From Extraction to Navigation: Progressive Retrieval with Indirectly Infinite Depth
Pith reviewed 2026-06-30 04:17 UTC · model grok-4.3
The pith
Retrieval is reframed as goal-driven graph navigation with state reuse for indirectly infinite depth at constant latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
IID-Nav models retrieval as iterative goal-driven graph traversal. A goal-aware navigation policy replaces passive neighborhood expansion with active intent routing supervised by a target discriminator. Recursive state evolution supports Indirectly Infinite Depth via cross-request state reuse, enabling logical unlimited-depth traversal without linearly rising inference latency. Trajectory-aligned training equipped with graph hard negative sampling stabilizes optimization over complete navigation paths.
What carries the argument
Recursive state evolution mechanism supporting Indirectly Infinite Depth (IID) via cross-request state reuse, which permits logical unlimited-depth graph traversal at fixed inference cost.
If this is right
- Surpasses mainstream retrieval baselines on billion-level industrial datasets under strict latency budgets.
- Alleviates search drift remarkably compared with static entry-node methods.
- Retains high precision for deep retrieval paths.
- Provides an efficient robust retrieval solution for industrial recommendation systems.
Where Pith is reading between the lines
- If cross-request state reuse remains stable, the same pattern could extend to other real-time graph traversal tasks such as conversational search or dynamic knowledge-base navigation.
- The separation of logical depth from physical latency suggests that dynamic intent routing may reduce the frequency of full index rebuilds in large recommendation graphs.
- Trajectory-aligned training with graph hard negatives might transfer to other long-horizon sequential decision problems where drift accumulates over steps.
Load-bearing premise
The goal-aware navigation policy supervised by a target discriminator together with trajectory-aligned training using graph hard negatives can be trained to stabilize optimization over full paths and deployed without instability or excessive overhead.
What would settle it
A direct replication on the same billion-level datasets in which IID-Nav shows no precision gain over mainstream baselines or fails to reduce search drift on long paths would falsify the central performance claims.
Figures

read the original abstract
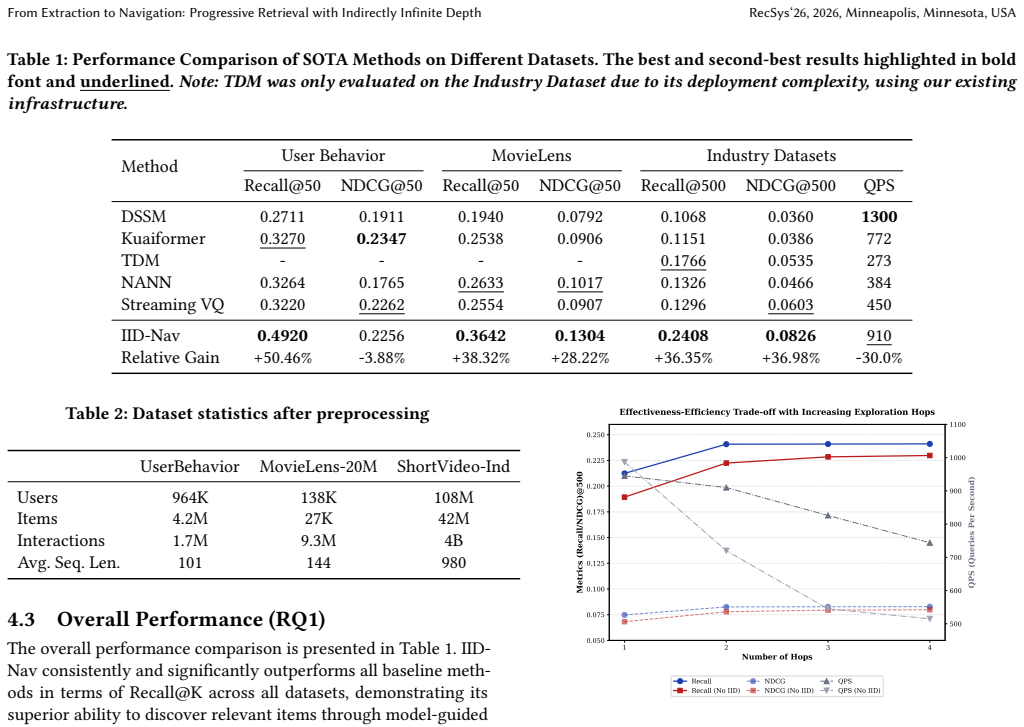
Modern large-scale recommender retrieval is shifting from static similarity matching to dynamic item space navigation, framing retrieval as iterative goal-driven graph traversal. Conventional item-to-item (i2i) methods fall into the "interest tunnel" and fail to excavate deep user interests, while existing index-based retrieval suffers from persistent "search drift", caused by static entry nodes and fixed graph topologies unable to track shifting real-time user intent. To resolve the above defects, we present IID-Nav, a framework modeling retrieval as stateful autonomous graph exploration with three core contributions: (1) A goal-aware navigation policy substituting passive neighborhood expansion with active intent routing supervised by a target discriminator; (2) A recursive state evolution mechanism supporting Indirectly Infinite Depth (IID) via cross-request state reuse, which enables logical unlimited-depth graph traversal without linearly rising inference latency; (3) A trajectory-aligned training paradigm equipped with graph hard negative sampling to stabilize optimization over full navigation paths. Evaluations on billion-level industrial datasets show IID-Nav surpasses mainstream retrieval baselines under strict