DCGrasp: Distance-aware Controllable Grasp Generation
Pith reviewed 2026-06-30 06:11 UTC · model grok-4.3
The pith
DCGrasp generates controllable 3D hand-object grasps from distance profiles that generalize across shapes and scales.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
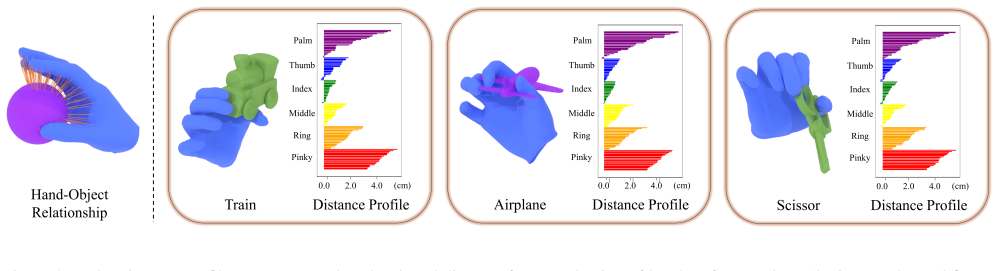
DCGrasp uses a novel grasp energy term that computes the Distance Profile—a signed distance from each hand vertex to the nearest object point—paired with distance-aware weighting. This captures semantically similar hand-object interactions in near-contact regions invariantly to object and hand identity. The system generates the Distance Profile via a Diffusion Transformer along with a candidate hand pose, then refines the pose through optimization to enforce consistency with the generated profile.
What carries the argument
The Distance Profile, defined as the signed distance from each hand vertex to the nearest object point, combined with distance-aware weighting in the grasp energy term.
If this is right
- User-provided control signals can steer grasp generation while the distance-profile consistency step maintains physical plausibility.
- The same pipeline applies to object and hand instances of different shapes and sizes without retraining.
- The generated interactions can serve directly as synthetic data for robotics or XR pipelines.
- Optimization enforces agreement between the generated profile and the final pose specifically in near-contact regions.
Where Pith is reading between the lines
- The identity-invariant distance representation could support transfer of interaction patterns to non-grasp tasks such as tool use.
- Real-time variants might replace the diffusion step with a faster predictor while retaining the profile-matching optimization.
- Combining the profiles with object dynamics could extend the method to moving or articulated objects.
- The weighting scheme might be adapted to other distance-based signals such as surface normals or penetration depth.
Load-bearing premise
The grasp energy term based on Distance Profile and distance-aware weighting effectively captures semantically similar hand-object interactions in near-contact regions while remaining invariant to object and hand identity.
What would settle it
If grasps produced for previously unseen object shapes and hand scales fail to produce stable contacts or physically plausible configurations when evaluated in a physics simulator, the generalization and invariance claims would not hold.
Figures



read the original abstract
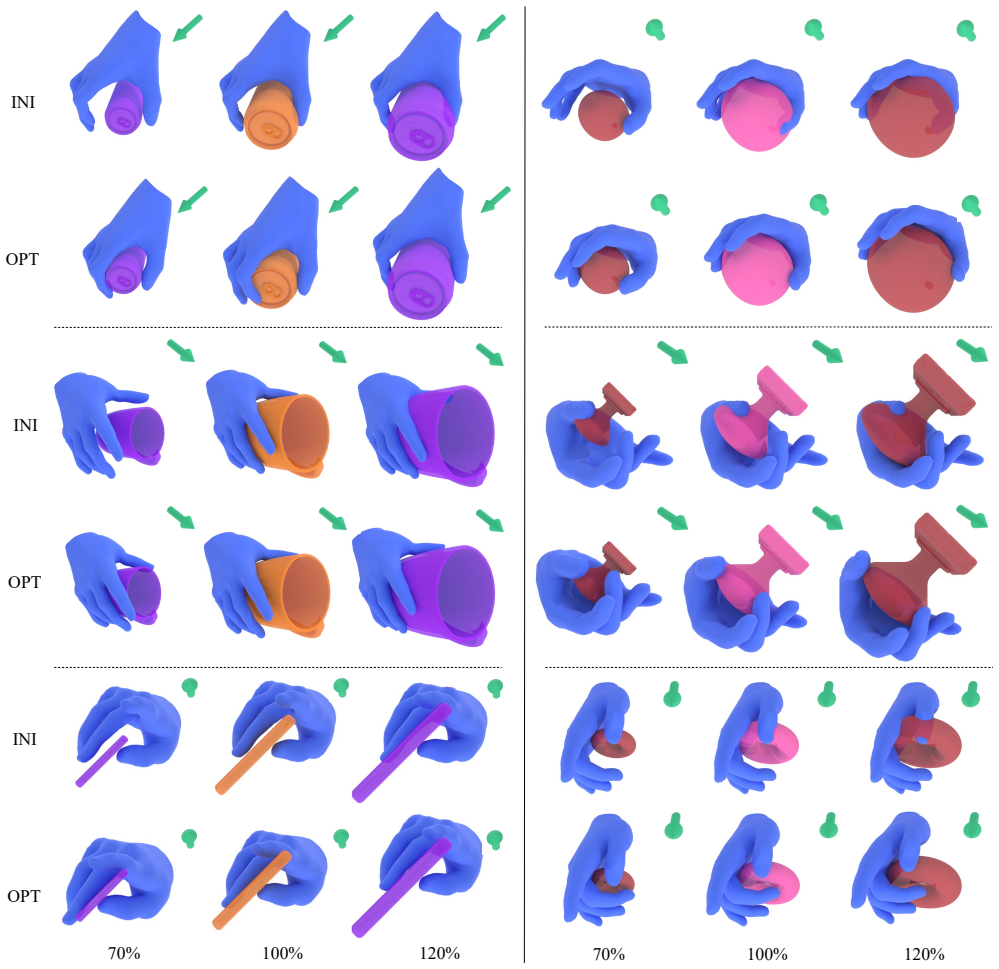
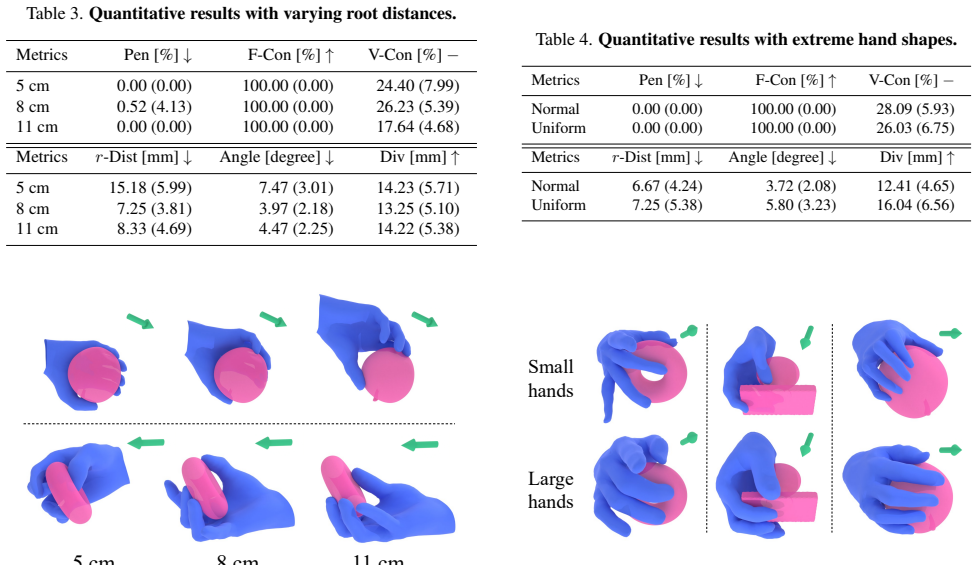
