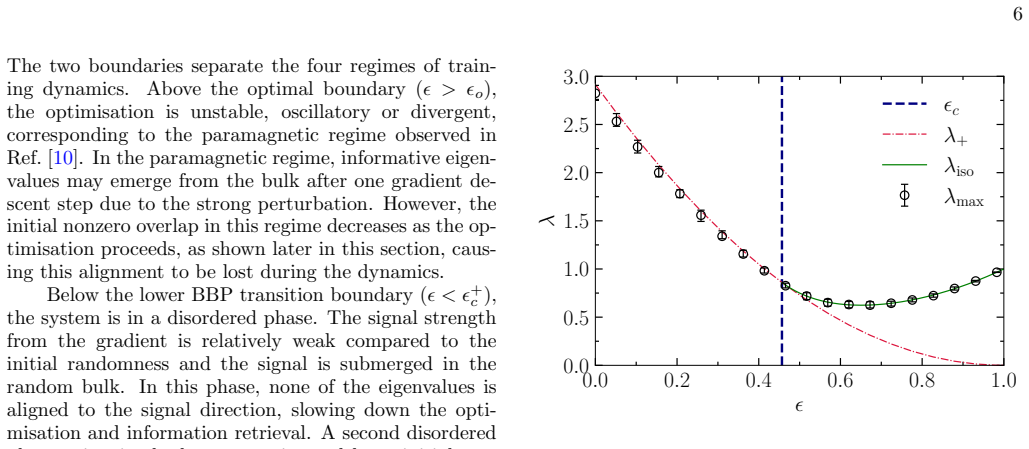
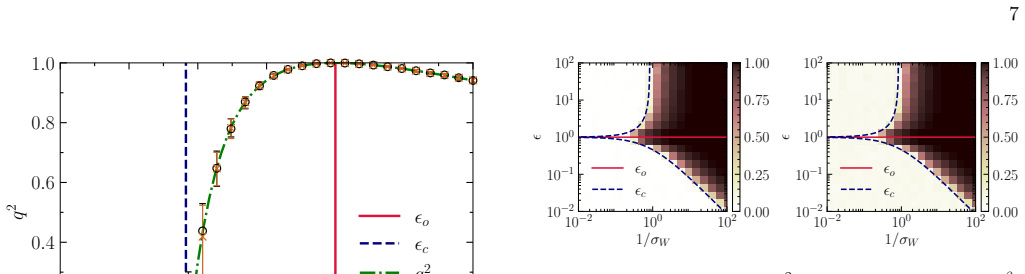
The emergence of low-dimensional structures in the spectra of neural network weight matrices is a common empirical feature of trained models, but the dynamical origin of this phenomenon during learning remains an open problem. We formulate neural network training as the stochastic evolution of an initially random matrix ensemble, driven by stochastic gradient descent (SGD) updates that reshape the spectral bulk while amplifying signal strength. This induces a Baik-Ben Arous-P\'ech\'e (BBP) transition during training, where isolated eigenvalues detach from the random bulk distribution, providing a dynamical framework for representation formation in high-dimensional learning dynamics. We demonstrate this in a solvable linear teacher-student model, where spectral evolution is analytically tractable and a phase diagram of trainability governed by the step size (or learning rate) and initial weight variance is obtained, and subsequently extend our formalism beyond the linear regime to nonlinear and stochastic settings. Numerical simulations in realistic settings support this picture, showing robust emergence of spectral alignment during training. Our results suggest that spectral analysis may provide a unified perspective of stochastic learning dynamics, linking trainability, optimisation hyperparameters, spectral phase transitions, and representation learning in neural networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that SGD training of neural networks can be modeled as the stochastic evolution of an initially random matrix ensemble, where updates reshape the spectral bulk and amplify signal strength, inducing a BBP transition with isolated eigenvalues detaching from the bulk. This is exactly solved in a linear teacher-student model to obtain a phase diagram in learning rate and initial variance, and the formalism is extended to nonlinear and stochastic settings with numerical simulations showing spectral alignment, providing a dynamical framework linking trainability, hyperparameters, and representation learning.
