Toward an Energy-Optimized Operation of Data Centers Located in Wind Farms Using Reinforcement Learning
Pith reviewed 2026-06-30 07:26 UTC · model grok-4.3
The pith
Reinforcement learning agents can shift data center workloads to match wind availability but need imitation learning or reward shaping to overcome credit assignment issues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
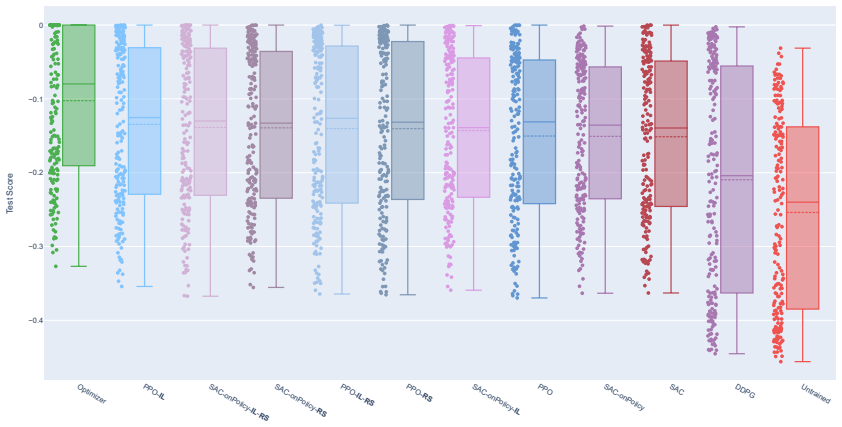
In the minimal single-turbine single-data-center case the authors show that pure RL exhibits a credit-assignment problem and underuses free wind energy, while PPO and an SAC variant with an extra on-policy update achieve strong empirical performance among learned policies; both imitation learning from an optimization baseline and reward shaping further improve outcomes in relevant configurations, although a gap to the offline optimizer with full-day foresight remains because RL must act from current observations alone.
What carries the argument
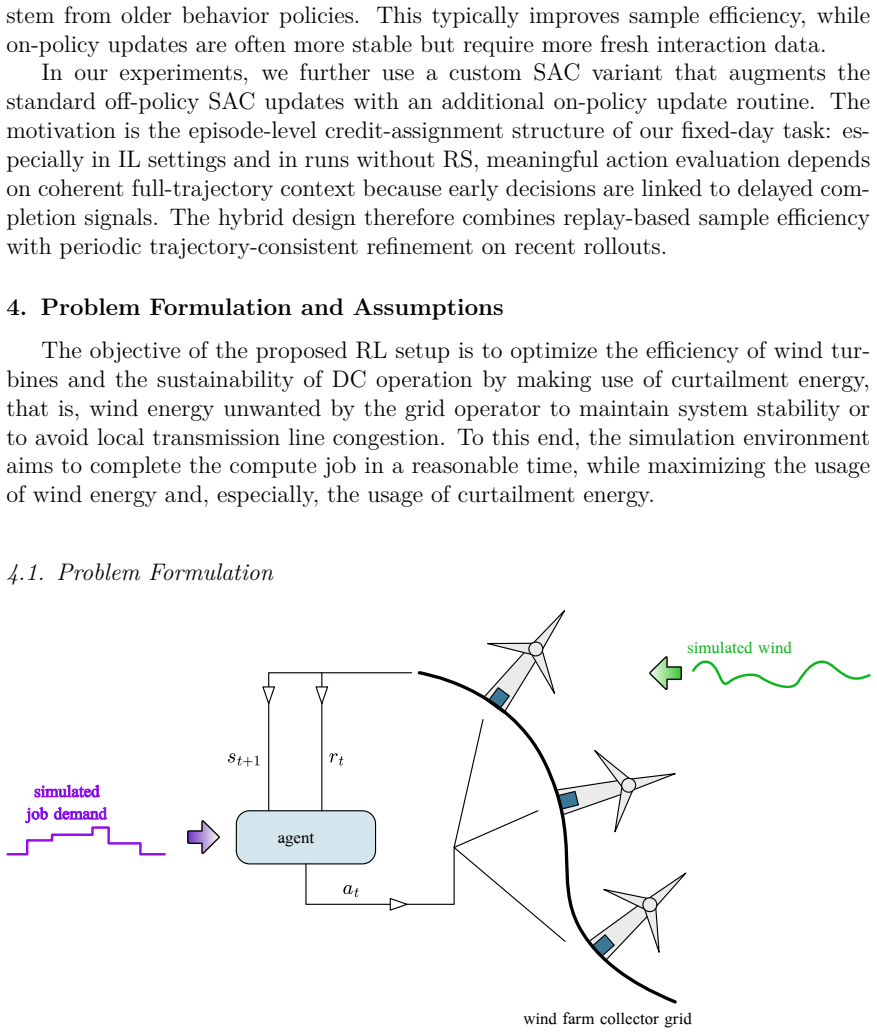
The reproducible fixed-day simulation framework that supplies synthetic wind and price signals together with delayed completion feedback, serving as the environment in which RL policies learn to perform curtailment-aware workload shifting.
