CADENZA: Compiling Natural-Language Intent into Task-Specific Operator DAGs for Semantic Query Processing
Pith reviewed 2026-07-02 21:05 UTC · model grok-4.3
The pith
CADENZA compiles each natural-language semantic operator intent into a space of typed task DAGs that can be rewritten and tuned for quality-latency-cost trade-offs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
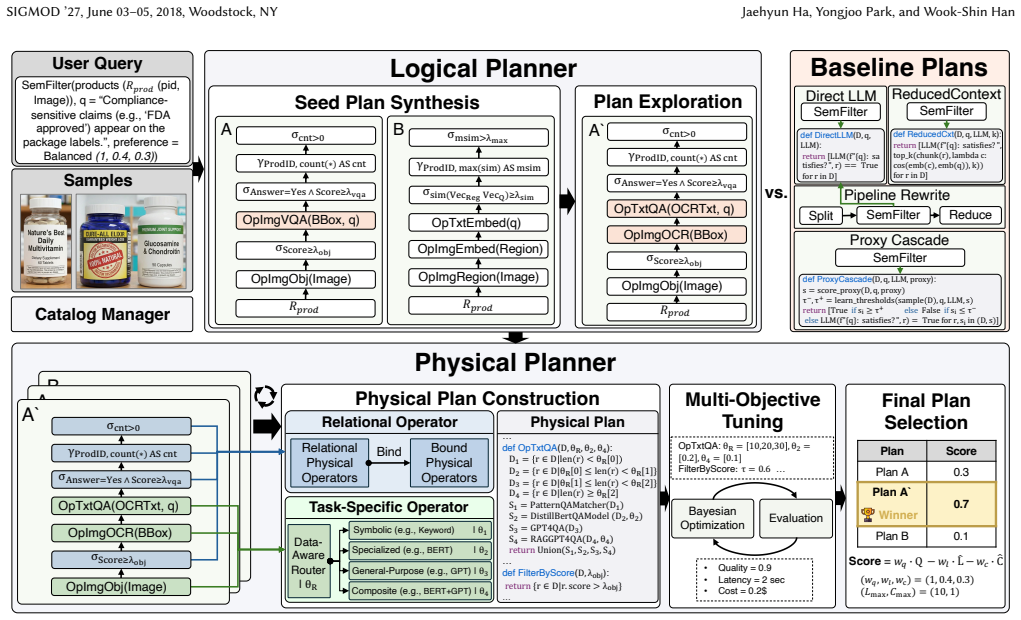
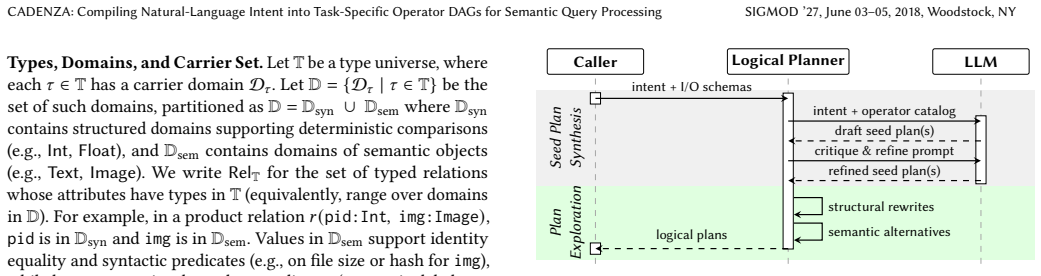
CADENZA compiles each semantic operator instance—a template bound to a natural-language intent—into an intent-specific plan space of typed task DAGs and selects an executable plan under user-specified quality-latency-cost trade-offs. It does so by introducing task-extended relational algebra (TxRA), synthesizing seed TxRA plans, applying structural rewrites whose safety is checked from operator dependencies, enumerating semantics-guided alternatives, and jointly tuning routing cutpoints, backend parameters, and relational thresholds with Bayesian optimization.
What carries the argument
Task-extended relational algebra (TxRA), a conservative extension of relational algebra that treats task-specific operators and their intermediate outputs as first-class relational objects for filtering, reordering, routing, and thresholding.
If this is right
- The logical planner can safely enumerate alternative task DAGs without changing the meaning of the original natural-language intent.
- The physical planner can jointly optimize routing decisions, backend parameters, and relational thresholds under explicit quality-latency-cost constraints.
- Intermediate task outputs become usable as relational objects, allowing standard algebraic identities to be applied to semantic operators.
- Quality, latency, and cost can be traded off at the level of individual task instances rather than whole queries.
Where Pith is reading between the lines
- The same compilation approach could be applied to other stochastic or model-driven operators that currently sit outside relational optimizers.
- If the TxRA representation is exposed, existing relational engines might incorporate semantic operators without a full rewrite of their planners.
- Users could receive multiple candidate DAGs ranked by different trade-off points rather than a single chosen plan.
- The method might reduce reliance on hand-tuned prompts by turning intent into an explicit, rewritable plan space.
