Diversity is the Strength of the AI Crowd
Pith reviewed 2026-06-30 06:46 UTC · model grok-4.3
The pith
Ensembles gain more from diverse AI forecasters than from additional similar ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
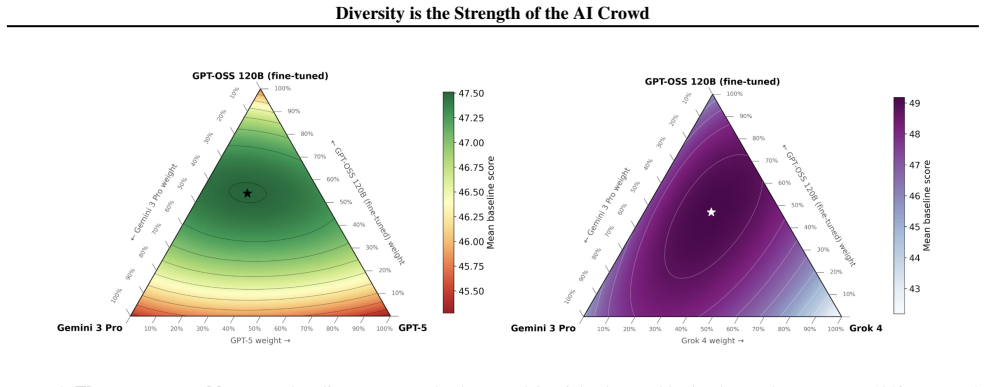
On binary questions from the Metaculus AI Benchmark, ensemble accuracy improves most when forecasts come from models that are both individually accurate and mutually uncorrelated in their errors. Many frontier LLMs make highly correlated predictions, which caps the value of drawing more samples from them or from close relatives. Models such as Grok 4 contribute disproportionately to the best ensembles because their forecasts show lower correlation with other leading LLMs, allowing the combination to cancel shared mistakes. The paper concludes that the strength of the AI crowd lies in combining forecasts across models with complementary errors rather than sampling more indiscriminately.
What carries the argument
Correlation between different LLMs' probability outputs on the same benchmark questions; high correlation reduces the marginal value of each new forecast in the ensemble.
Load-bearing premise
The measured correlations between model predictions on the Metaculus questions used here are stable enough across question types and time periods to explain the observed ensemble gains.
What would settle it
A fresh set of Metaculus binary questions on which the low-correlation models no longer raise ensemble accuracy above the level achieved by high-correlation models alone.
Figures


read the original abstract
Top AI forecasting systems are approaching superforecaster-level accuracy on future world events, but still rely primarily on off-the-shelf LLMs combined with forecasting-specific context gathering and scaffolding. We study how to improve this recipe through ensembling: given a fixed number of samples, which off-the-shelf model forecasts should be combined to maximize accuracy? On binary questions from the Metaculus AI Benchmark, we find that individual accuracy is not enough: many frontier LLMs make highly correlated predictions, limiting the value of additional forecasts from the same or similar models. Instead, the strongest ensembles combine accurate but diverse forecasters, with models such as \model{Grok 4} contributing disproportionately because their predictions are less correlated with other frontier LLMs. These results suggest that the strength of the AI crowd comes not from sampling more forecasts indiscriminately, but from combining forecasts across models with complementary errors, motivating forecasting systems that explicitly optimize for both model quality and diversity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines ensembling off-the-shelf LLMs for binary forecasting questions on the Metaculus AI Benchmark. It claims that individual model accuracy is insufficient because frontier LLMs produce highly correlated predictions; the strongest ensembles instead combine accurate but diverse forecasters, with models such as Grok 4 contributing disproportionately due to lower correlations with other models. The results motivate forecasting systems that explicitly optimize for both quality and diversity rather than sampling more forecasts indiscriminately.
Significance. If the empirical findings on correlation-driven ensemble gains hold after robustness checks, the work would provide concrete guidance for constructing AI forecasting ensembles and underscore that complementary error patterns, rather than model count alone, determine performance. The absence of free parameters or invented entities in the core claim is a strength, but the result remains empirical and would benefit from explicit falsifiability tests.
major comments (3)
- [Abstract / Methods] The central claim that low pairwise correlations causally improve ensemble accuracy (abstract) rests on the untested assumption that these correlations are stable across time windows, question domains, and resolution horizons. The manuscript should report robustness checks (e.g., split-sample correlations by year or topic) or else qualify the recommendation to optimize explicitly for low-correlation models.
- [Abstract] No information is supplied on sample size, exact ensemble construction method, statistical tests for correlation differences, controls for question difficulty, or error bars on the reported gains. These omissions leave the quantitative support for the 'disproportionate contribution' of Grok 4 and the diversity-over-accuracy conclusion without visible derivation.
- [Results] The weakest assumption—that measured correlations reflect stable complementary errors rather than unmeasured factors such as differing calibration or information access—requires either a causal analysis or at minimum a comparison of ensemble performance when diversity is controlled versus when accuracy alone is maximized.
minor comments (1)
- [Abstract] The notation \model{Grok 4} should be defined on first use or replaced with consistent plain text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify important areas for strengthening the manuscript's clarity, robustness, and interpretability. We respond to each major comment below, indicating planned revisions where feasible.
read point-by-point responses
-
Referee: [Abstract / Methods] The central claim that low pairwise correlations causally improve ensemble accuracy (abstract) rests on the untested assumption that these correlations are stable across time windows, question domains, and resolution horizons. The manuscript should report robustness checks (e.g., split-sample correlations by year or topic) or else qualify the recommendation to optimize explicitly for low-correlation models.
