KM-Speaker: Keypoint-Based Style Control for High-Quality Speech-Driven 3D Facial Animation and Dialogue Localization
Pith reviewed 2026-06-30 01:05 UTC · model grok-4.3
The pith
KM-Speaker uses keypoint control to add precise style and timing to high-fidelity speech-driven 3D facial animation from limited data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
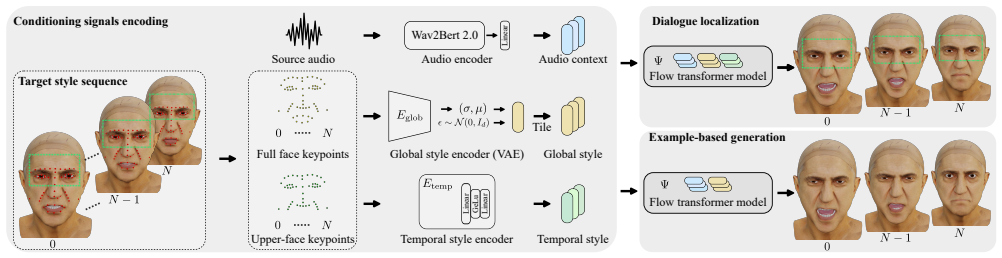
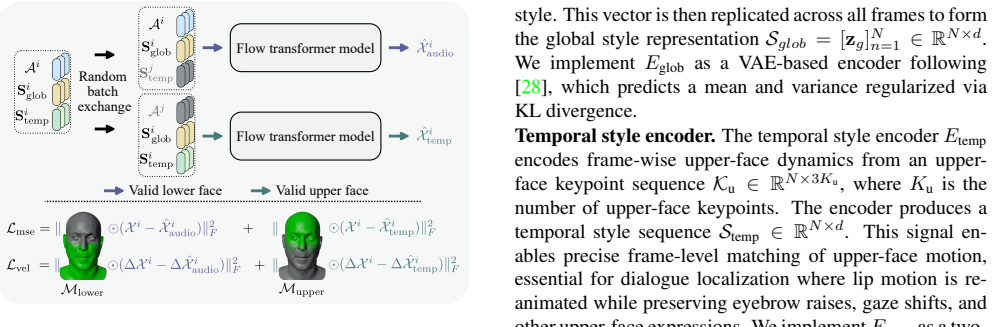
We present KM-Speaker, a novel keypoint-conditioned flow-based generative framework that provides both global style guidance and frame-level temporal control from reference performances. We propose a disentanglement strategy that separates audio-driven lip motion from keypoint-driven upper-face dynamics, together with a global style context preservation mechanism to ensure coherent full-face expressiveness. KM-Speaker advances example-based 3D facial animation by achieving high-fidelity motion and flexible controllability in a data-constrained setting, consistently outperforming state-of-the-art methods in lip-sync accuracy, style adherence, and expressive temporal control.
What carries the argument
keypoint-conditioned flow-based generative framework with disentanglement of audio-driven lip motion from keypoint-driven upper-face dynamics plus global style preservation
If this is right
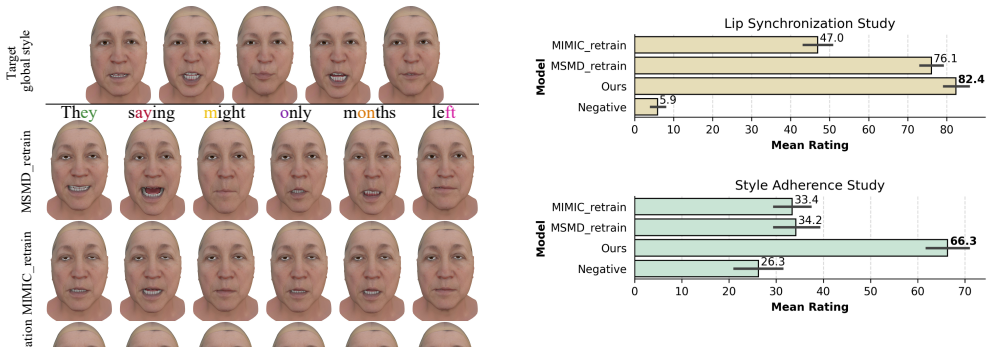
- Outperforms prior methods on lip-sync accuracy when measured against ground-truth animations.