If this is right
- RL policies can make decisions without future wind or price realizations, enabling real-time operation.
- Imitation learning from optimization solutions improves RL performance when credit assignment is difficult.
- Reward shaping addresses daily-cycle credit assignment without changing the underlying environment dynamics.
- The single-site benchmark supplies a transparent starting point for scaling to multi-site continuous-time settings.
- The remaining gap to the optimizer is expected and quantifies the value of online versus offline information.
Where Pith is reading between the lines
- If the framework extends successfully, data centers could respond to local wind without centralized day-ahead planning.
- The same simulation approach could be adapted to solar or other variable renewables with similar daily patterns.
- Hybrid controllers that blend partial forecasts with RL might narrow the performance gap while retaining online reactivity.
- Real-world tests would need to verify whether the synthetic signals capture the statistical dependence between wind speed and electricity price.
Load-bearing premise
The synthetic wind and price signals plus the fixed-day delayed-completion feedback model are representative enough of real wind-farm data-center dynamics that performance differences observed in simulation will translate when the controller is deployed on actual hardware.
What would settle it
Deploy the trained PPO and SAC policies on real 200-day wind-farm and data-center traces and check whether the measured wind-energy utilization and total energy cost remain within the same relative gap to the offline optimizer that was seen in simulation.
Figures




read the original abstract
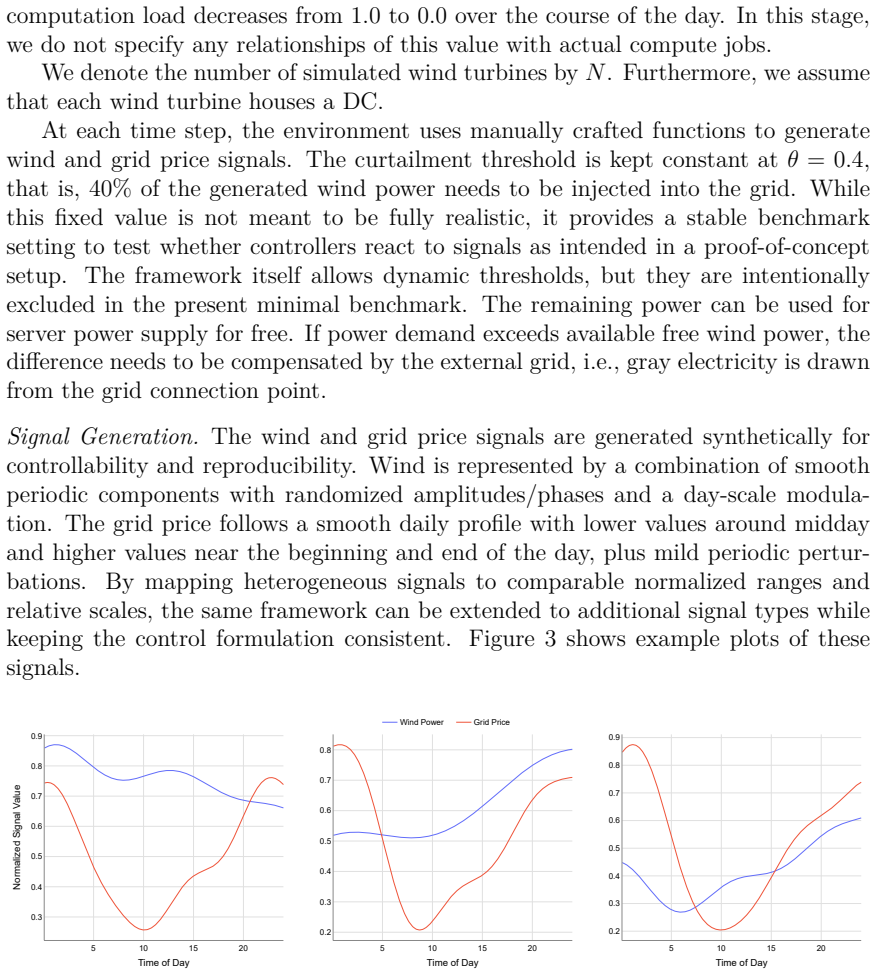
This paper studies Reinforcement Learning as an online controller for curtailment-aware workload shifting in wind-turbine-integrated high-performance computing (HPC) data centers. We introduce a reproducible fixed-day simulation framework with synthetic wind and price signals and delayed completion feedback, designed to be extensible toward more complex scenarios. As a controlled benchmarking basis, we then focus on the minimal case with one wind turbine and one co-located data center. In this setting, pure Reinforcement Learning exhibits a pronounced credit-assignment problem and tends to underuse free wind energy early in the day. We therefore evaluate two complementary countermeasures: optimization-based Imitation Learning and potential-based Reward Shaping. Across multi-seed training and a 200-day test set, Proximal Policy Optimization (PPO) and a Soft Actor-Critic (SAC) variant with an additional on-policy update routine achieve strong empirical performance among learned policies, and both Imitation Learning and Reward Shaping provide improvements in relevant configurations. A performance gap to the optimizer remains, which is expected: the optimizer plans offline with full-day foresight, whereas Reinforcement