Load-bearing premise
Structural rewrites preserve query semantics when their safety conditions are verified only from operator dependencies.
What would settle it
A concrete query on SemBench where applying one of CADENZA’s structural rewrites produces a final answer whose semantic quality differs from the original intent under an independent equivalence check.
Figures


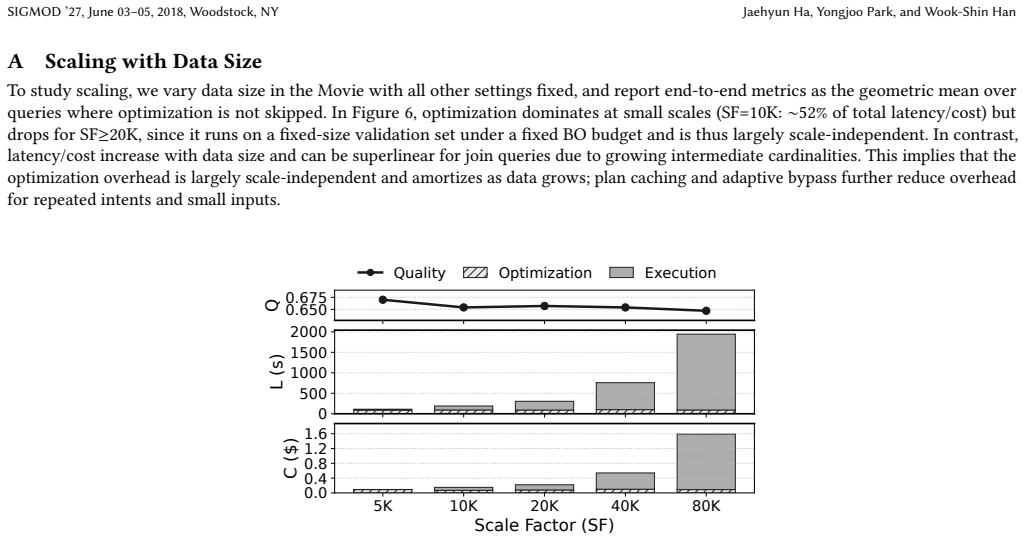
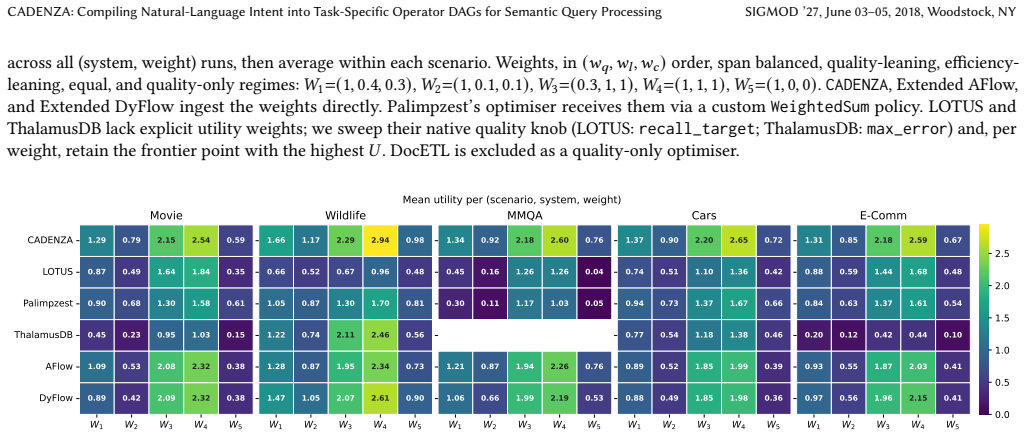
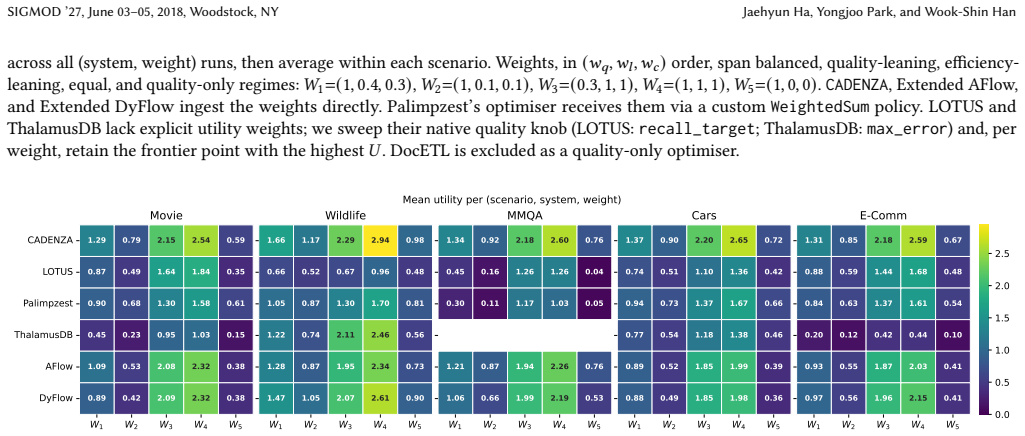
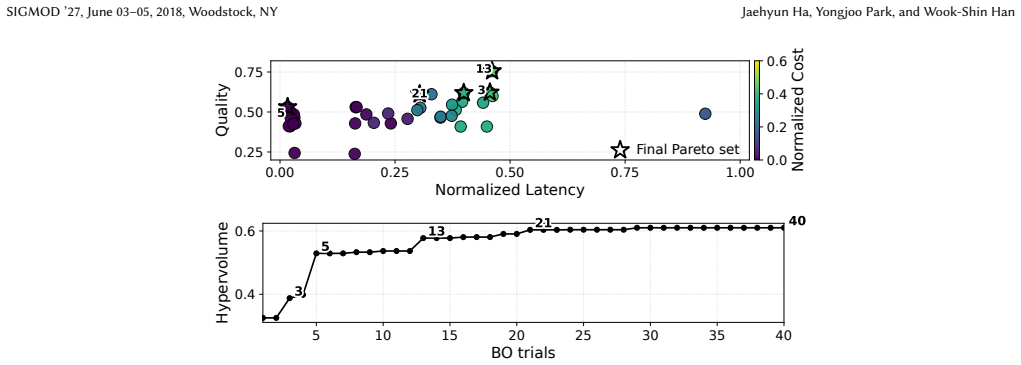
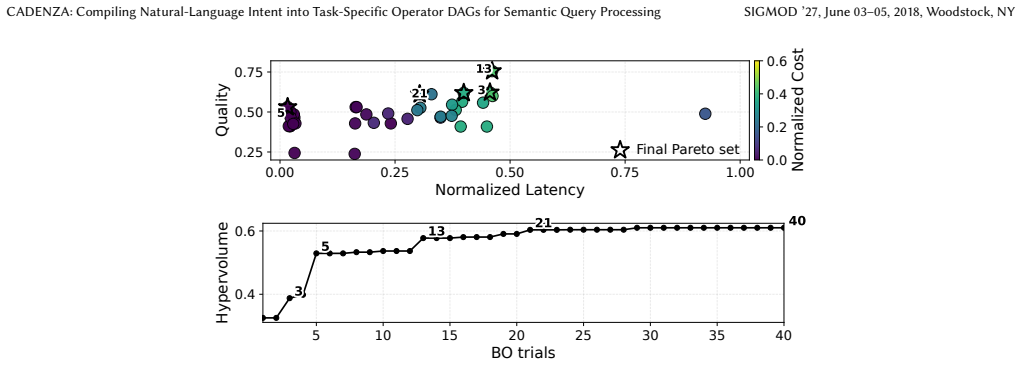

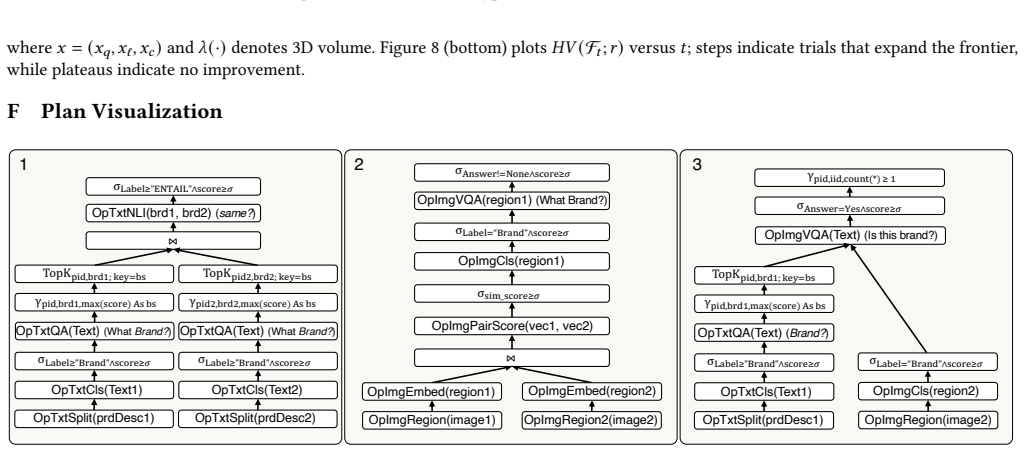
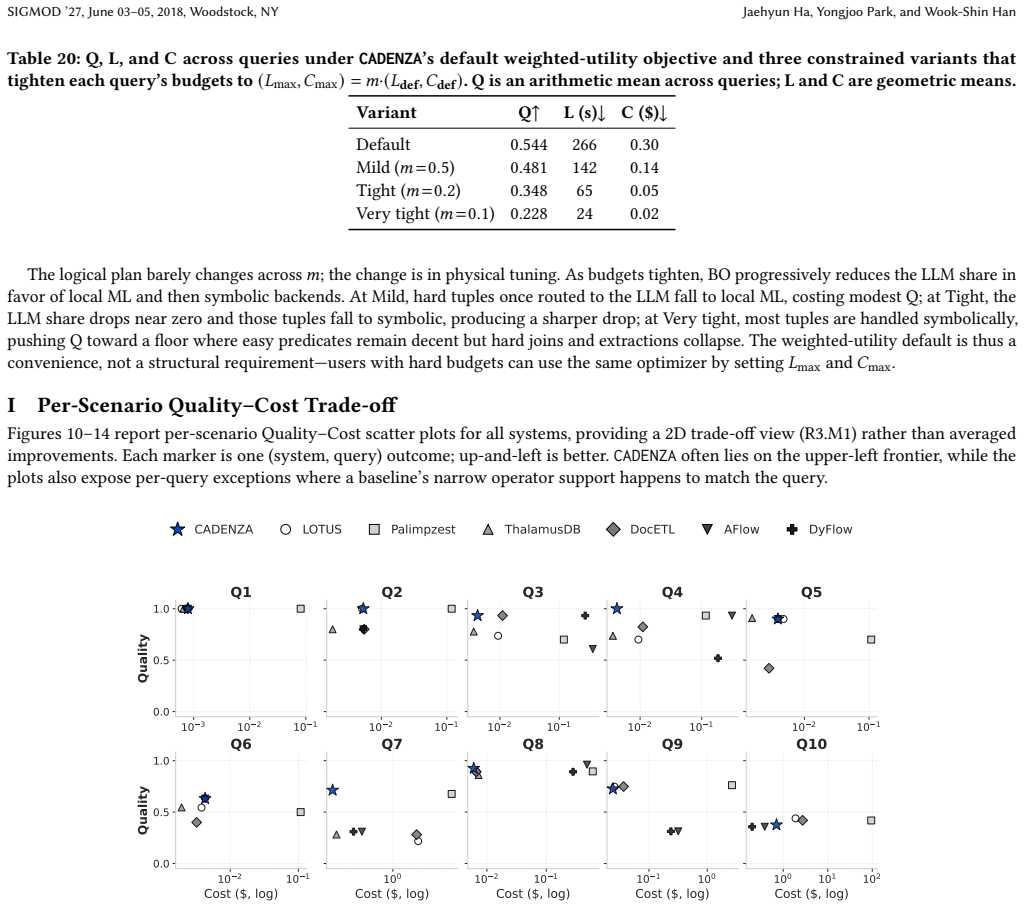
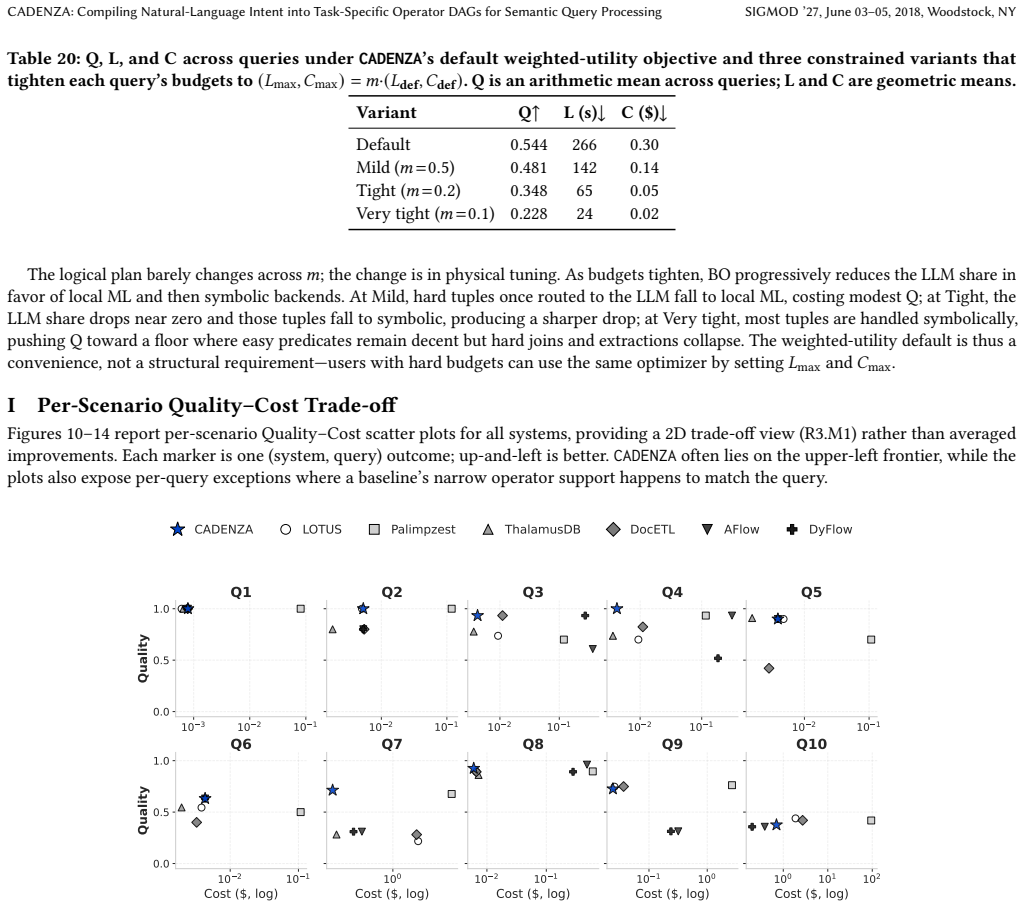

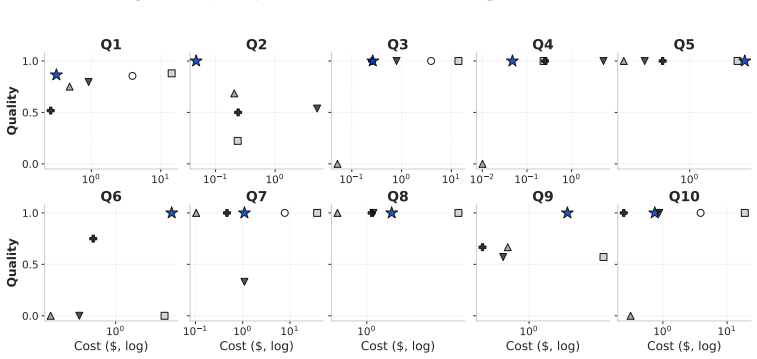
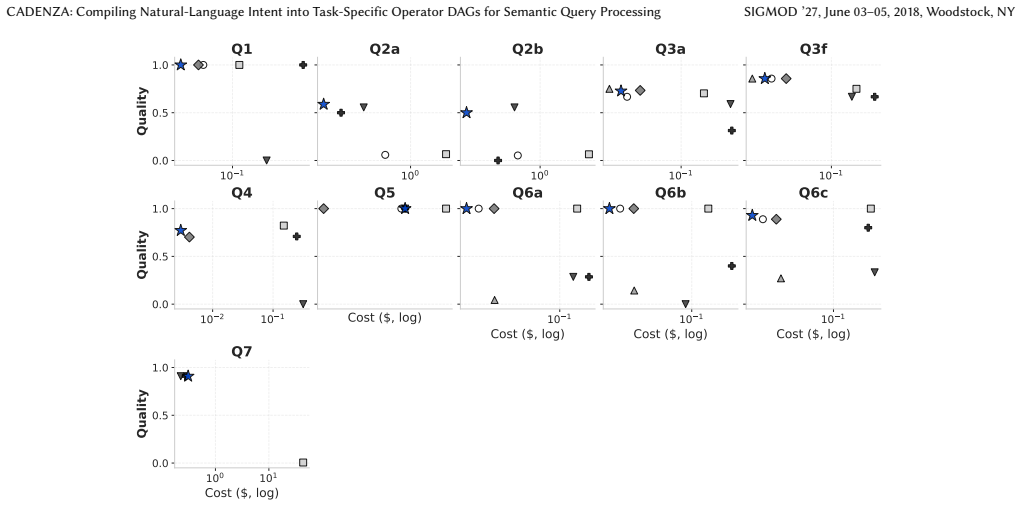





read the original abstract
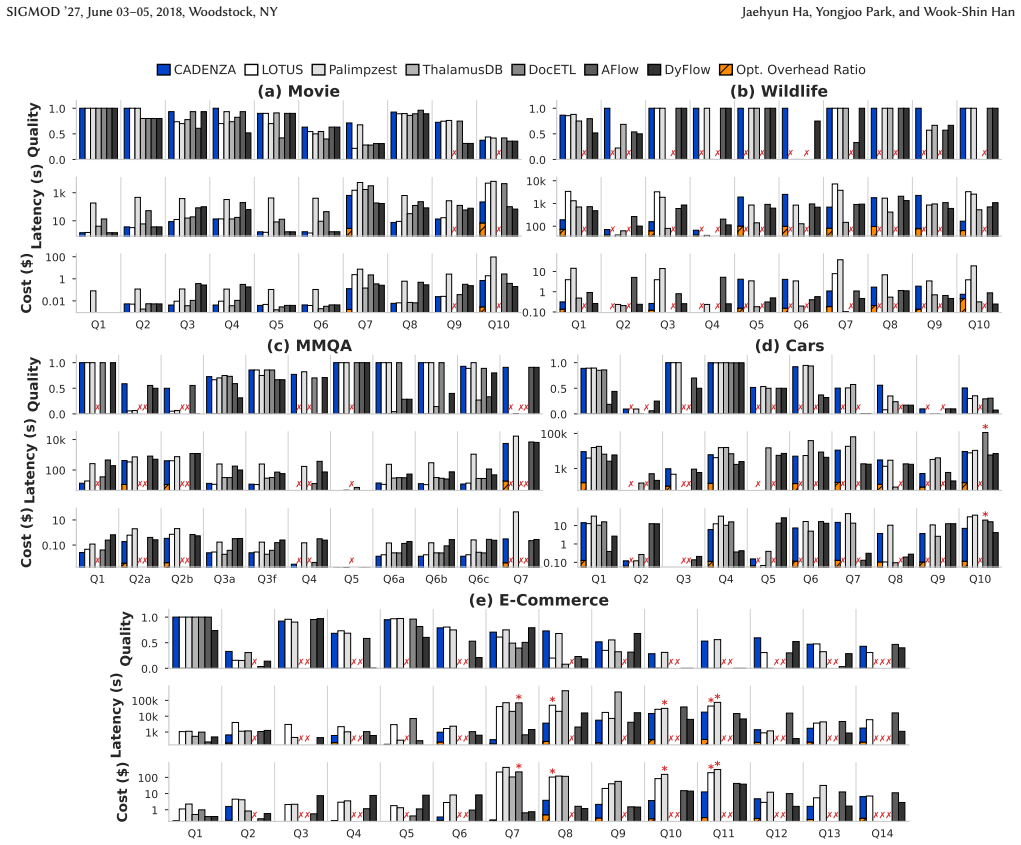
Semantic query processing engines (SQPEs) extend relational query processing with semantic operators that are executed via model inference over unstructured data. Optimizing such queries is inherently