Significance. If the central claim holds, the work offers an analytically tractable RMT-based dynamical explanation for the emergence of low-dimensional spectral structures in trained networks, with the exact linear solution and phase diagram as notable strengths. This could unify perspectives on optimization and representation formation, though the extension beyond linear regimes requires further substantiation to realize this potential.
major comments (2)
- [Abstract] The central claim that SGD updates preserve RMT bulk properties (e.g., Marchenko-Pastur or semicircle) needed for the BBP transition is load-bearing, yet the manuscript provides an exact solution only for the linear teacher-student model; the extension to nonlinear activations and stochastic settings is stated without a derivation showing that the update rule continues to map the ensemble to the required bulk whose edge is crossed at the same critical parameters (see abstract and the paragraph following the linear model solution).
- The modeling assumption that the collection of neural-network weight matrices evolves as a stochastic random-matrix ensemble under SGD is invoked to explain representation formation, but no analysis addresses whether nonlinear activations or mini-batch noise introduce persistent correlations that deform the bulk or alter effective spike strength, undermining applicability outside the linear regime.
minor comments (1)
- [Abstract] The abstract mentions 'subsequently extend our formalism beyond the linear regime' but does not specify the section or equations where this extension is detailed.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments. We respond point-by-point to the major comments below, clarifying the scope of our analytical results and indicating revisions that will be made to address the concerns about extensions beyond the linear regime.
read point-by-point responses
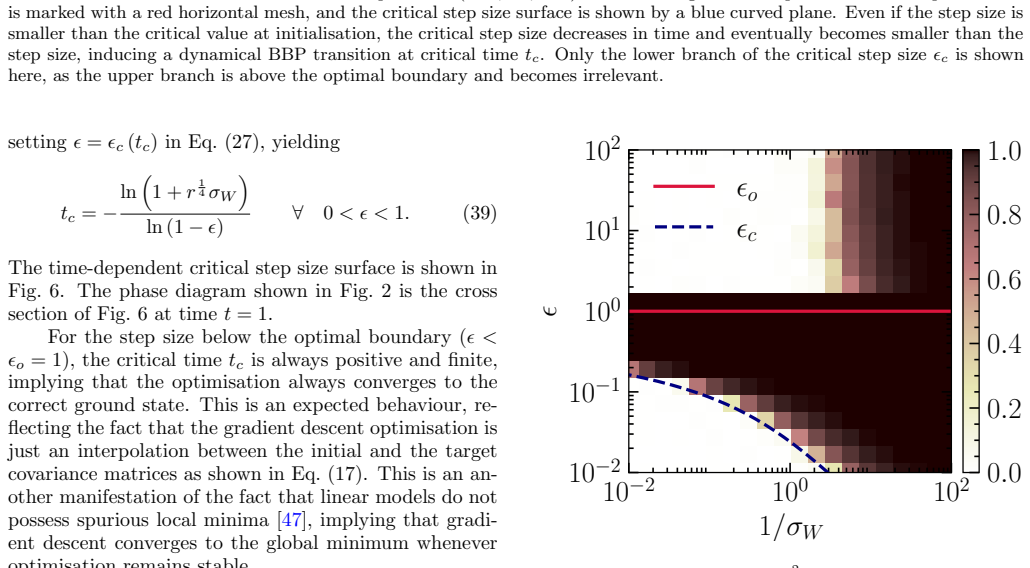
-
Referee: [Abstract] The central claim that SGD updates preserve RMT bulk properties (e.g., Marchenko-Pastur or semicircle) needed for the BBP transition is load-bearing, yet the manuscript provides an exact solution only for the linear teacher-student model; the extension to nonlinear activations and stochastic settings is stated without a derivation showing that the update rule continues to map the ensemble to the required bulk whose edge is crossed at the same critical parameters (see abstract and the paragraph following the linear model solution).
