FADE: Mitigating Hallucinations by Reducing Language-Prior Dominance in Large Vision-Language Models
Pith reviewed 2026-06-30 07:04 UTC · model grok-4.3
The pith
Attenuating feed-forward network outputs at critical layers reduces language-prior dominance and mitigates hallucinations in large vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
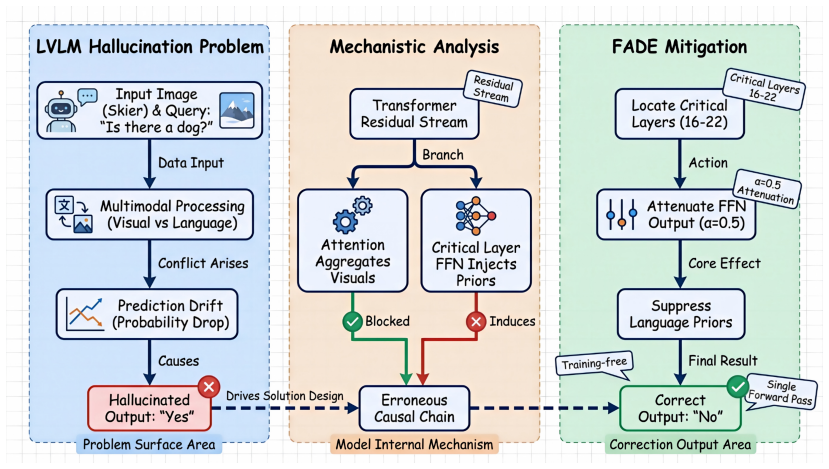
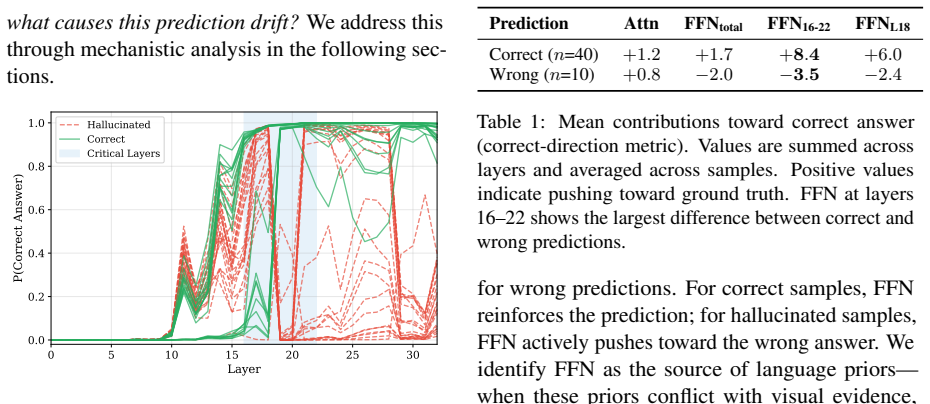
Attention modules across layers aggregate visual evidence, yet FFN modules at critical layers supply language priors that override it and shift correct intermediate predictions toward incorrect final outputs; FADE counters this by attenuating those FFN outputs to lower language-prior dominance.
What carries the argument
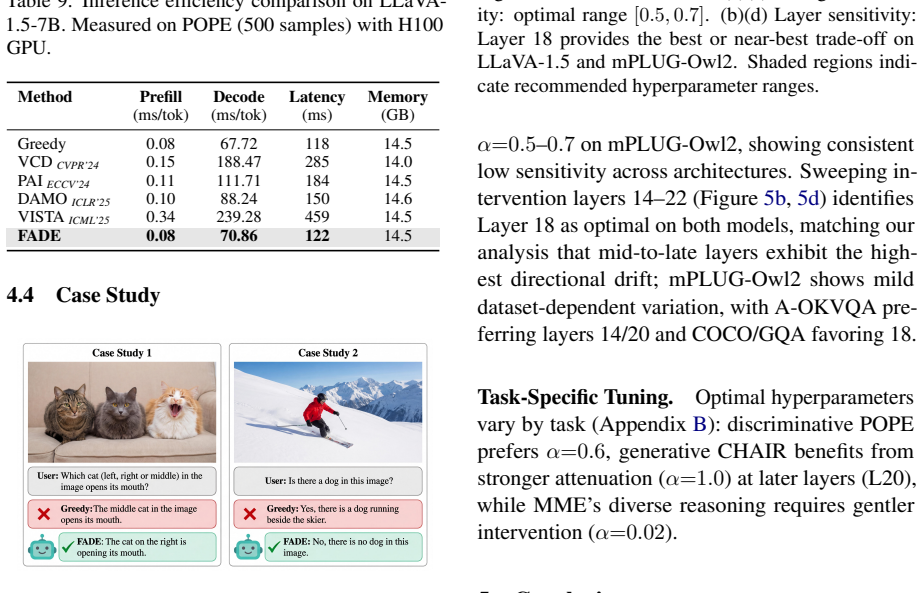
FADE (FFN Attenuation for DEcoding), which scales down FFN outputs at identified critical layers to limit language-prior injection during decoding.