Learning must decide online from current observations without future realizations. The benchmark and ablation results provide a transparent basis for extending the approach toward richer multi-site and continuous-time scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a reproducible fixed-day synthetic simulation for curtailment-aware workload shifting in a single wind-turbine co-located HPC data center. It identifies a credit-assignment problem in pure RL, evaluates PPO and a SAC variant augmented with an on-policy update, and shows that optimization-based imitation learning and potential-based reward shaping yield empirical gains on a 200-day held-out test set across multiple seeds, while the learned policies remain below an offline full-information optimizer.
Significance. If the relative ordering holds under the stated synthetic dynamics, the work supplies a transparent, extensible benchmark that isolates the credit-assignment issue and quantifies the benefit of the two countermeasures. The explicit acknowledgment of the offline-optimizer gap and the use of multi-seed training plus held-out evaluation are positive features that facilitate future extensions to multi-turbine or continuous-time settings.
minor comments (2)
- [Methods / Experimental Setup] The precise definition of the state vector, action space, and reward components (including the delayed-completion term) should be stated explicitly in §3 or §4 so that the credit-assignment diagnosis can be reproduced without ambiguity.
- [Results] Table or figure reporting the 200-day results should include per-seed standard deviations or confidence intervals to substantiate the claim that IL and RS provide improvements "in relevant configurations."
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation of minor revision. The referee's summary correctly captures the paper's focus on the reproducible simulation, the credit-assignment issue in pure RL, the empirical gains from imitation learning and reward shaping, and the expected gap to the offline optimizer. We are pleased that the transparent benchmark and multi-seed held-out evaluation are viewed as strengths that support future extensions.
Circularity Check
No significant circularity
full rationale
The manuscript reports relative empirical performance of PPO, SAC variants, Imitation Learning, and Reward Shaping on a deliberately synthetic fixed-day benchmark with held-out test days. No equations, predictions, or central claims reduce by construction to quantities fitted inside the same experiment; the reported ordering is generated by standard RL training and evaluation on separate trajectories. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing support for the results. The performance gap to the offline optimizer is explicitly acknowledged as expected given the online decision constraint.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The environment can be modeled as a Markov decision process with the chosen state and action spaces.