Generating 3D hand-object interactions is essential for applications in robotics, XR, and synthetic data generation, where flexible controllability and strong generalization to diverse object geometries are required. However, existing methods rarely satisfy these requirements, limiting their practical applicability. We present DCGrasp, a distance-aware controllable grasp generation system built on a novel grasp energy term. This term computes Distance Profile, a signed distance from each hand vertex to the nearest object point, coupled with distance-aware weighting, effectively capturing the semantically similar hand-object interaction in near-contact regions while remaining invariant to object and hand identity. Given various controllable signals, DCGrasp first generates a Distance Profile based on a Diffusion Transformer, together with a corresponding candidate hand pose. We then refine the candidate pose through optimization, enforcing consistency between the optimized hand pose and the generated Distance Profile in near-contact regions. Our experiments show that DCGrasp produces high-quality, physically plausible grasps with flexible user control, generalizing to diverse object and hand shapes and scales. Our work establishes a robust and versatile pipeline for the synthesis of controllable 3D hand-object interactions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents DCGrasp, a system for generating controllable 3D hand-object grasps. It introduces a grasp energy term based on a Distance Profile (per-vertex signed distance to the nearest object point) combined with distance-aware weighting, asserted to capture semantically similar near-contact interactions invariantly to hand and object identity. A Diffusion Transformer generates the profile and candidate hand pose from controllable signals; an optimization step then refines the pose to enforce consistency with the profile. Experiments claim high-quality, physically plausible grasps with flexible control and generalization across diverse object/hand shapes and scales.
Significance. If the invariance property of the Distance Profile holds and is empirically validated, the approach could meaningfully advance controllable grasp synthesis for robotics, XR, and data generation by combining diffusion-based generation with energy-based refinement. The pipeline addresses a practical gap in existing methods regarding controllability and cross-identity generalization.
major comments (3)
- [§3] §3 (Grasp Energy Term): The definition of Distance Profile as signed distance plus distance-aware weighting is asserted to be invariant to hand/object identity and to capture semantic near-contact interactions, but no explicit normalization factor, scaling term, or derivation is provided showing how the weighting eliminates geometry-dependent differences (e.g., for scaled hands or topologically distinct objects in equivalent contact). This invariance is load-bearing for both the generalization claim and the subsequent optimization consistency step.