Authors: We agree that the exact analytical solution, including the phase diagram for the BBP transition, is derived only in the linear teacher-student model. The manuscript states that the formalism is extended to nonlinear and stochastic settings on the basis of numerical simulations that demonstrate spectral alignment, but no derivation is provided showing that the update rule preserves the required bulk properties (e.g., Marchenko-Pastur or semicircle) or that the critical parameters remain unchanged. In the revised manuscript we will modify the abstract and the paragraph following the linear-model solution to state explicitly that the BBP transition and phase diagram are rigorously obtained only for the linear case, while numerical evidence in nonlinear networks is consistent with analogous spectral behavior. This revision will remove any implication of an analytical extension. revision: yes
-
Referee: [—] The modeling assumption that the collection of neural-network weight matrices evolves as a stochastic random-matrix ensemble under SGD is invoked to explain representation formation, but no analysis addresses whether nonlinear activations or mini-batch noise introduce persistent correlations that deform the bulk or alter effective spike strength, undermining applicability outside the linear regime.
Authors: This observation is correct. While our simulations in nonlinear architectures exhibit the emergence of isolated eigenvalues consistent with the linear picture, we have not analyzed whether nonlinear activations or mini-batch stochasticity generate persistent correlations capable of deforming the bulk spectrum or modifying effective spike strength. In the revised manuscript we will add a dedicated paragraph in the discussion section that acknowledges this limitation, clarifies that applicability outside the linear regime rests on empirical observation rather than analytical control of the bulk, and identifies the effect of such correlations as an open question for future work. revision: yes
Circularity Check
No significant circularity; linear derivation is independent
full rationale
The paper derives the BBP transition and phase diagram exactly in the solvable linear teacher-student model, with learning rate and initial variance as external control parameters rather than quantities fitted to the observed transition. The extension to nonlinear regimes is presented via numerical simulations showing spectral alignment, without any reduction of the nonlinear case to the linear equations by construction. No self-citations, self-definitional steps, or fitted-input predictions appear in the derivation chain. The initial modeling assumption (weight matrices as SGD-driven random-matrix evolution) is stated explicitly but does not create a circular loop within the analytic results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural-network weight matrices behave as an initially random matrix ensemble whose spectrum is reshaped by SGD updates
Reference graph
Works this paper leans on
-
[1]
(52) The trainability phase diagram after a single update is shown in the left panel of Fig
Hyperbolic tangent For the hyperbolic tangent activation function, ϕ(x) = tanh(x), we have tanh′(x) = 1−tanh 2(x), tanh′′(x) = 2 tanh3(x)−2 tanh(x). (52) The trainability phase diagram after a single update is shown in the left panel of Fig. 8. The hyperbolic tangent function is bounded from above and below, and a large portion of the gradient reaches the...
-
[2]
ReLU For the ReLU activation function, ReLU(x) = xΘ(x), we have ReLU′(x) = Θ(x),ReLU ′′(x) =δ(x),(53) where Θ(x) is the Heaviside function. In this case the functions can be integrated analytically, yielding, ¯µ1 = 1 4 ,¯µ 2 = 1 2 .(54) Following the same steps as above, we determine the trainability phase diagram for ReLU activation, shown in Fig. 9. The...
-
[3]
Low-temperature limit In the limit of low temperature (T→0), the fluctu- ating term on the right-hand side is negligible, and the equation only has a trivial solution, ΣH+HΣ = 0⇒Σ = 0.(91) The weight covariance converges to the correct ground stateX=W ∗W ∗T , which covers the case of full batch update, shown in Sec. II
-
[4]
Random Matrix Theory for Learning 20 and Statistical Physics
High-temperature limit In the high-temperature limit, thermal fluctuations become significant, and the weight fluctuations satisfy Σ =H −1FH −1.(92) Assuming a well-behaved loss function with a compact ground-state manifold, the Hessian is almost surely in- vertible up to a finite number of zero modes [59]. The spectral properties of the weight covariance...