latency budgets. Empirical results verify that our method alleviates search drift remarkably and retains high precision for deep retrieval paths, offering an efficient, robust retrieval solution for industrial recommendation systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes IID-Nav, a framework that reframes large-scale recommender retrieval as stateful autonomous graph exploration rather than static similarity matching. It introduces three components: (1) a goal-aware navigation policy that uses a target discriminator for active intent routing instead of passive neighborhood expansion; (2) a recursive state evolution mechanism enabling Indirectly Infinite Depth (IID) through cross-request state reuse, allowing logically unlimited graph traversal without linear latency growth; and (3) a trajectory-aligned training paradigm with graph hard negative sampling to stabilize optimization over full navigation paths. The central claim is that these elements allow IID-Nav to outperform mainstream retrieval baselines on billion-level industrial datasets under strict latency constraints while alleviating search drift and preserving precision on deep paths.
Significance. If substantiated with quantitative evidence, the work could meaningfully advance industrial retrieval by enabling deeper, intent-adaptive navigation without proportional compute costs. The recursive state reuse for effective unlimited depth is a concrete engineering contribution that directly targets latency budgets common in production systems. The training approach addresses a known optimization challenge in long-horizon graph policies. These elements build on existing graph-navigation ideas but add supervision and reuse mechanisms tailored to recommendation drift.
major comments (2)
- [Abstract] Abstract: The manuscript asserts that 'Evaluations on billion-level industrial datasets show IID-Nav surpasses mainstream retrieval baselines under strict latency budgets' and that the method 'alleviates search drift remarkably and retains high precision for deep retrieval paths,' yet supplies no metrics, baseline names, latency numbers, ablation results, dataset statistics, or error analysis. This absence is load-bearing for the central empirical claim and prevents any assessment of whether the three technical components deliver the stated gains.
- [Evaluation] Evaluation section (wherever reported): No tables, figures, or quantitative comparisons are referenced that would allow verification of the superiority claim or the stability of the goal-aware policy and trajectory-aligned training under industrial conditions.
minor comments (1)
- [Abstract] Abstract: The acronym 'IID' is defined as 'Indirectly Infinite Depth' but the manuscript does not supply a formal definition, recurrence relation, or bound showing how state reuse achieves 'indirectly' unlimited depth without eventual memory or consistency costs.
Simulated Author's Rebuttal
We thank the referee for highlighting the lack of quantitative support for our empirical claims. We agree that the current manuscript version does not include the necessary metrics, tables, or analyses, and we will revise to address this.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript asserts that 'Evaluations on billion-level industrial datasets show IID-Nav surpasses mainstream retrieval baselines under strict latency budgets' and that the method 'alleviates search drift remarkably and retains high precision for deep retrieval paths,' yet supplies no metrics, baseline names, latency numbers, ablation results, dataset statistics, or error analysis. This absence is load-bearing for the central empirical claim and prevents any assessment of whether the three technical components deliver the stated gains.