Authors: We agree that demonstrating stability strengthens the claim. The full analysis uses the complete Metaculus AI Benchmark, which spans multiple years, topics, and horizons, but we did not previously report subset-specific correlations. In revision we will add split-sample correlation analyses by year and by topic (and, where sample permits, by resolution horizon) in the methods and results sections. If the low-correlation patterns and ensemble gains are stable, we will report this explicitly; if not, we will qualify the recommendation to optimize for diversity as the referee suggests. revision: yes
-
Referee: [Abstract] No information is supplied on sample size, exact ensemble construction method, statistical tests for correlation differences, controls for question difficulty, or error bars on the reported gains. These omissions leave the quantitative support for the 'disproportionate contribution' of Grok 4 and the diversity-over-accuracy conclusion without visible derivation.
Authors: The full manuscript contains the benchmark size, describes ensembles as unweighted averages of selected model probabilities, and reports correlation coefficients with some significance testing, but these details are not summarized in the abstract. We will revise the abstract to state the number of binary questions analyzed, briefly describe the ensemble construction procedure, note the statistical tests applied to correlation differences, mention any stratification or controls for question difficulty, and include error bars or confidence intervals on the reported ensemble gains. This will make the quantitative support visible at the abstract level. revision: yes
-
Referee: [Results] The weakest assumption—that measured correlations reflect stable complementary errors rather than unmeasured factors such as differing calibration or information access—requires either a causal analysis or at minimum a comparison of ensemble performance when diversity is controlled versus when accuracy alone is maximized.
Authors: We concur that the observational design limits causal claims about complementary errors. A full causal analysis is not feasible with the current data. However, we will add an ablation that directly compares (i) ensembles formed by selecting the most accurate models and (ii) ensembles formed by jointly optimizing accuracy and low pairwise correlation. This comparison will quantify the incremental value of diversity beyond accuracy alone and will be reported in the revised results section. revision: partial
Circularity Check
No circularity; empirical measurements of correlations and ensemble gains are independent of inputs
full rationale
The paper derives its central claim from direct computation of pairwise prediction correlations on the external Metaculus AI Benchmark dataset, followed by explicit ensemble accuracy measurements when combining models. No equations define a quantity in terms of itself, no fitted parameters are relabeled as out-of-sample predictions, and no self-citations or prior-author uniqueness theorems are invoked to close the argument. The reported finding that low-correlation models (e.g., Grok 4) improve ensembles is a straightforward empirical outcome on held-out benchmark questions rather than a self-referential construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM outputs on binary forecasting questions can be meaningfully compared via correlation and combined in ensembles to improve accuracy
Reference graph
Works this paper leans on
-
[1]
, journal =
Schoenegger, Philipp and Park, Peter S. , journal =. Large language model prediction capabilities:
-
[2]
Advances in Neural Information Processing Systems , year =
Forecasting future world events with neural networks , author =. Advances in Neural Information Processing Systems , year =
-
[3]
Advances in Neural Information Processing Systems , year =
Approaching human-level forecasting with language models , author =. Advances in Neural Information Processing Systems , year =
-
[4]
and Bastos, Rafael Valdece Sousa and Tetlock, Philip E
Schoenegger, Philipp and Tuminauskaite, Indre and Park, Peter S. and Bastos, Rafael Valdece Sousa and Tetlock, Philip E. , journal =. Wisdom of the silicon crowd:. 2024 , publisher =
2024
-
[5]
, booktitle =
Karger, Ezra and Bastani, Houtan and Yueh-Han, Chen and Jacobs, Zachary and Halawi, Danny and Zhang, Fred and Tetlock, Philip E. , booktitle =. 2025 , note =
2025
-
[6]
Zeng, Zhiyuan and others , journal =
-
[7]
, journal =
Murphy, Kevin P. , journal =. Agentic forecasting using sequential
-
[8]
Turtel, Benjamin and others , journal =
-
[9]
Outcome- based reinforcement learning to predict the future
Outcome-based reinforcement learning to predict the future , author =. arXiv preprint arXiv:2505.17989 , year =
-
[10]
Advances in Neural Information Processing Systems , year =
Neural network ensembles, cross validation, and active learning , author =. Advances in Neural Information Processing Systems , year =
-
[11]
Information Fusion , volume =
Diversity creation methods: a survey and categorisation , author =. Information Fusion , volume =
-
[12]
Journal of Machine Learning Research , volume =
A unified theory of diversity in ensemble learning , author =. Journal of Machine Learning Research , volume =
-
[13]
Journal of the American Statistical Association , volume =
Strictly proper scoring rules, prediction, and estimation , author =. Journal of the American Statistical Association , volume =
-
[14]
Jiang, Dongfu and Ren, Xiang and Lin, Bill Yuchen , booktitle =
-
[15]
International Conference on Machine Learning , year =
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time , author =. International Conference on Machine Learning , year =
-
[16]
International Journal of Forecasting , volume =
Combining multiple probability predictions using a simple logit model , author =. International Journal of Forecasting , volume =
-
[17]
Superforecasting: The art and science of prediction , author =
-
[18]
Metaculus scoring documentation: Baseline score , author =
-
[19]
Thinking Machines Lab: Connectionism , year =
Horace He and Thinking Machines Lab , title =. Thinking Machines Lab: Connectionism , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.