- [§4] §4 (Method, Diffusion Transformer and Optimization): No ablation is reported that isolates the contribution of the distance-aware weighting versus a baseline signed-distance term, nor any quantitative test (e.g., profile similarity metrics across scaled or varied geometries) demonstrating that the generated profiles remain equivalent under identity changes while preserving contact semantics. Without such evidence the central generalization result cannot be verified.
- [§5] §5 (Experiments): The reported results on physical plausibility and generalization lack error bars, statistical significance tests, or cross-dataset evaluation on held-out scales/topologies; it is therefore unclear whether the claimed superiority over prior methods is robust or driven by the unverified invariance assumption.
minor comments (2)
- [§3] Notation for the Distance Profile and weighting function should be introduced with explicit equations early in §3 rather than described narratively.
- [§5] Figure captions and axis labels in the qualitative results should explicitly state the controllable signals used for each example to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where our claims on invariance and experimental validation require stronger support. We address each major comment below and commit to revisions that add the requested derivations, ablations, and statistical analyses without altering the core technical contributions.
read point-by-point responses
-
Referee: [§3] §3 (Grasp Energy Term): The definition of Distance Profile as signed distance plus distance-aware weighting is asserted to be invariant to hand/object identity and to capture semantic near-contact interactions, but no explicit normalization factor, scaling term, or derivation is provided showing how the weighting eliminates geometry-dependent differences (e.g., for scaled hands or topologically distinct objects in equivalent contact). This invariance is load-bearing for both the generalization claim and the subsequent optimization consistency step.
Authors: We agree that the manuscript lacks an explicit derivation of the invariance property. The distance-aware weighting applies an exponential decay based on the signed distance to prioritize near-contact vertices, which are intended to encode interaction semantics independent of global scale or topology. However, no formal normalization or proof under scaling/topology variation was included. In the revision we will add a dedicated subsection deriving the invariance under uniform scaling (showing the weighting normalizes relative distances) and provide empirical profile comparisons across topologically distinct objects. revision: yes
-
Referee: [§4] §4 (Method, Diffusion Transformer and Optimization): No ablation is reported that isolates the contribution of the distance-aware weighting versus a baseline signed-distance term, nor any quantitative test (e.g., profile similarity metrics across scaled or varied geometries) demonstrating that the generated profiles remain equivalent under identity changes while preserving contact semantics. Without such evidence the central generalization result cannot be verified.
Authors: The referee correctly notes the absence of these ablations and quantitative tests. The current manuscript relies on qualitative generalization results and end-to-end performance rather than isolating the weighting term. We will add an ablation study comparing the full distance-aware energy against a plain signed-distance baseline, together with quantitative metrics (e.g., mean profile L2 distance and contact-semantic preservation scores) evaluated on scaled hand/object variants and held-out topologies. These results will be inserted into Section 5. revision: yes
-
Referee: [§5] §5 (Experiments): The reported results on physical plausibility and generalization lack error bars, statistical significance tests, or cross-dataset evaluation on held-out scales/topologies; it is therefore unclear whether the claimed superiority over prior methods is robust or driven by the unverified invariance assumption.
Authors: We acknowledge that the experiments section does not report error bars, statistical tests, or explicit held-out scale/topology splits. The presented numbers are single-run point estimates on the evaluated datasets. In the revision we will recompute all metrics with error bars over five random seeds, include paired t-tests against baselines, and add cross-dataset results on held-out object scales and topologies drawn from additional sources to directly test the generalization claim. revision: yes