Reference graph
Works this paper leans on
-
[1]
Iea. 2023. international energy agency’s data centres and data trans- mission networks.,https://www.iea.org/energy-system/buildings/ data-centres-and-data-transmission-networks, accessed: 2025-08-27 (2023)
2023
-
[2]
Iea. 2023. international energy agency’s report on low- emissions sources of electricity.,https://www.iea.org/reports/ low-emissions-sources-of-electricity, accessed: 2025-08-27 (2023)
2023
-
[3]
A. A. Chien, L. Lin, As Grids Reach 100% Renewable at Peak, Growing Curtail- ment of 8 Gigawatts Looms as a Challenge to Decarbonization, SIGENERGY Energy Inform. Rev. 4 (1) (2024) 3–10.doi:10.1145/3649432.3649434
-
[4]
J. Zheng, A. A. Chien, S. Suh, Mitigating Curtailment and Carbon Emissions through Load Mirgration between Data Centers, Joule 4 (10) (2020) 2208–2222. doi:10.1016/j.joule.2020.08.001. 21
-
[5]
F. Yang, A. A. Chien, Large-Scale and Extreme-Scale Computing with Stranded Green Power: Opportunities and Costs, IEEE Transactions on Parallel and Dis- tributed Systems 29 (5) (2018) 1103–1116.doi:10.1109/TPDS.2017.2782677
-
[6]
L. Lin, A. A. Chien, Adapting Datacenter Capacity for Greener Datacenters and Grid, in: Proceedings of the 14th ACM International Conference on Future Energy Systems, e-Energy ’23, Association for Computing Machinery, New York, NY, USA, 2023, p. 200–213.doi:10.1145/3575813.3595197
-
[7]
A. Radovanović, R. Koningstein, I. Schneider, B. Chen, A. Duarte, B. Roy, D. Xiao, M. Haridasan, P. Hung, N. Care, S. Talukdar, E. Mullen, K. Smith, M. Cottman, W. Cirne, Carbon-aware computing for datacenters, IEEE Trans- actions on Power Systems 38 (2) (2023) 1270–1280.doi:10.1109/TPWRS.2022. 3173250
-
[8]
T. Sukprasert, A. Souza, N. Bashir, D. Irwin, P. Shenoy, On the limitations of carbon-aware temporal and spatial workload shifting in the cloud, in: Proceed- ings of the Nineteenth European Conference on Computer Systems, EuroSys ’24, Association for Computing Machinery, New York, NY, USA, 2024, p. 924–941. doi:10.1145/3627703.3650079. URLhttps://doi.org/...
-
[9]
T. B. Hewage, S. Ilager, M. A. Rodriguez, R. Buyya, A framework for carbon- aware real-time workload management in clouds using renewables-driven cores, IEEE Transactions on Computers 74 (8) (2025) 2757–2771.doi:10.1109/TC. 2025.3571495
work page doi:10.1109/tc 2025
-
[10]
A. Kilian, H. de Meer, G. Schomaker, Energy-optimized supercomputer networks using wind energy, Commun. ACM 68 (7) (2025) 74–79.doi:10.1145/3725981
-
[11]
A. Kilian, M. Bettermann, H. de Meer, Energy-optimized operation of a dis- tributed data center infrastructure located in wind farms: a multi-agent system approach, Applied Energy 409 (2026) 127454.doi:10.1016/j.apenergy.2026. 127454
-
[12]
M. Ahmadi, L. Knorr, H. Meschede, Improvement of wind power utilization through flexible operation of data center in wind parks, Renewable Energy 248 (2025) 123073.doi:10.1016/j.renene.2025.123073
-
[13]
A. Jayanetti, S. Halgamuge, R. Buyya, Deep reinforcement learning for energy and time optimized scheduling of precedence-constrained tasks in edge–cloud computing environments, Future Generation Computer Systems 137 (2022) 14– 30.doi:10.1016/j.future.2022.06.012. 22
-
[14]
S. Swarup, E. M. Shakshuki, A. Yasar, Energy Efficient Task Scheduling in Fog Environment using Deep Reinforcement Learning Approach, Procedia Computer Science 191 (2021) 65–75, the 18th International Conference on Mobile Systems and Pervasive Computing (MobiSPC), The 16th International Conference on Fu- ture Networks and Communications (FNC), The 11th In...