If this is right
- Hallucination rates drop on POPE, CHAIR, and MME for LLaVA-1.5, mPLUG-Owl2, and InstructBLIP.
- Inference speed remains unchanged because no extra computation or training is added.
- The method works without modifying model weights or architecture.
- The same attenuation targets the internal source rather than relying on contrastive decoding at output time.
Where Pith is reading between the lines
- The same FFN attenuation principle might apply to other transformer-based multimodal systems facing similar prior dominance.
- Measuring prediction drift layer by layer could become a standard diagnostic for hallucination risk before deployment.
- If critical layers prove consistent across model scales, FADE-style adjustments could be applied as a lightweight post-training step.
- Extending the attenuation to non-critical layers might reveal whether language priors serve useful roles elsewhere in the network.
Load-bearing premise
The information-flow analysis correctly identifies FFN modules at critical layers as the primary source of language priors that override visual evidence.
What would settle it
Running FADE on the same models and benchmarks yields no reduction in hallucination rates or produces worse accuracy than the unmodified baseline.
Figures


read the original abstract
Despite the impressive capabilities of Large Vision-Language Models (LVLMs), they remain susceptible to hallucination, generating content inconsistent with the input image. Recent studies attribute this to the dominance of language priors over visual inputs and employ contrastive decoding methods to mitigate this dominance, but the mechanistic origin remains unexplored. We investigate the information flow through each transformer layer and find that attention modules consistently aggregate visual evidence, while FFN modules at critical layers act as the source of language priors. These priors can override visual evidence, causing correct predictions in intermediate layers to drift toward incorrect outputs. Based on this insight, we propose FADE (FFN Attenuation for DEcoding), a training-free method that attenuates FFN outputs to reduce language-prior dominance. Evaluations on POPE, CHAIR, and MME benchmarks across LLaVA-1.5, mPLUG-Owl2, and InstructBLIP show that FADE effectively mitigates hallucinations while preserving inference efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that hallucinations in LVLMs arise because FFN modules at critical transformer layers introduce overriding language priors that displace visual evidence aggregated by attention modules. It proposes FADE, a training-free decoding intervention that attenuates FFN outputs at those layers to reduce language-prior dominance. Experiments on POPE, CHAIR, and MME across LLaVA-1.5, mPLUG-Owl2, and InstructBLIP are reported to show hallucination reduction with no added inference cost.
Significance. If the layer-wise attribution and the resulting attenuation method hold under broader scrutiny, the work supplies both a mechanistic account of a known failure mode and a lightweight, training-free fix that preserves efficiency. The explicit linkage from information-flow observations to a falsifiable intervention is a strength.
major comments (2)
- [§3] §3 (layer-wise analysis): the claim that FFN modules at 'critical layers' are the primary source of overriding priors requires explicit controls showing that attenuating attention or other components does not produce comparable gains; without such ablations the attribution remains correlational rather than causal.
- [§4.2] §4.2 (FADE formulation): the scaling coefficient applied to FFN outputs is described as fixed, yet no derivation or sensitivity analysis is provided for how its value is selected across models; this risks making the method less parameter-free than asserted.
minor comments (2)
- [Table 1] Table 1 and Figure 3: axis labels and legend entries use inconsistent abbreviations for the three evaluated models; standardize notation.
- The description of 'information flow' investigation would benefit from a short pseudocode or diagram clarifying exactly which activations are measured at each layer.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below and indicate where revisions will be made to address the points raised.
read point-by-point responses
-
Referee: [§3] §3 (layer-wise analysis): the claim that FFN modules at 'critical layers' are the primary source of overriding priors requires explicit controls showing that attenuating attention or other components does not produce comparable gains; without such ablations the attribution remains correlational rather than causal.
