Adaptive AI Delegation under Uncertainty: A Bayesian Governance Policy for Sequential Decision Authority
Pith reviewed 2026-06-30 01:55 UTC · model grok-4.3
The pith
Sequential Bayesian governance outperforms fixed heuristics by adaptively allocating decision authority to AI under evolving uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that modeling AI delegation as a Governance-Aware POMDP, with Bayesian updates on the informational state and reward-maximizing sequential choice of delegation level, yields a general-purpose policy that allocates organizational decision authority more effectively than fixed heuristics when AI quality, uncertainty, and objectives change over time.
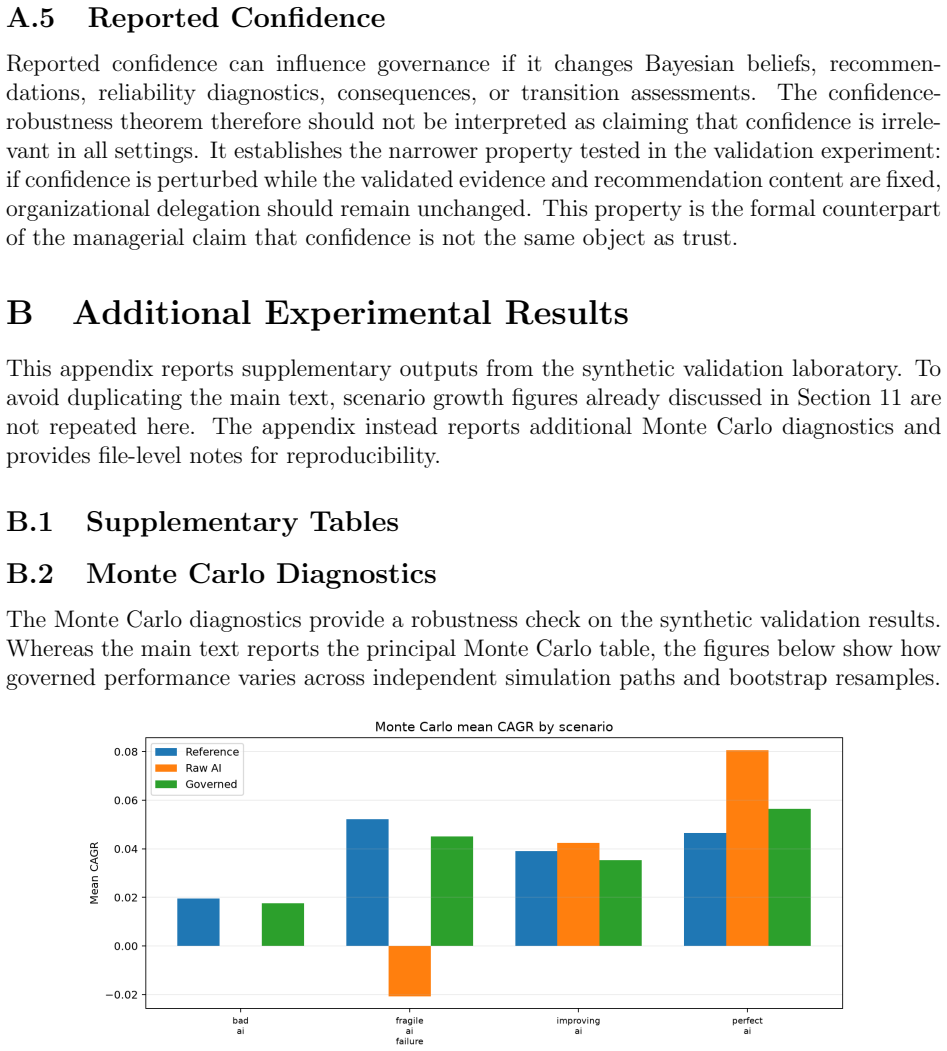
What carries the argument
Governance-Aware Partially Observable Markov Decision Process (POMDP) that uses Bayesian inference to estimate the current informational state from LLM outputs and then solves for the optimal delegation level at each time step.