2025
-
[5]
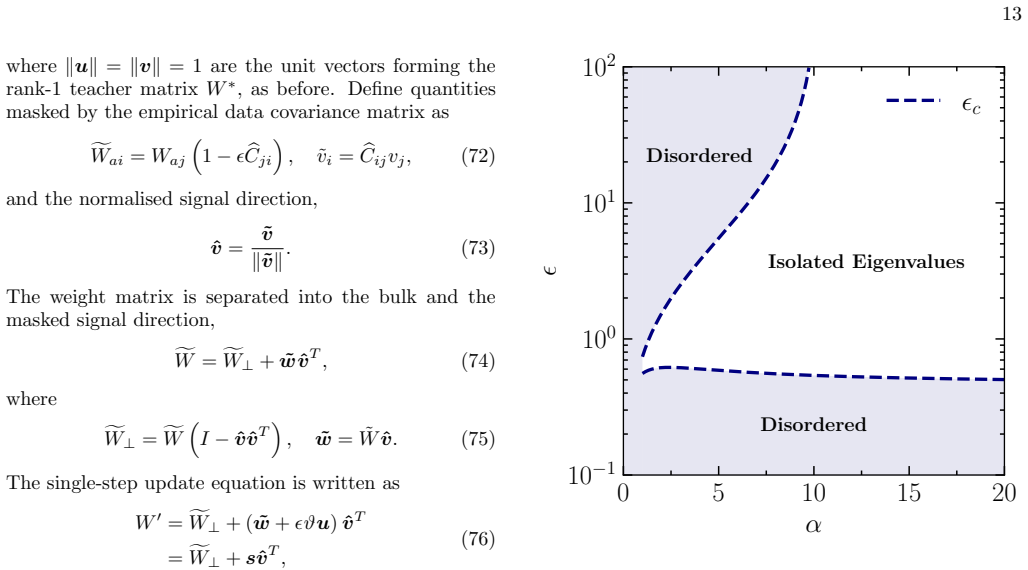
Bulk resolvent The bulk part eX⊥ =fW⊥fW T ⊥ is written explicitly eX⊥ =fW⊥fW T ⊥ =W I−ϵ bC I−ˆvˆvT I−ϵ bC T W T ≃W I−ϵ bC 2 W T , (H2) where the term proportional toˆvˆvT in the second line is neglected as it is a rank-1 correction, which does not alter the bulk spectrum. This is a standard correlated Wishart matrix with temporal correlation [38], where t...
-
[6]
Masked rank-1 signal Denote the bulk matrix resolvent as R⊥(z) = zI− eX⊥ −1 .(H5) Then, using the matrix determinant lemma, det (zI−X ′) = det zI− eX⊥ 1−s T R⊥(z)s ,(H6) the signal equation corresponding to Eq. (26) becomes 1 =s T R⊥(ziso)s.(H7) Using the definition of the masked signals=˜w+ϵϑu, we find 1 =˜wT R⊥(z)˜w+ϵ2ϑ2uT R⊥(z)u.(H8) The second term on...
-
[7]
Sompolinsky, A
H. Sompolinsky, A. Crisanti and H. J. Sommers,Chaos in Random Neural Networks,Physical Review Letters 61(1988) 259–262
1988
-
[8]
C. H. Martin and M. W. Mahoney,Traditional and Heavy-Tailed Self Regularization in Neural Network Models, inProceedings of the 36th International Conference on Machine Learning, pp. 4284–4293, PMLR, 2019.arXiv:1901.08276
Pith/arXiv arXiv 2019
-
[9]
C. H. Martin and M. W. Mahoney,Implicit Self-Regularization in Deep Neural Networks: Evidence from Random Matrix Theory and Implications for Learning,Journal of Machine Learning Research22 (2021) 1–73, [arXiv:1810.01075]
Pith/arXiv arXiv 2021
- [10]
-
[11]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang et al.,LoRA: Low-Rank Adaptation of Large Language Models, inInternational Conference on Learning Representations, 2021.arXiv:2106.09685
Pith/arXiv arXiv 2021
-
[12]
D. Granziol, S. Zohren and S. Roberts,Learning Rates as a Function of Batch Size: A Random Matrix Theory Approach to Neural Network Training,Journal of Machine Learning Research23(2022) 1–65, [arXiv:2006.09092]
arXiv 2022
-
[13]
A. Sclocchi, M. Geiger and M. Wyart,Dissecting the Effects of SGD Noise in Distinct Regimes of Deep Learning, inProceedings of the 40th International Conference on Machine Learning, pp. 30381–30405, PMLR, 2023.arXiv:2301.13703. DOI
arXiv 2023
-
[14]
D. S. Kalra and M. Barkeshli,Phase diagram of early 29 training dynamics in deep networks: Effect of the learning rate, depth, and width, inProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, (Red Hook, NY, USA), pp. 51621–51662, Curran Associates Inc., 2023. arXiv:2302.12250
arXiv 2023
- [15]
-
[16]
C. Park, B. Lucini and G. Aarts,Phase diagram and eigenvalue dynamics of stochastic gradient descent in multilayer neural networks,Mach. Learn. Sci. Tech.6 (2025) 045048, [arXiv:2509.01349]
arXiv 2025
-
[17]
C. Louart, Z. Liao and R. Couillet,A random matrix approach to neural networks,The Annals of Applied Probability28(2018) 1190–1248, [arXiv:1702.05419]
Pith/arXiv arXiv 2018
-
[18]
Pennington and P
J. Pennington and P. Worah,Nonlinear random matrix theory for deep learning,Journal of Statistical Mechanics: Theory and Experiment(2019) 124005
2019
-
[19]
L. Defilippis, Y. Xu, J. Girardin, E. Troiani, V. Erba, L. Zdeborov´ a et al.,Scaling Laws and Spectra of Shallow Neural Networks in the Feature Learning Regime, inThe Fourteenth International Conference on Learning Representations, 2025.arXiv:2509.24882