Authors: We agree that explicit controls are needed to move from correlational to causal attribution. Our layer-wise information flow analysis shows attention modules consistently aggregate visual evidence while FFN modules at critical layers introduce language priors that cause prediction drift. In the revised manuscript we will add ablations attenuating attention outputs (and other components) at the same critical layers and report the resulting hallucination metrics on POPE, CHAIR, and MME to demonstrate that comparable gains are not obtained. revision: yes
-
Referee: [§4.2] §4.2 (FADE formulation): the scaling coefficient applied to FFN outputs is described as fixed, yet no derivation or sensitivity analysis is provided for how its value is selected across models; this risks making the method less parameter-free than asserted.
Authors: We acknowledge that additional justification is warranted. The coefficient was selected via preliminary tuning to balance hallucination reduction against capability preservation. In the revision we will include a sensitivity analysis across a range of coefficient values for LLaVA-1.5, mPLUG-Owl2, and InstructBLIP, together with a short rationale for the chosen operating point, to better substantiate the method's parameter-free character. revision: yes
Circularity Check
No significant circularity; derivation is empirical and self-contained
full rationale
The paper's central chain proceeds from an empirical layer-wise information flow analysis (attention aggregates visual evidence; FFN at critical layers supplies overriding language priors) to a training-free attenuation intervention (FADE). This observation is presented as a direct mechanistic finding rather than a fitted parameter or self-referential definition, and the method is explicitly training-free with no equations that rename inputs as predictions. No self-citations are invoked as load-bearing uniqueness theorems, and external benchmarks (POPE, CHAIR, MME) supply independent falsifiability. The derivation therefore remains self-contained against external data rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[2]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Mitigating object hallucinations in large vision-language models with assembly of global and local attention , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[3]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Eliciting latent predictions from transformers with the tuned lens , author=. arXiv preprint arXiv:2303.08112 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
European conference on computer vision , pages=
Uniter: Universal image-text representation learning , author=. European conference on computer vision , pages=. 2020 , organization=
2020
-
[6]
Science China Information Sciences , volume=
How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites , author=. Science China Information Sciences , volume=. 2024 , publisher=
2024
-
[7]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[8]
International Conference on Learning Representations , volume=
Dola: Decoding by contrasting layers improves factuality in large language models , author=. International Conference on Learning Representations , volume=
-
[9]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
A survey on multimodal large language models for autonomous driving , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[10]
Advances in neural information processing systems , volume=
Instructblip: Towards general-purpose vision-language models with instruction tuning , author=. Advances in neural information processing systems , volume=
-
[11]
PaLM-E: An Embodied Multimodal Language Model
Palm-e: An embodied multimodal language model , author=. arXiv preprint arXiv:2303.03378 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Transformer Circuits Thread , volume=
A mathematical framework for transformer circuits , author=. Transformer Circuits Thread , volume=
-
[14]
Fu, Chaoyou and Chen, Peixian and Shen, Yunhang and Qin, Yulei and Zhang, Mengdan and Lin, Xu and Yang, Jinrui and Zheng, Xiawu and Li, Ke and Sun, Xing and Wu, Yunsheng and Ji, Rongrong and Shan, Caifeng and He, Ran , booktitle=
-
[15]
Proceedings of the 2022 conference on empirical methods in natural language processing , pages=
Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space , author=. Proceedings of the 2022 conference on empirical methods in natural language processing , pages=
2022
-
[16]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Transformer feed-forward layers are key-value memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[17]
2025 , eprint=
Hallucination of Multimodal Large Language Models: A Survey , author=. 2025 , eprint=
2025
-
[18]
2024 , eprint=
A Survey on Hallucination in Large Vision-Language Models , author=. 2024 , eprint=
2024
-
[19]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[20]
International Conference on Learning Representations , volume=
Self-Introspective Decoding: Alleviating Hallucinations for Large Vision-Language Models , author=. International Conference on Learning Representations , volume=
-
[21]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[22]
Advances in Neural Information Processing Systems , volume=
Code: Contrasting self-generated description to combat hallucination in large multi-modal models , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mitigating object hallucinations in large vision-language models through visual contrastive decoding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[24]
arXiv preprint arXiv:2508.01653 , year=
MAP: Mitigating Hallucinations in Large Vision-Language Models with Map-Level Attention Processing , author=. arXiv preprint arXiv:2508.01653 , year=
-
[25]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[26]
International conference on machine learning , pages=
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[27]
Advances in neural information processing systems , volume=