- Delivers stronger adherence to the style of reference performances across entire sequences.
- Supports frame-level temporal adjustments that improve expressive control during dialogue localization.
- Maintains high motion quality even when training data is limited rather than large and noisy.
- Enables more precise matching of specific facial expressions in dubbing tasks.
Where Pith is reading between the lines
- The separation of lip and upper-face control could let animators adjust emotional cues independently of spoken content.
- Reference-based control might lower the volume of data needed for other motion synthesis domains that use sparse keypoints.
- The framework could integrate with existing 3D pipelines by treating keypoints as an additional input channel.
- If the style preservation holds across longer sequences, it could support extended dialogue scenes without drift.
Load-bearing premise
The disentanglement of lip motion from upper-face dynamics combined with the style preservation mechanism actually produces coherent full-face expressiveness without introducing artifacts or losing fidelity.
What would settle it
Side-by-side visual or metric evaluation on held-out sequences where the upper-face keypoint control produces visible artifacts, mismatched expressions, or lower fidelity than direct reference copying.
Figures









read the original abstract
Speech-driven 3D facial animation methods face significant challenges in simultaneously achieving high-fidelity motion and precise artistic control at production quality. Existing controllable models typically learn global style control by relying on large-scale, low-quality \emph{in-the-wild} datasets that compromise overall animation realism. Furthermore, these frameworks often lack the fine-grained temporal precision required for demanding tasks such as dialogue localization (e.g., dubbing), where matching specific facial expressions is as critical as lip synchronization. We present KM-Speaker (Keypoint-Matching Speaker), a novel keypoint-conditioned flow-based generative framework that provides both global style guidance and frame-level temporal control from reference performances. We propose a disentanglement strategy that separates audio-driven lip motion from keypoint-driven upper-face dynamics, together with a global style context preservation mechanism to ensure coherent full-face expressiveness. KM-Speaker advances example-based 3D facial animation by achieving high-fidelity motion and flexible controllability in a data-constrained setting, consistently outperforming state-of-the-art methods in lip-sync accuracy, style adherence, and expressive temporal control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces KM-Speaker, a keypoint-conditioned flow-based generative framework for speech-driven 3D facial animation. It proposes a disentanglement strategy separating audio-driven lip motion from keypoint-driven upper-face dynamics, along with a global style context preservation mechanism. The method aims to achieve high-fidelity motion and flexible controllability in data-constrained settings, outperforming state-of-the-art methods in lip-sync accuracy, style adherence, and expressive temporal control, with applications to dialogue localization.
Significance. If the empirical results hold, this work offers a significant advancement in controllable 3D facial animation by enabling precise style and temporal control without relying on large-scale low-quality datasets. The disentanglement approach and flow-based generation are strengths, and the support from architecture, losses, and ablations strengthens the contribution to production-quality animation and dubbing tasks.
minor comments (2)
- Abstract: the claim of 'consistently outperforming state-of-the-art methods' would be strengthened by including one or two key quantitative metrics (e.g., lip-sync error or style similarity scores) rather than qualitative descriptors alone.
- The introduction could briefly expand on the specific data constraints (e.g., dataset size or quality characteristics) to better contextualize the data-constrained setting relative to prior work.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. We are pleased that the disentanglement strategy, flow-based generation, and empirical support were viewed as strengths.