If this is right
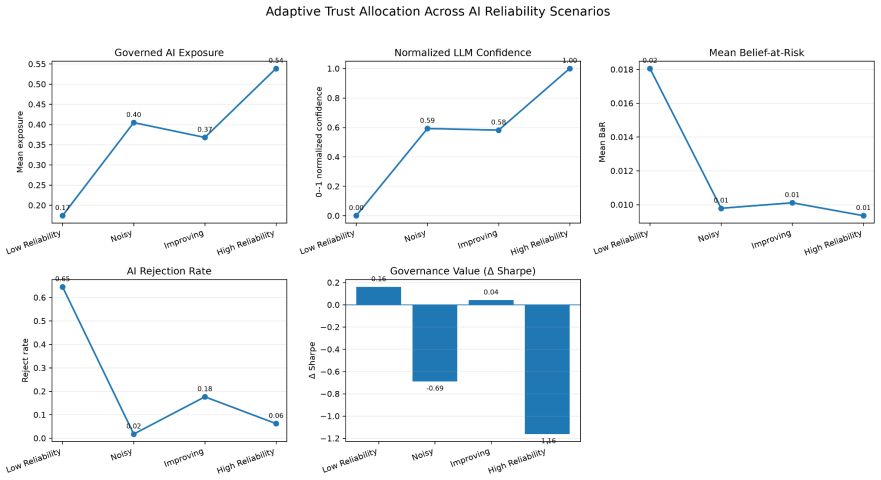
- Organizations gain a quantitative method to raise or lower AI authority as evidence quality improves or deteriorates.
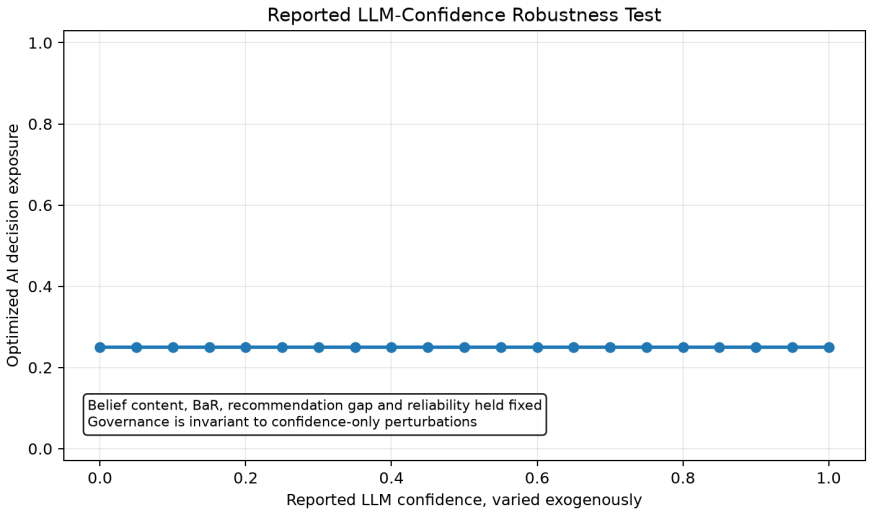
- The policy exhibits graceful degradation when AI confidence signals become noisy or biased.
- Institutional conservatism can be calibrated directly through the POMDP reward parameters without post-hoc rule changes.
- Early-warning indicators emerge when the policy begins to withhold authority from an AI system whose quality is declining.
Where Pith is reading between the lines
- The same POMDP structure could be applied to delegation decisions involving non-LLM agents if their output distributions can be treated as observations.
- Extending the state space to include multiple AI systems would allow joint optimization of authority across an ensemble rather than single-system delegation.
- The benchmarking framework itself could serve as a testbed for comparing governance policies in other sequential decision domains such as regulatory approval or clinical trial oversight.
Load-bearing premise
Bayesian inference on LLM outputs can reliably recover the true underlying informational state, and the chosen POMDP reward function matches the organization's actual objectives without further adjustment.