multi-objective: model inference dominates latency and monetary cost, and outputs are stochastic and backend-dependent, so quality must be optimized alongside efficiency. Existing SQPE optimizers do not expose each semantic operator instance's intermediate task outputs as a relational optimization object, leaving optimization unable to filter, reorder, route, threshold, or jointly tune them. We present CADENZA, which compiles each semantic operator instance--a template bound to a natural-language intent--into an intent-specific plan space of typed task DAGs and selects an executable plan under user-specified quality-latency-cost trade-offs. CADENZA introduces task-extended relational algebra (TxRA), a conservative extension of relational algebra with task-specific operators. The logical planner synthesizes seed TxRA plans, applies structural rewrites whose safety conditions are checked from operator dependencies, and enumerates semantics-guided alternatives from alternative-generation templates. The physical planner compiles each task-specific operator into a router over heterogeneous backends and jointly tunes routing cutpoints, backend parameters, and relational thresholds with Bayesian optimization. On SemBench, CADENZA improves the scenario-level averages of quality, latency, and cost by up to +0.49, 165.7x, and 310.3x, respectively, relative to state-of-the-art.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. CADENZA compiles each semantic operator instance (a template bound to a natural-language intent) into an intent-specific plan space of typed task DAGs using task-extended relational algebra (TxRA), a conservative extension of relational algebra. The logical planner synthesizes seed TxRA plans, applies structural rewrites whose safety conditions are checked from operator dependencies, and enumerates semantics-guided alternatives; the physical planner compiles each task-specific operator into a router over heterogeneous backends and jointly tunes routing cutpoints, backend parameters, and relational thresholds via Bayesian optimization. On SemBench the