Circularity Check
No significant circularity in derivation chain
full rationale
The manuscript presents an empirical neural architecture for speech-driven 3D facial animation, relying on a disentanglement strategy between audio-driven lip motion and keypoint-driven upper-face dynamics plus a global style preservation mechanism. No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Claims of high-fidelity motion and controllability are supported directly by architecture descriptions, losses, ablations, and quantitative/qualitative results rather than any derivation that reduces to its own inputs by construction. The work is self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
com/, 2024
Triplegangers Face Models.https : / / triplegangers . com/, 2024. Online; Accessed: 13-11-2024. 18
2024
-
[2]
Seamless: Multilingual expressive and streaming speech translation,
Lo ¨ıc Barrault, Yu-An Chung, Mariano Coria Meglioli, David Dale, Ning Dong, Mark Duppenthaler, Paul-Ambroise Duquenne, Brian Ellis, Hady Elsahar, Justin Haaheim, et al. Seamless: Multilingual expressive and streaming speech translation.arXiv preprint arXiv:2312.05187, 2023. 5
-
[3]
Multilingual video dub- bing—a technology review and current challenges.Frontiers in signal processing, 3:1230755, 2023
Dan Bigioi and Peter Corcoran. Multilingual video dub- bing—a technology review and current challenges.Frontiers in signal processing, 3:1230755, 2023. 2, 3
2023
-
[4]
Pose-aware speech driven facial land- mark animation pipeline for automated dubbing.IEEE Ac- cess, 10:133357–133369, 2022
Dan Bigioi, Hugh Jordan, Rishabh Jain, Rachel McDonnell, and Peter Corcoran. Pose-aware speech driven facial land- mark animation pipeline for automated dubbing.IEEE Ac- cess, 10:133357–133369, 2022. 3
2022
-
[5]
A semantic talking style space for speech-driven facial ani- mation.IEEE Transactions on Visualization and Computer Graphics, 2025
Yujin Chai, Yanlin Weng, Tianjia Shao, and Kun Zhou. A semantic talking style space for speech-driven facial ani- mation.IEEE Transactions on Visualization and Computer Graphics, 2025. 19
2025
-
[6]
Cafe-talk: Generating 3d talking face animation with multi- modal coarse-and fine-grained control
Hejia Chen, Haoxian Zhang, Shoulong Zhang, Xiaoqiang Liu, Sisi Zhuang, Pengfei Wan, Di ZHANG, and Shuai Li. Cafe-talk: Generating 3d talking face animation with multi- modal coarse-and fine-grained control. InInternational Con- ference on Learning Representations, 2025. 2
2025
-
[7]
Disenemo: Learning disentangled emotional representation from facial motion for 3d talking head generation