Circularity Check
No significant circularity; central construction is a novel ansatz without reduction to fitted inputs or self-citations
full rationale
The paper defines a grasp energy term via Distance Profile (signed per-vertex distance to nearest object point) plus distance-aware weighting, asserting invariance to identity and semantic capture of near-contact interactions. This is presented as a design choice enabling the diffusion+optimization pipeline, not derived from or equivalent to any fitted parameter or prior self-cited result within the given text. No equations, self-citation chains, or renamings of known results appear that would force the claimed generalization or plausibility by construction. The reader's assessment of score 2 aligns with absence of load-bearing self-reference or definitional loops.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Distance Profile
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Karen Liu
Jo ˜ao Pedro Ara´ujo, Jiaman Li, Karthik Vetrivel, Rishi Agar- wal, Jiajun Wu, Deepak Gopinath, Alexander Clegg, and C. Karen Liu. CIRCLE: Capture in rich contextual environ- ments. InComputer Vision and Pattern Recognition (CVPR), pages 21211–21221, 2023. 3
2023
-
[2]
Motion capture of hands in action using discriminative salient points
Luca Ballan, Aparna Taneja, J ¨urgen Gall, Luc Van Gool, and Marc Pollefeys. Motion capture of hands in action using discriminative salient points. InEuropean Conference on Computer Vision (ECCV), pages 640–653, 2012. 2
2012
-
[3]
Kemp, and James Hays
Samarth Brahmbhatt, Cusuh Ham, Charles C. Kemp, and James Hays. ContactDB: Analyzing and predicting grasp contact via thermal imaging. InComputer Vision and Pat- tern Recognition (CVPR), pages 8709–8719, 2019. 3
2019
-
[4]
ContactGrasp: Functional multi-finger grasp synthe- sis from contact
Samarth Brahmbhatt, Ankur Handa, James Hays, and Dieter Fox. ContactGrasp: Functional multi-finger grasp synthe- sis from contact. InInternational Conference on Intelligent Robots and Systems (IROS), pages 2386–2393, 2019. 3
2019
-
[5]
Twigg, Charles C
Samarth Brahmbhatt, Chengcheng Tang, Christopher D. Twigg, Charles C. Kemp, and James Hays. ContactPose: A dataset of grasps with object contact and hand pose. InEu- ropean Conference on Computer Vision (ECCV), pages 361– 378, 2020. 3
2020
-
[6]
In- structpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. In- structpix2pix: Learning to follow image editing instructions. InComputer Vision and Pattern Recognition (CVPR), 2023. 4 10
2023
-
[7]
Text2hoi: Text-guided 3d motion generation for hand- object interaction
Junuk Cha, Jihyeon Kim, Jae Shin Yoon, and Seungryul Baek. Text2hoi: Text-guided 3d motion generation for hand- object interaction. InComputer Vision and Pattern Recogni- tion (CVPR), 2024. 3
2024
-
[8]
Narang, Karl Van Wyk, Umar Iqbal, Stan Birchfield, Jan Kautz, and Dieter Fox
Yu-Wei Chao, Wei Yang, Yu Xiang, Pavlo Molchanov, Ankur Handa, Jonathan Tremblay, Yashraj S. Narang, Karl Van Wyk, Umar Iqbal, Stan Birchfield, Jan Kautz, and Dieter Fox. DexYCB: Abenchmark for capturing hand grasping of objects. InComputer Vision and Pattern Recog- nition (CVPR), pages 9044–9053, 2021. 3
2021
-
[9]
D-Grasp: Physically plausible dynamic grasp synthesis for hand-object interactions
Sammy Joe Christen, Muhammed Kocabas, Emre Aksan, Jemin Hwangbo, Jie Song, and Otmar Hilliges. D-Grasp: Physically plausible dynamic grasp synthesis for hand-object interactions. InComputer Vision and Pattern Recognition (CVPR), pages 20577–20586, 2022. 3
2022
-
[10]
GanHand: Predicting human grasp affordances in multi-object scenes
Enric Corona, Albert Pumarola, Guillem Aleny `a, Francesc Moreno-Noguer, and Gr´egory Rogez. GanHand: Predicting human grasp affordances in multi-object scenes. InCom- puter Vision and Pattern Recognition (CVPR), pages 5031– 5041, 2020. 3
2020
-
[11]
Newcombe, and Lingni Ma
Enric Corona, Tomas Hodan, Minh V o, Francesc Moreno- Noguer, Chris Sweeney, Richard A. Newcombe, and Lingni Ma. LISA: learning implicit shape and appearance of hands. InComputer Vision and Pattern Recognition (CVPR), pages 20501–20511, 2022. 2
2022
-
[12]
Markos Diomataris, Nikos Athanasiou, Omid Taheri, Xi Wang, Otmar Hilliges, and Michael J. Black. W ANDR: Intention-guided human motion generation. InComputer Vi- sion and Pattern Recognition (CVPR), pages 927–936, 2024. 3