system reports scenario-level average improvements of up to +0.49 in quality, 165.7x in latency, and 310.3x in cost relative to state-of-the-art SQPE optimizers.
Significance. If the central claims hold, the work would be a substantive contribution to semantic query processing by exposing intermediate task outputs as first-class relational optimization objects, enabling joint quality-latency-cost optimization that prior SQPE engines do not support. The conservative TxRA extension and the separation of dependency-checked logical rewriting from Bayesian physical tuning are technically interesting and could influence future designs of AI-augmented database systems.
major comments (1)
- [Abstract / Logical planner] Abstract / Logical planner description: the safety of structural rewrites is asserted on the basis of checks performed only from operator dependencies. Because semantic operators produce backend-dependent stochastic outputs, dependency-based checks alone do not establish that a rewritten DAG yields an output distribution whose quality is interchangeable with the original; any mismatch would invalidate both the quality gains and the subsequent physical tuning results. This assumption is load-bearing for the enumeration of alternatives and the reported improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We respond to the major comment below, providing clarification on the safety conditions for structural rewrites in the logical planner.
read point-by-point responses
-
Referee: [Abstract / Logical planner] Abstract / Logical planner description: the safety of structural rewrites is asserted on the basis of checks performed only from operator dependencies. Because semantic operators produce backend-dependent stochastic outputs, dependency-based checks alone do not establish that a rewritten DAG yields an output distribution whose quality is interchangeable with the original; any mismatch would invalidate both the quality gains and the subsequent physical tuning results. This assumption is load-bearing for the enumeration of alternatives and the reported improvements.