Pith/arXiv arXiv 2025
-
[20]
A. Atanasov, J. A. Zavatone-Veth and C. Pehlevan, Scaling and renormalization in high-dimensional regression,Journal of Statistical Mechanics: Theory and Experiment2026(2025) 043404, [arXiv:2405.00592]
Pith/arXiv arXiv 2025
-
[21]
F. D’Amico, D. Bocchi and M. Negri,Implicit bias produces neural scaling laws in learning curves, from perceptrons to deep networks,arXiv:2505.13230
-
[22]
J. Ba, M. A. Erdogdu, T. Suzuki, Z. Wang, D. Wu and G. Yang,High-dimensional Asymptotics of Feature Learning: How One Gradient Step Improves the Representation, inAdvances in Neural Information Processing Systems, 2022.arXiv:2205.01445
arXiv 2022
- [23]
-
[24]
J. Baik, G. Ben Arous and S. P´ ech´ e,Phase transition of the largest eigenvalue for nonnull complex sample covariance matrices,The Annals of Probability33 (2005) 1643–1697, [math/0403022]
Pith/arXiv arXiv 2005
-
[25]
S. F. Edwards and R. C. Jones,The eigenvalue spectrum of a large symmetric random matrix,Journal of Physics A: Mathematical and General9(1976) 1595
1976
-
[26]
Watkin and J.-P
T. Watkin and J.-P. Nadal,Optimal unsupervised learning,Journal of Physics A: Mathematical and General27(1994) 1899
1994
-
[27]
Hoyle and M
D. Hoyle and M. Rattray,Limiting Form of the Sample Covariance Eigenspectrum in PCA and Kernel PCA, in Advances in Neural Information Processing Systems, vol. 16, MIT Press, 2003
2003
-
[28]
Paul,Asymptotics of sample eigenstructure for a large dimensional spiked covariance model,Statistica Sinica(2007) 1617–1642
D. Paul,Asymptotics of sample eigenstructure for a large dimensional spiked covariance model,Statistica Sinica(2007) 1617–1642
2007
-
[29]
A. Montanari, D. Reichman and O. Zeitouni,On the limitation of spectral methods: From the Gaussian hidden clique problem to rank one perturbations of Gaussian tensors,arXiv:1411.6149
-
[30]
A. Perry, A. S. Wein, A. S. Bandeira and A. Moitra, Optimality and sub-optimality of PCA I: Spiked random matrix models,The Annals of Statistics46(2018) 2416–2451, [arXiv:1609.05573]
Pith/arXiv arXiv 2018
-
[31]
U. Adomaityte, G. Sicuro and P. Vivo,PCA recovery thresholds in low-rank matrix inference with sparse noise,arXiv:2511.11927
-
[32]
D. Bocchi, G. Biroli, C. Cammarota and F. Ricci-Tersenghi,Discontinuous BBP transitions, arXiv:2604.27992
-
[33]
Z. Wang, D. Wu and Z. Fan,Nonlinear spiked covariance matrices and signal propagation in deep neural networks, inProceedings of Thirty Seventh Conference on Learning Theory, pp. 4891–4957, PMLR, 2024.arXiv:2402.10127
arXiv 2024
-
[34]
B. L. Annesi, D. Bocchi and C. Cammarota, Overparametrization bends the landscape: BBP transitions at initialization in simple Neural Networks, inThe Fourteenth International Conference on Learning Representations, 2025.arXiv:2510.18435
arXiv 2025
-
[35]
T. Bonnaire, G. Biroli and C. Cammarota,The Role of the Time-Dependent Hessian in High-Dimensional Optimization,Journal of Statistical Mechanics: Theory and Experiment2025(2025) 083401, [arXiv:2403.02418]
arXiv 2025
-
[36]