-
[15]
S. Shadroo, A. M. Rahmani, A. Rezaee, The two-phase scheduling based on deep learning in the Internet of Things, Computer Networks 185 (2021) 107684. doi:10.1016/j.comnet.2020.107684
-
[16]
T. Oudaa, H. Gharsellaoui, S. Ben Ahmed, An Agent-based Model for Resource Provisioning and Task Scheduling in Cloud Computing Using DRL, Procedia Computer Science 192 (2021) 3795–3804, knowledge-Based and Intelligent Infor- mation&EngineeringSystems: Proceedingsofthe25thInternationalConference KES2021.doi:10.1016/j.procs.2021.09.154
-
[17]
G. Zhou, R. Wen, W. Tian, R. Buyya, Deep reinforcement learning-based algorithms selectors for the resource scheduling in hierarchical Cloud com- puting, Journal of Network and Computer Applications 208 (2022) 103520. doi:10.1016/j.jnca.2022.103520
-
[18]
R. Shaw, E. Howley, E. Barrett, Applying Reinforcement Learning towards au- tomating energy efficient virtual machine consolidation in cloud data centers, Information Systems 107 (2022) 101722.doi:10.1016/j.is.2021.101722
-
[19]
Y. Wang, Y. Li, T. Wang, G. Liu, Towards an energy-efficient Data Center Network based on deep reinforcement learning, Computer Networks 210 (2022) 108939.doi:10.1016/j.comnet.2022.108939
-
[20]
E. Kolker-Hicks, D. Zhang, D. Dai, A Reinforcement Learning Based Backfilling Strategy for HPC Batch Jobs, in: Proceedings of the SC ’23 Workshops of the International Conference on High Performance Computing, Network, Storage, and Analysis, SC-W ’23, Association for Computing Machinery, New York, NY, USA, 2023, pp. 1316–1323.doi:10.1145/3624062.3624201
-
[21]
R. Leo, R. S. Milton, S. Sibi, Reinforcement learning for optimal energy man- agement of a solar microgrid, in: 2014 IEEE Global Humanitarian Technol- ogy Conference - South Asia Satellite (GHTC-SAS), 2014, pp. 183–188.doi: 10.1109/GHTC-SAS.2014.6967580. 23
-
[22]
G. Muriithi, S. Chowdhury, Optimal Energy Management of a Grid-Tied Solar PV-Battery Microgrid: A Reinforcement Learning Approach, Energies 14 (9) (2021).doi:10.3390/en14092700
-
[23]
B. Zhang, W. Hu, J. Li, D. Cao, R. Huang, Q. Huang, Z. Chen, F. Blaab- jerg, Dynamic energy conversion and management strategy for an integrated electricity and natural gas system with renewable energy: Deep reinforcement learning approach, Energy Conversion and Management 220 (2020) 113063. doi:10.1016/j.enconman.2020.113063
-
[24]
Y. Liu, X. Guan, J. Li, D. Sun, T. Ohtsuki, M. M. Hassan, A. Alelaiwi, Eval- uating smart grid renewable energy accommodation capability with uncertain generation using deep reinforcement learning, Future Generation Computer Sys- tems 110 (2020) 647–657.doi:10.1016/j.future.2019.09.036
-
[25]
T. Yang, L. Zhao, W. Li, A. Y. Zomaya, Reinforcement learning in sustainable energy and electric systems: a survey, Annual Reviews in Control 49 (2020) 145–163.doi:10.1016/j.arcontrol.2020.03.001
-
[26]
T. Ahmad, R. Madonski, D. Zhang, C. Huang, A. Mujeeb, Data-driven prob- abilistic machine learning in sustainable smart energy/smart energy systems: Key developments, challenges, and future research opportunities in the context of smart grid paradigm, Renewable and Sustainable Energy Reviews 160 (2022) 112128.doi:10.1016/j.rser.2022.112128
-
[27]
R. S. Sutton, A. G. Barto, Reinforcement Learning: An Introduction, 2nd Edi- tion, Adaptive Computation and Machine Learning series, The MIT Press, 2018
2018
-
[28]
M. T. J. Spaan, Partially Observable Markov Decision Processes, Springer Berlin Heidelberg, Berlin, Heidelberg, 2012, pp. 387–414.doi:10.1007/ 978-3-642-27645-3\_12. URLhttps://doi.org/10.1007/978-3-642-27645-3_12
-
[29]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, O. Klimov, Proximal policy optimization algorithms (2017).arXiv:1707.06347. URLhttps://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, D.Wierstra, Continuouscontrolwithdeepreinforcementlearning(2019).arXiv: 1509.02971. URLhttps://arxiv.org/abs/1509.02971 24
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[31]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, S. Levine, Soft actor-critic: Off-policy maxi- mum entropy deep reinforcement learning with a stochastic actor (2018). URLhttps://openreview.net/forum?id=HJjvxl-Cb
2018
-
[32]
Libardi, G
G. Libardi, G. De Fabritiis, S. Dittert, Guided exploration with proximal policy optimization using a single demonstration (18–24 Jul 2021). URLhttps://proceedings.mlr.press/v139/libardi21a.html
2021
-
[33]
A. Y. Ng, D. Harada, S. J. Russell, Policy invariance under reward transfor- mations: Theory and application to reward shaping, in: Proceedings of the Sixteenth International Conference on Machine Learning, ICML ’99, Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 1999, p. 278–287. 25 Appendix A. On-Policy Update Routine for SAC This appendix sum...
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.