2024
-
[13]
Black, and Otmar Hilliges
Zicong Fan, Omid Taheri, Dimitrios Tzionas, Muhammed Kocabas, Manuel Kaufmann, Michael J. Black, and Otmar Hilliges. ARCTIC: A dataset for dexterous bimanual hand- object manipulation. InComputer Vision and Pattern Recog- nition (CVPR), pages 12943–12954, 2023. 3
2023
-
[14]
Black, and Otmar Hilliges
Zicong Fan, Maria Parelli, Maria Eleni Kadoglou, Xu Chen, Muhammed Kocabas, Michael J. Black, and Otmar Hilliges. HOLD: Category-agnostic 3D reconstruction of interacting hands and objects from video. InComputer Vision and Pat- tern Recognition (CVPR), pages 494–504, 2024. 3
2024
-
[15]
First-person hand action bench- mark with RGB-D videos and 3D hand pose annotations
Guillermo Garcia-Hernando, Shanxin Yuan, Seungryul Baek, and Tae-Kyun Kim. First-person hand action bench- mark with RGB-D videos and 3D hand pose annotations. InComputer Vision and Pattern Recognition (CVPR), pages 409–419, 2018. 3
2018
-
[16]
IMoS: Intent-driven full-body motion synthesis for human-object interactions
Anindita Ghosh, Rishabh Dabral, Vladislav Golyanik, Chris- tian Theobalt, and Philipp Slusallek. IMoS: Intent-driven full-body motion synthesis for human-object interactions. In Computer Graphics Forum (CGF), 2023. 3
2023
-
[17]
Twigg, Minh V o, Samarth Brahmbhatt, and Charles C
Patrick Grady, Chengcheng Tang, Christopher D. Twigg, Minh V o, Samarth Brahmbhatt, and Charles C. Kemp. Con- tactOpt: Optimizing contact to improve grasps. InComputer Vision and Pattern Recognition (CVPR), pages 1471–1481,
-
[18]
HOnnotate: A method for 3D annotation of hand and object poses
Shreyas Hampali, Mahdi Rad, Markus Oberweger, and Vin- cent Lepetit. HOnnotate: A method for 3D annotation of hand and object poses. InComputer Vision and Pattern Recognition (CVPR), pages 3196–3206, 2020. 3
2020
-
[19]
Keypoint transformer: Solving joint identifica- tion in challenging hands and object interactions for accurate 3D pose estimation
Shreyas Hampali, Sayan Deb Sarkar, Mahdi Rad, and Vin- cent Lepetit. Keypoint transformer: Solving joint identifica- tion in challenging hands and object interactions for accurate 3D pose estimation. InComputer Vision and Pattern Recog- nition (CVPR), pages 11090–11100, 2022. 3
2022
-
[20]
Hand-centric motion refinement for 3d hand-object interaction via hierarchical spatial-temporal modeling
Yuze Hao, Jianrong Zhang, Tao Zhuo, Fuan Wen, and Hehe Fan. Hand-centric motion refinement for 3d hand-object interaction via hierarchical spatial-temporal modeling. In AAAI Conference on Artificial Intelligence, 2024. 3
2024
-
[21]
Black, Ivan Laptev, and Cordelia Schmid
Yana Hasson, G ¨ul Varol, Dimitrios Tzionas, Igor Kale- vatykh, Michael J. Black, Ivan Laptev, and Cordelia Schmid. Learning joint reconstruction of hands and manipulated ob- jects. InComputer Vision and Pattern Recognition (CVPR), pages 11807–11816, 2019. 3
2019
-
[22]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 4
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Dy- namic handover: Throw and catch with bimanual hands
Binghao Huang, Yuanpei Chen, Tianyu Wang, Yuzhe Qin, Yaodong Yang, Nikolay Atanasov, and Xiaolong Wang. Dy- namic handover: Throw and catch with bimanual hands. Conference on Robot Learning (CoRL), 2023. 3
2023
-
[24]
Hand-object contact consistency reasoning for human grasps generation
Hanwen Jiang, Shaowei Liu, Jiashun Wang, and Xiaolong Wang. Hand-object contact consistency reasoning for human grasps generation. InInternational Conference on Computer Vision (ICCV), pages 11087–11096, 2021. 2, 3
2021
-
[25]
Black, Krikamol Muandet, and Siyu Tang
Korrawe Karunratanakul, Jinlong Yang, Yan Zhang, Michael J. Black, Krikamol Muandet, and Siyu Tang. Grasping field: Learning implicit representations for human grasps. InInternational Conference on 3D Vision (3DV), pages 333–344, 2020. 2
2020
-
[26]
H2O: Two hands manipulating objects for first person interaction recognition
Taein Kwon, Bugra Tekin, Jan St ¨uhmer, Federica Bogo, and Marc Pollefeys. H2O: Two hands manipulating objects for first person interaction recognition. InInternational Confer- ence on Computer Vision (ICCV), pages 10138–10148, 2021. 3
2021
-
[27]
Interhandgen: Two-hand interaction generation via cascaded reverse diffusion