What would settle it
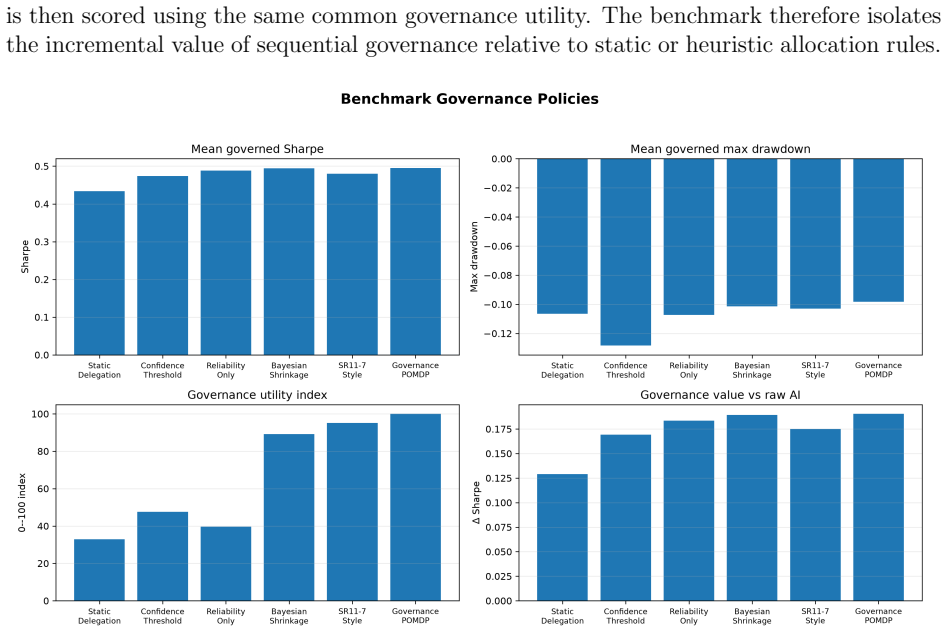
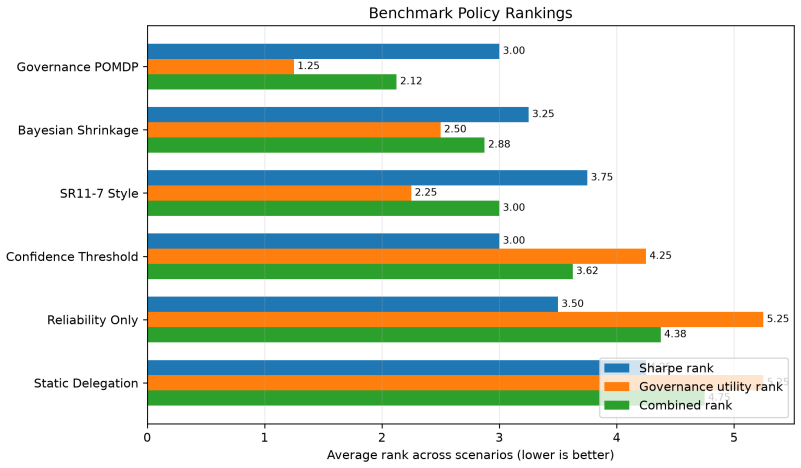
A controlled sequence of decisions with known ground-truth outcomes in which the Bayesian POMDP policy fails to produce higher cumulative reward than at least one of the five benchmark heuristics when AI quality changes over time.
Figures












read the original abstract
Organizations increasingly use large language models and agentic AI systems to generate probabilistic assessments and candidate actions in high-consequence settings. This creates a managerial problem distinct from prediction: how should organizations allocate decision authority to AI-generated recommendations as evidence quality, uncertainty, and organizational objectives evolve over time? Existing AI governance frameworks emphasize transparency, documentation, oversight, and regulatory compliance, but provide limited quantitative guidance for dynamically allocating decision authority under uncertainty. To address this challenge, we formulate adaptive AI delegation as a Governance-Aware Partially Observable Markov Decision Process (POMDP) in which Bayesian inference estimates the informational state and sequential optimization determines delegated AI authority. The paper also develops a quantitative validation and benchmarking framework for governance policies. Synthetic stress tests, reported LLM-confidence robustness, forecast-accuracy validation, governance-appetite sensitivity, and fragile-AI early-warning experiments evaluate whether the proposed policy exhibits graceful degradation, robustness to confidence-only perturbations, adaptive delegation under improving evidence quality, and interpretable calibration of institutional conservatism. The Governance-Aware POMDP is further benchmarked against five representative governance strategies operating under identical Bayesian beliefs, information, and governance objectives. The results show that while specialized heuristics perform well in stationary settings, sequential Bayesian governance provides the strongest general-purpose governance policy across heterogeneous AI-quality regimes by adaptively allocating organizational decision authority under uncertainty.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formulates adaptive allocation of decision authority to AI systems as a Governance-Aware POMDP. Bayesian updating on LLM outputs estimates the hidden informational state, while finite-horizon value iteration yields a policy that chooses the level of AI delegation at each step. Synthetic benchmarks compare this policy against five fixed heuristics under identical beliefs and objectives; the POMDP policy is reported to dominate across heterogeneous AI-quality regimes, with additional experiments on governance-appetite sensitivity, confidence robustness, and early-warning behavior.