Align before fuse: Vision and language representation learning with momentum distillation , author=. Advances in neural information processing systems , volume=
-
[28]
European conference on computer vision , pages=
Oscar: Object-semantics aligned pre-training for vision-language tasks , author=. European conference on computer vision , pages=. 2020 , organization=
2020
-
[29]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Evaluating object hallucination in large vision-language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[30]
arXiv preprint arXiv:2502.03628 , year=
The hidden life of tokens: Reducing hallucination of large vision-language models via visual information steering , author=. arXiv preprint arXiv:2502.03628 , year=
-
[31]
International Conference on Learning Representations , volume=
Mitigating hallucination in large multi-modal models via robust instruction tuning , author=. International Conference on Learning Representations , volume=
-
[32]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[33]
LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Li, Bo and Zhang, Yuanhan and Shen, Sheng and Lee, Yong Jae , month=. LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
-
[34]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[35]
International Conference on Learning Representations , volume=
Reducing hallucinations in large vision-language models via latent space steering , author=. International Conference on Learning Representations , volume=
-
[36]
European Conference on Computer Vision , pages=
Paying more attention to image: A training-free method for alleviating hallucination in lvlms , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[37]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Mitigating hallucinations in large vision-language models (lvlms) via language-contrastive decoding (lcd) , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[38]
Advances in neural information processing systems , volume=
Locating and editing factual associations in gpt , author=. Advances in neural information processing systems , volume=
-
[39]
International Conference on Learning Representations , volume=
Towards interpreting visual information processing in vision-language models , author=. International Conference on Learning Representations , volume=
-
[40]
2026 , eprint=
Intervene-All-Paths: Unified Mitigation of LVLM Hallucinations across Alignment Formats , author=. 2026 , eprint=
2026
-
[41]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[42]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
Object hallucination in image captioning , author=. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
2018
-
[43]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Aligning large multimodal models with factually augmented rlhf , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[44]
International Conference on Learning Representations , volume=
Redeep: Detecting hallucination in retrieval-augmented generation via mechanistic interpretability , author=. International Conference on Learning Representations , volume=
-
[45]
Mitigating Hallucinations via Inter-Layer Consistency Aggregation in Large Vision-Language Models
Mitigating Hallucinations via Inter-Layer Consistency Aggregation in Large Vision-Language Models , author=. arXiv preprint arXiv:2505.12343 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Vigc: Visual instruction generation and correction , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[49]
The Thirteenth International Conference on Learning Representations , year=
Damo: Decoding by accumulating activations momentum for mitigating hallucinations in vision-language models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[50]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Mitigating hallucinations in large vision-language models with instruction contrastive decoding , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[52]
Simvlm: Simple visual language model pretraining with weak supervision
Simvlm: Simple visual language model pretraining with weak supervision , author=. arXiv preprint arXiv:2108.10904 , year=
-
[53]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Proceedings of the ieee/cvf conference on computer vision and pattern recognition , pages=
mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration , author=. Proceedings of the ieee/cvf conference on computer vision and pattern recognition , pages=
-
[55]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[56]
Advances in Neural Information Processing Systems , volume=
FlexAC: Towards Flexible Control of Associative Reasoning in Multimodal Large Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Vinvl: Revisiting visual representations in vision-language models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[58]
Chain-of-Thought Compression Should Not Be Blind: V-Skip for Efficient Multimodal Reasoning via Dual-Path Anchoring , author=. Ann. Meet. Assoc. Comput. Linguist. , year=
-
[59]
Not All Errors Are Created Equal: ASCoT Addresses Late-Stage Fragility in Efficient LLM Reasoning , author=. arXiv Prepr. arXiv:2508.05282 , year=
-
[60]
PointCoT: A Multi-modal Benchmark for Explicit 3D Geometric Reasoning , author=. arXiv Prepr. arXiv:2602.23945 , year=
-
[61]
Not all queries need deep thought: Coficot for adaptive coarse-to-fine stateful refinement , author=. Ann. Conf. Uncertain. Artif. Intell. , year=
-
[62]
Beyond Hallucinations: Enhancing LVLMs through Hallucination-Aware Direct Preference Optimization
Beyond hallucinations: Enhancing lvlms through hallucination-aware direct preference optimization , author=. arXiv preprint arXiv:2311.16839 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
International Conference on Learning Representations , volume=
Analyzing and mitigating object hallucination in large vision-language models , author=. International Conference on Learning Representations , volume=
-
[64]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , author=. arXiv preprint arXiv:2308.12966 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.