Jihyun Lee, Shunsuke Saito, Giljoo Nam, Minhyuk Sung, and Tae-Kyun Kim. Interhandgen: Two-hand interaction generation via cascaded reverse diffusion. InComputer Vi- sion and Pattern Recognition (CVPR), 2024. 3
2024
-
[28]
Dextouch: Learning to seek and manipulate objects with tactile dexterity.Robotics and Automation Letters (RA- L), 2024
Kang-Won Lee, Yuzhe Qin, Xiaolong Wang, and Soo-Chul Lim. Dextouch: Learning to seek and manipulate objects with tactile dexterity.Robotics and Automation Letters (RA- L), 2024. 3
2024
-
[29]
Karen Liu
Jiaman Li, Jiajun Wu, and C. Karen Liu. Object motion guided human motion synthesis. InTransactions on Graph- ics (TOG), pages 197:1–197:11, 2023. 3
2023
-
[30]
Latenthoi: On the generalizable hand object motion generation with latent hand diffusion
Muchen Li, Sammy Christen, Chengde Wan, Yujun Cai, Renjie Liao, Leonid Sigal, and Shugao Ma. Latenthoi: On the generalizable hand object motion generation with latent hand diffusion. InComputer Vision and Pattern Recognition (CVPR), 2025. 3
2025
-
[31]
NIMBLE: A non-rigid hand model with bones and mus- cles.Transactions on Graphics (TOG), 41(4):120:1–120:16,
Yuwei Li, Longwen Zhang, Zesong Qiu, Yingwenqi Jiang, Nianyi Li, Yuexin Ma, Yuyao Zhang, Lan Xu, and Jingyi Yu. NIMBLE: A non-rigid hand model with bones and mus- cles.Transactions on Graphics (TOG), 41(4):120:1–120:16,
-
[32]
ContactGen: Generative contact modeling 11 for grasp generation
Shaowei Liu, Yang Zhou, Jimei Yang, Saurabh Gupta, and Shenlong Wang. ContactGen: Generative contact modeling 11 for grasp generation. InInternational Conference on Com- puter Vision (ICCV), pages 20552–20563, 2023. 3
2023
-
[33]
GeneOH diffusion: Towards general- izable hand-object interaction denoising via denoising diffu- sion
Xueyi Liu and Li Yi. GeneOH diffusion: Towards general- izable hand-object interaction denoising via denoising diffu- sion. InInternational Conference on Learning Representa- tions (ICLR), 2024. 3
2024
-
[34]
Hoi4d: A 4d egocentric dataset for category-level human- object interaction
Yunze Liu, Yun Liu, Che Jiang, Kangbo Lyu, Weikang Wan, Hao Shen, Boqiang Liang, Zhoujie Fu, He Wang, and Li Yi. Hoi4d: A 4d egocentric dataset for category-level human- object interaction. InComputer Vision and Pattern Recogni- tion (CVPR), 2022. 3
2022
-
[35]
HOI4D: A 4D egocentric dataset for category-level human- object interaction
Yunze Liu, Yun Liu, Che Jiang, Kangbo Lyu, Weikang Wan, Hao Shen, Boqiang Liang, Zhoujie Fu, He Wang, and Li Yi. HOI4D: A 4D egocentric dataset for category-level human- object interaction. InComputer Vision and Pattern Recogni- tion (CVPR), pages 21013–21022, 2022. 3
2022
-
[36]
Taco: Benchmarking general- izable bimanual tool-action-object understanding
Yun Liu, Haolin Yang, Xu Si, Ling Liu, Zipeng Li, Yuxiang Zhang, Yebin Liu, and Li Yi. Taco: Benchmarking general- izable bimanual tool-action-object understanding. InCom- puter Vision and Pattern Recognition (CVPR), 2024. 3
2024
-
[37]
Lorensen and Harvey E
William E. Lorensen and Harvey E. Cline. Marching cubes: A high resolution 3d surface construction algorithm. InInter- national Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), page 163–169, 1987. 2
1987
-
[38]
Graspgen: A diffusion-based framework for 6-dof grasping with on-generator training
Adithyavairavan Murali, Balakumar Sundaralingam, Yu-Wei Chao, Jun Yamada, Wentao Yuan, Mark Carlson, Fabio Ramos, Stan Birchfield, Dieter Fox, and Clemens Eppner. Graspgen: A diffusion-based framework for 6-dof grasping with on-generator training. InInternational Conference on Robotics and Automation (ICRA), 2026. 3
2026
-
[39]
Ar- gyros
Iason Oikonomidis, Nikolaos Kyriazis, and Antonis A. Ar- gyros. Efficient model-based 3D tracking of hand articula- tions using Kinect. InBritish Machine Vision Conference (BMVC), pages 1–11, 2011. 2
2011
-
[40]
3D Whole-body grasp synthesis with directional controllability
Georgios Paschalidis, Romana Wilschut, Dimitrije Anti ´c, Omid Taheri, and Dimitrios Tzionas. 3D Whole-body grasp synthesis with directional controllability. InInternational Conference on 3D Vision (3DV), 2025. 3, 6
2025
-
[41]
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black. Expressive body capture: 3D hands, face, and body from a single image. InComputer Vision and Pat- tern Recognition (CVPR), pages 10975–10985, 2019. 3
2019
-
[42]
Ef- ficient Learning on Point Clouds With Basis Point Sets
Sergey Prokudin, Christoph Lassner, and Javier Romero. Ef- ficient Learning on Point Clouds With Basis Point Sets. In International Conference on Computer Vision (ICCV), pages 4332–4341, 2019. 3