Ziang Chen, Tianhua Qi, Cheng Lu, and Wenming Zheng. Disenemo: Learning disentangled emotional representation from facial motion for 3d talking head generation. In2025 IEEE International Conference on Image Processing (ICIP), pages 289–294. IEEE, 2025. 2, 3
2025
-
[8]
Artalk: Speech-driven 3d head animation via autoregressive model
Xuangeng Chu, Nabarun Goswami, Ziteng Cui, Hanqin Wang, and Tatsuya Harada. Artalk: Speech-driven 3d head animation via autoregressive model. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–9, 2025. 2
2025
-
[9]
Daniel Cudeiro, Timo Bolkart, Cassidy Laidlaw, Anurag Ranjan, and Michael J. Black. Capture, learning, and synthe- sis of 3d speaking styles. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019. 5
2019
-
[10]
Emotional speech- driven animation with content-emotion disentanglement
Radek Dan ˇeˇcek, Kiran Chhatre, Shashank Tripathi, Yandong Wen, Michael Black, and Timo Bolkart. Emotional speech- driven animation with content-emotion disentanglement. In SIGGRAPH Asia 2023 Conference Papers, SA ’23, New York, NY , USA, 2023. Association for Computing Machin- ery. 2
2023
-
[11]
The light stages and their applications to pho- toreal digital actors.SIGGRAPH Asia, 2(4):1–6, 2012
Paul Debevec. The light stages and their applications to pho- toreal digital actors.SIGGRAPH Asia, 2(4):1–6, 2012. 2
2012
-
[12]
Jali: an animator-centric viseme model for expressive lip synchronization.ACM Transactions on graphics (TOG), 35(4):1–11, 2016
Pif Edwards, Chris Landreth, Eugene Fiume, and Karan Singh. Jali: an animator-centric viseme model for expressive lip synchronization.ACM Transactions on graphics (TOG), 35(4):1–11, 2016. 2, 8
2016
-
[13]
Black, and Timo Bolkart
Yao Feng, Haiwen Feng, Michael J. Black, and Timo Bolkart. Learning an animatable detailed 3d face model from in-the-wild images.ACM Trans. Graph., 40(4), July 2021. 2
2021
-
[14]
Mimic: Speaking style disentanglement for speech-driven 3d facial animation
Hui Fu, Zeqing Wang, Ke Gong, Keze Wang, Tianshui Chen, Haojie Li, Haifeng Zeng, and Wenxiong Kang. Mimic: Speaking style disentanglement for speech-driven 3d facial animation. InProceedings of the AAAI conference on artifi- cial intelligence, volume 38, pages 1770–1777, 2024. 2, 3, 5, 6, 9
2024
-
[15]
Serep: Semantic facial expression representation for robust in-the-wild capture and retargeting
Arthur Josi, Luiz Gustavo Hafemann, Abdallah Dib, Eme- line Got, Rafael MO Cruz, and Marc-Andre Carbonneau. Serep: Semantic facial expression representation for robust in-the-wild capture and retargeting. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14538–14548, 2025. 3, 6, 18, 19, 20
2025
-
[16]
Adam: A method for stochastic optimization
Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInternational Conference on Learning Representations (ICLR), San Diega, CA, USA,