Significance. If the reported ranking survives scrutiny of the reward specification, the work supplies a decision-theoretic, quantitative alternative to the largely qualitative AI-governance literature. The explicit benchmarking framework and sensitivity experiments constitute a reproducible validation protocol that could be extended to real organizational data.
major comments (1)
- [Validation and benchmarking framework] Validation and benchmarking framework: the headline claim that sequential Bayesian governance is the strongest general-purpose policy rests on outperformance under a single POMDP reward structure. The governance-appetite sensitivity experiments vary a scalar conservatism parameter but do not demonstrate that the ranking is preserved under alternative, still-plausible reward weightings (e.g., different relative penalties on false delegation versus missed opportunity). Without such checks, the superiority could be an artifact of the chosen objective rather than a general property of the POMDP formulation.
minor comments (2)
- [Abstract] Abstract: the model is described only at a high level; including the state space, action space, or the explicit form of the reward function would allow readers to assess the central construction without immediately consulting the full text.
- Notation: the manuscript should define the governance-appetite parameter and the reward weights in a single, early table or equation block so that later sensitivity results can be directly linked to those quantities.
Simulated Author's Rebuttal
We thank the referee for highlighting the need to verify that the reported policy ranking is not an artifact of the specific reward weighting. We address this directly below and commit to additional experiments in revision.
read point-by-point responses
-
Referee: the headline claim that sequential Bayesian governance is the strongest general-purpose policy rests on outperformance under a single POMDP reward structure. The governance-appetite sensitivity experiments vary a scalar conservatism parameter but do not demonstrate that the ranking is preserved under alternative, still-plausible reward weightings (e.g., different relative penalties on false delegation versus missed opportunity). Without such checks, the superiority could be an artifact of the chosen objective rather than a general property of the POMDP formulation.
Authors: We agree that the current sensitivity analysis, which varies only the scalar governance-appetite parameter within a fixed reward structure, does not fully address robustness to alternative weightings of the core penalties. The POMDP formulation itself is agnostic to the specific weights, but the headline claim of general-purpose superiority would be strengthened by explicit checks. In the revised manuscript we will add a new set of experiments that systematically rescale the relative penalty on false delegation versus missed opportunity (holding the governance-appetite parameter fixed at its baseline value) and re-compute the policy rankings under these alternative objectives. Results will be reported alongside the existing sensitivity figures. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper formulates adaptive AI delegation as a Governance-Aware POMDP with Bayesian state estimation and sequential optimization, then benchmarks the resulting policy against five heuristics under identical beliefs, information, and objectives. This is a standard optimal-vs-heuristic comparison within a defined model and does not reduce by construction to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. No equations or sections are quoted that exhibit the specific reductions required by the circularity patterns; the central claim rests on the optimization and experimental validation framework rather than tautological equivalence to inputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- governance-appetite parameters
- reward function weights
axioms (2)
- domain assumption Bayesian inference on LLM outputs yields accurate estimates of informational state
- domain assumption The POMDP formulation captures the essential dynamics of decision authority allocation
Reference graph
Works this paper leans on
-
[1]
, title=
Berger, James O. , title=
-
[2]
and Sondik, Edward J
Smallwood, Richard D. and Sondik, Edward J. , title=. Operations Research , volume=
-
[3]
, title=
Puterman, Martin L. , title=
-
[4]
and Cassandra, Anthony R
Kaelbling, Leslie Pack and Littman, Michael L. and Cassandra, Anthony R. , title=. Artificial Intelligence , volume=
-
[5]