Authors: The dependency checks verify that a structural rewrite preserves the exact dataflow: each task-specific operator receives identical inputs (including any upstream task outputs) as in the seed plan. Because each operator is a fixed function of its inputs, identical inputs imply identical output distributions regardless of later backend assignment. Backend dependence and stochasticity are addressed exclusively in the physical planner, which selects routers, tunes parameters, and sets thresholds via Bayesian optimization to achieve target quality. Consequently, enumerated alternatives remain valid at the task-semantics level, and quality measurements in the evaluation reflect these equivalent plans. We are prepared to add an explicit lemma formalizing input preservation (and thus distribution equivalence) under the checked conditions if the editor deems it necessary. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper introduces CADENZA, TxRA as a conservative extension of relational algebra, and describes logical/physical planners that synthesize plans, apply dependency-checked rewrites, and tune via Bayesian optimization. No equations, fitted parameters called predictions, self-citations, or uniqueness theorems appear in the abstract or described content that would reduce any claim to an input by construction. Performance numbers are presented as empirical results on the external SemBench benchmark, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
invented entities (2)
-
TxRA
no independent evidence
-
task-specific operator DAGs
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Amazon Redshift ML
2025. Amazon Redshift ML. https://aws.amazon.com/ko/redshift/features/ redshift-ml/. accessed: 2025-09-28
2025
-
[2]
Samuel Arch, Yuchen Liu, Todd C Mowry, Jignesh M Patel, and Andrew Pavlo
-
[3]
The key to effective udf optimization: Before inlining, first perform outlin- ing.Proceedings of the VLDB Endowment18, 1 (2024), 1–13
2024
-
[4]
Konstantinos Chasialis, Yannis Foufoulas, Alkis Simitsis, and Yannis Ioannidis
-
[5]
Optimizing UDF Queries in SQL Data Engines. (2025)
2025
-
[6]
Karel D’Oosterlinck, François Remy, Johannes Deleu, Thomas Demeester, Chris Develder, Klim Zaporojets, Aneiss Ghodsi, Simon Ellershaw, Jack Collins, and Christopher Potts. 2023. BioDEX: Large-scale biomedical adverse drug event extraction for real-world pharmacovigilance. InFindings of the association for computational linguistics: EMNLP 2023. 13425–13454
2023
-
[7]
David Eriksson and Martin Jankowiak. 2021. High-dimensional Bayesian opti- mization with sparse axis-aligned subspaces. InUncertainty in Artificial Intelli- gence. PMLR, 493–503
2021
-
[8]
David Eriksson, Michael Pearce, Jacob Gardner, Ryan D Turner, and Matthias Poloczek. 2019. Scalable global optimization via local Bayesian optimization. Advances in neural information processing systems32 (2019)
2019
-
[9]
Google. 2025. BigQuery ML. https://cloud.google.com/bigquery-ml/docs. [On- line; accessed 03-November-2025]
2025
-
[10]
Sirui Hong, Yizhang Lin, Bang Liu, Bangbang Liu, Binhao Wu, Ceyao Zhang, Danyang Li, Jiaqi Chen, Jiayi Zhang, Jinlin Wang, et al. 2025. Data interpreter: An llm agent for data science. InFindings of the Association for Computational Linguistics: ACL 2025. 19796–19821
2025
-
[11]
Shengran Hu, Cong Lu, and Jeff Clune. [n. d.]. Automated Design of Agentic Systems. InThe Thirteenth International Conference on Learning Representations
-
[12]
Fabian Hueske, Mathias Peters, Matthias J Sax, Astrid Rheinländer, Rico Bergmann, Aljoscha Krettek, and Kostas Tzoumas. 2012. Opening the Black Boxes in Data Flow Optimization.Proceedings of the VLDB Endowment5, 11 (2012)
2012
-
[13]
Ihab F. Ilyas, Rahul Shah, Walid G. Aref, Jeffrey Scott Vitter, and Ahmed K. Elmagarmid. 2004. Rank-aware Query Optimization. InProceedings of the 2004 ACM SIGMOD International Conference on Management of Data (SIGMOD ’04). ACM, New York, NY, USA. doi:10.1145/1007568.1007593
-
[14]
Saehan Jo and Immanuel Trummer. 2024. Thalamusdb: Approximate query processing on multi-modal data.Proceedings of the ACM on Management of Data 2, 3 (2024), 1–26
2024
-
[15]
Gaurav Tarlok Kakkar, Jiashen Cao, Pramod Chunduri, Zhuangdi Xu, Sury- atej Reddy Vyalla, Prashanth Dintyala, Anirudh Prabakaran, Jaeho Bang, Aubhro Sengupta, Kaushik Ravichandran, et al. 2023. Eva: An end-to-end exploratory video analytics system. InProceedings of the Seventh Workshop on Data Manage- ment for End-to-End Machine Learning. 1–5
2023
-
[16]