-
[17]
Tianye Li, Timo Bolkart, Michael. J. Black, Hao Li, and Javier Romero. Learning a model of facial shape and ex- pression from 4D scans.ACM Transactions on Graphics, (Proc. SIGGRAPH Asia), 36(6):194:1–194:17, 2017. 2, 6
2017
-
[18]
Towards high-fidelity 3d talking avatar with personalized dy- namic texture
Xuanchen Li, Jianyu Wang, Yuhao Cheng, Yikun Zeng, Xingyu Ren, Wenhan Zhu, Weiming Zhao, and Yichao Yan. Towards high-fidelity 3d talking avatar with personalized dy- namic texture. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 204–214, 2025. 15
2025
-
[19]
Flow matching for generative mod- eling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative mod- eling. In11th International Conference on Learning Repre- sentations, ICLR 2023, 2023. 4
2023
-
[20]
Yaron Lipman, Marton Havasi, Peter Holderrieth, Neta Shaul, Matt Le, Brian Karrer, Ricky TQ Chen, David Lopez- Paz, Heli Ben-Hamu, and Itai Gat. Flow matching guide and code.arXiv preprint arXiv:2412.06264, 2024. 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Emoface: Audio-driven emotional 3d face animation
Chang Liu, Qunfen Lin, Zijiao Zeng, and Ye Pan. Emoface: Audio-driven emotional 3d face animation. In2024 IEEE Conference Virtual Reality and 3D User Interfaces (VR), pages 387–397. IEEE, 2024. 2
2024
-
[22]
Chang Liu, Ye Pan, Chenyang Ding, Susanto Rahardja, and Xiaokang Yang. Medtalk: Multimodal controlled 3d facial animation with dynamic emotions by disentangled embed- ding.arXiv preprint arXiv:2507.06071, 2025. 2
-
[23]
Identity-preserving video dubbing using motion warping.arXiv preprint arXiv:2501.04586, 2025
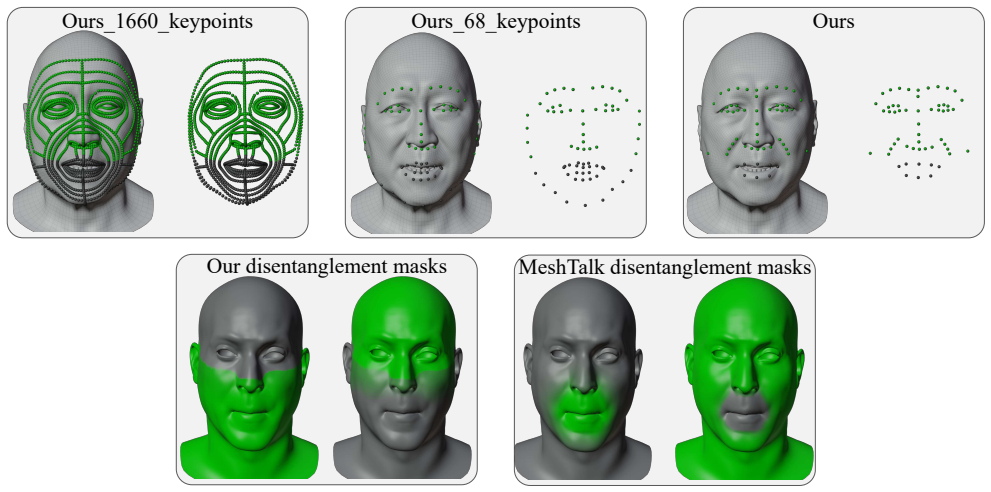
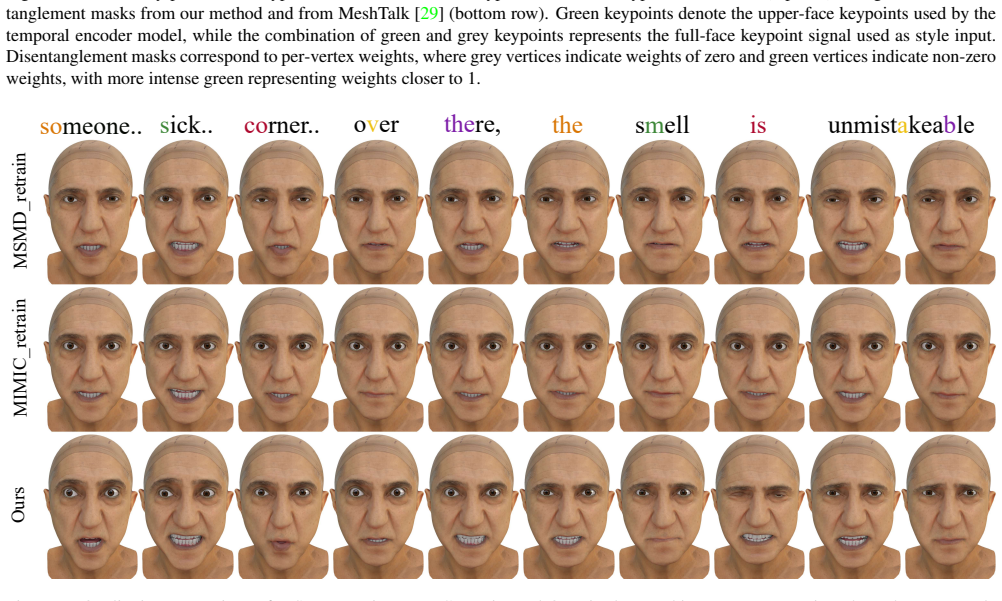
Runzhen Liu, Qinjie Lin, Yunfei Liu, Lijian Lin, Ye Zhu, Yu Li, Chuhua Xian, and Fa-Ting Hong. Identity-preserving video dubbing using motion warping.arXiv preprint arXiv:2501.04586, 2025. 3 9 Ours Ours_1660_keypoints Ours_68_keypoints Our disentanglement masks MeshTalk disentanglement masks Figure 6. We visually present the keypoints used in Ours 1660 ke...
-
[24]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, et al. Flow straight and fast: Learning to generate and transfer data with rectified flow. In NeurIPS 2022 Workshop on Score-Based Methods, 2022. 2
2022
-
[25]
Meta-stylespeech: Multi-speaker adaptive text-to- speech generation
Dongchan Min, Dong Bok Lee, Eunho Yang, and Sung Ju Hwang. Meta-stylespeech: Multi-speaker adaptive text-to- speech generation. InInternational Conference on Machine 10 Target temporal style something wander.. fog I anyone disorgsuch conditionsightfog MeshTalk Ours meshalk encoder Ours mesthalk mask Ours Ours no disentanglement Figure 8. Qualitative resul...