and Simmons, Joseph P
Dietvorst, Berkeley J. and Simmons, Joseph P. and Massey, Cade , title=. Journal of Experimental Psychology: General , volume=
-
[6]
and Minson, Julia A
Logg, Jennifer M. and Minson, Julia A. and Moore, Don A. , title=. Organizational Behavior and Decision Processes , volume=
-
[7]
and von Krogh, Georg , title=
Shrestha, Yash Raj and Ben-Menahem, Shiko M. and von Krogh, Georg , title=. California Management Review , volume=
-
[8]
Academy of Management Review , volume=
Raisch, Sebastian and Krakowski, Sebastian , title=. Academy of Management Review , volume=
-
[9]
and Valentine, Melissa A
Kellogg, Katherine C. and Valentine, Melissa A. and Christin, Ang. Algorithms at Work: The New Contested Terrain of Control , journal=
-
[10]
and Inkpen, Kori and Teevan, Jaime and Kikin-Gil, Ruth and Horvitz, Eric , title=
Amershi, Saleema and Weld, Dan and Vorvoreanu, Mihaela and Fourney, Adam and Nushi, Besmira and Collisson, Penny and Suh, Jina and Iqbal, Shamsi and Bennett, Paul N. and Inkpen, Kori and Teevan, Jaime and Kikin-Gil, Ruth and Horvitz, Eric , title=. Proceedings of the CHI Conference on Human Factors in Computing Systems , year=
-
[11]
and Weld, Daniel S
Bansal, Gagan and Nushi, Besmira and Kamar, Ece and Lasecki, Walter S. and Weld, Daniel S. and Horvitz, Eric , title=. Proceedings of the AAAI Conference on Human Computation and Crowdsourcing , year=
-
[12]
Proceedings of the ACM on Human-Computer Interaction , volume=
Green, Ben and Chen, Yiling , title=. Proceedings of the ACM on Human-Computer Interaction , volume=
-
[13]
Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages=
Ribeiro, Marco Tulio and Singh, Sameer and Guestrin, Carlos , title=. Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages=
-
[14]
2017 , eprint=
Doshi-Velez, Finale and Kim, Been , title=. 2017 , eprint=
2017
-
[15]
Proceedings of the Conference on Fairness, Accountability, and Transparency , pages=
Mitchell, Margaret and Wu, Simone and Zaldivar, Andrew and Barnes, Parker and Vasserman, Lucy and Hutchinson, Ben and Spitzer, Elena and Raji, Inioluwa Deborah and Gebru, Timnit , title=. Proceedings of the Conference on Fairness, Accountability, and Transparency , pages=
-
[16]
Datasheets for Datasets , journal=
Gebru, Timnit and Morgenstern, Jamie and Vecchione, Briana and Vaughan, Jennifer Wortman and Wallach, Hanna and Daum. Datasheets for Datasets , journal=
-
[17]
and Mitchell, Margaret and Gebru, Timnit and Hutchinson, Ben and Smith-Loud, Jamila and Theron, Daniel and Barnes, Parker , title=
Raji, Inioluwa Deborah and Smart, Andrew and White, Rebecca N. and Mitchell, Margaret and Gebru, Timnit and Hutchinson, Ben and Smith-Loud, Jamila and Theron, Daniel and Barnes, Parker , title=. Proceedings of the Conference on Fairness, Accountability, and Transparency , pages=
-
[18]
Artificial Intelligence Risk Management Framework (AI RMF 1.0) , institution=
-
[19]
ISO/IEC 42001:2023 Artificial Intelligence Management System , year=
2023
-
[20]
Regulation (EU) 2024/1689: Artificial Intelligence Act , year=
2024
-
[21]
Artificial Intelligence Public--Private Forum: Final Report , institution=
-
[22]
Artificial Intelligence in UK Financial Services: 2024 , institution=
2024
-
[23]
The Financial Stability Implications of Artificial Intelligence , institution=
-
[24]
Artificial Intelligence and the Economy: Implications for Central Banks , institution=
-
[25]
2026 , eprint=
Dixon, Matthew , title=. 2026 , eprint=
2026
-
[26]
Bellman, Richard , title=
-
[27]
, title=
Bertsekas, Dimitri P. , title=
-
[28]
, title=
Powell, Warren B. , title=
-
[29]
, title=
Simon, Herbert A. , title=
-
[30]
, title=
Galbraith, Jay R. , title=. Interfaces , volume=
-
[31]
and Meckling, William H
Jensen, Michael C. and Meckling, William H. , title=. Journal of Applied Corporate Finance , volume=
-
[32]
Journal of Political Economy , volume=
Aghion, Philippe and Tirole, Jean , title=. Journal of Political Economy , volume=
-
[33]
Annals of Mathematical Statistics , volume=
Blackwell, David , title=. Annals of Mathematical Statistics , volume=
-
[34]
and Pisano, Gary and Shuen, Amy , title=
Teece, David J. and Pisano, Gary and Shuen, Amy , title=. Strategic Management Journal , volume=
-
[35]
and Martin, Jeffrey A
Eisenhardt, Kathleen M. and Martin, Jeffrey A. , title=. Strategic Management Journal , volume=
-
[36]
OECD Principles on Artificial Intelligence , year=
-
[37]
SR 11-7: Guidance on Model Risk Management , institution=
-
[38]
, title=
Topkis, Donald M. , title=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.