Gaurav Tarlok Kakkar, Jiashen Cao, Aubhro Sengupta, Joy Arulraj, and Hyesoon Kim. 2025. Aero: Adaptive Query Processing of ML Queries.Proceedings of the ACM on Management of Data3, 3 (2025), 1–27
2025
-
[17]
Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, and Ashish Sabharwal. [n. d.]. Decomposed Prompting: A Modular Ap- proach for Solving Complex Tasks. InThe Eleventh International Conference on Learning Representations
- [18]
-
[19]
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. InProceedings of the 58th annual meeting of the association for computational linguistics. 7871–7880
2020
-
[20]
Chengkai Li, Kevin Chen-Chuan Chang, Ihab F. Ilyas, and Sumin Song. 2005. RankSQL: Query Algebra and Optimization for Relational Top- 𝑘 Queries. In Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data (SIGMOD ’05). ACM, New York, NY, USA, 131–142. doi:10.1145/1066157. 1066173
-
[21]
Chunwei Liu, Matthew Russo, Michael Cafarella, Lei Cao, Peter Baile Chen, Zui Chen, Michael Franklin, Tim Kraska, Samuel Madden, Rana Shahout, et al. 2025. Palimpzest: Optimizing ai-powered analytics with declarative query processing. InProceedings of the Conference on Innovative Database Research (CIDR). 2
2025
- [22]
-
[23]
Liana Patel, Siddharth Jha, Melissa Pan, Harshit Gupta, Parth Asawa, Carlos Guestrin, and Matei Zaharia. 2025. Semantic Operators and Their Optimization: Enabling LLM-Based Data Processing with Accuracy Guarantees in LOTUS. Proceedings of the VLDB Endowment18, 11 (2025), 4171–4184
2025
-
[24]
Archiki Prasad, Alexander Koller, Mareike Hartmann, Peter Clark, Ashish Sabhar- wal, Mohit Bansal, and Tushar Khot. 2024. Adapt: As-needed decomposition and planning with language models. InFindings of the Association for Computational Linguistics: NAACL 2024. 4226–4252
2024
-
[25]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
2021
- [26]
-
[27]
Jon Saad-Falcon, Adrian Gamarra Lafuente, Shlok Natarajan, Nahum Maru, Hristo Todorov, Etash Kumar Guha, E Kelly Buchanan, Mayee F Chen, Neel Guha, Christopher Re, et al. [n. d.]. An Architecture Search Framework for Inference- Time Techniques. InForty-second International Conference on Machine Learning
-
[28]
SemBench Maintainers. 2025. Medical scenario removed due to licensing issues. https://github.com/SemBench/SemBench/issues/16. GitHub Issue #16
2025
-
[29]
Shreya Shankar, Tristan Chambers, Tarak Shah, Aditya G. Parameswaran, and Eugene Wu. 2025. DocETL: Agentic Query Rewriting and Evaluation for Complex Document Processing.Proc. VLDB Endow.18, 9 (May 2025), 3035–3048. doi:10. 14778/3746405.3746426
-
[30]
Matthias Urban and Carsten Binnig. 2024. CAESURA: language models as multi- modal query planners.CIDR(2024)
2024
-
[31]
Jiayi Wang and Jianhua Feng. 2025. Unify: An unstructured data analytics system. In2025 IEEE 41st International Conference on Data Engineering (ICDE). IEEE Computer Society, 4662–4674
2025
-
[32]
Junlin Wang, WANG Jue, Ben Athiwaratkun, Ce Zhang, and James Zou. [n. d.]. Mixture-of-Agents Enhances Large Language Model Capabilities. InThe Thir- teenth International Conference on Learning Representations
-
[33]
Jiayi Wang and Guoliang Li. 2025. Aop: Automated and interactive llm pipeline orchestration for answering complex queries. CIDR
2025
- [34]
-
[35]
Yanbo Wang, Zixiang Xu, Yue Huang, Xiangqi Wang, Zirui Song, Lang Gao, Chenxi Wang, Xiangru Tang, Yue Zhao, Arman Cohan, et al . 2025. DyFlow: Dynamic Workflow Framework for Agentic Reasoning. InAdvances in Neural Information Processing Systems
2025
-
[36]
Johannes Wehrstein, Tiemo Bang, Roman Heinrich, and Carsten Binnig. 2025. GRACEFUL: A Learned Cost Estimator for UDFs. In2025 IEEE 41st International CADENZA: Compiling Natural-Language Intent into Task-Specific Operator DAGs for Semantic Query Processing SIGMOD ’27, June 03–05, 2018, Woodstock, NY Conference on Data Engineering (ICDE). IEEE Computer Soci...
2025
-
[37]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR)
2023
-
[38]
Enhao Zhang, Nicole Sullivan, Brandon Haynes, Ranjay Krishna, and Magdalena Balazinska. 2025. Self-Enhancing Video Data Management System for Com- positional Events with Large Language Models.Proceedings of the ACM on Management of Data3, 3 (2025), 1–29
2025
-
[39]
#$%&”()"*+
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xiong-Hui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, et al. [n. d.]. AFlow: Automating Agentic Workflow Generation. InThe Thirteenth International Con- ference on Learning Representations. SIGMOD ’27, June 03–05, 2018, Woodstock, NY Jaehyun Ha, Yongjoo Park, and Wook-Shin Han ...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.