2021
-
[26]
Learning landmarks motion from speech for speaker- agnostic 3d talking heads generation
Federico Nocentini, Claudio Ferrari, and Stefano Berretti. Learning landmarks motion from speech for speaker- agnostic 3d talking heads generation. InInternational Con- ference on Image Analysis and Processing, pages 340–351. Springer, 2023. 3
2023
-
[27]
V ocal: V owel and consonant layering for expres- sive animator-centric singing animation
Yifang Pan, Chris Landreth, Eugene Fiume, and Karan Singh. V ocal: V owel and consonant layering for expres- sive animator-centric singing animation. InSIGGRAPH Asia 2022 Conference Papers, pages 1–9, 2022. 2
2022
-
[28]
Model see model do: Speech-driven facial animation with style control
Yifang Pan, Karan Singh, and Luiz Gustavo Hafemann. Model see model do: Speech-driven facial animation with style control. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Confer- ence Conference Papers, pages 1–10, 2025. 2, 3, 4, 5, 6, 7, 9
2025
-
[29]
Meshtalk: 3d face an- imation from speech using cross-modality disentanglement
Alexander Richard, Michael Zollh ¨ofer, Yandong Wen, Fer- nando De la Torre, and Yaser Sheikh. Meshtalk: 3d face an- imation from speech using cross-modality disentanglement. InProceedings of the IEEE/CVF international conference on computer vision, pages 1173–1182, 2021. 2, 3, 4, 5, 6, 8, 9, 10, 11
2021
-
[30]
300 faces in-the-wild challenge: Database and results.Image and vi- sion computing, 47:3–18, 2016
Christos Sagonas, Epameinondas Antonakos, Georgios Tz- imiropoulos, Stefanos Zafeiriou, and Maja Pantic. 300 faces in-the-wild challenge: Database and results.Image and vi- sion computing, 47:3–18, 2016. 5
2016
-
[31]
Method for the subjective assessment of interme- diate quality level of audio systems.International Telecom- munication Union Radiocommunication Assembly, 2, 2014
B Series. Method for the subjective assessment of interme- diate quality level of audio systems.International Telecom- munication Union Radiocommunication Assembly, 2, 2014. 7
2014
-
[32]
Diffposetalk: 11 Speech-driven stylistic 3d facial animation and head pose generation via diffusion models.ACM Transactions on Graphics (TOG), 43(4):1–9, 2024
Zhiyao Sun, Tian Lv, Sheng Ye, Matthieu Lin, Jenny Sheng, Yu-Hui Wen, Minjing Yu, and Yong-jin Liu. Diffposetalk: 11 Speech-driven stylistic 3d facial animation and head pose generation via diffusion models.ACM Transactions on Graphics (TOG), 43(4):1–9, 2024. 2, 3, 6
2024
-
[33]
3d face reconstruction with dense landmarks
Erroll Wood, Tadas Baltru ˇsaitis, Charlie Hewitt, Matthew Johnson, Jingjing Shen, Nikola Milosavljevi´c, Daniel Wilde, Stephan Garbin, Toby Sharp, Ivan Stojiljkovi´c, et al. 3d face reconstruction with dense landmarks. InEuropean Confer- ence on Computer Vision, pages 160–177. Springer, 2022. 2
2022
-
[34]
3d face reconstruction with dense landmarks
Erroll Wood, Tadas Baltru ˇsaitis, Charlie Hewitt, Matthew Johnson, Jingjing Shen, Nikola Milosavljevi´c, Daniel Wilde, Stephan Garbin, Toby Sharp, Ivan Stojiljkovi´c, et al. 3d face reconstruction with dense landmarks. InEuropean Confer- ence on Computer Vision, pages 160–177. Springer, 2022. 3, 5
2022
-
[35]
Probtalk3d: Non-deterministic emotion controllable speech- driven 3d facial animation synthesis using vq-vae
Sichun Wu, Kazi Injamamul Haque, and Zerrin Yumak. Probtalk3d: Non-deterministic emotion controllable speech- driven 3d facial animation synthesis using vq-vae. InPro- ceedings of the 17th ACM SIGGRAPH Conference on Mo- tion, Interaction, and Games, pages 1–12, 2024. 2
2024
-
[36]
Mmhead: Towards fine-grained multi- modal 3d facial animation
Sijing Wu, Yunhao Li, Yichao Yan, Huiyu Duan, Ziwei Liu, and Guangtao Zhai. Mmhead: Towards fine-grained multi- modal 3d facial animation. InProceedings of the 32nd ACM International Conference on Multimedia, pages 7966–7975,
-