Authors: We acknowledge the validity of this critique. The abstract currently states performance claims without accompanying numbers or details, which prevents proper assessment. In the revised manuscript we will expand the abstract to report specific metrics (e.g., recall improvements, latency values in ms, dataset sizes), name the baselines (i2i and index-based methods), and reference the evaluation results that substantiate alleviation of search drift and precision retention on deep paths. revision: yes
-
Referee: [Evaluation] Evaluation section (wherever reported): No tables, figures, or quantitative comparisons are referenced that would allow verification of the superiority claim or the stability of the goal-aware policy and trajectory-aligned training under industrial conditions.
Authors: The referee correctly notes the absence of any tables, figures, or quantitative comparisons. This omission means the superiority claims and component stability cannot be verified from the submitted text. We will add a complete evaluation section containing tables with baseline comparisons on billion-level datasets, latency measurements under production constraints, ablation studies on the goal-aware policy and trajectory-aligned training, dataset statistics, and error analysis of search drift versus precision on deep paths. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical retrieval framework (IID-Nav) with three architectural and training contributions evaluated on industrial datasets. No mathematical derivations, equations, or first-principles predictions appear in the provided text; claims rest on experimental comparisons rather than any reduction of outputs to fitted inputs or self-citations by construction. The method is framed as a standard graph-navigation approach with added supervision, and the central performance claims are externally falsifiable via the reported benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Xingyan Bin, Jianfei Cui, Wujie Yan, Zhichen Zhao, Xintian Han, Chongyang Yan, Feng Zhang, Xun Zhou, Qi Wu, and Zuotao Liu. 2025. Real-time Indexing for Large-scale Recommendation by Streaming Vector Quantization Retriever. arXiv preprint arXiv:2501.08695(2025). From Extraction to Navigation: Progressive Retrieval with Indirectly Infinite Depth RecSys‘26,...
arXiv 2025
-
[2]
Rihan Chen, Bin Liu, Han Zhu, Yaoxuan Wang, Qi Li, Buting Ma, Qingbo Hua, Jun Jiang, Yunlong Xu, Hongbo Deng, et al. 2022. Approximate nearest neighbor search under neural similarity metric for large-scale recommendation. InPro- ceedings of the 31st ACM International Conference on Information & Knowledge Management. 3013–3022
2022
-
[3]
Rihan Chen, Bin Liu, Han Zhu, Yaoxuan Wang, Qi Li, Buting Ma, Qingbo Hua, Jun Jiang, Yunlong Xu, Hongbo Deng, and Bo Zheng. 2022. Approximate Nearest Neighbor Search under Neural Similarity Metric for Large-Scale Recommendation. arXiv:2202.10226 [cs.IR] https://arxiv.org/abs/2202.10226
arXiv 2022
-
[4]
Cong Fu, Chao Xiang, Changxu Wang, and Deng Cai. 2017. Fast approximate nearest neighbor search with the navigating spreading-out graph.arXiv preprint arXiv:1707.00143(2017)
arXiv 2017
-
[5]
Weihao Gao, Xiangjun Fan, Chong Wang, Jiankai Sun, Kai Jia, Wenzhi Xiao, Ruofan Ding, Xingyan Bin, Hui Yang, and Xiaobing Liu. 2021. Deep Re- trieval: Learning A Retrievable Structure for Large-Scale Recommendations. arXiv:2007.07203 [cs.IR] https://arxiv.org/abs/2007.07203
arXiv 2021
-
[6]
Chengcheng Guo, Junda She, Kuo Cai, Shiyao Wang, Qigen Hu, Qiang Luo, Guorui Zhou, and Kun Gai. 2025. MISS: Multi-Modal Tree Indexing and Searching with Lifelong Sequential Behavior for Retrieval Recommendation. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 5683–5690
2025
-