G. B. Arous, R. Gheissari, J. Huang and A. Jagannath, Spectral alignment of stochastic gradient descent for high-dimensional classification tasks,The Annals of Applied Probability35(2025) 2767–2822, [arXiv:2310.03010]
arXiv 2025
-
[37]
G. B. Arous, R. Gheissari, J. Huang and A. Jagannath, Local geometry of high-dimensional mixture models: Effective spectral theory and dynamical transitions, arXiv:2502.15655
-
[38]
C. Lauditi, C. Pehlevan and B. Bordelon,Spectral Dynamics in Deep Networks: Feature Learning, Outlier Escape, and Learning Rate Transfer,arXiv:2605.07870
-
[39]
O. J. H´ enaff, N. Rabinowitz, J. Ball´ e and E. P. Simoncelli,The local low-dimensionality of natural images, inInt\’l Conf on Learning Representations (ICLR), 2015.arXiv:1412.6626
Pith/arXiv arXiv 2015
- [40]
-
[41]
N. Levi and Y. Oz,The Underlying Universal Statistical Structure of Natural Datasets, inForty-Second International Conference on Machine Learning, 2025. arXiv:2306.14975
arXiv 2025
-
[42]
F. Benaych-Georges and R. R. Nadakuditi,The singular values and vectors of low rank perturbations of large rectangular random matrices,Journal of Multivariate Analysis111(2012) 120–135, [arXiv:1103.2221]
Pith/arXiv arXiv 2012
-
[43]
N. Forner, A. Maloney and B. Rosenow,BBP Phase Transition for an Extensive Number of Outliers, arXiv:2511.18501
-
[44]
M. Potters and J.-P. Bouchaud,A First Course In Random Matrix Theory. Cambridge University Press, 2021, 10.1017/9781108768900
-
[45]
Ros,High-dimensional random landscapes: From typical to large deviations,arXiv:2502.14084
V. Ros,High-dimensional random landscapes: From typical to large deviations,arXiv:2502.14084
-
[46]
P. Kaushik, S. Chaudhari, A. Vaidya, R. Chellappa and A. Yuille,The Universal Weight Subspace Hypothesis, arXiv:2512.05117
-
[47]
A. Sclocchi, A. Favero, N. I. Levi and M. Wyart, Probing the Latent Hierarchical Structure of Data via 30 Diffusion Models,Journal of Statistical Mechanics: Theory and Experiment2025(2025) 084005, [arXiv:2410.13770]
arXiv 2025
-
[48]
Yoo,On the Geometric Structure of Layer Updates in Deep Language Models,arXiv:2604.02459
J.-S. Yoo,On the Geometric Structure of Layer Updates in Deep Language Models,arXiv:2604.02459
-
[49]
J. Huang, B. Loureiro and S. S. Mannelli,Sharp description of local minima in the loss landscape of high-dimensional two-layer ReLU neural networks, arXiv:2604.09412
-
[50]
Glorot and Y
X. Glorot and Y. Bengio,Understanding the difficulty of training deep feedforward neural networks, in Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics(Y. W. Teh and M. Titterington, eds.), vol. 9 ofProceedings of Machine Learning Research, pp. 249–256, PMLR, 2010
2010
-
[51]
K. He, X. Zhang, S. Ren and J. Sun,Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification, in2015 IEEE International Conference on Computer Vision (ICCV), pp. 1026–1034, 2015.arXiv:1502.01852. DOI
Pith/arXiv arXiv 2015
-
[52]
F. Coeurdoux, G. Ferr´ e and J.-P. Bouchaud,Random Matrix Theory of Early-Stopped Gradient Flow: A Transient BBP Scenario,arXiv:2604.18450
-
[53]
L. Venturi, A. S. Bandeira and J. Bruna,Spurious Valleys in One-hidden-layer Neural Network Optimization Landscapes,Journal of Machine Learning Research20(2019) 1–34, [arXiv:1802.06384]
arXiv 2019
-
[54]