2019
-
[43]
Javier Romero, Dimitrios Tzionas, and Michael J. Black. Embodied hands: Modeling and capturing hands and bod- ies together.Transactions on Graphics (TOG), 36(6):1–17,
-
[44]
Macs: Mass conditioned 3d hand and object motion synthe- sis
Soshi Shimada, Franziska Mueller, Jan Bednarik, Bardia Doosti, Bernd Bickel, Danhang Tang, Vladislav Golyanik, Jonathan Taylor, Christian Theobalt, and Thabo Beeler. Macs: Mass conditioned 3d hand and object motion synthe- sis. InInternational Conference on 3D Vision (3DV), 2024. 3
2024
-
[45]
Denois- ing diffusion implicit models.International Conference on Learning Representations (ICLR), 2021
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models.International Conference on Learning Representations (ICLR), 2021. 5
2021
-
[46]
In- teractive markerless articulated hand motion tracking using rgb and depth data
Srinath Sridhar, Antti Oulasvirta, and Christian Theobalt. In- teractive markerless articulated hand motion tracking using rgb and depth data. InInternational Conference on Com- puter Vision (ICCV), pages 2456–2463, 2013. 2
2013
-
[47]
SHOWMe: Benchmarking object-agnostic hand-object 3D reconstruction
Anilkumar Swamy, Vincent Leroy, Philippe Weinzaepfel, Fabien Baradel, Salma Galaaoui, Romain Br ´egier, Matthieu Armando, Jean-S ´ebastien Franco, and Gr ´egory Rogez. SHOWMe: Benchmarking object-agnostic hand-object 3D reconstruction. InInternational Conference on Computer Vi- sion (ICCV), pages 1927–1936, 2023. 3
1927
-
[48]
Black, and Dim- itrios Tzionas
Omid Taheri, Nima Ghorbani, Michael J. Black, and Dim- itrios Tzionas. GRAB: A dataset of whole-body human grasping of objects. InEuropean Conference on Computer Vision (ECCV), pages 581–600, 2020. 3, 6
2020
-
[49]
Black, and Dim- itrios Tzionas
Omid Taheri, Vasileios Choutas, Michael J. Black, and Dim- itrios Tzionas. GOAL: Generating 4D whole-body motion for hand-object grasping. InComputer Vision and Pattern Recognition (CVPR), pages 13263–13273, 2022. 3
2022
-
[50]
Omid Taheri, Yi Zhou, Dimitrios Tzionas, Yang Zhou, Duygu Ceylan, Soren Pirk, and Michael J. Black. GRIP: Generating interaction poses using spatial cues and latent consistency. InInternational Conference on 3D Vision (3DV), pages 933–943, 2024. 3
2024
-
[51]
FLEX: Full-body grasping without full-body grasps
Purva Tendulkar, D ´ıdac Sur´ıs, and Carl V ondrick. FLEX: Full-body grasping without full-body grasps. InCom- puter Vision and Pattern Recognition (CVPR), pages 21179– 21189, 2023. 3
2023
-
[52]
Dickinson, and Animesh Garg
Dylan Turpin, Liquang Wang, Eric Heiden, Yun-Chun Chen, Miles Macklin, Stavros Tsogkas, Sven J. Dickinson, and Animesh Garg. Grasp’D: Differentiable contact-rich grasp synthesis for multi-fingered hands. InEuropean Conference on Computer Vision (ECCV), pages 201–221, 2022. 3
2022
-
[53]
Fast-grasp’d: Dexterous multi- finger grasp generation through differentiable simulation
Dylan Turpin, Tao Zhong, Shutong Zhang, Guanglei Zhu, Eric Heiden, Miles Macklin, Stavros Tsogkas, Sven Dick- inson, and Animesh Garg. Fast-grasp’d: Dexterous multi- finger grasp generation through differentiable simulation. InInternational Conference on Robotics and Automation (ICRA), 2023. 3
2023
-
[54]
Unidexgrasp++: Im- proving dexterous grasping policy learning via geometry- aware curriculum and iterative generalist-specialist learning
Weikang Wan, Haoran Geng, Yun Liu, Zikang Shan, Yaodong Yang, Li Yi, and He Wang. Unidexgrasp++: Im- proving dexterous grasping policy learning via geometry- aware curriculum and iterative generalist-specialist learning. International Conference on Computer Vision (ICCV), 2023
2023
-
[55]
Cy- berdemo: Augmenting simulated human demonstration for real-world dexterous manipulation
Jun Wang, Yuzhe Qin, Kaiming Kuang, Yigit Korkmaz, Akhilan Gurumoorthy, Hao Su, and Xiaolong Wang. Cy- berdemo: Augmenting simulated human demonstration for real-world dexterous manipulation. InComputer Vision and Pattern Recognition (CVPR), 2024. 3
2024
-
[56]
DexGraspNet: A large-scale robotic dexterous grasp dataset for general ob- jects based on simulation
Ruicheng Wang, Jialiang Zhang, Jiayi Chen, Yinzhen Xu, Puhao Li, Tengyu Liu, and He Wang. DexGraspNet: A large-scale robotic dexterous grasp dataset for general ob- jects based on simulation. InInternational Conference on Robotics and Automation (ICRA), pages 11359–11366,