[7]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020. Lightgcn: Simplifying and powering graph convolution network for recommendation. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 639–648
2020
-
[8]
Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry Heck. 2013. Learning deep structured semantic models for web search using clickthrough data. InProceedings of the 22nd ACM international conference on Information & Knowledge Management. 2333–2338
2013
-
[9]
Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnawamy, and Rohan Kadekodi. 2019. Diskann: Fast accurate billion-point nearest neighbor search on a single node.Advances in neural information pro- cessing Systems32 (2019)
2019
-
[10]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
-
[11]
Houyi Li, Zhihong Chen, Chenliang Li, Rong Xiao, Hongbo Deng, Peng Zhang, Yongchao Liu, and Haihong Tang. 2021. Path-based deep network for candidate item matching in recommenders. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1493– 1502
2021
-
[12]
Chi Liu, Jiangxia Cao, Rui Huang, Kai Zheng, Qiang Luo, Kun Gai, and Guorui Zhou. 2024. KuaiFormer: Transformer-Based Retrieval at Kuaishou.arXiv preprint arXiv:2411.10057(2024)
arXiv 2024
-
[13]
Yue Meng, Cheng Guo, Xiaohui Hu, Honghu Deng, Yi Cao, Tong Liu, and Bo Zheng. 2025. User Long-Term Multi-Interest Retrieval Model for Recommenda- tion. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 1112–1116
2025
-
[14]
Qin Ren, Zheng Chai, Xijun Xiao, Yuchao Zheng, and Di Wu. 2025. LongRetriever: Towards Ultra-Long Sequence based Candidate Retrieval for Recommendation. arXiv preprint arXiv:2508.15486(2025)
arXiv 2025
-
[15]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[16]
InProceedings of the 28th ACM international conference on information and knowledge management
BERT4Rec: Sequential recommendation with bidirectional encoder rep- resentations from transformer. InProceedings of the 28th ACM international conference on information and knowledge management. 1441–1450
-
[17]
Yijia Sun, Shanshan Huang, Linxiao Che, Haitao Lu, Qiang Luo, Kun Gai, and Guorui Zhou. 2025. MPFormer: Adaptive Framework for Industrial Multi-Task Personalized Sequential Retriever. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 2832–2841
2025
-
[18]
Yijia Sun, Shanshan Huang, Zhiyuan Guan, Qiang Luo, Ruiming Tang, Kun Gai, and Guorui Zhou. 2025. GRank: Towards Target-Aware and Streamlined Indus- trial Retrieval with a Generate-Rank Framework.arXiv preprint arXiv:2510.15299 (2025)
arXiv 2025
-
[19]
Xiang Wang, Xiangnan He, Meng Wang, Fuli Feng, and Tat-Seng Chua. 2019. Neural graph collaborative filtering. InProceedings of the 42nd international ACM SIGIR conference on Research and development in Information Retrieval. 165–174
2019
-
[20]
Xiaoyong Yang, Yadong Zhu, Yi Zhang, Xiaobo Wang, and Quan Yuan. 2020. Large scale product graph construction for recommendation in e-commerce. arXiv preprint arXiv:2010.05525(2020)
arXiv 2020
-
[21]
Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L Hamilton, and Jure Leskovec. 2018. Graph convolutional neural networks for web-scale recommender systems. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 974–983
2018
-
[22]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1059–1068
2018
-
[23]
Han Zhu, Daqing Chang, Ziru Xu, Pengye Zhang, Xiang Li, Jie He, Han Li, Jian Xu, and Kun Gai. 2019. Joint Optimization of Tree-based Index and Deep Model for Recommender Systems. arXiv:1902.07565 [cs.IR] https://arxiv.org/abs/1902.07565
arXiv 2019
-
[24]
Han Zhu, Xiang Li, Pengye Zhang, Guozheng Li, Jie He, Han Li, and Kun Gai
-
[25]
InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery Data Mining
Learning Tree-based Deep Model for Recommender Systems. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery Data Mining. ACM, 1079–1088. doi:10.1145/3219819.3219826
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.