J. Lee, Y. Bahri, R. Novak, S. S. Schoenholz, J. Pennington and J. Sohl-Dickstein,Deep Neural Networks as Gaussian Processes, inInternational Conference on Learning Representations, 2018. arXiv:1711.00165
Pith/arXiv arXiv 2018
-
[55]
S. Goldt, B. Loureiro, G. Reeves, F. Krzakala, M. Mezard and L. Zdeborova,The Gaussian equivalence of generative models for learning with shallow neural networks, inProceedings of the 2nd Mathematical and Scientific Machine Learning Conference, pp. 426–471, PMLR, 2022.arXiv:2006.14709
arXiv 2022
-
[56]
P. Chaudhari and S. Soatto,Stochastic gradient descent performs variational inference, converges to limit cycles for deep networks, inInternational Conference on Learning Representations, 2018.arXiv:1710.11029
Pith/arXiv arXiv 2018
-
[57]
Mandt, M
S. Mandt, M. D. Hoffman and D. M. Blei, Continuous-Time Limit of Stochastic Gradient Descent Revisited, in8th NIPS Workshop on Optimization for MachineLearning, 2015
2015
-
[58]
S. Mandt, M. D. Hoffman and D. M. Blei,Stochastic Gradient Descent as Approximate Bayesian Inference, Journal of Machine Learning Research18(2018) 1–35, [arXiv:1704.04289]
Pith/arXiv arXiv 2018
-
[59]
S. Yaida,Fluctuation-dissipation relations for stochastic gradient descent, inInternational Conference on Learning Representations, 2019.arXiv:1810.00004
Pith/arXiv arXiv 2019
-
[60]
P. Goyal, P. Doll´ ar, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola et al.,Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour, arXiv:1706.02677
-
[61]
S. L. Smith, P.-J. Kindermans, C. Ying and Q. V. Le, Don’t Decay the Learning Rate, Increase the Batch Size, inInternational Conference on Learning Representations, 2018.arXiv:1711.00489
Pith/arXiv arXiv 2018
-
[62]
A. Engel and C. Van den Broeck,Statistical mechanics of learning. Cambridge University Press, 2001, 10.1017/CBO9781139164542
-
[63]
C. Beck,Superstatistics: Theory and Applications, Continuum Mechanics and Thermodynamics16(2004) 293–304, [cond-mat/0303288]
Pith/arXiv arXiv 2004
-
[64]
U. Adomaityte, G. Sicuro and P. Vivo,Classification of Heavy-tailed Features in High Dimensions: A Superstatistical Approach, inThirty-Seventh Conference on Neural Information Processing Systems, 2023. arXiv:2304.02912
arXiv 2023
-
[65]
H. Tanaka and D. Kunin,Noether’s Learning Dynamics: Role of Symmetry Breaking in Neural Networks, inAdvances in Neural Information Processing Systems, vol. 34, pp. 25646–25660, Curran Associates, Inc., 2021.arXiv:2105.02716
arXiv 2021
-
[66]
UTKFace: Large scale face dataset
“UTKFace: Large scale face dataset.” https://susanqq.github.io/UTKFace/
-
[67]
D. P. Kingma and J. Ba,Adam: A Method for Stochastic Optimization, inCoRR, 2015. arXiv:1412.6980
Pith/arXiv arXiv 2015
-
[68]
B. Poole, S. Lahiri, M. Raghu, J. Sohl-Dickstein and S. Ganguli,Exponential Expressivity in Deep Neural Networks through Transient Chaos,arXiv:1606.05340
-
[69]
J. Pennington, S. S. Schoenholz and S. Ganguli, Resurrecting the sigmoid in deep learning through dynamical isometry: Theory and practice, inAdvances in Neural Information Processing Systems, vol. 30, Curran Associates, Inc., 2017.arXiv:1711.04735
Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.