-
[57]
Dexgraspnet: A large- scale robotic dexterous grasp dataset for general objects based on simulation.International Conference on Robotics and Automation (ICRA), 2022
Ruicheng Wang, Jialiang Zhang, Jiayi Chen, Yinzhen Xu, Puhao Li, Tengyu Liu, and He Wang. Dexgraspnet: A large- scale robotic dexterous grasp dataset for general objects based on simulation.International Conference on Robotics and Automation (ICRA), 2022. 3
2022
-
[58]
SAGA: Stochastic whole-body grasping with contact
Yan Wu, Jiahao Wang, Yan Zhang, Siwei Zhang, Otmar Hilliges, Fisher Yu, and Siyu Tang. SAGA: Stochastic whole-body grasping with contact. InEuropean Conference on Computer Vision (ECCV), pages 257–274, 2022. 3
2022
-
[59]
G-hop: Generative hand-object prior for interaction reconstruction and grasp synthesis
Yufei Ye, Abhinav Gupta, Kris Kitani, and Shubham Tul- siani. G-hop: Generative hand-object prior for interaction reconstruction and grasp synthesis. InComputer Vision and Pattern Recognition (CVPR), 2024. 3
2024
-
[60]
Rotating without seeing: Towards in- hand dexterity through touch.International Conference on Robotics and Automation (ICRA), 2023
Zhao-Heng Yin, Binghao Huang, Yuzhe Qin, Qifeng Chen, and Xiaolong Wang. Rotating without seeing: Towards in- hand dexterity through touch.International Conference on Robotics and Automation (ICRA), 2023. 3
2023
-
[61]
ManipNet: Neural manipulation synthesis with a hand-object spatial representation.Transactions on Graphics (TOG), 40(4):121:1–121:14, 2021
He Zhang, Yuting Ye, Takaaki Shiratori, and Taku Ko- mura. ManipNet: Neural manipulation synthesis with a hand-object spatial representation.Transactions on Graphics (TOG), 40(4):121:1–121:14, 2021. 3
2021
-
[62]
GraspXL: Generating grasping motions for di- verse objects at scale
Hui Zhang, Sammy Christen, Zicong Fan, Otmar Hilliges, and Jie Song. GraspXL: Generating grasping motions for di- verse objects at scale. InEuropean Conference on Computer Vision (ECCV), pages 386–403, 2024. 3
2024
-
[63]
ArtiGrasp: Physically plausible synthesis of bi-manual dexterous grasp- ing and articulation
Hui Zhang, Sammy Christen, Zicong Fan, Luocheng Zheng, Jemin Hwangbo, Jie Song, and Otmar Hilliges. ArtiGrasp: Physically plausible synthesis of bi-manual dexterous grasp- ing and articulation. InInternational Conference on 3D Vi- sion (3DV), 2024. 3
2024
-
[64]
Manidext: Hand-object manipulation synthesis via continuous corre- spondence embeddings and residual-guided diffusion
Jiajun Zhang, Yuxiang Zhang, Liang An, Mengcheng Li, Hongwen Zhang, Zonghai Hu, and Yebin Liu. Manidext: Hand-object manipulation synthesis via continuous corre- spondence embeddings and residual-guided diffusion. 2025. 3
2025
-
[65]
HOIDiffusion: Generating realistic 3D hand-object interaction data
Mengqi Zhang, Yang Fu, Zheng Ding, Sifei Liu, Zhuowen Tu, and Xiaolong Wang. HOIDiffusion: Generating realistic 3D hand-object interaction data. InComputer Vision and Pattern Recognition (CVPR), pages 8521–8531, 2024. 3
2024
-
[66]
Bimart: A unified ap- proach for the synthesis of 3d bimanual interaction with ar- ticulated objects
Wanyue Zhang, Rishabh Dabral, Vladislav Golyanik, Vasileios Choutas, Eduardo Alvarado, Thabo Beeler, Marc Habermann, and Christian Theobalt. Bimart: A unified ap- proach for the synthesis of 3d bimanual interaction with ar- ticulated objects. InComputer Vision and Pattern Recogni- tion (CVPR), 2025. 3, 6
2025
-
[67]
Cams: Canonicalized manipulation spaces for category-level functional hand-object manipulation synthe- sis
Juntian Zheng, Qingyuan Zheng, Lixing Fang, Yun Liu, and Li Yi. Cams: Canonicalized manipulation spaces for category-level functional hand-object manipulation synthe- sis. InComputer Vision and Pattern Recognition (CVPR), 2023
2023
-
[68]
TOCH: Spatio-temporal object-to-hand correspondence for motion refinement
Keyang Zhou, Bharat Lal Bhatnagar, Jan Eric Lenssen, and Gerard Pons-Moll. TOCH: Spatio-temporal object-to-hand correspondence for motion refinement. InEuropean Confer- ence on Computer Vision (ECCV), pages 1–19, 2022. 3
2022
-
[69]
Russell, Max J
Christian Zimmermann, Duygu Ceylan, Jimei Yang, Bryan C. Russell, Max J. Argus, and Thomas Brox. Frei- HAND: A Dataset for Markerless Capture of Hand Pose and Shape From Single RGB Images. InInternational Confer- ence on Computer Vision (ICCV), pages 813–822, 2019. 3 13
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.