[37]
Codetalker: Speech-driven 3d facial animation with discrete motion prior
Jinbo Xing, Menghan Xia, Yuechen Zhang, Xiaodong Cun, Jue Wang, and Tien-Tsin Wong. Codetalker: Speech-driven 3d facial animation with discrete motion prior. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12780–12790, 2023. 2, 6
2023
-
[38]
Kmtalk: Speech-driven 3d facial animation with key motion embed- ding
Zhihao Xu, Shengjie Gong, Jiapeng Tang, Lingyu Liang, Yining Huang, Haojie Li, and Shuangping Huang. Kmtalk: Speech-driven 3d facial animation with key motion embed- ding. InEuropean Conference on Computer Vision, pages 236–253. Springer, 2024. 2
2024
-
[39]
MuseTalk: Real-time high-fidelity video dubbing via spatio-temporal sampling, 2025
Yue Zhang, Zhizhou Zhong, Minhao Liu, Zhaokang Chen, Bin Wu, Yubin Zeng, Chao Zhan, Yingjie He, Junxin Huang, and Wenjiang Zhou. Musetalk: Real-time high-fidelity video dubbing via spatio-temporal sampling.arXiv preprint arXiv:2410.10122, 2024. 3
-
[40]
Media2face: Co-speech facial animation gen- eration with multi-modality guidance
Qingcheng Zhao, Pengyu Long, Qixuan Zhang, Dafei Qin, Han Liang, Longwen Zhang, Yingliang Zhang, Jingyi Yu, and Lan Xu. Media2face: Co-speech facial animation gen- eration with multi-modality guidance. InACM SIGGRAPH 2024 conference papers, pages 1–13, 2024. 2
2024
-
[41]
Expclip: Bridging text and facial expressions via se- mantic alignment
Yicheng Zhong, Huawei Wei, Peiji Yang, and Zhisheng Wang. Expclip: Bridging text and facial expressions via se- mantic alignment. InProceedings of the AAAI Conference on Artificial Intelligence, 2024. 2
2024
-
[42]
Visemenet: Audio- driven animator-centric speech animation.ACM Transac- tions on Graphics (ToG), 37(4):1–10, 2018
Yang Zhou, Zhan Xu, Chris Landreth, Evangelos Kaloger- akis, Subhransu Maji, and Karan Singh. Visemenet: Audio- driven animator-centric speech animation.ACM Transac- tions on Graphics (ToG), 37(4):1–10, 2018. 2
2018
-
[43]
Celebv- hq: A large-scale video facial attributes dataset
Hao Zhu, Wayne Wu, Wentao Zhu, Liming Jiang, Siwei Tang, Li Zhang, Ziwei Liu, and Chen Change Loy. Celebv- hq: A large-scale video facial attributes dataset. InEuropean conference on computer vision, pages 650–667. Springer,
-
[44]
Data collection protocol We built our dataset by recording synchronized speech audio and high-fidelity facial performances from 12 profes- sional actors
18 12 Appendices A. Data collection protocol We built our dataset by recording synchronized speech audio and high-fidelity facial performances from 12 profes- sional actors. To ensure broad demographic coverage, we conducted a targeted casting aimed at maximizing diversity in age, gender, and ethnicity within the limited number of actors we captured. Our ...
-
[45]
To this end, we sample three audio clips from CelebV-HQ [43], three target videos serv- ing as styles, and three neutral meshes with diverse facial traits from Triplegangers [1]
rather than 4D capture. To this end, we sample three audio clips from CelebV-HQ [43], three target videos serv- ing as styles, and three neutral meshes with diverse facial traits from Triplegangers [1]. 18 Ours no global Target animation Blendno global Blend Ours Figure 13. Qualitative results for two distinct examples (left and right), given a target ani...
-
[46]
19 Target style Generated animation see from recipe kn ow marinade inflation global glo bal sc alefact out should be fighting pleaser Figure 14
or [5]), would likely improve robustness and reduce these effects. 19 Target style Generated animation see from recipe kn ow marinade inflation global glo bal sc alefact out should be fighting pleaser Figure 14. KM-Speaker generalization results on in-the-wild audio, style, and varying face geometries. Given a target video providing the desired style (lef...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.